使用高级SQL向量查询增强您的 RAG 应用程序


通过使用 MyScale 和 LangChain 创建 AI 助手来克服 RAG 的限制,以提高数据检索过程的准确性和效率。
译自 Enhance Your RAG Application With Advanced SQL Vector Queries,作者 Usama Jamil。
检索增强生成 (RAG) 彻底改变了我们与数据交互的方式,在相似性搜索中提供了无与伦比的性能。它擅长根据简单查询检索相关信息。但是,RAG 在处理更复杂的任务(例如基于时间的查询或复杂的关联数据库查询)时常常力不从心。这是因为 RAG 主要设计用于使用来自外部来源的相关信息进行增强文本生成,而不是执行基于条件的精确检索。这些限制 限制了它在需要精确和条件数据检索的场景中的应用。
我们的高级 RAG 模型基于 SQL 向量数据库,将有效管理各种查询类型。它不仅可以处理简单的相似性搜索,还擅长基于时间的查询和复杂的关联查询。
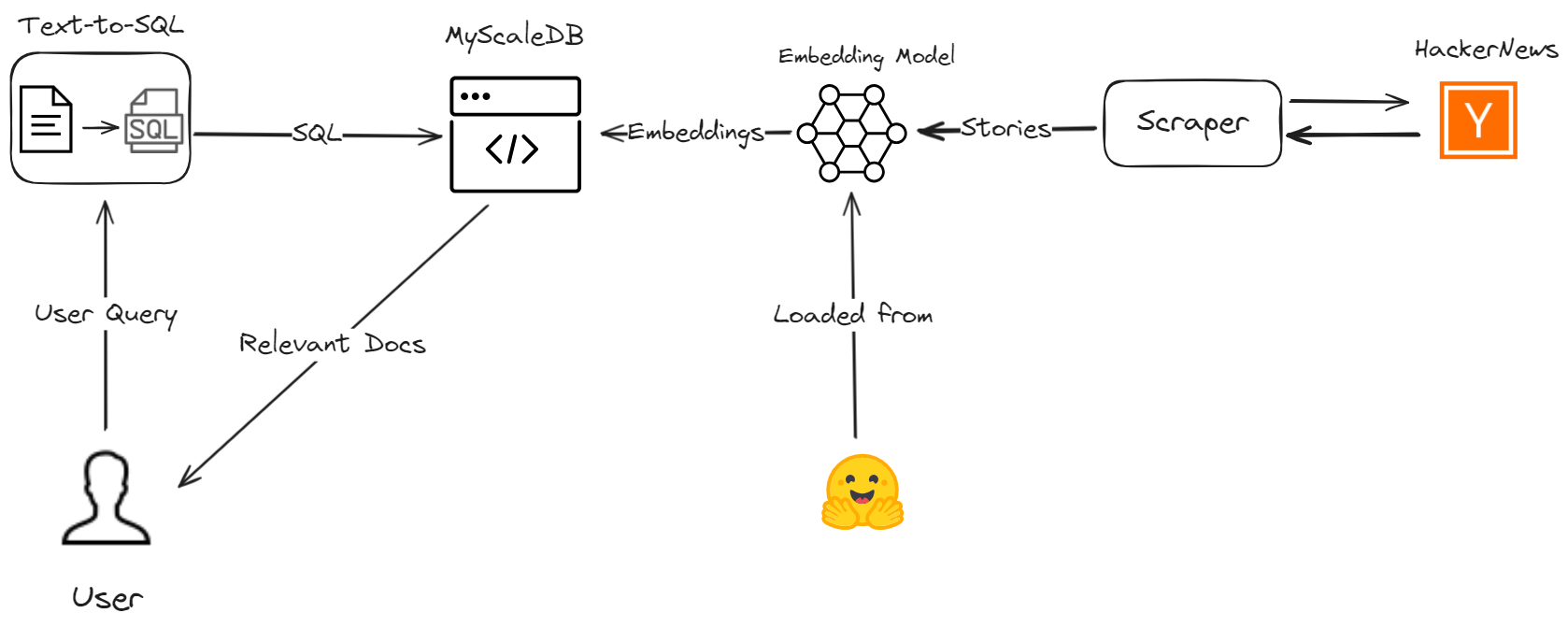
让我们讨论一下如何使用 MyScale 和 LangChain 创建 AI 助手来克服这些 RAG 限制,从而提高数据检索过程的准确性和效率。我们将抓取 Hacker News 的最新故事,同时指导您完成该过程,以演示如何使用高级 SQL 向量查询增强您的 RAG 应用程序。
工具和技术
我们将使用多种工具,包括 MyScaleDB、OpenAI、LangChain、Hugging Face 和 HackerNews API 来开发此有用应用程序。
- MyScaleDB:MyScale 是一个 SQL 向量数据库,可以高效地存储和处理结构化和非结构化数据。
- OpenAI:我们将使用 OpenAI 的聊天模型生成文本到 SQL 查询。
- LangChain:LangChain 将帮助构建工作流并与 MyScale 和 OpenAI 无缝集成。
- Hugging Face:我们将使用 Hugging Face 的嵌入模型获取文本嵌入,这些嵌入将存储在 MyScale 中以供进一步分析。
- HackerNews API:此 API 将从 HackerNews 获取实时数据以进行处理和分析。
准备
设置环境
在开始编写代码之前,我们必须确保安装了所有必需的库和依赖项。您可以使用以下方法安装它们:
pip install requests clickhouse-connect transformers openai langchain此 pip 命令应安装此项目中所需的所有依赖项。
导入库并定义辅助函数
首先,我们将导入必要的库并定义用于从 Hacker News 获取和处理数据的辅助函数。
import requests
from datetime import datetime, timedelta
import pandas as pd
import numpy as np
# Fetch story IDs from a specific endpoint
def fetch_story_ids(endpoint):
url = f'https://hacker-news.firebaseio.com/v0/{endpoint}.json'
response = requests.get(url)
return response.json()
# Get details of a specific item by ID
def get_item_details(item_id):
item_url = f'https://hacker-news.firebaseio.com/v0/item/{item_id}.json'
item_response = requests.get(item_url)
return item_response.json()
# Recursively fetch comments for a story
def fetch_comments(comment_ids, depth=0):
comments = []
for comment_id in comment_ids:
comment_details = get_item_details(comment_id)
if comment_details and comment_details.get('type') == 'comment':
comment_text = comment_details.get('text', '[deleted]')
comment_by = comment_details.get('by', 'Anonymous')
indent = ' ' * depth * 2
comments.append(f"{indent}Comment by {comment_by}: {comment_text}")
if 'kids' in comment_details:
comments.extend(fetch_comments(comment_details['kids'], depth + 1))
return comments
# Convert list of comments to a single string
def create_comment_string(comments):
return ' '.join(comments)
# Set the time limit to 12 hours ago
time_limit = datetime.utcnow() - timedelta(hours=12)
unix_time_limit = int(time_limit.timestamp())这些函数获取故事 ID,获取特定项目的详细信息,递归获取评论并将评论转换为单个字符串。
获取和处理故事
接下来,我们从 Hacker News 获取最新和最热门的故事,并处理它们以提取相关数据。
# Fetch latest and top stories
latest_stories_ids = fetch_story_ids('newstories')
top_stories_ids = fetch_story_ids('topstories')
# Fetch top 20 stories
top_stories = [get_item_details(story_id) for story_id in top_stories_ids[:20]]
# Fetch all latest stories from the last 12 hours
latest_stories = [get_item_details(story_id) for story_id in latest_stories_ids if get_item_details(story_id).get('time', 0) >= unix_time_limit]
# Prepare data for DataFrame
data = []
def process_stories(stories):
for story in stories:
if story:
story_time = datetime.utcfromtimestamp(story.get('time', 0))
if story_time >= time_limit:
story_data = {
'Title': story.get('title', 'No Title'),
'URL': story.get('url', 'No URL'),
'Score': story.get('score', 0),
'Time': convert_unix_to_datetime(story.get('time', 0)),
'Writer': story.get('by', 'Anonymous'),
'Comments': story.get('descendants', 0) # Correctly handle the number of comments
}
# Fetch comments if any
if 'kids' in story:
comments = fetch_comments(story['kids'])
story_data['Comments_String'] = create_comment_string(comments)
else:
story_data['Comments_String'] = ""
data.append(story_data)
# Process latest and top stories
process_stories(latest_stories)
process_stories(top_stories)
# Create DataFrame
df = pd.DataFrame(data)
# Ensure correct data types
df['Score'] = df['Score'].astype(np.uint64)
df['Comments'] = df['Comments'].astype(np.uint64)
df['Time'] = pd.to_datetime(df['Time'])我们使用上述定义的辅助函数从 Hacker News 获取最新和最热门的故事。我们处理获取的故事以提取相关信息,如标题、URL、分数、时间、作者和评论。我们还将评论列表转换为单个字符串。
初始化用于嵌入的 Hugging Face 模型
我们现在将使用预训练模型为故事标题和评论生成嵌入。此步骤对于创建 RAG 系统至关重要。
import torch
from transformers import AutoTokenizer, AutoModel
# Initialize the tokenizer and model for embeddings
tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
model = AutoModel.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
# Generate embeddings after DataFrame is created
empty_embedding = np.zeros(384, dtype=np.float32) # Assuming the embedding size is 384
def generate_embeddings(texts):
inputs = tokenizer(texts, padding=True, truncation=True, return_tensors="pt", max_length=512)
with torch.no_grad():
outputs = model(**inputs)
embeddings = outputs.last_hidden_state.mean(dim=1)
return embeddings.numpy().astype(np.float32).flatten()我们将使用 Hugging Face transformers 库加载用于生成嵌入的预训练模型,并为故事标题和评论生成嵌入。
处理长评论
为了处理超出模型最大令牌长度的长评论,我们将它们拆分为可管理的部分。
# Function to handle long comments
def handle_long_comments(comments, max_length):
parts = [' '.join(comments[i:i + max_length]) for i in range(0, len(comments), max_length)]
return parts此函数将长评论拆分为适合模型最大令牌长度的部分。
处理故事以进行嵌入
最后,我们将处理每个故事以生成标题和评论的嵌入,并创建一个最终的 Pandas DataFrame。
# Process each story for embeddings
final_data = []
for story in data:
title_embedding = generate_embeddings([story['Title']]).tolist()
comments_string = story['Comments_String']
if comments_string and isinstance(comments_string, str):
max_length = tokenizer.model_max_length # Use the model's max token length
if len(comments_string.split()) > max_length:
parts = handle_long_comments(comments_string.split(), max_length)
for part in parts:
part_comments_string = ' '.join(part)
comments_embeddings = generate_embeddings([part_comments_string]).tolist() if part_comments_string else empty_embedding.tolist()
final_data.append({
'Title': story['Title'],
'URL': story['URL'],
'Score': story['Score'],
'Time': story['Time'],
'Writer': story['Writer'],
'Comments': story['Comments'],
'Comments_String': part_comments_string,
'Title_Embedding': title_embedding,
'Comments_Embedding': comments_embeddings
})
else:
comments_embeddings = generate_embeddings([comments_string]).tolist() if comments_string else empty_embedding.tolist()
final_data.append({
'Title': story['Title'],
'URL': story['URL'],
'Score': story['Score'],
'Time': story['Time'],
'Writer': story['Writer'],
'Comments': story['Comments'],
'Comments_String': comments_string,
'Title_Embedding': title_embedding,
'Comments_Embedding': comments_embeddings
})
else:
story['Title_Embedding'] = title_embedding
story['Comments_Embedding'] = empty_embedding.tolist()
final_data.append(story)
# Create final DataFrame
final_df = pd.DataFrame(final_data)
# Ensure correct data types in the final DataFrame
final_df['Score'] = final_df['Score'].astype(np.uint64)
final_df['Comments'] = final_df['Comments'].astype(np.uint64)
final_df['Time'] = pd.to_datetime(final_df['Time'])在此步骤中,我们处理每个故事以生成标题和评论的嵌入,在必要时处理长评论,并使用所有处理后的数据创建一个最终的 DataFrame。
连接到 MyScaleDB 并创建表
MyScaleDB 是一款先进的 SQL 向量数据库,通过高效处理全文搜索和过滤向量搜索等复杂查询和相似性搜索强化了 RAG 模型。
我们将使用 ClickHouse-Connect 连接到 MyScaleDB 并在其中创建一张表用来存储爬取到的故事。
import clickhouse_connect
client = clickhouse_connect.get_client(
host='your-host',
port=443,
username='your-username',
password='your-password'
)
client.command("DROP TABLE IF EXISTS default.posts")
client.command("""
CREATE TABLE default.posts (
id UInt64,
Title String,
URL String,
Score UInt64,
Time DateTime64,
Writer String,
Comments UInt64,
Title_Embedding Array(Float32),
Comments_Embedding Array(Float32),
CONSTRAINT check_data_length CHECK length(Title_Embedding) = 384
) ENGINE = MergeTree()
ORDER BY id
""")此代码导入 clickhouse-connect 库并使用提供的凭证建立与 MyScaleDB 的连接。如果已有默认表格 default.posts ,将删除它们,并使用指定架构创建一个新表格。
注:MyScaleDB 提供一个用于保存 500 万向量的免费 pod,以便您可以立即在 RAG 应用程序中使用 MyScaleDB,无需预先付款。
高效处理复杂查询
高效处理复杂查询 和相似性搜索,例如 全文搜索 和 过滤向量搜索。
我们将使用 clickhouse-connect 连接到 MyScaleDB,并创建一个表来存储抓取的故事。
此代码导入 clickhouse-connect 库,并使用提供的凭据建立与 MyScaleDB 的连接。如果存在,它将删除现有的表 default.posts,并使用指定架构创建一个新表。
注意: MyScaleDB 为 500 万个向量的向量存储提供了一个免费的 pod。因此,你可以在你的 RAG 应用程序中开始使用 MyScaleDB,而无需任何初始付款。
插入数据和创建向量索引
现在,我们将处理后的数据插入 MyScaleDB 表,并创建一个索引以实现高效的数据检索。
batch_size = 20 # Adjust based on your needs
num_batches = len(final_df) // batch_size
for i in range(num_batches):
start_idx = i * batch_size
end_idx = start_idx + batch_size
batch_data = final_df[start_idx:end_idx]
client.insert("default.posts", batch_data, column_names=['Title', 'URL', 'Score', "Time",'Writer', 'Comments','Title_Embedding','Comments_Embedding'])
print(f"Batch {i+1}/{num_batches} inserted.")
client.command("""
ALTER TABLE default.posts
ADD VECTOR INDEX photo_embed_index Title_Embedding
TYPE MSTG
('metric_type=Cosine')
""")此代码将数据批量插入 default.posts 表中,以高效管理大量数据。向量索引在 Title_Embedding 列上创建。
设置查询生成提示模板
我们将设置一个提示模板,将自然语言查询转换为 MyScaleDB SQL 查询。
prompt_template = """
You are a MyScaleDB expert. Given an input question, first create a syntactically correct MyScaleDB query to run, then look at the results of the query and return the answer to the input question.
MyScaleDB queries have a vector distance function called `DISTANCE(column, array)` to compute relevance to the user's question and sort the feature array column by relevance. The `DISTANCE(column, array)` function only accepts an array column as its first argument and a `Embeddings(entity)` as its second argument. You also need a user-defined function called `Embeddings(entity)` to retrieve the entity's array.
When the query is asking for the closest rows based on a certain keyword (e.g., "AI field" or "criticizing"), you have to use this distance function to calculate the distance to the entity's array in the vector column and order by the distance to retrieve relevant rows. If the question involves time constraints (e.g., "last 7 hours"), use the `today()` function to get the current date and time.
If the question specifies the number of examples to obtain, use that number; otherwise, query for at most {top_k} results using the LIMIT clause as per MyScale. Only order according to the distance function when necessary. Never query for all columns from a table; query only the columns needed to answer the question, and wrap each column name in double quotes (") to denote them as delimited identifiers.
Be careful to use only the column names present in the tables below and ensure you know which column belongs to which table. The `ORDER BY` clause should always be after the `WHERE` clause. Do not add a semicolon to the end of the SQL.
Pay attention to the following steps when constructing the query:
1. Identify keywords in the input question (e.g., "most voted articles," "last 7 hours," "AI field").
2. Map keywords to specific query components (e.g., "most voted" maps to "Score DESC").
3. If the question involves relevance to a keyword (e.g., "criticizing"), use the distance function. Otherwise, use standard SQL clauses.
4. If the question mentions the title or comments specifically, calculate the distance accordingly. By default, calculate distance with the title.
5. Use `Embeddings(keyword)` to get embeddings for keywords and use them in the `DISTANCE` function only when the query involves a keyword relevance search.
6. Ensure to consider the comments column if explicitly mentioned in the question.
7. Don't use dist in a query where you haven't found any distance and make sure to use order by dist with other columns as well where the distance is calculated
Example questions and how to handle them:
1. "What are the most voted articles during the last 7 hours in the AI field?"
- Extract keywords: "most voted articles," "last 7 hours," "AI field."
- Map "most voted" to "Score DESC."
- Construct query for the most voted articles in the last 7 hours:
- `SELECT DISTINCT "Title", "URL", "Score", DISTANCE("Title_Embedding", Embeddings('AI field')) FROM posts1 WHERE Time >= today() - INTERVAL 7 HOUR ORDER BY Score DESC LIMIT {top_k}`
2. "Give me some comments where people are criticizing the content?"
- Extract keywords: "comments," "criticizing."
- Map "criticizing" to DISTANCE function.
- Construct query for relevant comments:
- `SELECT DISTINCT "Comments", "Score", DISTANCE("Comments_Embedding", Embeddings('criticizing')) as dist FROM posts1 ORDER BY dist LIMIT {top_k}`
3. "What were the top voted stories during the last 6 hours?"
- Extract keywords: "top voted stories," "last 6 hours."
- Map "top voted" to "Score DESC."
- Construct a simple query for the top voted stories in the last 6 hours:
- `SELECT DISTINCT "Title", "URL", "Score" FROM posts1 WHERE Time >= today() - INTERVAL 6 HOUR ORDER BY Score DESC LIMIT {top_k}`
4. "What are the trending stories in the AI field?"
- Extract keywords: "trending stories," "AI field."
- Map "trending" to "Score DESC."
- Construct query for trending stories in the AI field:
- `SELECT DISTINCT "Title", "URL", "Score", DISTANCE("Title_Embedding", Embeddings('AI field')) as dist FROM posts1 ORDER BY dist,Score DESC LIMIT {top_k}`
5. "Give me some comments that are discussing about latest trends of LLMs?"
- Extract keywords: "comments," "latest trends of LLMs."
- Map "latest trends of LLMs" to DISTANCE function.
- Construct query for comments discussing latest trends of LLMs:
- `SELECT DISTINCT "Comments", "Score", DISTANCE("Comments_Embedding", Embeddings('latest trends of LLMs')) as dist FROM posts1 ORDER BY dist LIMIT {top_k}`
Now, let's create the query based on the provided input.
======== table info ========
{table_info}
Question: {input}
SQLQuery: "
Remove \n,\, " or any kind of redundant letter from the query and Be careful to not query for columns that do not exist.
"""
def generate_final_prompt(input, table_info, top_k=5):
final_prompt = prompt_template.format(input=input, table_info=table_info, top_k=top_k)
return final_prompt此代码设置了一个提示模板,指导 LLM 根据输入问题生成正确的 MyScaleDB 查询。
设置查询参数
我们将设置查询生成的 parameters。
top_k = 5
table_info = """
posts1 (
id UInt64,
Title String,
URL String,
Score UInt64,
Time DateTime64,
Writer String,
Comments UInt64,
Title_Embedding Array(Float32),
Comments_Embedding Array(Float32)
)
"""此代码设置要检索的 top 结果数 (top_k),定义表信息 (table_info),并为问题设置一个空输入字符串 (input)。
设置模型
在此步骤中,我们将设置 OpenAI 模型,以将用户输入转换为 SQL 查询。
from langchain.chat_models import ChatOpenAI
model = ChatOpenAI(openai_api_key="open-ai-api-key")将文本转换为 SQL
此方法首先根据用户输入和表信息生成一个最终提示,然后使用 OpenAI 模型将文本转换为 SQL 向量查询。
def get_query(user_input):
final_prompt = generate_final_prompt(user_input, table_info, top_k)
response_text = model.predict(final_prompt)
return response_text
user_input="What are the most voted stories?"
response=get_query(user_input)在此步骤之后,我们将获得如下查询:
'SELECT DISTINCT "Title", "URL", "Score", DISTANCE("Title_Embedding", Embeddings(\'AI domain\')) as dist FROM posts1 ORDER BY dist, Score DESC LIMIT 5'但 MyScaleDB DISTANCE 预期 DISTANCE(column, array)。因此,我们需要将 Embeddings('AI domain') 部分转换为向量嵌入。
处理和替换查询字符串中的嵌入
此方法将用于将 Embeddings(“Extracted keywords”) 替换为 float32 数组。
import re
def process_query(query):
pattern = re.compile(r'Embeddings\(([^)]+)\)')
matches = pattern.findall(query)
for match in matches:
processed_embedding = str(list(generate_embeddings(match)))
query = query.replace(f'Embeddings({match})', processed_embedding)
return query
query=process_query1(f"""{response}""")此方法将查询作为 input,如果查询字符串中存在任何 Embeddings 方法,则返回更新后的查询。
执行查询
最后,我们将执行查询以从向量数据库中检索相关故事。
query=query.replace("\n","")
results = client.query(f"""{query}""")
for row in results.named_results():
print("Title ", row["Title"])此外,你可以获取模型返回的查询,提取指定列并使用它们来获取列,如上所示。然后可以将这些结果传递回聊天模型,创建一个完整的 AI 聊天助手。这样,助手可以动态地使用直接从结果中提取的相关数据来响应用户查询,确保无缝且交互式的体验。
结论
简单的 RAG 由于专注于直接相似性搜索而用途有限。但是,当与 MyScaleDB、LangChain 等高级工具结合使用时,RAG 应用程序不仅可以满足大规模大数据管理的需求,还可以超越这些需求。它们可以处理更广泛的查询,包括基于时间和复杂的关联查询,从而显著提高当前系统的性能和效率。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-06-132,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号