给 WordPress 添加一个 RSS 友链阅读器

给 WordPress 添加一个 RSS 友链阅读器

2Broear
发布于 2024-09-07 13:23:10
发布于 2024-09-07 13:23:10
前情提要
前不久在 jeffer 的一篇文章看到写了一个wp的rss阅读插件,有点小心动。其实早在去年就和 thyuu 交流过这个wp的友链rss功能,当时老哥很快搞定了,还分享了实现代码。当时对rss不是很感冒,基本就是在友链页面翻翻经常逛的那几个,想着也不是每个人都有这个就感觉有点没必要,而且可以直接去看友链的公共聚合之类的,就没弄。直到现在,用了就感觉,欸 好像还挺方便的。
实现
需求是这样的:在wp原生链接基础上,读取不同分类链接中的 link_rss 数据然后解析为自定义 stdClass 返回并储存到 wp_options 表中(方便后期排序等操作),通过不同的链接分类,可以读取不同分类下的rss数据集,通过设置链接显示状态(visible)来限制已订阅链接。
基本理念就是读取和解析xml文件,不过这大千世界,rss种类也很多,面对多种数据结构需要手动去兼容返回。刚开始直接就问了kimi给了一套方案,用php自带的simplexml扩展来解析数据,试了 能用,不过需要自己手动兼容rss类型,就相对比较麻烦。后来想起 thyuu 之前用的wp原生功能 fetch_feed 能自动解析,效果感觉比 curl 好使..
后面尝试了两种不同输出的效果,虽然大差不差但还是wp原生的用起来更稳定(貌似),后面把数据缓存到 wp_option 表了,并挂载更新到了原生链接操作hook(增删改均可同步更新对应分类),添加 wp_schedule 定时清理所有分类缓存任务。
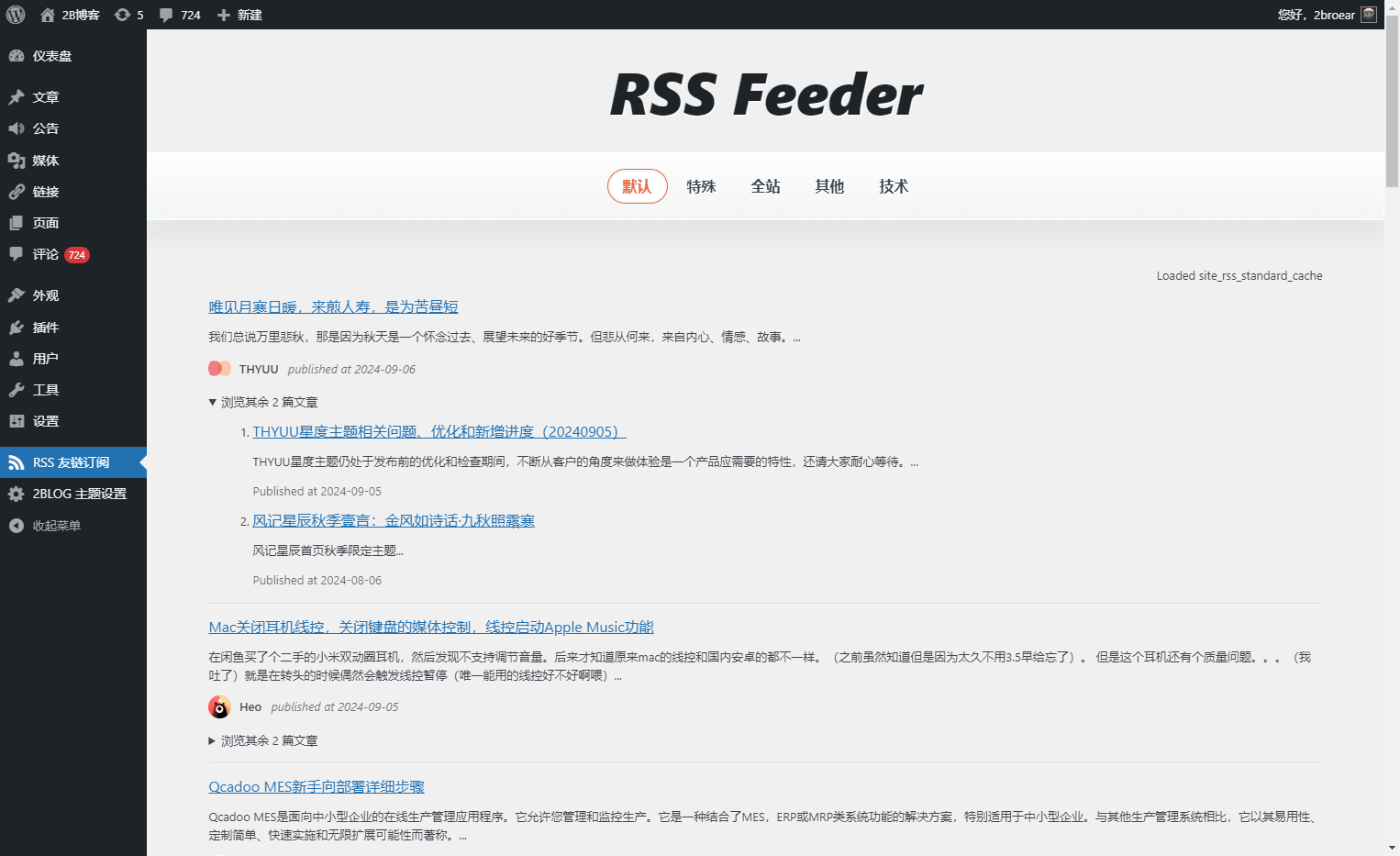
效果
综合效果还是不错的,如图。
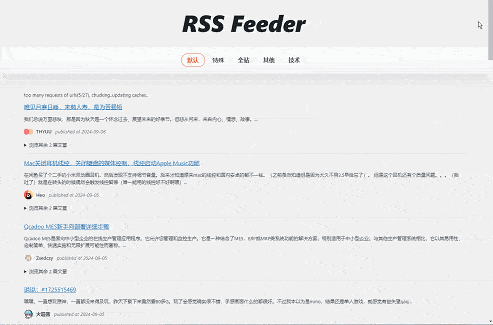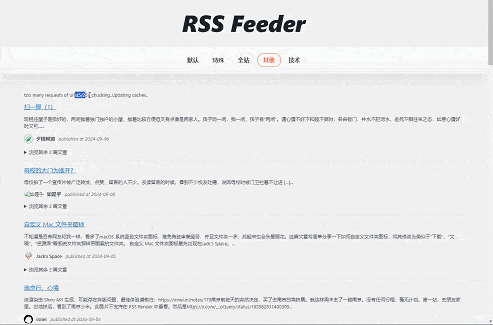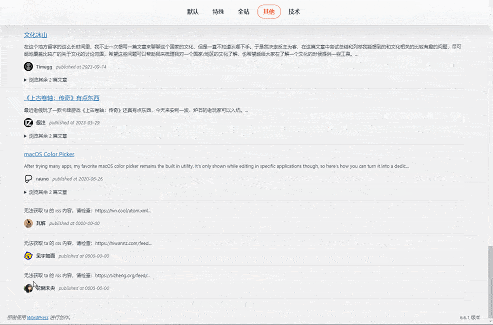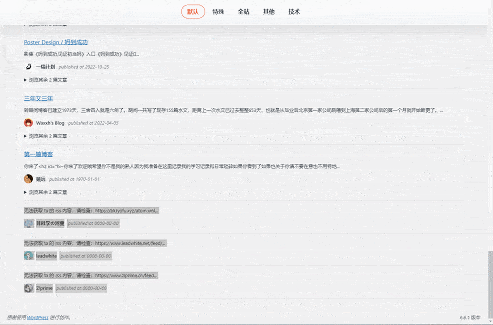
一些请求被分割,一些请求失败(底部)
问题
主要有两个问题,一个是rss 抓取时间过长,另一个是抓取成功率问题。
- 抓取时效性
- 抓取成功率
关于 rss 抓取时效方面,从拉数据到缓存50+的链接需要反应大概2分钟左右。我问了kimi很多解决方案,什么异步、分块、多线程等等,效果都不太理想。
抓取成功率方面,我试了下当链接超过一定量时就会出现抓取失败的情况,有些报错是数据没完全接收。针对这一情况,首先尝试了 curl_multi 多线程处理,基本没效果。然后尝试将rss链接集分块请求处理,效果不理想。
综上所述,目前还是用的默认 fetch_feed 做的分块请求处理。有没有大佬来指点一二,这种数据应该怎么处理以性能最大化?
闲聊
tmd我前几天手贱给笔记本换硅脂,中毒了去看什么硅脂视频,tmd就是一坨大便艹。换完直接屏幕闪屏,一旦请求gpu上来就开始闪,以为gpu核心出问题了,换核显结果一样。。网上搜了一圈发现可能是显示器线材问题,于是外接显示器最后发现是笔记本显示器的问题。。。这tmd百思不得其解
最要命的是,换了硅脂,笔记本发热降频???我tmd合着搁着绕圈子呢,何况之前根本不降频,温度比这更高高负载时间也比这更长,我干,到底什么原因。我现在就怕这核心被我搞了,但按理来说我拆装非常小心所以不应该啊,哎日了狗,黑神话也搁置了,全怪自己手贱啊,非要去换sb硅脂,这就叫没事找事!!
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024/09/06 ,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号