行人重识别ReID整理


行人重识别(Person re-identification)也称行人再识别,被广泛认为是一个图像检索子问题,是利用计算机视觉技术判断图像或者视频中是否存在特定行人的技术,即给定一个监控行人图像检索跨设备下的该行人图像。行人重识别技术可以弥补目前固定摄像头的视觉极限,并可与行人检测、行人跟踪技术相结合,应用于视频监控、智能安防等领域。

一般行人重识别具有短时效应,我们需要识别的行人的衣服是一个主要特征,当然衣服只是特征之一,如果该行人更换了衣服,那么行人重识别可能会失效。
它的主要原理如下
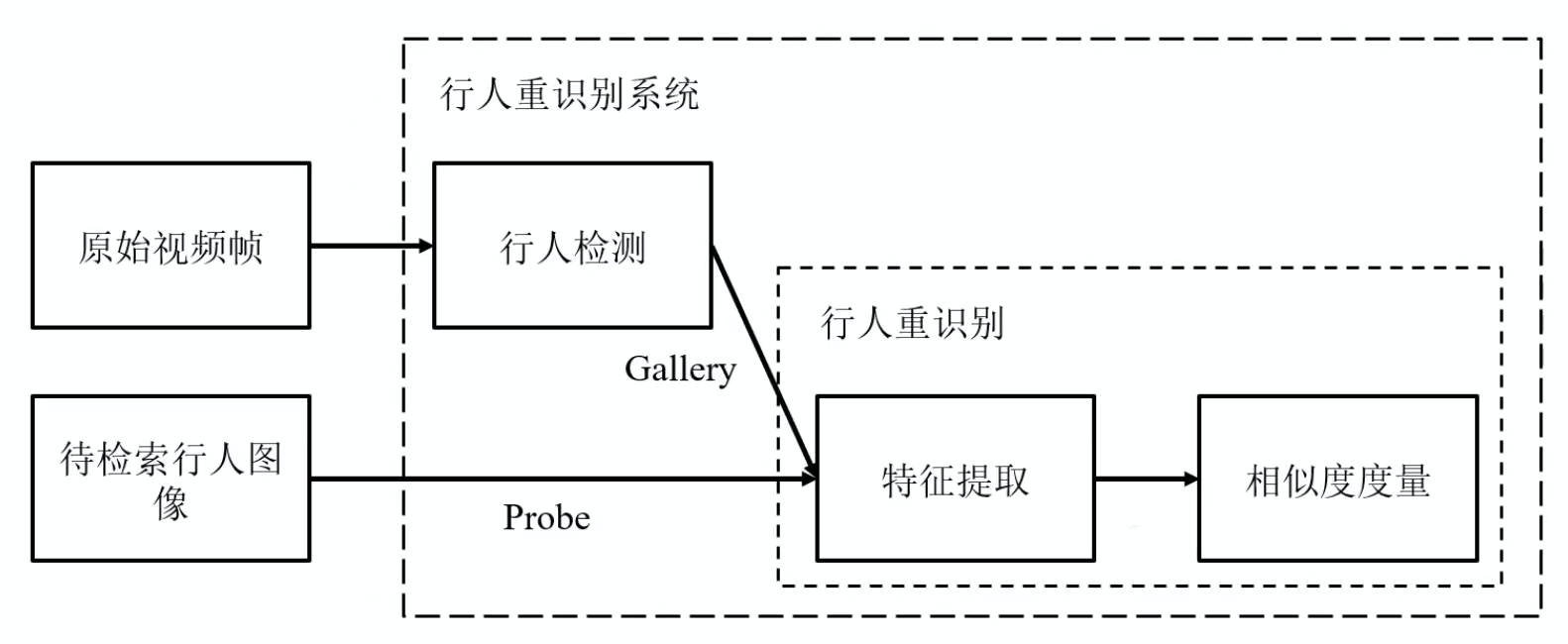
首先我们需要一个行人检测系统将原始视频帧中的所有行人全部检测出来,形成一个仓库Gallery,然后我们需要一个待检索的行人的个人图像,称为Probe,将该行人的特征提取出来,在Gallery中进行比对,即进行相似度的度量,大于一定的阈值,即认为在Gallery中检索到了该行人。
数据集
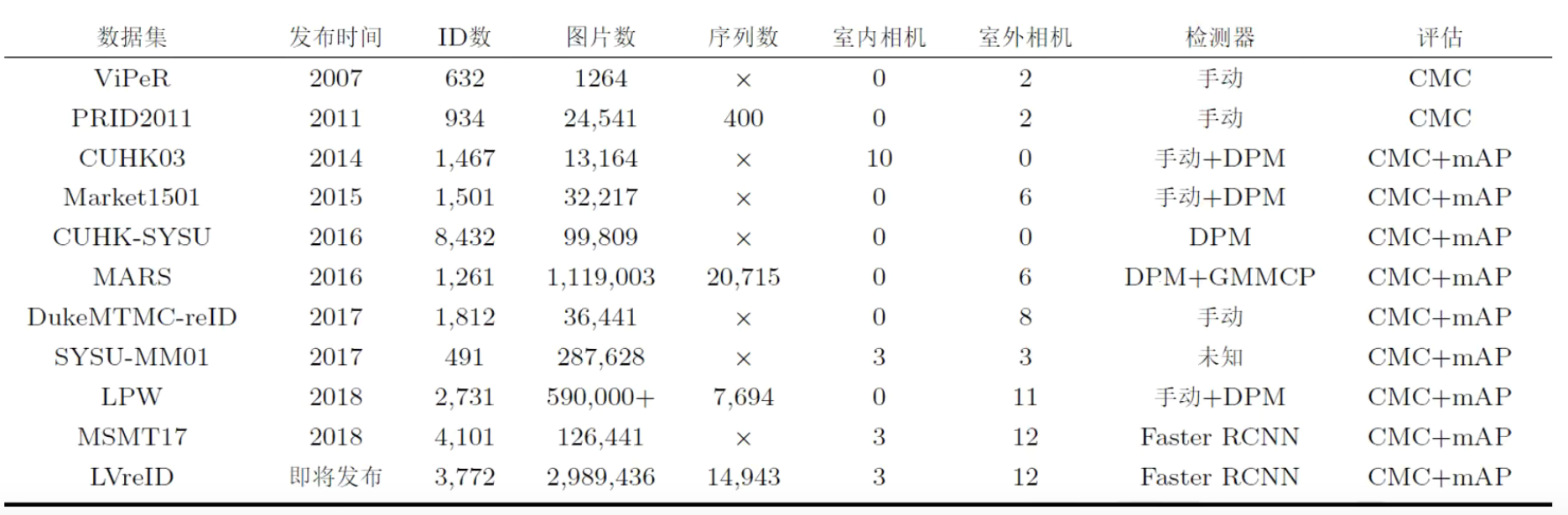
数据集通常是通过人工标注或者检测算法得到的行人图片,目前与检测独立,注重识别。分为训练集、验证集、Query(一堆Probe,待检索的个人照片)、Gallery(图像库)。在训练集上进行模型训练,得到模型参数后对Query与Gallery中的图片提取特征值计算相似度,对于每个Query在Gallery中找出前N个与其相似的图片。训练、测试中人物身份不能重复。

数据集分为单帧和序列的。

单帧

序列
挑战
行人重识别目前准确率只能达到90%,不同人脸识别,可以达到99%的准确率,主要原因为

常用的评价指标
- rank-k:算法返回的排序列表中,前k位存在检索目标则称为rank-k命中。
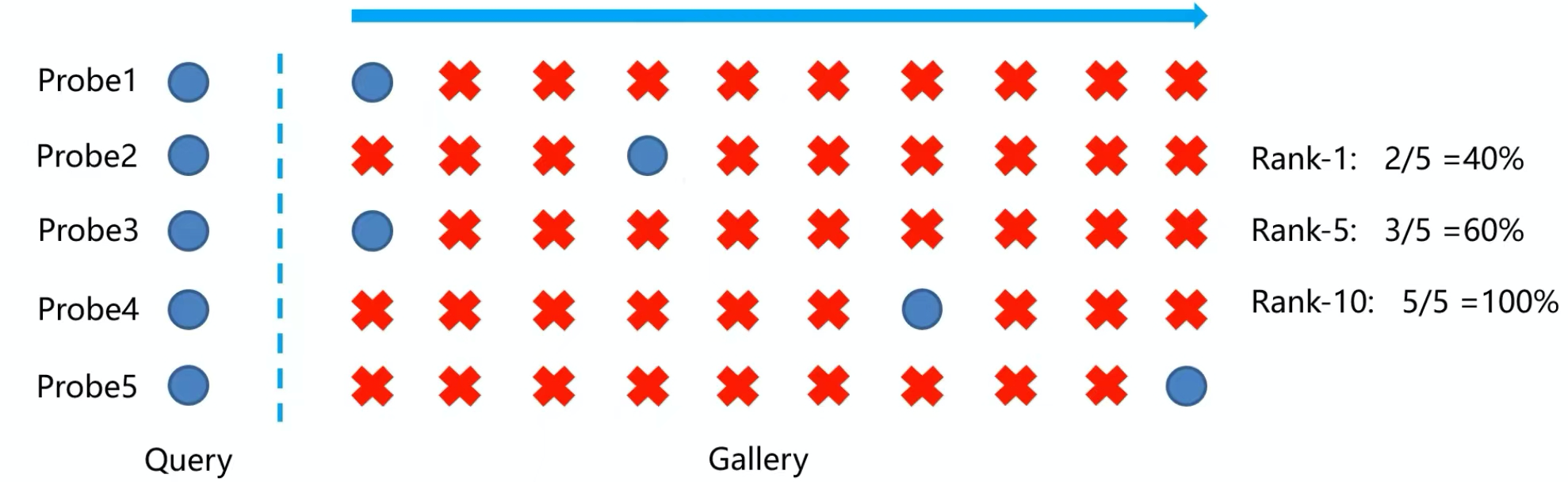
上图中第一行第一个样本,第一个就击中了,所以它是rank-1击中;第二行第二个样本,它前3都未击中,第四个击中了,它属于前5击中,包括rank-1在那,所以是rank-5击中;第四和第五行都没有前五击中,但是在前10集中,所以它们都是好rank-10。这样下来rank-1的概率就为40%,rank-5的概率就为60%,rank-10的概率就是100%。
- CMC曲线:计算rank-k的击中率,形成rank-acc的曲线
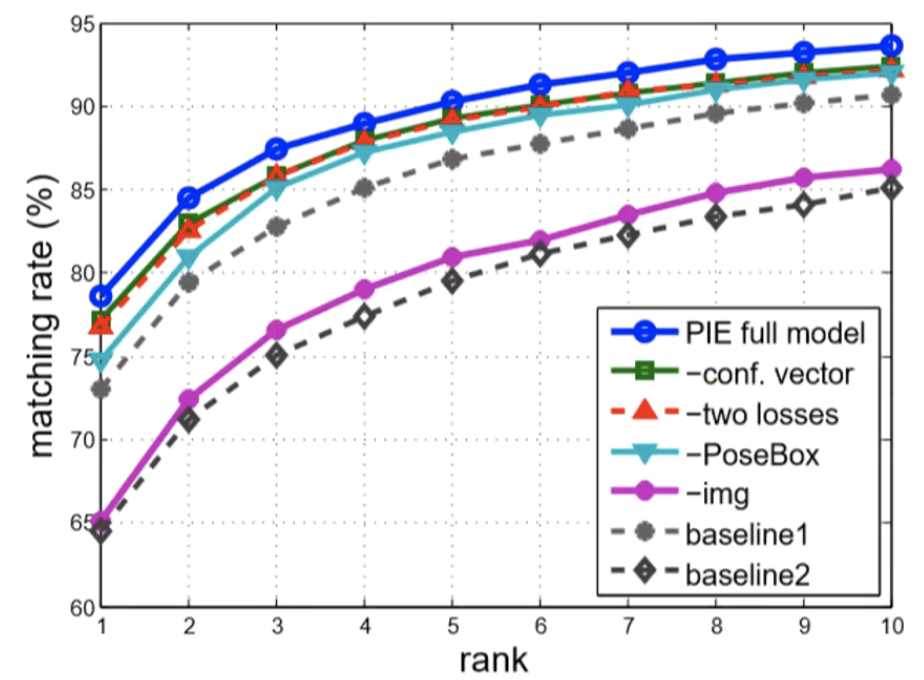
上图是各个算法的rank-k曲线,无论哪种算法,肯定k值越大,准确率越高,这是必然的。
- mAP曲线:反应检索的人在数据库中所有正确的图片在排序列表前面的程度,能更加全面的衡量ReID算法的性能。
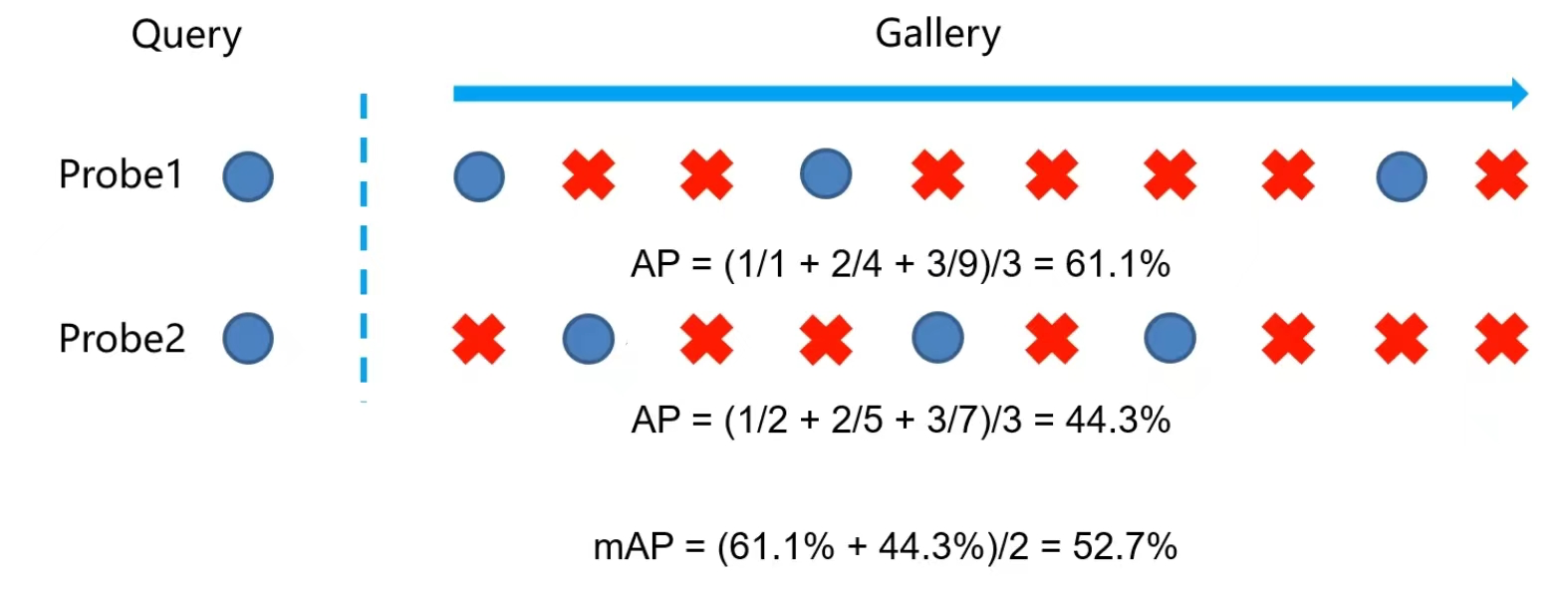
在上图中,如果Gallery有多个Probe1的图片,其中有一张图片在rank-1被击中,另外两张图片分别在rank-4和rank-9被击中。而Probe2在rank-2、rank-5、rank-7被击中,由于Probe1有rank-1的,Probe2只有rank-2的,是否说明Prob1比Prob2好呢?答案是不一定的。
这里我们要计算AP值,在Probe1中,rank-1的概率是1/1,rank-4的概率是2/4(这里包含了rank-1),rank-9的概率是3/9(这里包含了rank-1和rank-4),将rank-1、rank-4、rank-9的概率加起来除以平均数3,就得到了Probe1的AP值为61.1%。同理Probe2的AP值为44.3%。
mAP就是所有Probe AP的平均,由于这里只有两个Probe,故mAP=52.7%。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2023-12-08,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号