【.NET】使用OpenCV和tesseract-ocr引擎实现识别图片文字内容

【.NET】使用OpenCV和tesseract-ocr引擎实现识别图片文字内容

Wesky
发布于 2024-08-13 18:55:33
发布于 2024-08-13 18:55:33
前言:没啥写的,直接看下文:
Tesseract OCR引擎下载
各个系统环境版本下载地址:
https://tesseract-ocr.github.io/tessdoc/Installation.html
Windows系统下载地址:
https://github.com/UB-Mannheim/tesseract/wiki
如果感兴趣看内部实现源码,可以参考Tesseract OCR引擎开源源码:
https://github.com/tesseract-ocr/tesseract
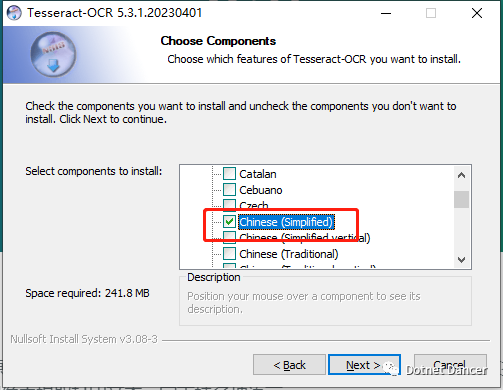
安装引擎,我用的Windows64位版本,安装期间,需要根据需要识别的内容,选择需要的语言包。默认只有英文。例如我选择简体中文。
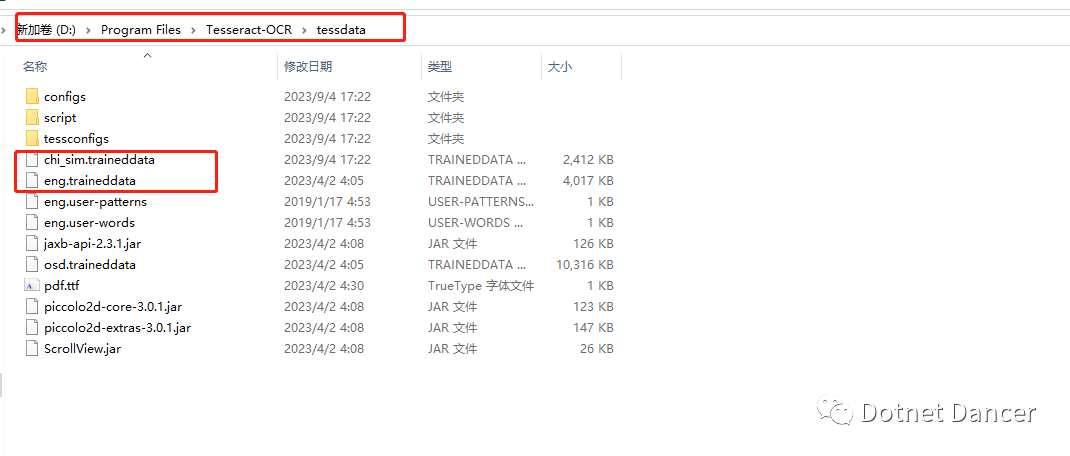
安装完成,在安装路径下,可以看到traineddata,这个是训练数据集,前面代码语言类型,代码里面需要根据语言类型来指定需要识别的语言。
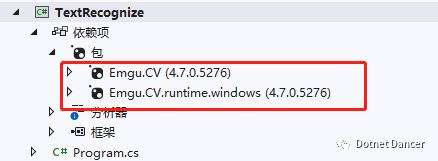
创建控制台程序,引用OpenCV的两个包:
Emgu.CV 和 Emgu.CV.runtime.windows
初始化OCR引擎,参数是训练数据集绝对路径,以及使用的训练数据语言,根据文件前缀,得知简体中文是chi_sim
Tesseract ocr = new Tesseract(@"D:\Program Files\Tesseract-OCR\tessdata", "chi_sim", OcrEngineMode.Default);
截图了个图片拿来测试。测试图片:
获取本地图片进行识别:
// 读取图像文件
using (Mat image = CvInvoke.Imread(@"D:\test.png", ImreadModes.Color))
{
if (image != null)
{
// 设置要识别的图像
ocr.SetImage(image);
// 执行OCR识别
var res = ocr.Recognize();
if(res == 0)
{
Tesseract.Character[] characters = ocr.GetCharacters();
// 输出识别结果
foreach (var character in characters)
{
Console.Write($"{character.Text}");
}
}
}
}运行程序,查看效果:

基本上都识别出来了,但是可能有小个别不是很准确,但是影响不大。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-09-04,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 Dotnet Dancer 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号