加菲猫的AI大模型初体验


话说加菲猫捡垃圾,买了矿卡P108组装了一台跑AI模型的机器,就开始AI大模型学习之路了。
学习大模型离不了python3,pip3.CUDA
当然是先安装好它们了。安装过程就不讲啦,以后会整理课件吧。
这次要搭建的项目是清华开源项目 ChatGLM2-6B
这一项目可以直接部署在本地做测试,无需联网即可体验与AI 聊天的乐趣,当然我这个攒垃极的机器也能跑起来。
项目地址:
GitHub:https://github.com/THUDM/ChatGLM2-6B
Hugging Face:https://huggingface.co/THUDM/chatglm2-6bChatGLM2-6B 是开源中英双语对话模型 ChatGLM-6B 的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,ChatGLM2-6B 引入了如下新特性:
更强大的性能:基于 ChatGLM 初代模型的开发经验,我们全面升级了 ChatGLM2-6B 的基座模型。ChatGLM2-6B 使用了 GLM 的混合目标函数,经过了 1.4T 中英标识符的预训练与人类偏好对齐训练,评测结果显示,相比于初代模型,ChatGLM2-6B 在 MMLU(+23%)、CEval(+33%)、GSM8K(+571%) 、BBH(+60%)等数据集上的性能取得了大幅度的提升,在同尺寸开源模型中具有较强的竞争力。
更长的上下文:基于 FlashAttention 技术,我们将基座模型的上下文长度(Context Length)由 ChatGLM-6B 的 2K 扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练,允许更多轮次的对话。但当前版本的 ChatGLM2-6B 对单轮超长文档的理解能力有限,我们会在后续迭代升级中着重进行优化。
更高效的推理:基于 Multi-Query Attention 技术,ChatGLM2-6B 有更高效的推理速度和更低的显存占用:在官方的模型实现下,推理速度相比初代提升了 42%,INT4 量化下,6G 显存支持的对话长度由 1K 提升到了 8K。
更开放的协议:ChatGLM2-6B 权重对学术研究完全开放,在填写问卷进行登记后亦允许免费商业使用。
直接下载github项目下来并解压
或者用GIT工具下载下来。
git clone https://github.com/THUDM/ChatGLM2-6B
cd ChatGLM2-6B
模型放在chatglm2-6b文件夹下,模型一般都体积非常大,耐心等待。
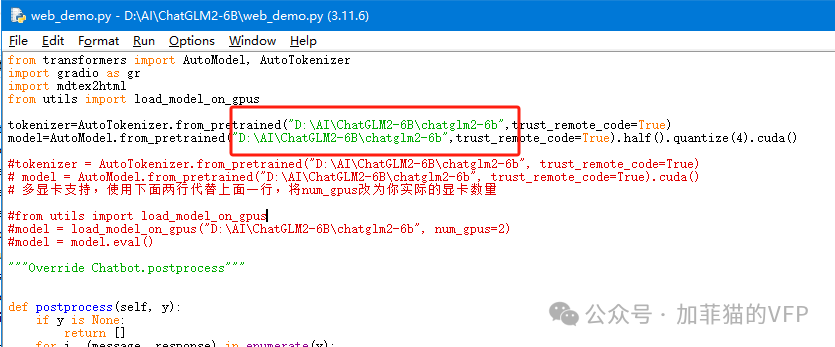
打开web_demo.py 如下图修改一下模型路径
进入命令行模式跑一下看看
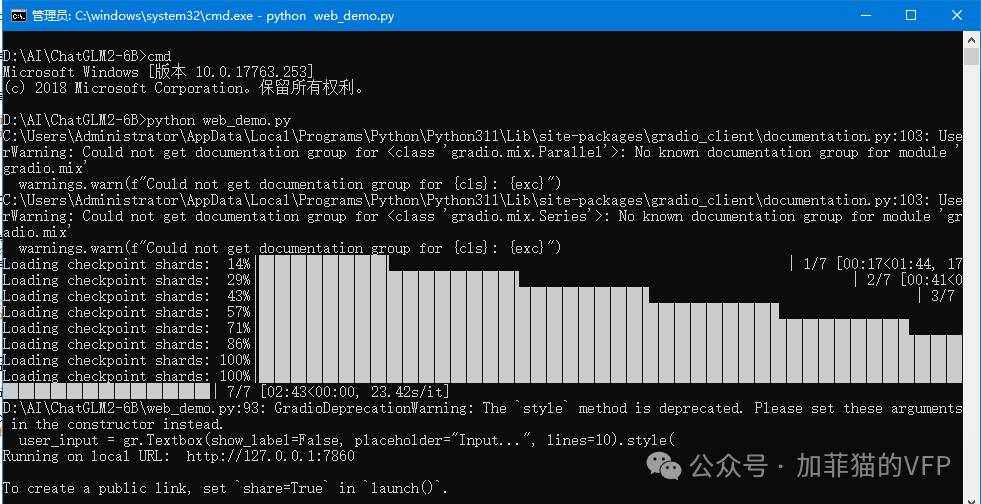
貌似有个小警告,但成功启动了。
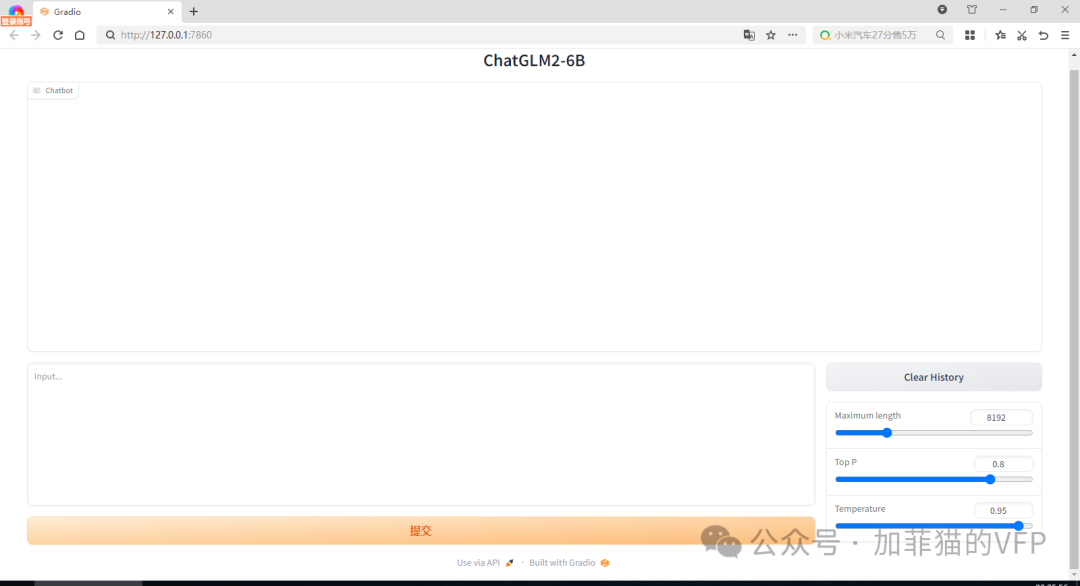
我问一下它,加菲猫的VFP是做什么的?

目前是一个一本正经胡说八道的家伙。
那我们要开始调教这个模型啦。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-03-29,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号