GBI探索体验DB-GPT部署使用
原创
GBI探索体验DB-GPT部署使用
原创
fanstuck
发布于 2024-09-23 09:56:22
发布于 2024-09-23 09:56:22
GBI概念以及DB-GPT不了解的可以去看看本人之前的两篇博文。本篇文章主要详细记录DB-Chat部署使用。
环境
- python3.10.9
- GPU:A100
- jupyter lab
- torch 1.13.1+cu117
- torch 0.13.1+cu117
- torchvision 0.14.1+cu117
- CUDA:11.7
Jupyter Lab
安装JupyterLab
pip install jupyterlab配置JupyterLab
创建一个配置文件:
jupyter lab --generate-config找到生成的配置文件,通常位于 ~/.jupyter/jupyter_lab_config.py,然后编辑它:
vim ~/.jupyter/jupyter_lab_config.py设置密码:
jupyter notebook password在生成的json文件下面打开找到hash_password。
在配置文件中找到以下几行,并根据需要取消注释和修改:
# 监听所有的IP地址(默认只监听本地)
c.ServerApp.ip = '0.0.0.0'
# 不使用浏览器自动打开
c.ServerApp.open_browser = False
# 设置访问密码
c.ServerApp.password = 'your_hashed_password'
# 是否需要访问密码
c.ServerApp.password_required = True
# 设置访问端口(默认是8888)
c.ServerApp.port = 8888如果有误打开了port重复打开端口:
先看看端口信息:
sudo netstat -tuln下载一下lsof:
sudo yum install lsof -y安装完成后,你可以确认 lsof 是否已成功安装:
lsof -v使用 lsof 查找并关闭端口
sudo lsof -i :8888找到使用该端口的进程ID (PID) 后,使用 kill 命令关闭进程:
sudo kill <PID>打开jupyter lab:
jupyter lab --allow-root记得在服务器上面打开端口,云服务器好设置,如果是本地机器的话需要确认服务器上的防火墙允许8888端口的流量:
sudo firewall-cmd --zone=public --add-port=8888/tcp --permanent
sudo firewall-cmd --reload
好了之后可以在8888端口访问,之后开始部署DB-Chat:
源码下载:
git clone https://github.com/eosphoros-ai/DB-GPT.git
可以先虚拟一个db-gpt的环境:
conda create -n dbgpt_env python=3.10
conda activate dbgpt_env下载依赖:
pip install -e ".[default]"我这里报错:
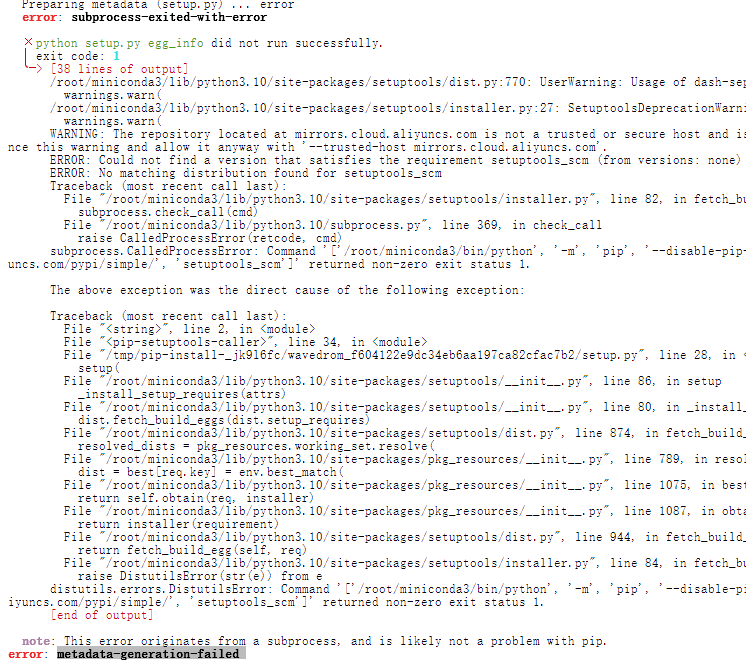
下载一下setuptools_scm
pip install setuptools_scm问题解决。

配置一下环境变量:
cp .env.template .env需要注意的是这几个点:
LLM:
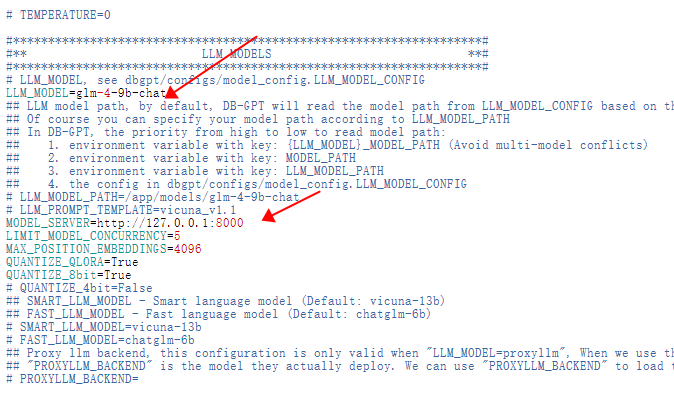
SQL:
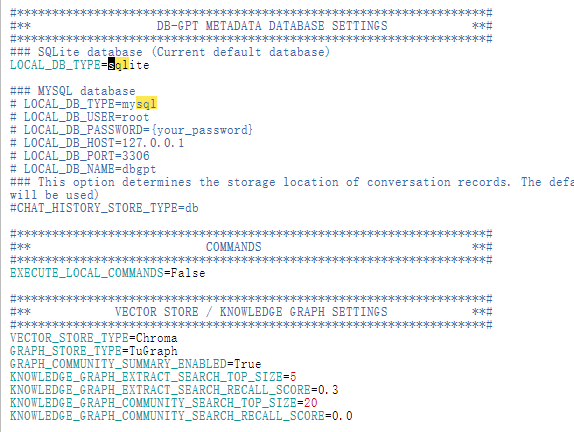
我这边先进行本地部署chatglm4-9b:
mkdir models and cd models通过魔搭下载确保lfs已经安装:
git lfs install
开始克隆:
git clone https://www.modelscope.cn/ZhipuAI/glm-4-9b-chat.git模型比较大,大概有20G需要耐心等一下,下载完了之后先安装一下依赖,跑个Demo看看效果:
trans_cli_demo.ipynb:
import os
from pathlib import Path
from threading import Thread
from typing import Union
import gradio as gr
import torch
from peft import AutoPeftModelForCausalLM, PeftModelForCausalLM
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
PreTrainedModel,
PreTrainedTokenizer,
PreTrainedTokenizerFast,
StoppingCriteria,
StoppingCriteriaList,
TextIteratorStreamer
)
from transformers import AutoTokenizer, StoppingCriteria, StoppingCriteriaList, TextIteratorStreamer, AutoModel
ModelType = Union[PreTrainedModel, PeftModelForCausalLM]
TokenizerType = Union[PreTrainedTokenizer, PreTrainedTokenizerFast]
MODEL_PATH = os.environ.get('MODEL_PATH', '/root/DB-GPT/models/glm-4-9b-chat')
TOKENIZER_PATH = os.environ.get("TOKENIZER_PATH", MODEL_PATH)
tokenizer = AutoTokenizer.from_pretrained(
MODEL_PATH,
trust_remote_code=True,
encode_special_tokens=True
)
model = AutoModel.from_pretrained(
MODEL_PATH,
trust_remote_code=True,
# attn_implementation="flash_attention_2", # Use Flash Attention
# torch_dtype=torch.bfloat16, #using flash-attn must use bfloat16 or float16
device_map="auto").eval()
class StopOnTokens(StoppingCriteria):
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> bool:
stop_ids = model.config.eos_token_id
for stop_id in stop_ids:
if input_ids[0][-1] == stop_id:
return True
return False
if __name__ == "__main__":
history = []
max_length = 8192
top_p = 0.8
temperature = 0.6
stop = StopOnTokens()
print("Welcome to the GLM-4-9B CLI chat. Type your messages below.")
while True:
user_input = input("\nYou: ")
if user_input.lower() in ["exit", "quit"]:
break
history.append([user_input, ""])
messages = []
for idx, (user_msg, model_msg) in enumerate(history):
if idx == len(history) - 1 and not model_msg:
messages.append({"role": "user", "content": user_msg})
break
if user_msg:
messages.append({"role": "user", "content": user_msg})
if model_msg:
messages.append({"role": "assistant", "content": model_msg})
model_inputs = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=True,
return_tensors="pt"
).to(model.device)
streamer = TextIteratorStreamer(
tokenizer=tokenizer,
timeout=60,
skip_prompt=True,
skip_special_tokens=True
)
generate_kwargs = {
"input_ids": model_inputs,
"streamer": streamer,
"max_new_tokens": max_length,
"do_sample": True,
"top_p": top_p,
"temperature": temperature,
"stopping_criteria": StoppingCriteriaList([stop]),
"repetition_penalty": 1.2,
"eos_token_id": model.config.eos_token_id,
}
t = Thread(target=model.generate, kwargs=generate_kwargs)
t.start()
print("GLM-4:", end="", flush=True)
for new_token in streamer:
if new_token:
print(new_token, end="", flush=True)
history[-1][1] += new_token
history[-1][1] = history[-1][1].strip() Demo可以跑起来,那么现在就开始DB-Chat本地环境变量配置了:

DB-GPT Demo
测试数据Linux
bash ./scripts/examples/load_examples.sh运行服务
python dbgpt/app/dbgpt_server.py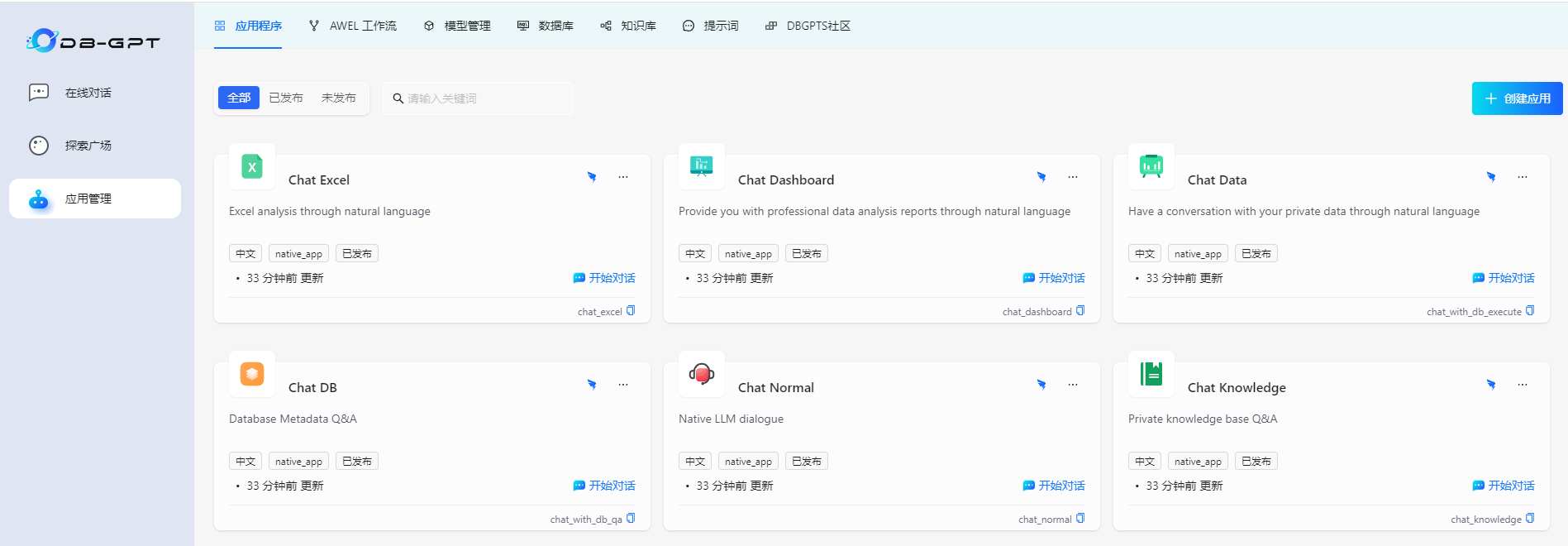
DB-GPT默认开放的端口为5670,根据开放的IP打开这个端口地址即可看到使用DB-GPT,需要注意的是需要关注GPU和CPU是否能够支持你嵌入的大模型底座算力需要,还需要看你的GPU是否能负载,版本是否能对上,可以先使用Chat Excel,上传一个excel文件用于测试:
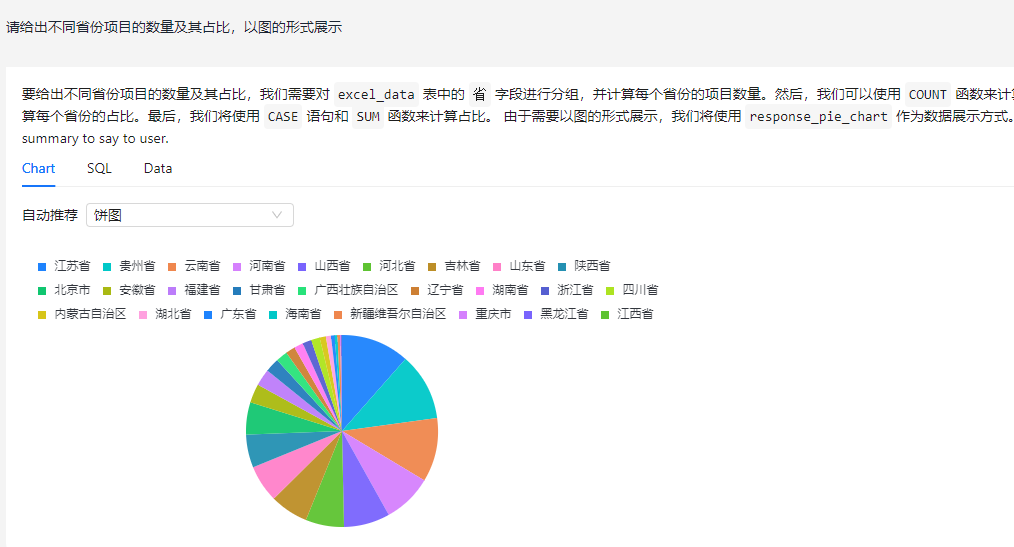
这个功能能运作了说明大模型调用是没问题的,基础的数据分析能力和RAG也都是没问题的,现在需要调通数据库模型能力,这部分我打算放到下一章对整个DB-GPT数据库层源码进行解读,本人之前做过较为底层的SQL Tree血缘解析,希望能够整合到开源项目里面中,共享出自己的一份力,加强AI数据合规方面能力。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号