feeds流系统设计概述


Feeds 流概述
什么是 Feeds 流? 从用户层面来说, 各种手机 APP 里面, 特别是社交类的, 我们可以看到关注的内容、好友的动态聚合成一个列表(最典型的就是微信朋友圈)都是 feeds 流的一种形式。
Feeds 流的核心功能就是: 信息聚合 它可以根据你的行为去聚合你想要的信息,然后再将它们以轻松易得的方式提供给你。这个方式就是信息流的方式,你只需要不断的滑动,就可以再各种信息中穿梭,而不需要自己去寻找,被动接收信息。 例如:微博是通过你的关注列表了解你可能想要的信息源,而后以时间轴的形式聚合各种信息推给你。后来又出现了抖音的猜你喜欢,它不需要你的手动关注,而是根据你的阅览时长,点赞等信息生成你的用户画像,从而聚合你可能感兴趣的信息。朋友圈的Feeds流则是根据你的好友关系,从而聚合了你可能想要的信息。
Feeds 流分类
从信息源聚合来看, Feeds 的信息源聚合有三种场景:
- 无依赖关系: 如抖音推荐页可以从你的操作行为中生成你的用户画像,再去匹配聚合信息
- 单向依赖关系: 譬如微博我关注了某个大v,就可以获取他发布的信息。这里的信息聚合依据是单向的关注关系
- 双向依赖关系: 如微信朋友圈,需要两个人互相通过好友,才会聚合对方的信息到自己的朋友圈中
从展示逻辑上来看, 又分为两种:
- 权重推荐: 如抖音, 依据隐含兴趣推荐信息,按权重排序展示的feeds流
- timeline 展示: 如微博和朋友圈, 依据用户关系拉取信息,按时间顺序展示的feeds流
Feeds 流模型术语
名称 | 说明 | 备注 |
|---|---|---|
Feed | Feed流中的每一条状态或者消息都是Feed,比如朋友圈中的一个状态就是一个Feed,微博中的一条微博就是一个Feed | 无 |
Feeds流 | Feed流本质上是数据流,核心逻辑是服务端系统将 “多个发布者的信息内容” 通过 “关注收藏屏蔽等关系” 推送给 “多个接收者”.如公众号订阅消息 | 三大特点:少部分人发布;基于订阅行为关联关系;大多数人读取信息 |
Timeline | Timeline其实是一种Feed流的类型,微博,朋友圈都是Timeline类型的Feed流,但是由于Timeline类型出现最早,使用最广泛,最为人熟知,有时候也用Timeline来表示Feed流 | 又称为时间轴 |
关注页Timeline | 展示其他人Feed消息的页面,比如朋友圈,微博的首页等。 | 又叫做收件箱,每个用户能看到的消息都会被存储到收件箱中 |
个人页Timeline | 展示自己发送过的Feed消息的页面,比如微信中的相册,微博的个人页等 | 又叫做发件箱,自己发布的消息都会被记录到自己的发件箱中。别人的收件箱内的消息,也是从他的各个关注人的发件箱内同步过来的 |
timeline feeds 流设计要点
timeline feeds 是根据用户之间的关系来召回 Feed, 然后基于发布时间排序的 feeds 流系统。
timeline Feeds 设计功能点
一个 timeline Feeds 模型需要开发的功能包括:
- 用户发布/删除 Feed
- 用户关注/取消关注其他用户
- 用户查看订阅的消息流(Feeds流):用户可以以timeline的形式查看所有订阅的消息源发布的消息。消息的删除和更新,都会实时被用户感知到。Feeds流的翻页问题:用户翻页Feeds流的时候,不管Feeds流更新了多少内容,此时都是沿着最后一次看到的信息往下看。Feeds流前面的信息被删改不予理会
- 用户可以查看某个用户的主页, 看其他用户曾经发布的 feed
- 用户对某条 feed 阅读/点赞/评论/转发等
- 额外功能: 发布内容安全合规审核/黑白名单配置等
设计面临的问题
feeds 流系统通用的特点(挑战):
- 实时性: 消息是实时产生,实时消费,实时推送的。 整体性能要求较高
- 海量数据: 消息来自不同的数据源, 产生的消息是海量的
- 读多写少: 一般读写比为 100:1 , 一个用户发布 feed 有 100 个用户会阅读此 feed
根据上述需要设计的功能, 以及通用问题, 进一步对问题进行抽象分析, 并给出解决方案
发布者发布 feed 后, 订阅者如何读取
在比较早之前,由于某个明星公布了一个私人消息导致微博访问量飙升直到系统崩溃, 微博做出了一系列扩容调整后宣布系统的吞吐量能支撑多位明星 “并发出轨” 实际上在数据密集系统设计(DDIA) 中提出过 ladygaga 问题:
- ladygaga 拥有千万粉丝, 那么粉丝列表的用户 ID size 就是 1000W, 这样每次 RPC 都要从用户关系服务中拉取 1000W 的数据量, 这很难再短时间内返回, 然后发布的 feed 还要像所有粉丝的收件箱中写入此 feedID, 这一操作最坏要产生 1000W 次 RPC 调用, 同时非常浪费存储空间, 因为发布一篇 feed 需要将其存储 1000W 份
- 其次 1000W 次 RPC 显然不能在短时间内调用完成, 那么会导致先写入的粉丝收到新的内容, 后写入的粉丝将滞后收到消息, 第一个粉丝和最后一个粉丝可能相差几十分钟甚至数小时, 用户体验受到严重影响
- 这一篇 feed 会产生大量的消费数据(阅读/评论等), 会导致此 feed 详情页 QPS 拉高, 随后波及到详情页的下游服务
- 用户对此 feed 的消费行为还包括评论, 评论系统的QPS拉升会导致写入评论以及评论数等缓存一致性行为受到影响
这里引申出两种方案: 读扩散和写扩散 问题
读扩散
读扩散实现:
- 订阅者去拉取 feeds 时,订阅者主动去查询关注列表,逐一请求出所有关注人的发件箱中未阅读过的 feed(通过上一次拉取的时间戳)
- 拿到多个 feed ID 后通过时间戳对其排序, 得到一个 list, 然后进行聚合展示返回
读扩散分页问题: 由于读扩散下,用户的收件箱是实时计算出来的,翻页的时候,需要去所有关注人的发件箱中拉取一定量的数据。拉取后,需要记录当前拉取到了写信箱的 write_last_id,多少个关注就要记录了多少个 write_last_id。而后翻页的时候,需要用这些write_last_id往后拉取新的一定量(比如page_size个)的数据。再用这些数据组成的新收件箱列表,筛选 page_size 条返回前端。同时,还需要更新他实际拉取了消息的写信箱中的 write_last_id,并且存储。当下一次翻页的时候,这批 write_last_id 将作为下次的翻页时定位的依据
总结: 读扩散模式,写 feed 逻辑简单, 节约存储, 但是读性能差, 分页功能实现复杂
写扩散
写扩散实现:
- 当发布 feed 时, 查询发布者的粉丝列表, 并将发布的 feed ID 写入粉丝的收件箱
- 读取时, 直接读取自身的收件箱, 然后打包成 feeds list 进行聚合展示
写扩散下分页: 由于用户收件箱都是写好的, 直接用 last_id 往下翻即可
总结: 写扩散模式读性能较好,但是浪费存储, 并且大V用户写扩散太慢会出现时效性问题
改进方案-推拉结合
所谓遇事不决,推拉结合。 我们上面提到过 feeds 流系统是一个读多写少的系统, 所以选择写扩散会更好, 不过针对上面提到的大V用户问题对写的放大太严重了, 性能受到较大影响。
所以我们采取推拉结合模式:
- 针对大V用户, 读扩散, 生成 feed 列表
- 针对普通用户, 写扩散, 生成 feed 列表
具体操作:
- 发布 feed 时, 如果是大V则仅写入自己的发件箱中
- 发布 feed 时, 如果是普通用户则进行写扩散推出去
- 读 feed 时, 读取关注列表判断哪些是大V用户, 拉取大V的发件箱(同样按照上面的 write_last_id 拉取), 并行读取自己的收件箱, 拿到两个 feedID list 进行合并
继续改进-用户分级策略
当我们解决了大V的写扩散问题后, 又面临着新的问题:
- 如何识别大V用户才能避免边界问题导致性能抖动(用户的粉丝量是一个动态的值, 如何标记一个用户是大V?)
- app 注册用户很多, 但是活跃用户很少, 如果为某个用户都存储收件箱是否会占据太多的存储成本(存储浪费)
针对上面的问题, 我们需要有一套体系对用户进行分级, 如何标识是大V ,如何标识是活跃用户
针对大V用户进行打标:
- 通过粉丝数/离线热度计算/机器学习模型打标等手段进行标识用户是否是大V, 并且将大V作为一种用户标签进行存储
- 通过 flink 等流式计算, 来标识是否是大V发文
- 大V用户只能升级不能降级, 一旦降级需要回溯所有粉丝的收件箱(重新写入所有粉丝的收件箱)
针对活跃用户进行用户分级:
- 基于日活/月活来判断一个用户是否是活跃用户, 甚至可以维护一个活跃级别
- 譬如月内活跃为一级,收件箱长度保留100条。周活跃为二级,收件箱长度保留300条。日活跃为3级,收件箱长度保留1000条(节约存储成本)
冷热分离+预拉取-收件箱过大问题
如果用户关注的列表过多,会导致这个用户的收件箱列表成为一个大 key, 这类用户的性能上会有影响
- 为了避免用户的收件箱在 redis 中无限增长, 可以对活跃用户做一个限制, 默认最多刷新1000条
- 如果用户持续拉取内人, 超过1000条, 可以退化为拉模式, 去关注者的发件箱拉取(每次拉取100条来更新用户的收件箱)
- 在写扩散的过程中, 只添加新的 feed 到列表, 删除超过限制的 feed(写入新的 100条, 删除最老的 100条)
软删除+懒删除-写扩散下删除问题
写扩散模式下,用户发布消息可以慢慢扩散出去,但是删除,修改都要扩散出去,速度过慢会出现时效性问题。而且,如果真的是删除了数据,可能会影响Feeds流的分页功能)
这种情况, 我们可以采用软删除+懒删除机制: 软删除是指消息内容不进行实际删除,而是将消息置为删除状态即可,不扩散出去。如此一来,用户在自己的读取收件箱中消息的时候,是先获取了消息 Id 后,再去数据库查出消息内容,而后判断状态进行过滤,把已经删除的状态剔除,不返回给前端。此时也需要重新进行捞数据,填充分页内容。 懒删除是指如果过滤了某个消息,此时才把消息从用户收件箱中真正删除。(redis的zset中的对应id进行剔除,完成Feeds流表的刷新)
软删除+懒删除的机制具体的实现方案较: 读扩散回查: 我们在写扩散时,只写了一个消息id到用户的收件箱中,所以,用户查询收件箱信息的时候,要进行一个回查将信息丰富(该方案相比直接把内容一起写入收件箱内会更加节约内存,减少冗余数据,同时消息删除无需扩散)。
timeline feeds 系统设计
架构设计
整体架构设计如下:
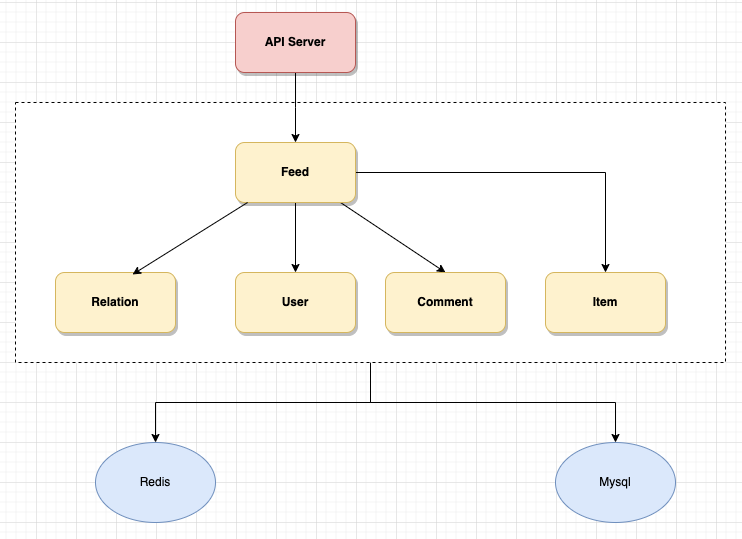
- User Svr: 存储用户信息, 用户维度的服务能力
- Relation Svr: 存储用户关系, 获取关注列表、粉丝列表等
- Item Svr: 存储原始发布内容, 提供发布和查询功能
- Comment Svr: 存储评论数据, 拉取评论列表以及评论相关信息
- Feed Svr: 存储 feed 信息,提供信息流列表能力, 如个人主页/浏览记录等
核心存储设计
feed 的核心逻辑主要是发布消息+拉取 feeds 流, 核心底层存储为一个关系型数据表存储消息原始内容, 两个 redis list 对应收发件箱
消息表的存储结构设计如下:
字段名称 | 字段说明 | 备注 |
|---|---|---|
msg_id | 消息唯一标识 | |
msg_title | 消息标题 | |
msg_content | 消息内容 | json 存储 |
msg_type | 消息类型 | 如文字、视频等 |
msg_status | 消息状态 | 用于状态标识, 如审核、软删除等 |
extra_info | 扩展信息 | 用于业务扩展需求, 存储 json |
sender_id | 发送人 | |
create_at | 发送时间 | |
modify_at | 修改时间 |
收/发件箱使用 redis zset 存储, 以收件箱为例: key是 接收者uid,zvalue为发件人uid+消息id,zscore:发布时间戳 。这样设计,可以将计算下沉,每次收件箱出现消息的刷新的时候,都会自行排序。
1 | key: 接收者uid -> value: 发件人uid+msg_id -> scroe: 消息发布时间戳 |
|---|
核心业务流程大致实现
发布 Feed
发布一条Feed消息的时候,流程是这样的:
- Feed消息先进入一个队列服务。
- 先从关注列表中读取到自己的粉丝列表,以及判断自己是否是大V。
- 将自己的Feed消息写入个人页Timeline(发件箱)。
- 如果是大V,此时拉取活跃用户;如果是普通用户,则拉取自己的所有粉丝用户。然后将自己的Feed消息同步写给自己的粉丝,同步的内容为Feed ID。
读取 Feed
用户刷新自己的Feed流程是这样的:
- 读取自己关注的大V列表
- 去读取自己的收件箱,范围起始位置是上次读取到的最新Feed的ID,结束位置可以使当前时间,也可以是MAX。然后通过查询出来的FeesId反查Feeds内容,并且把已经软删除的数据剔除出去。
- 如果有拉取到关注的大V列表,则再次并发读取每一个大V的发件箱,如果关注了10个大V,那么则需要10次访问。
- 合并2和3步的结果,然后按时间排序,返回给用户。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-6-13,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号