ICML 2023 | DECOMPDIFF:解义先验的扩散模型进行基于结构药物设计

ICML 2023 | DECOMPDIFF:解义先验的扩散模型进行基于结构药物设计

Houye
发布于 2024-01-18 14:46:19
发布于 2024-01-18 14:46:19

编译 | 邱闽瑶
审核 | 熊展坤
今天给大家介绍的是美国伊利诺伊大学及字节跳动发表在ICML的一篇文章:DECOMPDIFF: Diffusion Models with Decomposed Priors for Structure-Based Drug Design。设计针对靶向结合位点的3D药物分子是药物发现中的基本任务。现有的基于结构的药物设计方法平等对待所有配体原子,忽视了配体原子在药物设计中的不同作用,对于探索庞大的药物样分子空间可能效率较低。本文受制药实践的启发,将配体分子分解为两部分,即臂和支架,并提出了一种新的扩散模型 DECOMPDIFF,其对臂和支架采用了分解的先验。为了促进分解生成并改善所生成分子的性质,作者在模型中同时结合了键扩散和采样阶段的有效性指导
1.背景
现代深度学习正在彻底改变药物发现的许多子领域,其中基于结构的药物设计(SBDD)是一个重要且具有挑战性的领域。现有SBDD的深度学习方法取得了很好的成绩,例如,自回归模型通过迭代添加原子和键在目标结合位点以生成3D分子。然而却容易造成误差积累,且需预定义生成顺序。为了克服这些缺点,扩散模型进一步应用到该领域,近期的研究使用扩散模型从标准高斯先验中近似原子类型和位置的分布,并使用后处理算法来分配原子之间的键。这些基于扩散模型的方法可以同时模拟原子之间的局部和全局相互作用,并且比自回归模型具有更好的性能。尽管性能优秀,但在建模过程中忽略了键,可能导致不合理的分子结构。此外,基于扩散模型的方法将配体分子视为一个整体,并学习了目标结合位点与配体之间的整体对应关系。然而作者认为,同一配体中的原子具有不同的功能。因此,平等对待所有配体原子可能不是SBDD的最佳方法,特别是考虑到目前巨大的药物设计的探索空间和有限的高质量靶配体复合物训练数据。因此作者考虑如何将与功能相关的先验知识纳入到基于扩散模型的SBDD中。
作者将小分子视为臂(负责和蛋白相互作用)和骨架(负责将臂定位到特定位置)的组合,提出了具有分解先验的DECOMPDIFF扩散模型,使起可以在小分子与蛋白相互作用时,自然的将小分子按功能分解。同时作者还对化学键进行了扩散,并在生成阶段引入了有效性引导(促进臂和骨架的连接、避免与蛋白质口袋的冲突)。文章亮点:1.将药物设计的小分子进行分解为不同功能的片段(类似于NLP中的语义分解)。2.同时考虑原子和键的扩散。3.生成采样的过程中引入Guid,以引导生成有效的分子。
2.方法
本文利用了蛋白质结合位点的信息,定义为:
小分子被定义为:
其中
代表原子的坐标,
代表原子类型,原子数量可以从经验分布中采样,或神经网络预测。将配体视为K个片段,分为臂A和片段S,其中
从机器学习的角度来看,片段K提供了配体原子的自然簇。直观来说,利用这些自然聚类作为含知识的先验分布,将比不含先验的高斯先验更容易近似pθ。具体来说,根据最优先验假设(Optimal prior hypothesis),利用聚类簇位置进行最大似然估计(MLE),用高斯分布估计每个聚类的先验。在训练阶段,先验可以从参考配体中获得,在推理阶段,先验则有专家推理或算法计算。
2.1 先验知识
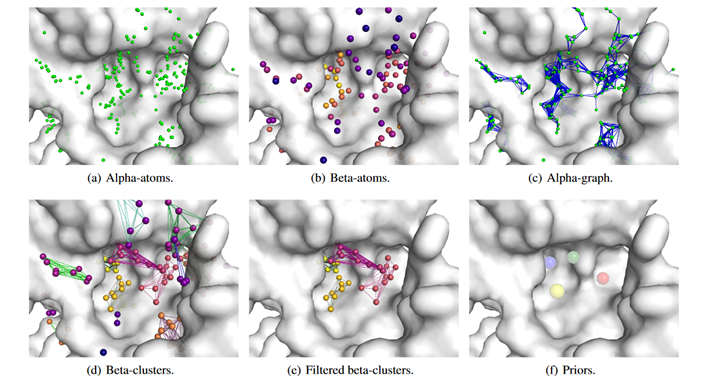
这里采用个体的空间先验知识,采用AlphaSpace2工具提取先验知识:(1)在reference ligand的10A附近,利用工具构建虚拟的α原子。该原子可与蛋白口袋表现形成几何接触(下图a);(2)利用该软件,将α原子group为β原子,并打分,分数代表pocket ligandability(下图b,颜色越深分数越高);(3)对β原子进行聚类(下图d),过滤掉打分较低的聚类结果(下图e),根据reference ligand和打分,将剩余β原子聚类为框架聚类和臂聚类(下图f)。(4)以左图为例,该蛋白质口袋的空间先验知识分为4个聚类,包括一个框架的置心区间,三个臂的置心区间(下图f)。
2.2 结合先验知识的扩散模型
上一节得到的先验知识包括:
。其中,
为聚类簇的置心坐标,
为方差矩阵,
为Nk*K的0/1矩阵,一个原子仅能分配到一个聚类簇中。由于这里的先验知识为3D坐标中的位置信息,因此作者省略了对原子类型和键类型扩散的一般过程,详细介绍了含有先验知识的3D坐标扩散的过程。为了实现等变效果,作者对坐标采用了中心移位操作,
采用蓝色突出了先验坐标扩散和一般坐标扩散的区别:
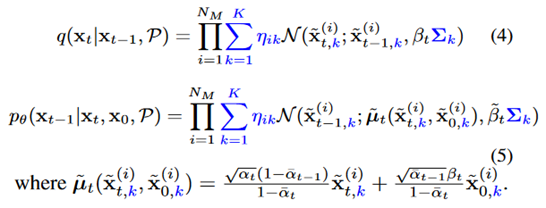
先验分布为:
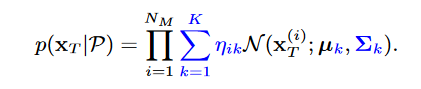
2.3 模型结构
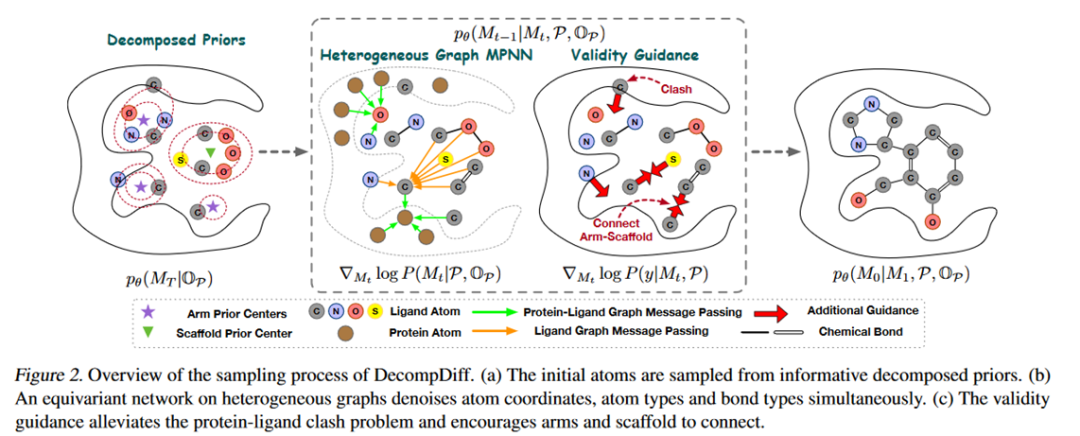
已有扩散模型多仅考虑对原子类型和原子坐标的扩散,通过后处理算法(例如OpenBabel)加键。理想情况下,如果原子坐标被准确地预测,这种范式就可以很好地工作。然而,由于键距的分布非常sharp,一个小的误差就可能导致完全不同的分子,基于不完美原子坐标的后处理算法添加键并不总是可靠的。因此,作者在扩散过程中同时考虑了化学键的扩散。将分子定义为:
,因此前向扩散可以看作:
节点的特征传递过程:
边特征的消息传递:
坐标特征的消息传递:
有效性引导:作者从两个方面考虑生成分子的有效性:(a)臂和支架应该连接起来形成一个完整的分子;(b)生成的分子和蛋白质表面之间不应有冲突。具体如何引导参见原文,公式为:对于臂-支架漂移可以推导如下:
碰撞漂移可以推导如下:
3.结果
作者从构象和性质两个方面对模型进行了评估,利用CrossDocked2020数据,经过过滤与筛选,得到训练数据100,000个,全新的测试数据100个。对于构象评估方面,作者计算了参考分子和生成分子之间原子/键距离分布和键角分布的Jensen-Shannon散度(JSD),如下表所示。
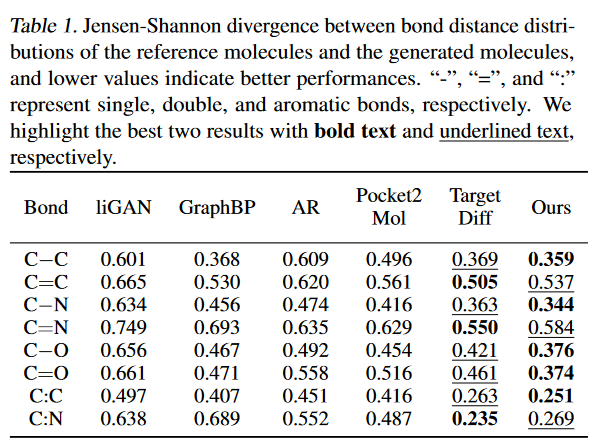
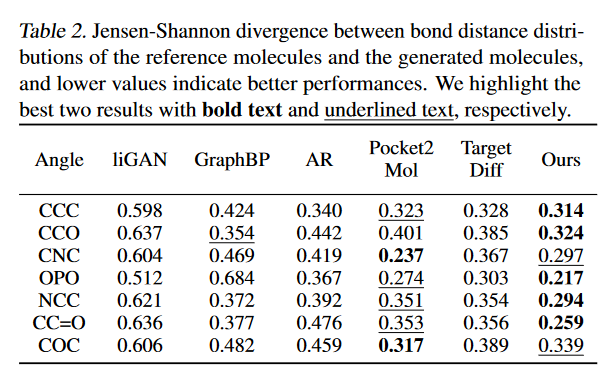
结果显示,作者的模型具有与TargetDiff相当的性能,并且明显优于所有其他基线,这表明其提出的方法具有直接生成稳定分子构象的强大潜力。然后,作者从结合亲和力和分子性质方面评估了其模型的有效性。可以看到,与属性相关的度量(QED、SA)和与亲和力相关的度量之间存在权衡。与TargetDiff一样,作者的模型在QED和SA得分方面落后于SOTA自回归模型Pocket2Mol。
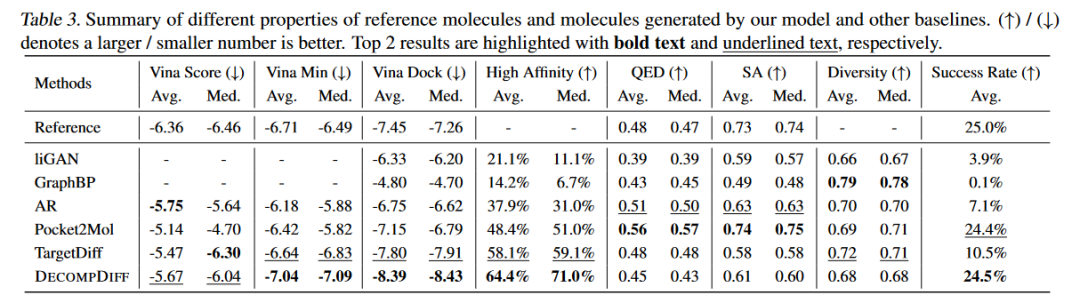
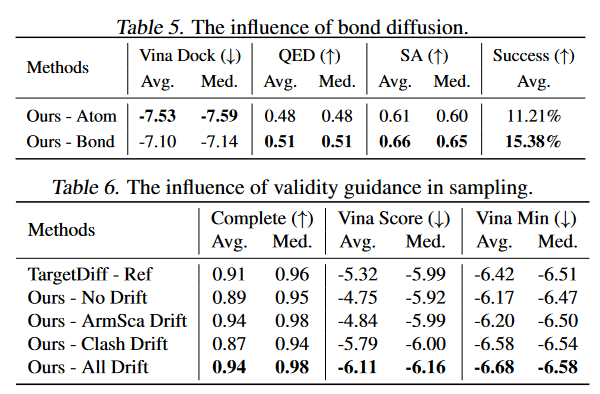
作者进一步进行了消融实验
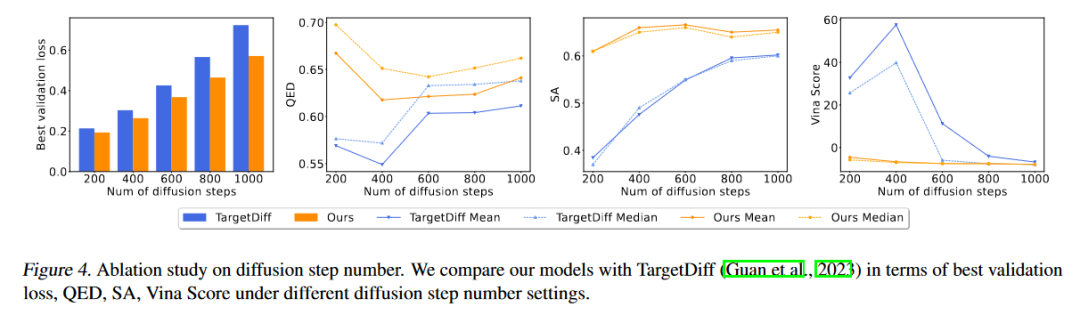
结果表明,该模型可以用更少的采样步骤生成高质量的配体分子(高QED和SA,低Vina)。作者还验证了键扩散和有效性采用引导的作用:
4.原文和代码
原文:https://openreview.net/forum?id=9qy9DizMlr
代码:https://github.com/bytedance/DecompDiff

点个在看+赞支持一下呗
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-01-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号