kotlin 协程入门教程


链接:https://juejin.cn/post/7370994785655767067
本文由作者授权发布
协程是什么
在广义的定义上,协程(Coroutine)是指相互协作的程序。对于初学协程的人来说,这个定义其实比较难理解。因此很多的文章在介绍 kotlin 的协程时,经常会把协程比作轻量级的Java线程。
但是我认为这种比喻不对,更好的解释是kotlin 的协程其实是 kotlin 线程池中的一个任务(Task);我们能执行协程操作,其实是因为调用了协程框架的接口,该协程框架是对线程池的进一步封装。
明白这一点后,你可能会问,为什么kotlin要重复造轮子,java线程池不好吗?kotlin协程相对于我们使用java线程池有什么优势吗?
为什么不直接使用Java线程池
这里需要提前说明一下,kotlin 协程封装的线程池与 java 的线程池是不一样的。Java 中的线程池是 ThreadPoolExecutor,而在 kotlin 中的线程池是 CoroutineScheduler。两种都实现了线程池的功能,但是它们实现的方式是不一样的。大概的原理如下图所示:
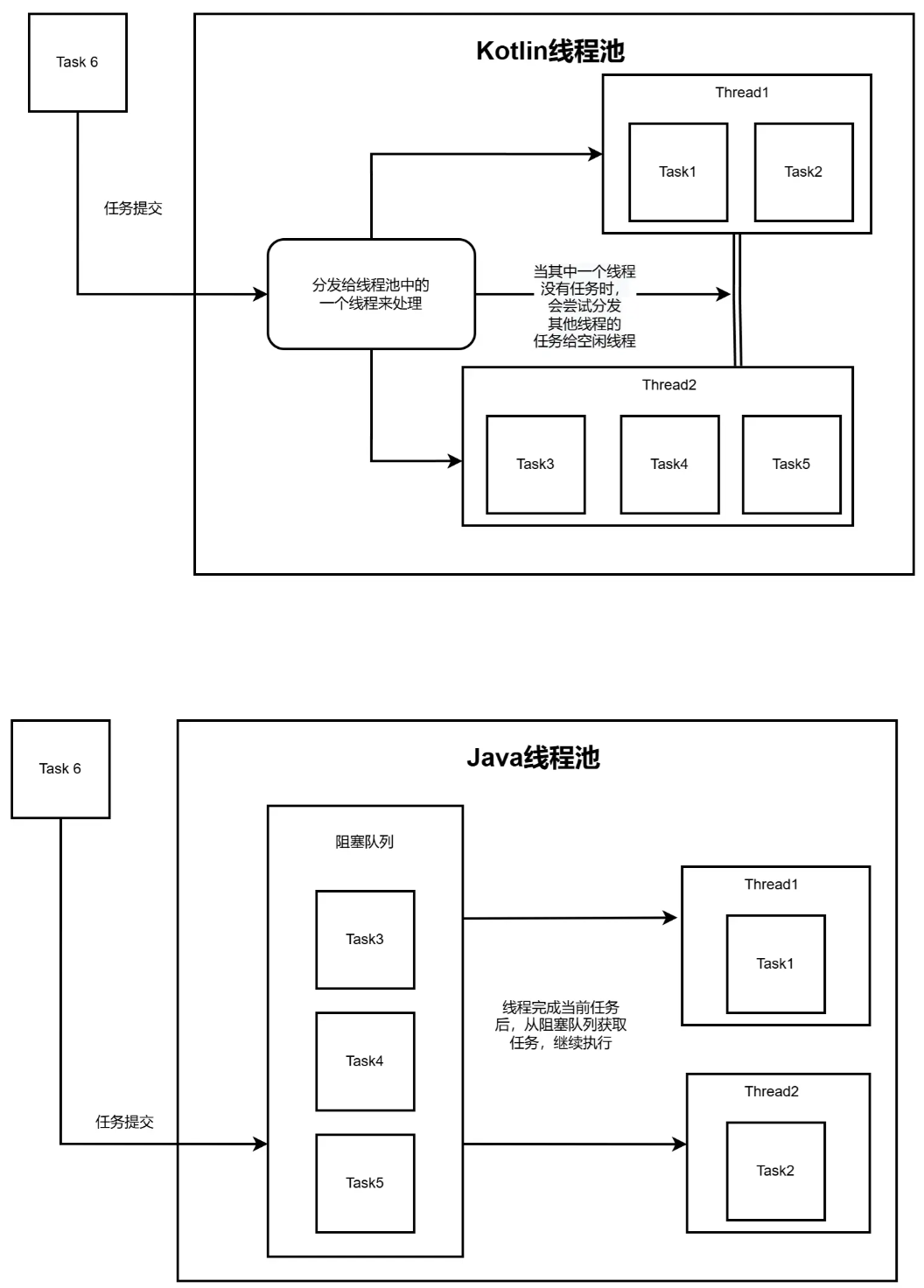
可以看到,Java线程池的实现是通过阻塞队列存储任务,然后线程不断地执行任务;而 kotlin 的线程池,则是线程中存储任务,kotlin线程池负责调度任务。除此之外,当其中一个线程没有任务时,kotlin线程池则会尝试分发其他线程的任务给空闲线程。至于这么做有什么好处,官方给的答案是以最有效的方式在工作线程上分发已调度的任务。
协程相对java线程池的优势是什么
其实 kotlin 协程的核心优势有三个,分别是:轻量、挂起函数以及结构化并发。轻量 ,很多文章都说过,这里不多介绍。至于 挂起函数 通过挂起与恢复解决了开发过程中的回调地狱问题。而结构化并发 则可以对一组协程进行统一的操作。关于它们的详细介绍,可以继续往下面看。
协程的创建
fun main() {
GlobalScope.launch {
delay(1000)
println("launch over")
}
println("main over")
Thread.sleep(1500)
}
//执行结果:
main over
launch over
在 kotlin 的协程框架中,提供了 launch 、async、runBlocking 三个方法来创建协程, launch 、async是 CoroutineScope的扩展方法,它们的区别是,async 可以获取协程执行的结果,而 launch 不行。runBlocking 则是一个顶层方法,它可以获取协程的执行结果,但这种方式会阻塞代码的执行流程,因此只建议在测试中使用。上面的代码示例是使用 launch 来创建协程。
public fun CoroutineScope.launch(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> Unit
): Job
launch 扩展方法如上代码所示。这里有几个点需要关注,分别是 CoroutineScope、CoroutineContext、CoroutineStart 以及带接收者的挂起函数(block)
- CoroutineScope 是协程的作用域,主要作用是用来追踪协程的。把协程看作任务的话,CoroutineScope 其实就是 TaskManager,负责管理所有通过它创建的协程。上面的代码示例中,GlobalScope 就是 CoroutineScope 的一个子类,表示的是全局作用域。需要注意:所有协程都需要通过 CoroutineScope 来启动。
- CoroutineContext 是指协程的上下文。不同于 Android 中 Context,CoroutineContext 的功能更像一个 Map,它内部包含多种类型的元素。
- CoroutineStart 是指协程的启动选项,有DEFAULT、LAZY、ATOMIC、UNDISPATCHED四种。DEFAULT 是默认的选项,指创建协程后立即启动;而LAZY 则是延迟启动。另外两个则使用得比较少
- block 是指带接收者的挂起函数,是 kotlin 的语法糖,它其实等同于suspend CoroutineScope(self: CoroutineScope) -> Unit。这里重要的不是语法糖,而是 suspend ,它表明该函数是挂起函数。
协程的组成部分
kotlin协程框架主要由三部分组成:CoroutineScope(协程作用域)、CoroutineContext(协程上下文)、挂起函数。下面我们分别来介绍。
挂起函数
挂起函数是指方法声明前加上 suspend 关键字的函数。它的作用主要是挂起与恢复。其实说挂起和恢复比较难理解,其实简单的说挂起就是协程任务从当前线程脱离,恢复则是协程任务回到了原线程。下面是常见的网络请求代码示例。
fun test() {
println("${Thread.currentThread().name} start")
GlobalScope.launch(Dispatchers.Main) {
println("${Thread.currentThread().name} launch start")//main线程
val result = getData()//子线程
println("${Thread.currentThread().name} launch over $result")//main线程
}
println("${Thread.currentThread().name} do other thing")
}
//模拟网络请求
suspend fun getData() = withContext(Dispatchers.IO) {
println("${Thread.currentThread().name} load data")
delay(1000)
"data"//模拟获取的数据
}
//执行结果为
main start
main do other thing
main launch start
DefaultDispatcher-worker-1 load data
main launch over data
可以看到当调用 getData 这个挂起函数时,协程会从主线程会切换到子线程,并执行网络请求任务;当请求任务执行完成后则回到了主线程。由于 kotlin 协程框架主动帮我们回到了原线程,这样我们就不需要写 Callback 来回调了。而是可以使用同步代码来完成异步的操作。
CoroutineScope(协程作用域)
前面简单介绍过,CoroutineScope 是协程的作用域,主要作用是用来追踪协程,方便我们批量地控制协程。CoroutineScope 可以分成两种:
- GlobalScope,是指全局协程作用域,通过它创建的协程可以一直运行直到应用停止运行。GlobalScope 本身不会阻塞当前线程,且启动的协程相当于守护线程,不会阻止 JVM 结束运行。一般不建议使用
- 自定义 CoroutineScope,可用于实现主动控制协程的生命周期范围,比如 lifecycleScope、viewModelScope。开发中一般是使用它们来确保生命周期安全,避免内存泄露。
public interface CoroutineScope {
public val coroutineContext: CoroutineContext
}
CoroutineScope 的接口如上所示。可以看到其实 CoroutineScope 本身并没定义批量地控制协程的方法,其核心是使用 CoroutineContext 来实现的。接下来我们就看看 CoroutineContext,它可以说是 kotlin 协程的核心了。
CoroutineContext(协程上下文)
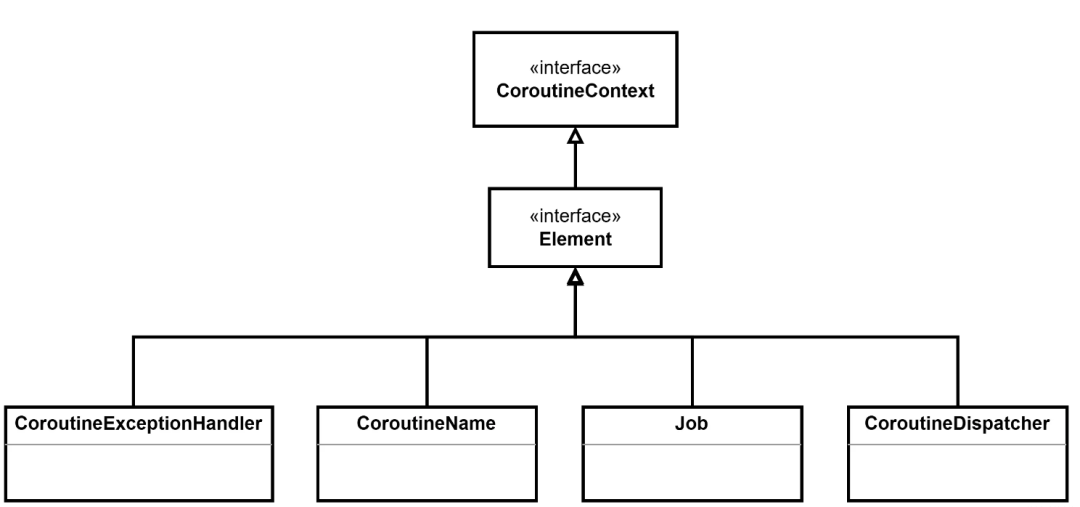
前文提到过,CoroutineContext 的功能类似一个 Map,它内部包含多种类型的元素。其核心功能就是内部的元素实现的。CoroutineContext 中最常用的有四种元素,分别是:
- Job:可以监测并操控协程
- CoroutineName:协程的名称,一般用于调试
- CoroutineDispatcher:用于将协程任务分发到要求的线程上
- CoroutineExceptionHandler:处理未捕获的异常
它们与 CoroutineContext 的关系如下图所示:
Job
Job 可以监测并操控协程,可以说是协程的句柄。Job的获取有三种方式,分别是通过 CoroutineContext 获取、通过 launch、async 的返回值获取。代码示例如下:
//通过 CoroutineContext 获取
coroutineContext.job //等同于 coroutineContext[Job]
//通过 launch 返回值获取
val job:Job = scope.launch {
...
}
//通过 async 返回值获取。Deferred 是 Job 的子类
//相比 Job 多了 await 方法来获取协程的返回值
val deferred: Deferred = scope.async {
...
}
获取到 Job 后,我们就可以通过它来监听当前协程的状态。代码如下所示:
job.isActive //是否活跃
job.isCancelled //是否被取消
job.isCompleted //是否执行完成
job.invokeOnCompletion { //协程执行完后回调
}
除此之外,还可以使用 Job 来操控协程。代码示例如下:
job.start() //启动协程,一般用作 CoroutineStart.LAZY 懒加载模式下启动协程
job.cancel() //取消协程
job.join() //阻塞等待直到此 Job 结束运行
deferred.await() //阻塞等待直到获取协程的执行结果
前面我们提到过,kotlin 协程的一大特点就是结构化并发。它也是通过 Job 来实现的。不同于java多线程,在kotlin 协程中,有父子协程的概念。代码示例如下:
val parentJob = GlobalScope.launch {//父协程
val job1 = launch { // 子协程1
}
val job2 = launch { //子协程2
}
}
parentJob.join() //会等待所有子协程执行完毕
parentJob.cancel() //会取消所有子协程
通过控制父协程,从而控制它的一堆子协程。这就是 kotlin 协程中的结构化并发。
CoroutineName
CoroutineName 用来表示协程的名称,一般用于调试或者打印日志。代码示例如下:kotlin复制代码GlobalScope.launch(CoroutineName("parent")) {//父协程
val job1 = launch(CoroutineName("child1")) { // 子协程1
}
val job2 = launch(CoroutineName("child2")) { //子协程2
}
}
CoroutineDispatcher
CoroutineDispatcher 用于将协程任务分发到要求的线程上。Kotlin 协程框架提供了四个 Dispatcher 用于指定在哪一类线程中执行协程。
- Dispatchers.Default,默认调度器,它是用于 CPU 密集型任务的线程池。一般来说,它内部的线程 个数是与机器 CPU 核心数量保持一致的,不过它有一个最小限制 2
- Dispatchers.IO,它是用于 IO 密集型任务的线程池。它内部的线程数量一般会更多一些
- Dispatchers.Unconfined,对执行协程的线程不做限制,可以直接在当前调度器所在线程上执行
- Dispatchers.Main,在Android中,表示UI线程
除此之外,还可以使用 newSingleThreadContext 新创建一个线程来执行协程的调度,或者自定义一个 Java 线程池来执行协程调度。代码示例如下:
//使用 newSingleThreadContext 新建一个线程
GlobalScope.launch(newSingleThreadContext("name")) {
}
//使用Java中的线程池
GlobalScope.launch(Executors.newCachedThreadPool().asCoroutineDispatcher()) {
}
CoroutineExceptionHandler
CoroutineExceptionHandler 用来处理未捕获的异常。代码示例如下:
kotlin复制代码val handle = CoroutineExceptionHandler { coroutineContext, throwable ->
println("处理异常")
}
GlobalScope.launch(handle) {
throw NullPointerException()
}
需要注意的是:使用 CoroutineExceptionHandler 处理复杂结构的协程异常时,它仅在顶层协程中起作用。
协程中的异常
由于协程的本质是线程池的任务,并且协程本身是结构化的,这就导致它的异常处理机制与我们普通的程序完全不一样。下面将介绍我们处理协程异常需要注意的点。
不要用 try-catch 直接包裹 launch、async
try {
GlobalScope.launch {
throw NullPointerException()
}
} catch (e: NullPointerException) {
println("catch exception")
}
这种方式是没有效果的,"catch exception 不会被打印。这是因为协程本质是线程池的任务,try-catch 包裹的相当于是 summit(Task()),因此没有效果。如果想要用try-catch 处理异常。你需要放到协程里面去。代码示例如下:
GlobalScope.launch {
try {
throw NullPointerException()
} catch (e: NullPointerException) {
println("catch exception")
}
}
cancel 和 CancellationException
如果你了解过 java 中的 interrupt 方法,理解 cancel 和 CancellationException 就简单了。其实 cancel 和 interrupt 一样对于协程的取消需要内部的配合。代码示例如下:
val job = launch(Dispatchers.Default) {
var i = 0
while (isActive) {
Thread.sleep(500L)
i ++
println("i = $i")
}
}
delay(2000L)
job.cancel()
当我们调用 job.cancel 方法时,isActive 会变为 false,这样协程里面的程序才会退出。至于为什么协程提供的挂起函数,像delay,可以自动响应协程的取消呢?这是因为它们会自动检测当前协程是否已经被取消了,如果已经被取消了,就会抛出 CancellationException 异常,从而终止当前的协程。
协程中异常的传播
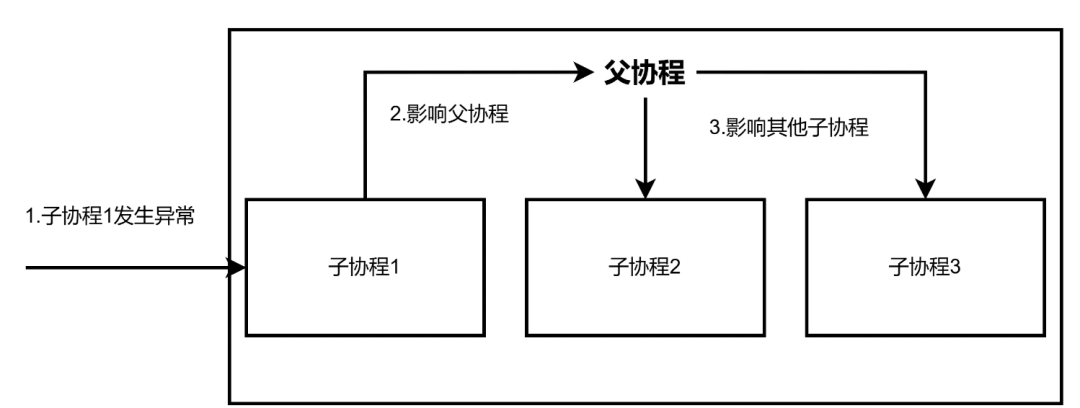
之前讲过协程存在父子结构。由于协程的这个特点,导致了一个协程的异常会影响到其他所有的协程。如下图所示,当子协程1发生异常时,它会先会传递给父协程,再从父协程传播到子协程2和3,从而影响所有的协程。
如果想要子协程1发生异常时,不影响其他的协程,可以使用 SupervisorJob。代码示例如下:
val parentJob = Job()
GlobalScope.launch(parentJob) {
val job1 = launch(SupervisorJob(parentJob)) {
1 / 0
println("job1 over")
}
val job2 = launch {
delay(1000)
println("job2 over")
}
val job3 = launch {
delay(1500)
println("job3 over")
}
}
当协程1抛出异常时,协程2和协程3都能正常打印。这里需要注意的是使用 SupervisorJob(parentJob),而不要使用 SupervisorJob()。这是为了确保协程1和 parentJob 还是父子关系。
如果使用了SupervisorJob(),协程1和 parentJob 就不是父子结构了,这时虽然协程1抛出异常,由于不是父子关系了就不会影响其他协程,但是同时parentJob.cancel 和 join方法也无法影响到协程1了。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-05-27,如有侵权请联系 cloudcommunity@tencent.com 删除
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号