标题:Personalized Behavior-Aware Transformer for Multi-Behavior Sequential Recommendation
地址:https://arxiv.org/pdf/2402.14473.pdf
会议:MM'23
学校:浙大
代码:https://github.com/TiliaceaeSU/PBAT
1.导读
本文主要针对序列推荐中的多行为序列推荐,即行为序列中包含不同的行为类型,比如点击,加购,购买等。为了捕获用户的个性化行为模式和行为间的复杂协作关系,作者提出PBAT方法:
- 通过个性化行为模式生成器来提取动态且具有区分度的行为模式,不同用户的行为模式是不同的
- 并在自注意力层引入行为感知的协作提取器,提取序列中的协作转换关系
alt text
如图所示是一个例子,对于Mike,他通常会将想要购买的物品添加到购物车,最终的购买也是之前加购物车的商品。而对于Anna,她的行为模式中可能加购和最终购买并没有强关联性,即不同用户的行为模式是不同的。
并且,将手机添加到购物车可能会促使用户随后购买蓝牙耳机,因为这两种物品在用途上是互补的。然而,将耳机添加到购物车可能会降低购买耳机的概率,因为这两种产品在市场竞争力上存在竞争关系。这些行为序列暗示了潜在的物品间协作关系,而物品间的协作又反过来影响了行为转换的影响。
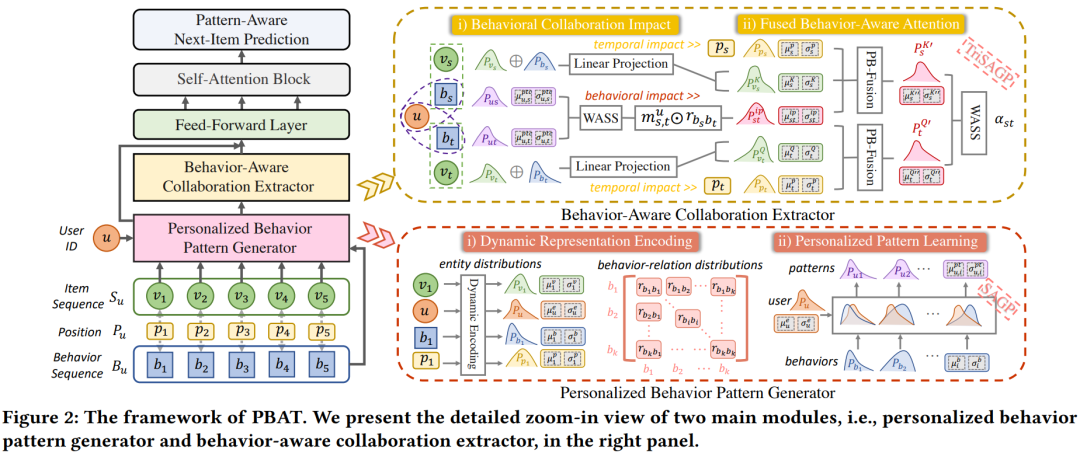
2. 方法
alt text
PBAT基于Transformer,主要由两个模块组成:
- 个性化行为模式生成器(Personalized Behavior Pattern Generator, PBPG),生成器包含两个部分:
- 动态表征编码,利用高斯分布来描述多行为序列中的实体和关系,得到更具区分性的表征
- 个性化模式学习,利用自适应高斯生成来精细化通用行为模式,更好地反映用户的个性化偏好。
- 行为感知协作提取器(Behavior-Aware Collaboration Extractor, BACE)。
- 通过整合统一的行为关系和个性化模式来提取行为协作影响因子;
- 使用行为感知注意力机制探索从物品、行为和位置的复杂序列协作。
2.1 个性化行为模式生成器
2.1.1 动态表征编码
受外部和内部因素的影响,用户行为模式在序列环境中表现出很大的动态性和不确定性。因此,固定向量无法描述不断演变的序列模式。因此作者这里学习表征的分布,采用多维椭圆高斯分布来描述不同的实体。
实体分布
多维椭圆高斯分布可以用均值和协方差来表示,均值来区分特征,协方差来控制不确定性。对于所有的商品,初始化均值表征
H^{\mu}=[h_1^{\mu},...,h_{|V|}^{\mu}],初始化协方差表征
H^{\sigma}=[h_1^{\sigma},...,h_{|V|}^{\sigma}],
|V|是item个数。那么行为序列中item的序列表征可以表示为
M_{S_u}^{\mu}=[h_{v_1^{u}}^{\mu},...,h_{v_L^{u}}^{\mu}] \\
M_{S_u}^{\sigma}=[h_{v_1^{u}}^{\sigma},...,h_{v_L^{u}}^{\sigma}]
同理可以得到用户,位置和行为类型的表征,即都初始化各自的均值和协方差,此处不赘述。
行为关系分布
由于每对行为转换都表现出异构的顺序依赖性(即不同行为之间的依赖性不同),因此需要考虑行为关系分布。一对行为类型之间的每个关系都被视为独立的分布表征,如两类行为
b_i和
b_j,则他们的依赖关系的均值的协方差表征为
r_{b_ib_j}^{\mu},
r_{b_ib_j}^{\sigma}。
2.1.2 个性化模式学习
本节设计了一种自适应高斯生成(SAGP),将统一的行为转换特征与个人特征相结合。用户和行为都是通过分布嵌入来表示的,其中均值向量决定全局特征,协方差向量指的是不确定性。个性化模式定义为下式,其中上标e,b,pt分别表示用户实体,行为实体和个性化模式实体。
\left[\mu_{u, i}^{p t}, \sigma_{u, i}^{p t}\right]=S A G P\left(\left[\mu_{u}^{e}, \sigma_{u}^{e}\right],\left[\mu_{i}^{b}, \sigma_{i}^{b}\right]\right)
SAGP的设计原则是从用户和行为的角度整合主要特征,并限制不确定性范围。融合均值向量如下式,
\mu_{u, i}^{p t}=\alpha_{1} \mu_{u}^{e}+\alpha_{2} \mathbf{W}_{\mu}^{b} \mu_{i}^{b}
其中
\alpha_{1}=\frac{\sigma_{i}^{b^{2}}}{\sigma_{i}^{b^{2}}+\sigma_{u}^{e^{2}}},
\alpha_{1}=\frac{\sigma_{i}^{e^{2}}}{\sigma_{i}^{b^{2}}+\sigma_{u}^{e^{2}}}。
\alpha是平衡来自用户和行为的影响,由于不同特征空间(即用户空间和行为空间)之间存在分布偏差,使用可学习的权重W来进行特征对齐。为了获得鲁棒的行为模式,需要提取强稳定性的判别特征,而较低的协方差表示更准确的分布,因此相对较大的协方差应该会对实体对最终模式产生较小的影响。通过下式融合用户和行为的分布的协方差,并且约束其上下限为
\left[\mathrm{Min}(\sigma_u^e,\sigma_i^b),\mathrm{Max}(\sigma_u^e,\sigma_i^b)\right]\sigma_{u,i}^{\boldsymbol{p}t}=\frac{2\sigma_{\boldsymbol{u}}^{\boldsymbol{e}2}\sigma_{\boldsymbol{i}}^{\boldsymbol{b}^2}}{\sigma_{\boldsymbol{u}}^{\boldsymbol{e}^2}+\sigma_{\boldsymbol{i}}^{\boldsymbol{b}^2}},
2.2 行为感知协作提取器
如前文所述,不用用户的行为模式不同,且item之间的写作关系也不同。因此本节提出了一种行为感知协作提取器来取代传统transformer中的普通注意力层。
2.2.1 行为协作影响因素
为了捕捉序列上下文中的行为转换语义,基于Wasserstein的方法来衡量行为协作影响因子。给定s位置和t位置的两个item
v_s^u,
v_t^u, 相应的行为是
b_s和
b_t。通过上文的SAGP结合用户和行为实体的分布,可以得到两个位置的模式
\mathcal{N}(\mu_{u,s}^{pt},\sigma_{u,s}^{pt}), \mathcal{N}(\mu_{u,t}^{pt},\sigma_{u,t}^{pt})对其进行映射后,计算Wasserstein距离(计算两个部分的距离)来衡量行为协作影响,其中x表示s或t
\mu_{u,x}^{ptc}=\mu_{u,x}^{pt}\mathbf{W}_{\mu}^{c},\quad\sigma_{u,x}^{ptc}=\mathbf{E}\mathbf{L}\mathbf{U}\left(\sigma_{u,x}^{pt}\mathbf{W}_{\sigma}^{c}\right)+1\\
\left.m_{s,t}^u=Wass\left(\begin{bmatrix}\mu_{u,s}^{ptc},\sigma_{u,s}^{ptc}\end{bmatrix}\right.,\begin{bmatrix}\mu_{u,t}^{ptc},\sigma_{u,t}^{ptc}\end{bmatrix}\right),
其中Wasserstein距离表示为下式
Wass_{12}=\|\mu_1-\mu_2\|_2^2+\mathrm{Tr}\left(\sigma_1+\sigma_2-2{\left(\sigma_1\right.}^{1/2}\sigma_1\sigma_2^{1/2}\right)^{1/2}.
得到表示模式之间的共同影响力系数m后,从关系对的集合中挑选出相应的行为关系表征(前面构造的两两行为关系的均值和协方差),将行为关系和行为模式结合起来得到下式,
\mu_{s,t}^{ip}=m_{s,t}^{u}r_{b_{s}b_{t}}^{\mu},\quad\sigma_{s,t}^{ip}=m_{s,t}^{u}r_{b_{s}b_{t}}^{\sigma}
2.2.2 融合行为感知注意力
本节引入了一种融合的行为感知注意力机制提取序列中的协作信息
位置增强的行为感知融合
为了实现多头注意力,要先对商品和行为的表征进行线性变换分别得到各自的qkv,这里以商品的query为例,同理可以得到其他的
\mu_s^Q=\mu_s^v\mathbf{W}_\mu^{QI}+\mu_s^b\mathbf{W}_\mu^{QB},\quad\sigma_s^Q=\mathbf{ELU}\left(\sigma_s^v\mathbf{W}_\sigma^{QI}+\sigma_s^b\mathbf{W}_\sigma^{QB}\right)+1,
对于传统的注意力层,点积通常用于计算商品之间的相关性,但不适用于推断高斯分布之间的距离。本节提出了一种位置增强的行为感知融合(PB Fusion),为混合分布表征设计,用于计算多行为交互对之间的差异。在SAGP的基础上提出TriSAGP,将SAGP扩展为三元的,在原有的基础上注入位置信息。(整体上和SAGP是类似的,就是多加个位置信息的表征),公式如下,
\begin{aligned}
&\left[\mu_{s}^{K^{\prime}},\sigma_{s}^{K^{\prime}}\right]=TriSAGP\left(\left[\mu_{s}^{K},\sigma_{s}^{K}\right],\left[\mu_{s,t}^{ip},\sigma_{s,t}^{ip}\right],\left[\mu_{s}^{p},\sigma_{s}^{p}\right]\right), \\
&\sigma_{\mathrm{s}}^{K^{\prime}}{}^{2}=\left(\frac{1}{\sigma_{\mathrm{s}}^{K^{2}}}+\frac{1}{\sigma_{s,t}^{ip^{2}}}+\frac{1}{\sigma_{s}^{p^{2}}}\right)^{-1},\mu_{\mathrm{s}}^{K^{\prime}}=\sigma_{\mathrm{s}}^{K^{\prime}}{}^{2}\cdot\left(\frac{\mu_{\mathrm{s}}^{K}}{\sigma_{\mathrm{s}}^{K^{2}}}+\mathbf{W}_{\mu}^{ip}\frac{\mu_{s,t}^{ip}}{\sigma_{s,t}^{ip^{2}}}+\mathbf{W}_{\mu}^{p}\frac{\mu_{s}^{p}}{\sigma_{s}^{p^{2}}}\right)
\end{aligned}
注意力聚合
使用前面得到的key和query,通过Wasserstein距离计算注意力得分为
\left.\alpha_{s,t}^u=-Wass\left(\begin{bmatrix}\mu_{s}^{K'},\sigma_{s}^{K'}\end{bmatrix}\right.,\begin{bmatrix}\mu_{t}^{Q'},\sigma_{t}^{Q'}\end{bmatrix}\right),,然后对得分进行归一化,之后进行加权求和:
x_t^\mu=\sum_{j=1}^L\frac{\alpha_{j,t}}{\sum_{i=1}^L\alpha_{i,t}}\mu_j^V,\quad x_t^\sigma=\sum_{j=1}^L\left(\frac{\alpha_{j,t}}{\sum_{i=1}^L\alpha_{i,t}}\right)^2\sigma_j^V.
然后在后面接FFN,类似transformer中一样,经过n层最后得到均值和协方差
X_{\mu}^{(n)},X_{\sigma}^{(n)}2.3 预测和训练
2.3.1 预测
在预测阶段,我们在前面已经得到了最终的均值和协方差的表征,在此基础上结合上用户在目标行为下的模式来细化表征
\left[\hat{x}_{t}^{\mu},\hat{x}_{t}^{\sigma}\right]=SAGP\left(\left[x_{t}^{\mu},x_{t}^{\sigma}\right],\left[\mu_{u,z}^{pt},\sigma_{u,z}^{pt}\right]\right),z表示目标行为,那
\left[\mu_{u,z}^{pt},\sigma_{u,z}^{pt}\right]其实也是通过SAGP得到的。最终的预测自然也是通过wass距离来计算相似度
\hat{\boldsymbol{y}}_{v_i,t+1}=-Wass\left(\left[\hat{x}_t^\mu,\hat{x}_t^\sigma\right],\left[\mu_i^v,\sigma_i^v\right]\right).
2.3.2 训练
采用Cloze任务作为训练目标,在这种多行为序列的情况下,对于每个训练step,随机在序列中屏蔽
\rho比例的商品,即用[𝑚𝑎𝑠𝑘]替换item,但是保持对应的行为token不被mask。模型基于序列上下文和目标行为模式对mask商品进行预测。损失函数为交叉熵损失
\mathcal{L}_{pre}=\sum_{S_u\in\mathcal{S}}\sum_{t\in\mathcal{P}_m}\sum_{v_j\notin\mathcal{S}_u}-\left[\log\left(\sigma\left(\hat{\boldsymbol{y}}_{v_t,t}\right)\right)+\log\left(1-\sigma\left(\hat{\boldsymbol{y}}_{v_j,t}\right)\right)\right],
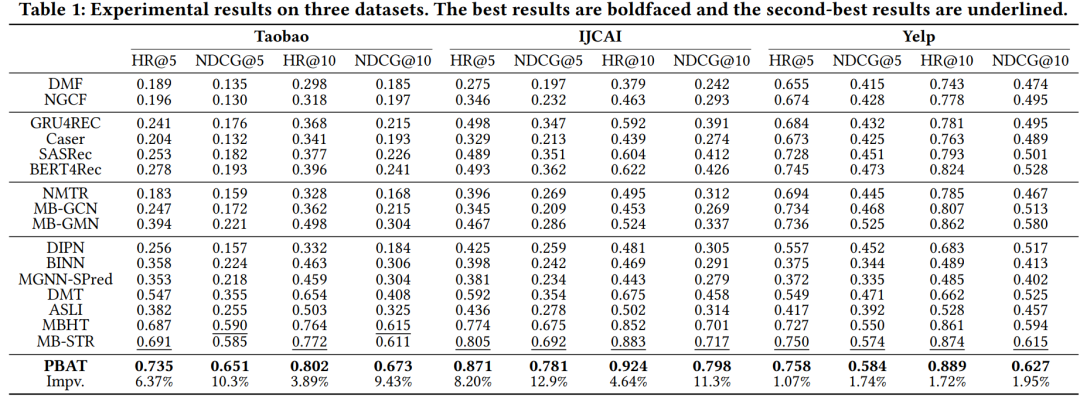
3. 结果