算法入门(六)—— 一文搞懂逻辑回归(内附Kaggle实战源码与数据集)

算法入门(六)—— 一文搞懂逻辑回归(内附Kaggle实战源码与数据集)

万事可爱^
发布于 2025-01-23 19:04:18
发布于 2025-01-23 19:04:18
大家好!欢迎来到我们的“算法入门”系列。今天我们要聊聊机器学习中的一位“老朋友”——逻辑回归。如果你对它的名字感觉既熟悉又陌生,别担心,今天我们会带你一起深入了解它的原理、公式以及在实践中的应用。最重要的是,我们会通过一个Kaggle实战项目,让你能够轻松上手!
准备好了吗?让我们一起开始这段学习之旅吧!
1. 逻辑回归概述
逻辑回归,听起来像回归分析的“亲戚”,但实际上它是一种分类算法。嗯,确实很让人困惑!线性回归是用来预测一个连续变量的数值,而逻辑回归虽然名字里有“回归”,但实际上它是用来做二分类(或者多分类)问题的算法,比如判断某个邮件是否为垃圾邮件,某个图片里是不是猫,等等。
1.1 线性回归与逻辑回归的关系
想象一下,我们用线性回归来做分类问题,假设我们有两个类别:类别 0 和类别 1。在标准的线性回归中,我们直接预测一个数值,而这个数值是无限的,可以正数、负数。
但是,如果我们直接用线性回归来做分类预测,那结果就会出现问题。例如,预测的值可能是 -10,也可能是 100,这样的结果对分类来说完全没有意义。我们更关心的是类别的概率值,0 到 1 之间的一个概率值。
逻辑回归的核心思想就是:将线性回归的预测结果(一个任意实数)通过一个Sigmoid函数(逻辑函数)转化为一个概率值,进而做分类。
1.2 Sigmoid函数的引入
Sigmoid函数是一个S型曲线,数学表达式为:
当
会趋近于 0。因此,它的输出总是在 0 到 1 之间,非常适合用来表示概率。
Sigmoid函数在神经网络中也很常见,其图形形状如下图所示:
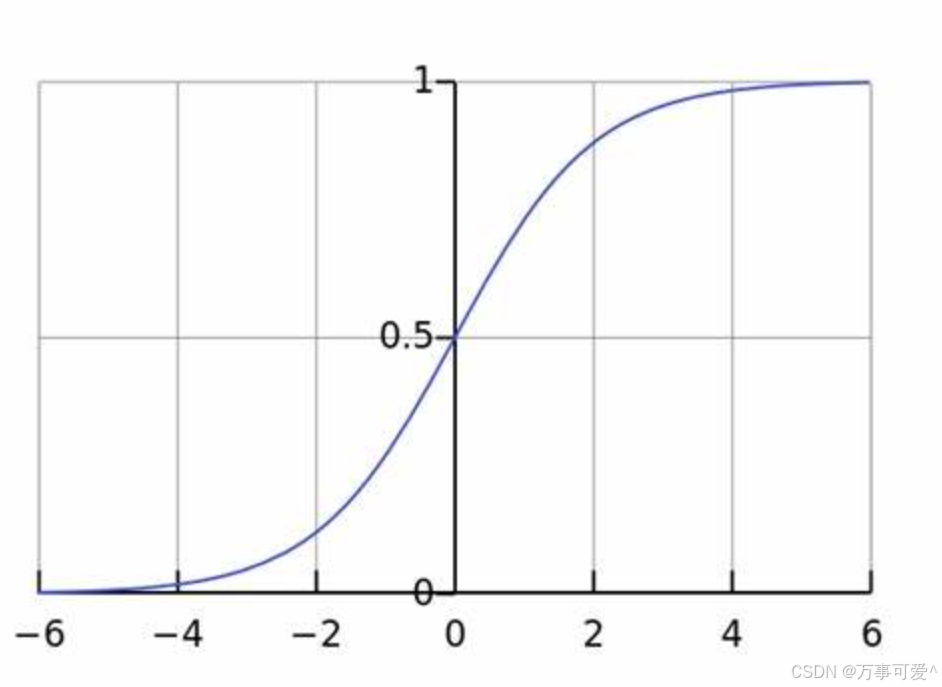
在这里插入图片描述
那么,逻辑回归的最终输出就可以通过如下公式得到:
其中,
是输入特征,
是模型参数(权重),
是偏置项,
是预测的概率值。
2. 对数似然损失函数与梯度下降优化
逻辑回归的目标是训练出一组模型参数 ( w ) 和 ( b ),使得模型的预测概率与真实标签的差异最小。
2.1 对数似然损失函数
为了量化预测与真实标签之间的差异,我们使用对数似然损失函数(Log-Loss),它的形式如下:
其中:
是第( i )个样本的真实标签(0 或 1)
是模型预测的概率。
这个损失函数的意义是:我们希望模型能够预测出接近 1 或接近 0 的概率值。如果某个样本的真实标签是 1,预测值越接近 1,损失就越小;如果预测值越接近 0,则损失越大。
2.2 梯度下降优化
为了最小化损失函数,我们需要使用梯度下降算法来优化模型参数。梯度下降的核心思想是:通过计算损失函数对参数的偏导数(梯度),来调整参数
,使得损失函数逐渐减小,直到收敛到最优解。
梯度下降的更新公式如下:
其中,
是学习率,控制每一步更新的步长。
3. 多分类逻辑回归(One-vs-Rest)
在实际问题中,我们通常面对的不只是二分类问题,还需要处理多分类问题。幸运的是,逻辑回归也能应对这种情况。
3.1 One-vs-Rest(OvR)策略
处理多分类问题时,最常见的一种方法是One-vs-Rest(也叫 One-vs-All)。这种策略的思路是:对于每一个类别,我们训练一个二分类模型,判断样本是否属于该类别。最终,分类的结果就是选择预测概率最大的那个类别。
例如,假设我们有 3 个类别:A、B、C,那么我们分别训练三个二分类模型:
- 模型 1:判断样本是否属于类别 A。
- 模型 2:判断样本是否属于类别 B。
- 模型 3:判断样本是否属于类别 C。
对于一个新的样本,我们将三个模型的预测结果进行比较,选择概率最大的类别作为最终的分类结果。
4. Kaggle实战:使用逻辑回归解决泰坦尼克号生存预测问题
现在,大家已经对逻辑回归有了一个清晰的理解。接下来,我们来动手做一个简单的Kaggle实战项目,通过逻辑回归来预测泰坦尼克号乘客的生存情况。
4.1 数据集介绍
我们将使用Kaggle上的“泰坦尼克号:机器学习生死预测”数据集。该数据集包含了泰坦尼克号上乘客的基本信息(如年龄、性别、票价等),我们需要预测每个乘客是否生还(Survived)。
4.2 数据预处理
首先,我们需要导入一些库,并加载数据集:
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, roc_curve, auc# 加载数据集
train_data=pd.read_csv('/kaggle/input/titanic/train.csv')
train_data.head()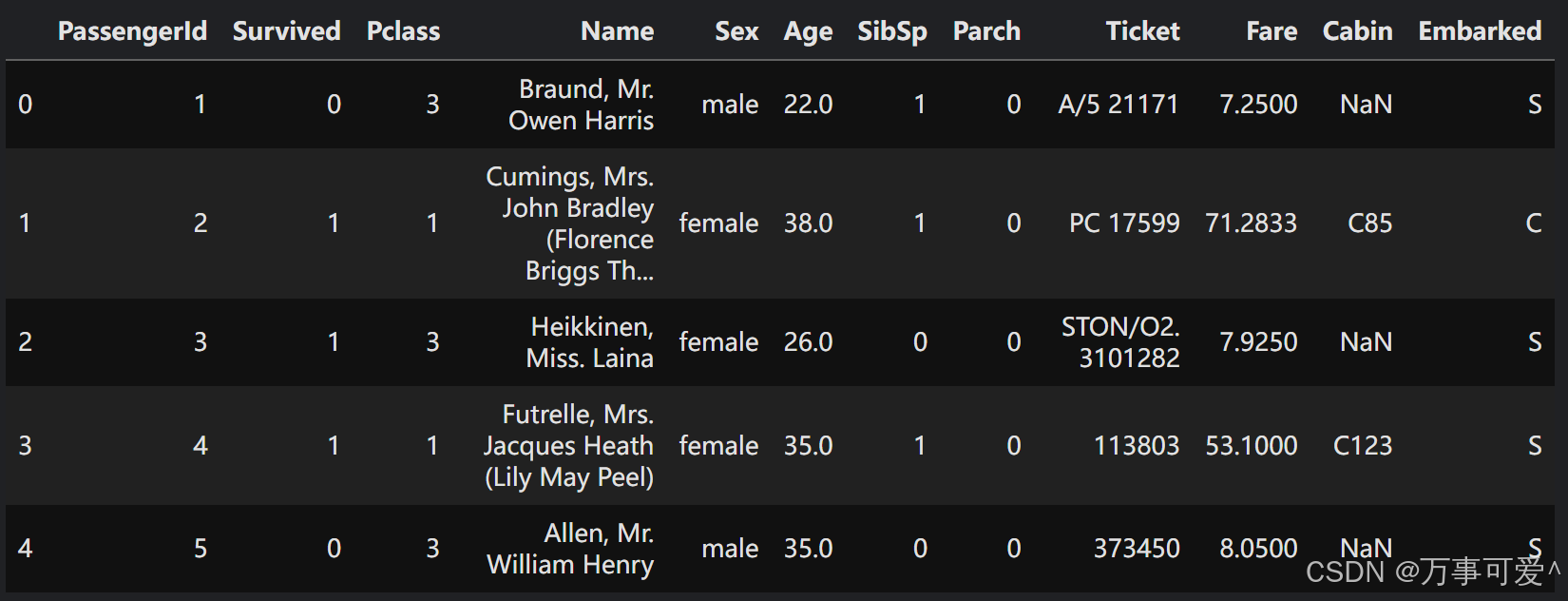
在这里插入图片描述
接下来,我们对数据进行预处理。泰坦尼克号数据集包含了缺失值,我们需要处理这些缺失值:
# 填充缺失值
data['Age'].fillna(data['Age'].mean(), inplace=True)
data['Embarked'].fillna(data['Embarked'].mode()[0], inplace=True)
# 选择特征列
features = ['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked']
# 将类别变量(如 Sex 和 Embarked)转换为数值型
data['Sex'] = data['Sex'].map({'male': 0, 'female': 1})
data = pd.get_dummies(data, columns=['Embarked'], drop_first=True)
# 选择特征和标签
X = data[features]
y = data['Survived']4.3 训练模型
接下来,我们将数据集拆分为训练集和测试集,然后训练逻辑回归模型:
# 拆分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 数据标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 初始化并训练逻辑回归模型
model = LogisticRegression()
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f'模型准确率: {accuracy:.2f}')
# 计算AUC曲线相关值
y_pred_proba = model.predict_proba(X_test)[:, 1] # 取正类的预测概率
fpr, tpr, thresholds = roc_curve(y_test, y_pred_proba)
roc_auc = auc(fpr, tpr)模型训练完成后为了更直观的展示其效果,这里做出AUC曲线图。
import matplotlib.pyplot as plt
# 绘制AUC曲线
plt.figure()
plt.plot(fpr, tpr, color='darkorange', lw=2, label=f'ROC curve (area = {roc_auc:.2f})')
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic')
plt.legend(loc="lower right")
plt.show()
在这里插入图片描述
4.4 结果分析
最后,我们通过准确率来评估模型的效果。如果模型效果不好我们可以通过调整模型的超参数或者进行更复杂的特征工程,通常可以提高预测准确率。
5. 总结
通过今天的学习,我们了解了逻辑回归的原理,并通过Kaggle泰坦尼克号数据集做了一个简单的实战项目。逻辑回归是一种非常重要且常用的分类算法,它的实现简单、效果显著,是我们进入机器学习领域的良好起点。
今天在算法修行的路上又迈出了一步,希望大家学习路上一帆风顺,有不懂的地方也可以在评论区留言讨论,我们下期见!
泰坦尼克号:机器学习生死预测数据集地址:https://www.kaggle.com/competitions/titanic/data?select=test.csv
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-01-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号