张俊林:Deepseek R1是如何做的?


MCST树搜索会是复刻OpenAI O1/O3的有效方法吗
前言|Deepseek R1是如何做的?Kimi K1.5的思路是什么?它们之间是什么关系?它们和MCST树搜索又是什么关系?本文探讨这些问题。
作者简介:张俊林 新浪微博新技术研发负责人,腾讯云TVP,中国中文信息学会理事,中科院软件所博士。目前担任新浪微博新技术研发负责人,在此之前在阿里巴巴担任资深技术专家,负责新技术团队。著有《这就是搜索引擎:核心技术详解》、《大数据日知录:架构与算法》,目前主要研发兴趣集中在大语言模型及推荐系统。
Deepseek R1和Kimi K1.5同一天公布技术报告,介绍了RL+LLM的做法,方法简洁有效,读完技术报告收获很大,且两者效果基本追平OpenAI O1,下一步就是赶超O3了,方法已经走通,赶超应该只是时间问题。
R1和K1.5的方法其实是类似的,且都没有采取MCST+PRM的技术路线,报告发布后涌现出一些声音,意思是MCST是不可行的,我觉得这个结论下得有点草率,而且为时过早。就比如攀登珠穆朗玛峰,可能有不同的路径,条条小路通封顶,不能说A路线能通顶,由此得出结论B路就不行,这里貌似没有必然的逻辑关系。
如果综合下目前相关研究进展,除了R1和K1.5,微软的rStar-Math也是个非常值得关注的技术方案,采取MCST+PRM路线,我认为它已经把树搜索如何做类o1模型的路趟通了,若综合R1、K1.5和rStar-Math一起分析,再深入思考下,应该能得出很多有意思的判断。比如,R1和K1.5以及MCST方法之间有什么特殊的关联吗?我认为三者之间有着密切的关联。本文会介绍这三者的主要思路,以及相互之间的联系。
正文有点长,这里提炼出一些要点:
- Kimi K1.5的做法是DeepSeek R1的特例,基于这个路线,我们可以推导出更通用的方法;
- 由K1.5和R1,可得到如下推论:存在大量题目,由模型给出的推理轨迹COT数据中包含中间步骤错误,但是这影响不大,用这种数据仍然能训练出强大的类o1模型;
- 进一步的推论:大模型比人类更适合学习复杂推理的过程,对于大模型来说就是把高概率的逻辑片段建立起迁移联系,一环套一环玩接力游戏就行,而人脑其实是不擅长学习长链条的知识推导的;
- Deepseek R1和Kimi K1.5采用的方法是MCST方法的特例,如果两者有效,一定可以推导出对应的更通用的有效MCST树搜索版本;
- All You Need is High Quality Logic Trajectory Data;
- 得益于Deepseek开源出的众多R1版本模型,我们可以低成本快速复制出逻辑推理能力更强大的模型;
正文开始。
一.Kimi K1.5和Deepseek R1的做法及联系
如果看过两者的技术报告,会发现这两者做法非常相似, K1.5基本上可以看成R1做法的特例情况。而且我在读完后引发了一些疑问,并在自我解释这个疑问的过程中引发出一些有意思的推论。
Kimi K1.5的做法
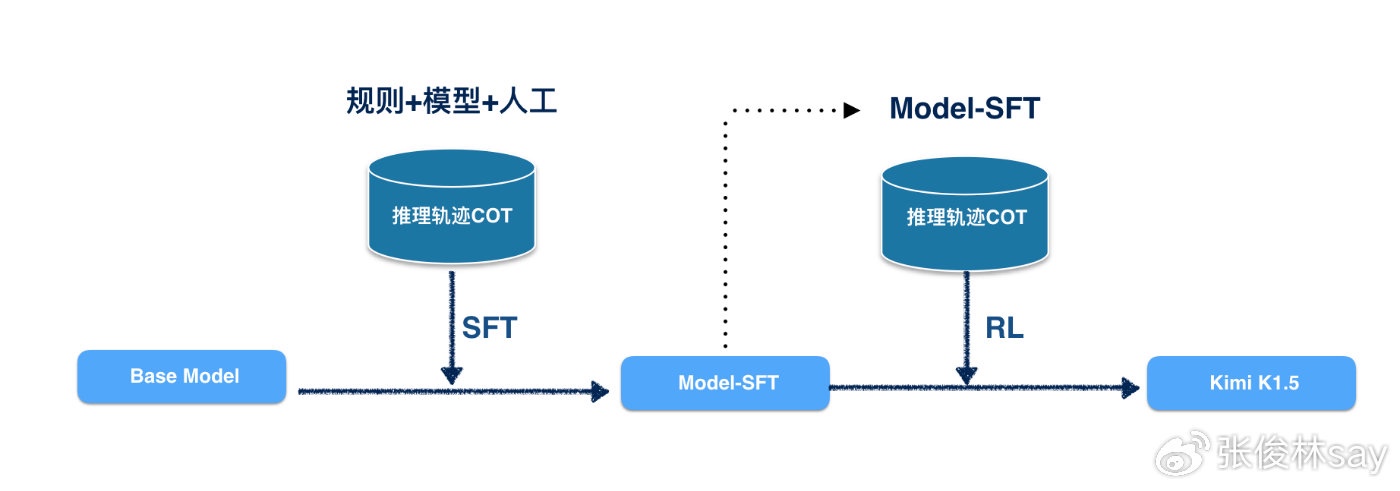
Kimi 1.5
在选定某个基座模型后,Kimi K1.5分为两个阶段,第一阶段找到一批<问题,答案>数据,通过某个能力较强的模型,来产生问题对应的推理轨迹COT数据(代表模型深度思考的过程)和模型推导出的答案,根据模型产生的答案是否与标准答案相同,可以过滤掉错误的中间推理过程,保留那些模型产生答案和标准答案相同的推理轨迹COT,再加上一些规则判断或人工校准,尽量减少中间推理步骤错误,由此产生一批推理轨迹COT数据,训练数据此时形成<问题,推理轨迹COT,答案>的形式,然后用这些数据SFT调整下模型参数。这个阶段的主要目的一个是让大模型能够产生初步的深度思考能力,一个是输出格式满足我们希望的形式,通过调整模型参数让这种能力内化到模型里。
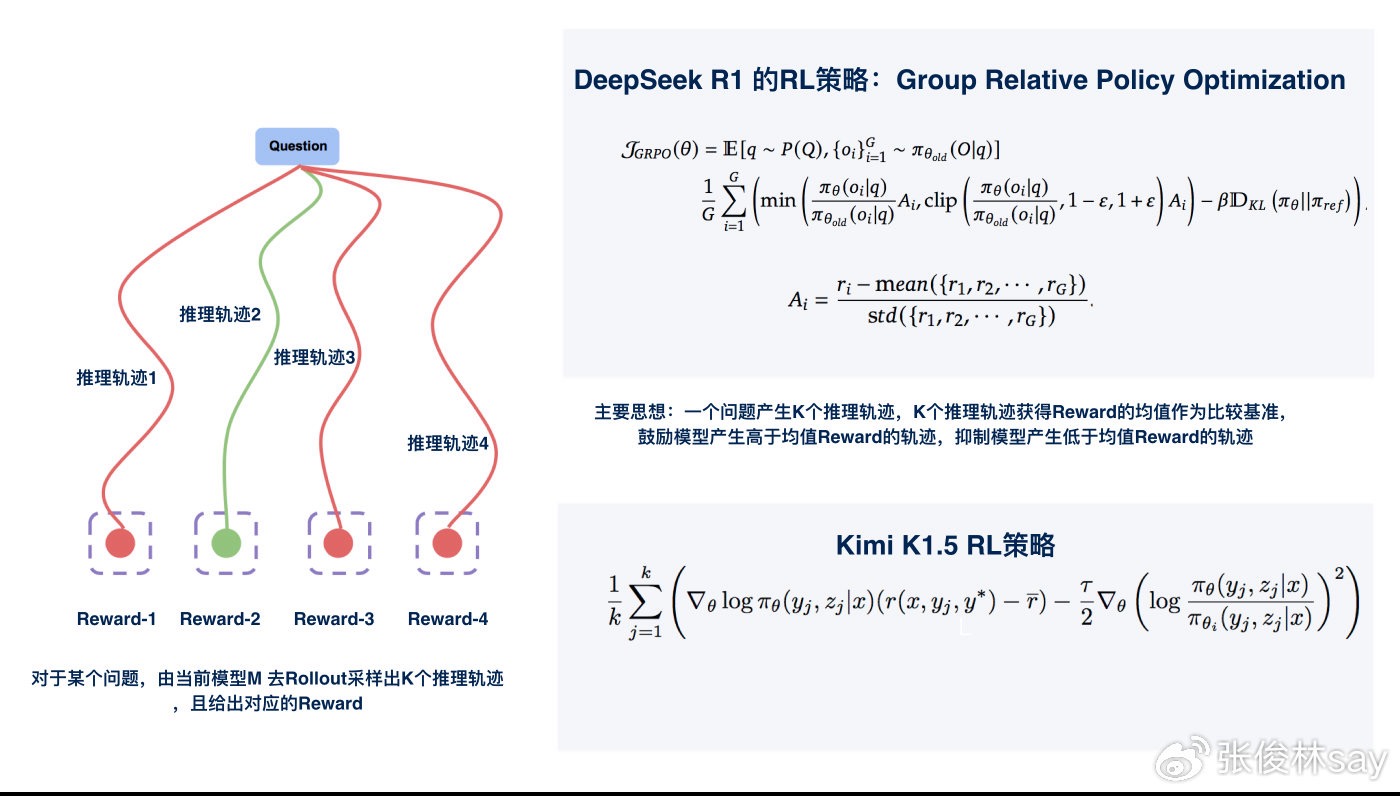
RL策略
第二个阶段则采用强化学习(RL)进一步优化模型的复杂逻辑推理能力(R1和K1.5的RL阶段做法非常接近,这里一起说了)。这个过程其实和传统的RLHF基本类似,只是RL策略里去掉了不太好调试的RM模型。具体而言(参考上图),在经过SFT后的模型Model-SFT基础上,比如我们现在拿到一个问题以及对应的标准答案数据<问题,标准答案>,此时让Model-SFT自己产生K条完整的推理轨迹COT,以及对应的答案。ORM(结果回报模型)根据某条推理轨迹产生的答案是否和问题的标准答案相同给出Reward,符合标准答案给出正向高回报,不符合标准答案则负向低回报(上图左部)。
同一个问题,K个推理轨迹,K个答案,产生高低不同的K个回报。我们可以认为得到高回报的推理轨迹质量高,于是,我们希望根据目前得到的这些数据,来调整下模型参数,让模型以后倾向输出那些高回报的推理轨迹COT作为思考过程,而别产生那些低回报的推理轨迹COT,这是强化学习希望达到的目标。Deepseek R1和Kimi K1.5的具体RL策略展示在上图右侧,两者核心思想高度一致:一个问题产生K个推理轨迹,以K个推理轨迹获得Reward的均值作为比较基准, 鼓励模型产生高于均值Reward的轨迹,抑制模型产生低于均值Reward的轨迹。通过上述策略修正模型参数,即可达成我们希望RL达成的目标,让Model-SFT产生质量越来越高的推理轨迹COT。
如果对大模型Post-Training比较熟悉的同学可以看出来,Kimi K1.5这种做法和标准的Post-Training流程基本是一样的,主要区别在于:传统的大模型SFT阶段是用人写的标准答案,而此时换成了用模型产生并人工校准的推理轨迹COT及答案;而RLHF阶段做法则基本一致。
Deepseek R1的做法
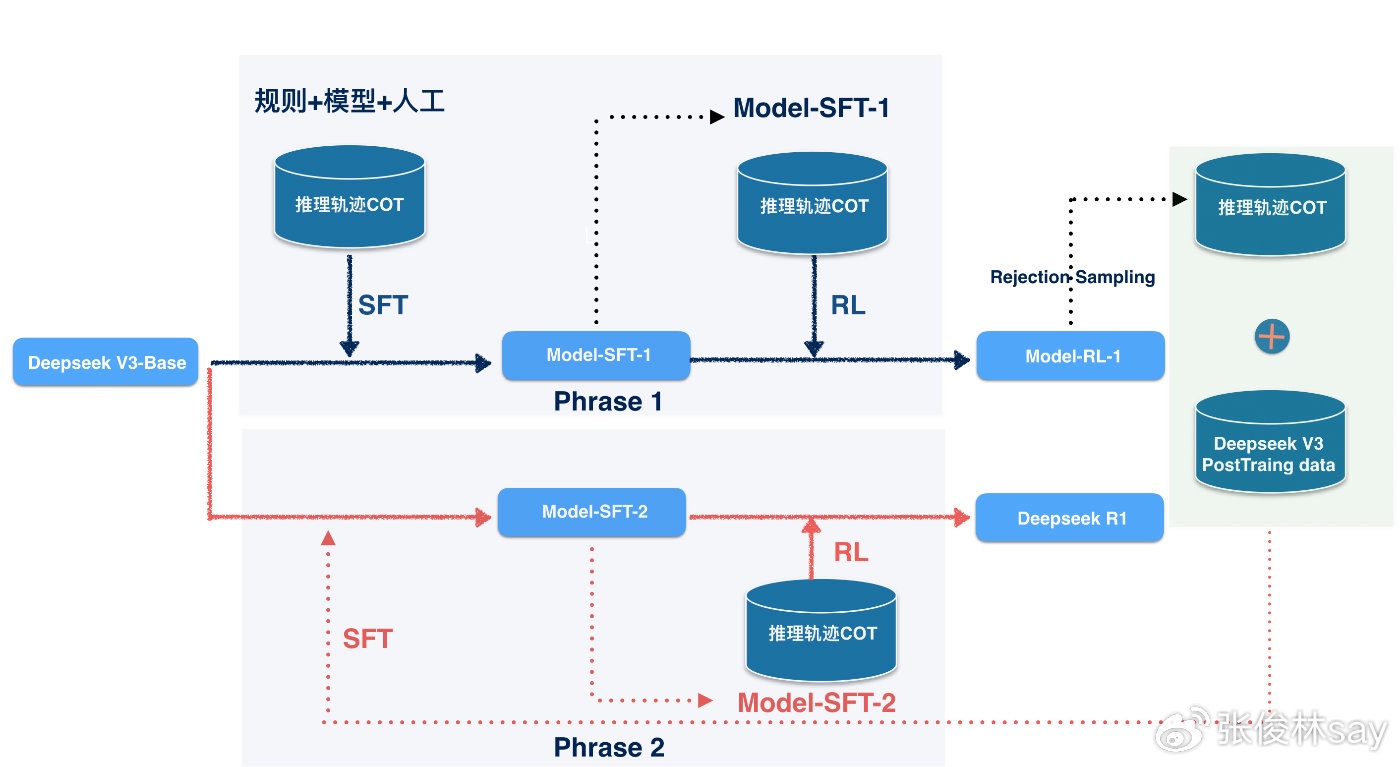
Deepseek R1
Deepseek R1的训练过程看着稍微复杂一些,但是若你仔细分析就会发现,Kimi K1.5其实可以看作Deepseek R1的一个特例。如上图所示,Deepseek R1训练可以划分成两个大的阶段,第一个阶段(Phrase 1)基本就是上述Kimi K1.5的做法,此处不赘述,这里的基座是Deepseek V3 Base,也就是预训练版本模型。区别在后面,对于Kimi来说完成第一个阶段就是最后的模型了,而对于Deepseek R1来说,阶段一只是个辅助过程,经过阶段一RL训练稳定后的模型Model RL-1,其主要目的是用来产生比第一次SFT阶段更高质量的推理轨迹COT数据,产生完新的数据就被抛弃了,我们要新产生的数据但是不要之前的旧模型。
然后,用Model RL-1产生的新COT数据,再加入Deepseek V3在Post-training阶段的数据(非逻辑推理类的数据,加入是为防止模型经过逻辑推理数据调整参数后产生的再难遗忘,导致其它非逻辑推理类任务效果变差,这是标准做法),进入第二阶段(Phrase 2),其过程和Phrase 1是一样的,内部也分为SFT和RL两个阶段,主要不同在于SFT用的数据集合换掉了,仅此而已。
但是这里需要注意一点,也是我认为训练逻辑推理模型过程中值得关注的技巧:第二阶段的基座模型是最开始选择的基座模型Deepseek V3 Base,而不是经过阶段一强化过的Model RL-1。这个很重要,道理也好理解,我们可以认为Phrase 1里SFT阶段的逻辑轨迹COT数据质量不够高,尽管经过RL有所增强,但比起Model RL-1产生的逻辑推理数据来说仍有所不如,所以可以把Model RL-1反向看成被低质量数据污染的模型,与其如此,不如直接用更好的数据在干净的Base模型上调整,这样效果应该更好。微软的MSCT思路模型rStar-Math里也反复采用了这一技巧,进行了四轮迭代,每次迭代都产生更好的训练数据,但策略模型的基座都是刚开始的干净Base模型,可见这一手段是很重要的训练逻辑推理模型的技巧。
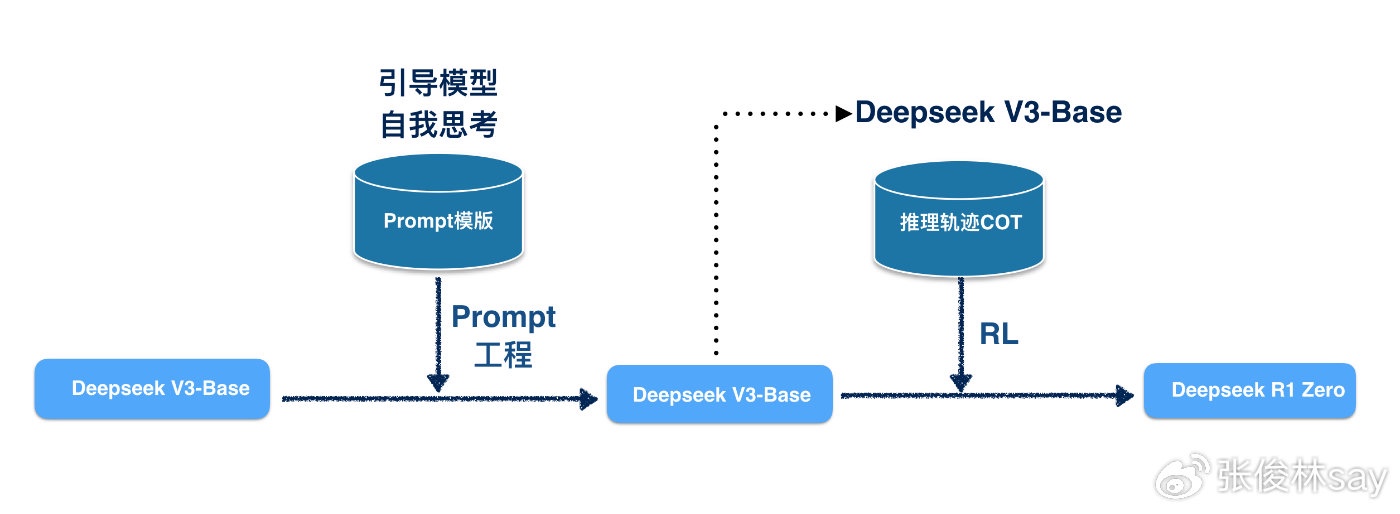
R1 Zero
谈完R1我们再来看R1 Zero,对比上面R1 Zero的训练过程图和Kimi K1.5的训练过程图,可以看出,R1 Zero的RL步骤和R1是完全一样的,最主要区别是没有用采集好的推理轨迹COT数据来通过SFT启动模型。但是,Zero也不是凭空进行RL的,你可以认为是用Pormpt工程的方式替代了SFT阶段,当基座模型能力足够强,写一个Prompt模版,要求它启动深度思考模式且输出满足我们期望的格式,这个强能力基座肯定可以办到。类似思路,可以参考OpenAI刚推出O1的时候的复刻模型Thinking Claude( https://github.com/richards199999/Thinking-Claude ),就是在Claude 3.5基座基础上,通过写Prompt模版的方式,来让Claude看上去像o1那样产生推理轨迹COT和答案,如果Thinking Claude再加上RL阶段去调整模型参数,我们就能获得R1 Zero。
由R1和K1.5可推导出的更通用的方法
前文有述,我们可以把K1.5看成是R1的一个特例,通过思考两者的关系,其实在R1的两个阶段基础上,我们可以进一步推广,形成更通用的一种多阶段训练类o1模型的思路。请参照上文提到的R1训练过程图,那里R1只进行了一次Phrase 1,而我们完全可以多次重复R1的Phrase 1阶段,在最后一个阶段使用R1的Phrase 2,如此这般,就能形成更通用的多阶段做法。比如我们设计4个阶段,第一阶段类似R1的Phrase 1,得到Model RL-1,使用它产生更高质量的推理轨迹COT数据,然后用这些数据对干净的Base模型进行SFT,开启Phrase 2,得到Model RL-2,由Model RL-2产生质量更进一步的推理轨迹COT数据,如此重复几次,最后一个阶段采用R1的Phrase 2策略,补充标准Post-Training阶段训练数据,防止对通用能力的灾难遗忘问题。
而且,在后续的阶段里,可以逐步增加难题占比,采用类似“课程学习”的思想:先从简单问题学起,逐步增加问题难度。在K1.5和rStar-Math都有提到,而且也都通过实验证明了逐步增加问题难度的有效性,所以这也是一个重要技巧。R1虽然没有提,但我猜也应遵循了这个思想,R1 Zero在RL阶段随着训练往后进行,输出Token数逐步增加,也可以推出越往后的训练阶段,难题数量越多的趋势。
由R1和K1.5训练方法引出的疑问及推论
在制作推理轨迹COT训练数据时,我之前认为对于复杂问题对应的推理轨迹COT来说,我们希望尽量减少中间步骤的错误,最好是得到推理轨迹COT中每个推理步骤都完全正确,且最终答案也正确的训练数据,这样的数据才是好的训练数据,经过这种训练数据训练出的逻辑推理模型才能解决好高难度问题。但若根据Deepseek R1和Kimi K1.5的做法反推,我能得到的推论是:推理轨迹COT中间推理步骤是否错误这事好像不重要,存在相当多中间步骤错误的训练数据,也一样能训练出强大的推理模型。我看完几篇论文综合信息推出这个结论后,刚开始觉得有点不可思议,但貌似事实确乎如此。
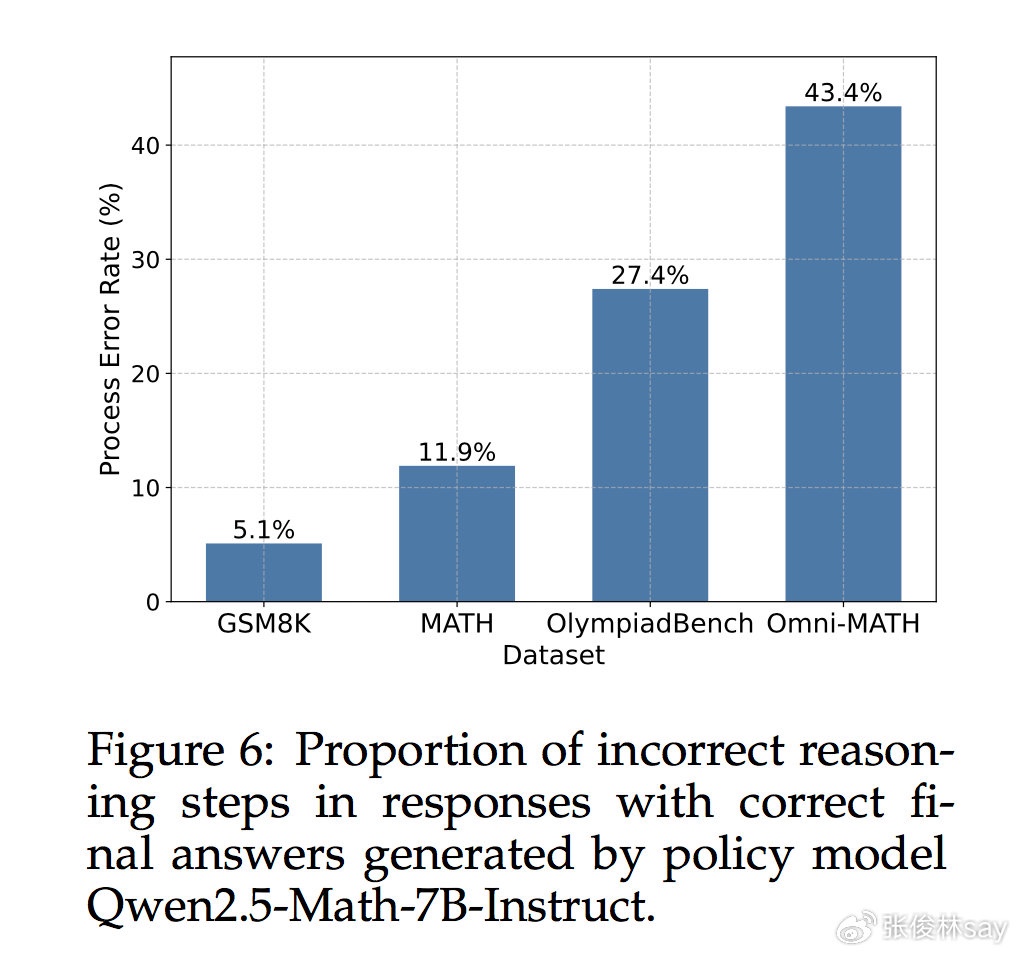
阿里PRM改进论文
我刚看完R1相关论文的疑问来自于:R1也好,K1.5也好,在制作SFT数据以及RL阶段产生推理轨迹COT数据时,是通过模型生成完整的推理轨迹COT,然后比较模型产生的最终答案和标准答案,根据两者是否相同筛选一下,去掉模型答案和标准答案不一致的数据,或者这种情况给个低Reward。
但是,很明显通过这种方法产生的推理轨迹COT中,存在很多中间步骤的错误,证据来自阿里关于PRM改进模型的论文(参考:The Lessons of Developing Process Reward Models in Mathematical Reasoning),可以参考上图,这个图说的意思是:通过Qwen2.5 Math对问题给出推理轨迹COT以及对应的答案,他们手工检查了一下,存在大量结果正确但是推理轨迹COT中包含错误中间步骤的数据,比如上图Omni-MATH数据,经检查发现有43%的数据推理轨迹COT中有错误中间步骤但是最终给出答案是正确的。而且很明显,越是困难的问题集合中,使用模型给出的推理轨迹COT中,包含错误中间步骤的比例会越高。
这意味着,R1和K1.5制作训练数据过程中,尽管经过和标准答案进行对比进行了筛选,但其产生的推理轨迹COT中,仍然有相当比例的数据存在中间步骤错误,而且越是困难的题目包含错误数据的比例越高(K1.5讲到了一些控制这个问题的办法,比如把选择题这种类型去掉,因为容易猜中答案但是推理过程是错的,但是在这里不适用,比如Omni-MATH是数值类型的答案,非选择类型,这个问题依然很严重)。但明显R1的做法又是有效的,所以综合两者,我得出上面的推论:存在大量题目,由模型给出的推理轨迹COT数据中包含中间步骤错误,但是这影响不大,用这种数据仍然能训练出强大的类o1模型。
如果在此基础上进一步深入思考,能得出更多更有趣的推论。比如,我们假设一种极端情形:模型给出的推理轨迹COT所有中间推理步骤都是错的,那么毫无疑问,用这种训练数据不太可能训练出好的类o1模型。结合第一个推论,就是说推理轨迹中存在中间步骤错误也没事,那么事实的真相很可能是这样的:某个推理轨迹COT的中间步骤存在错误是OK的,但是错误的中间步骤在总推理步骤的占比不能太高,应该是越低越好。就是说,我们不用介意某个推理轨迹COT中是否包含错误中间步骤,但是要考虑错误中间步骤的占比情况。所谓高质量的推理轨迹COT数据,应该是错误中间步骤占比低的数据。比如说,我们有10个问题,模型对于每个问题给出一个包含10个步骤的推理轨迹COT,即使是10个轨迹每个都包含错误中间步骤也没事,但是,如果10*10共100个推理步骤中,有50个中间步骤是错误的,那么相比只有10个中间步骤是错误的推理轨迹数据,10个中间步骤错的就是高质量的推理轨迹数据。
而前面提到多阶段的类o1训练过程,后一阶段之所以能进一步提高推理轨迹COT数据的质量,其核心含义应该是:越往后阶段的模型Model RL-i,由其产生的推理轨迹COT训练数据中包含的错误中间步骤比例,要比Model RL-i-1模型产生的错误数据占比来得要低。由此体现出训练数据质量越来越高的含义。当然,这也只是一个推论。
如果在此基础上再进一步思考,还能得出更有趣的推论。这说明大模型从推理轨迹训练数据中学到的是片段间的逻辑关系,而不是整体推理链条的正确性。就是说学到的是由步骤i可以推导出步骤i+1,这种细粒度的推理片段和关联,这是大模型逻辑推理学习的基本单元。所以很长的推理轨迹中出现一些错误的步骤,只要它总体占比不高,那么这并不影响模型对逻辑基本单元间建立联系的学习。这也是个推论,我猜很可能是成立的,这也可以解释目前我们看到的现象,就是最强大模型比如o3,在逻辑推理能力方面已经超过了99%的普通人。这说明就复杂推理这个能力来说,可能我们传统的理解有点问题,大模型比人类更适合学习复杂推理的过程,对于大模型来说就是把高概率的逻辑片段建立起迁移联系,一环套一环玩接力游戏就行,而人脑其实是不擅长学习长链条的推导知识的。
二.可行的MCST做法
rStar-Math技术方案
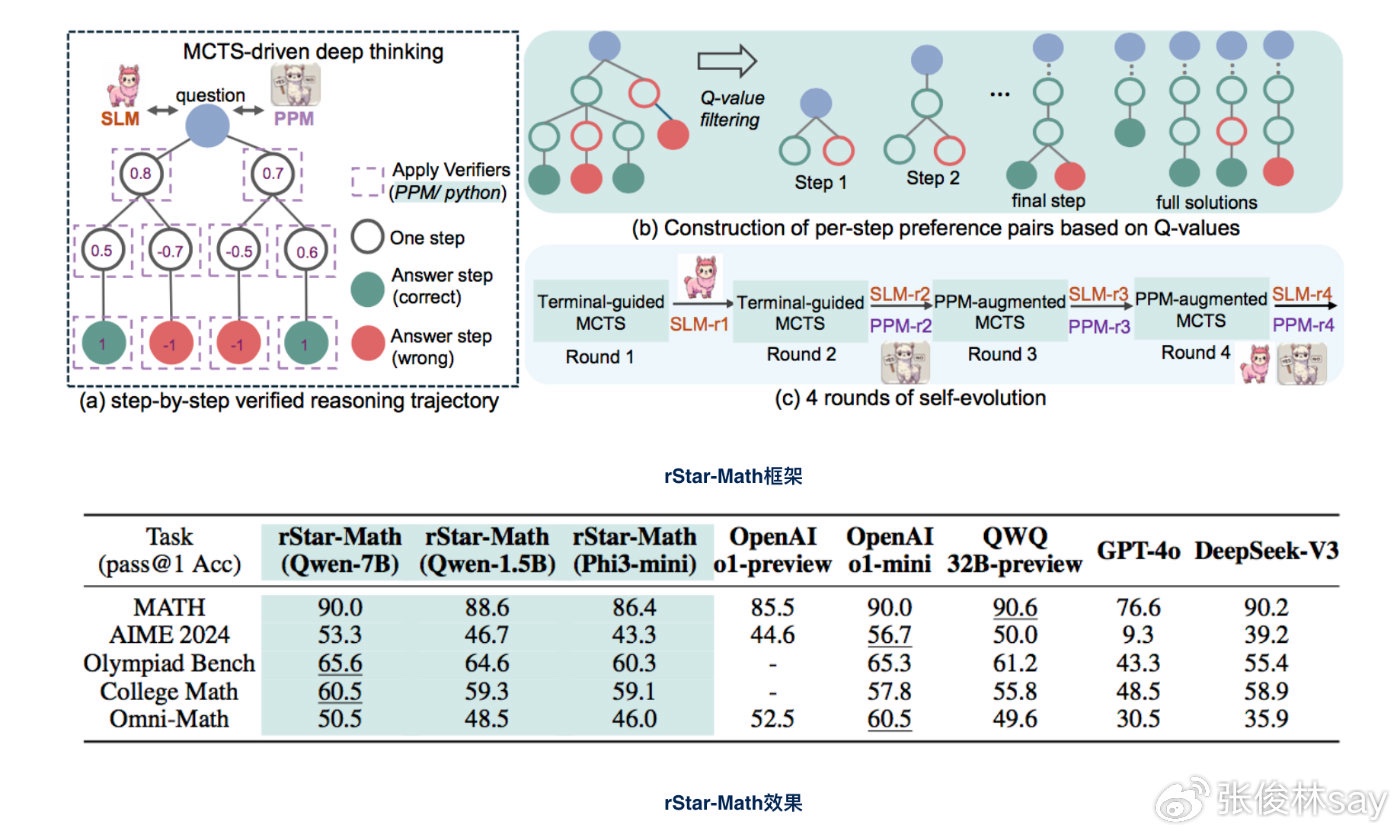
rStar-Match
rStar-Math已算是众多复刻类o1模型里把MCST路线走通的典范,而且仅使用了相当有限的机器资源达成的(4×40GB A100 GPUs),所以树搜索技术方案也不存在说因为太消耗资源一般人做不了的问题。上图展示了其架构、做法及效果,可以看出即使是1.5B和7B的模型,效果提升都非常大,如果换成更大规模的模型,各种评测指标肯定还能大幅提升,无疑rStar-Math已经验证了MCST路线是可行的。
具体方案这里不展开了,建议仔细阅读下论文。之前确实很多尝试MCST的方案不算成功,这说明不是技术路线的问题,而是魔鬼在细节,某个细节没做对就很容易导致整体技术全面失败。我觉得rStar-Math相比之前很多MCST方案做得好的主要有两点:第一个是训练分成了4个阶段,采取类似课程学习的思想,越往后迭代增加更多比例的难题,目前看这一点也是复刻类o1模型成功的重要技巧之一;
第二是综合出一个更好的PRM策略。MCST很难做成功的最大阻碍是PRM不太好做,大家一般会模仿AlphaGo,到了某个推理中间步骤S,然后从S出发rollout出多条之后的推理轨迹,直到产生最终答案,然后看下从S出发的多个后续轨迹中,有多少导向了正确的最终答案,导向越多正确最终答案的则Reward越高。这种做法从思想上来看是非常合理的,但是问题在于:其实从S出发导向最终正确答案的rollout轨迹里,很多都包含中间推理过程的错误,导致如此评估出的Reward不准确(这个结论请参考前面提到的阿里改进PRM的工作)。
Reward是指导MCST搜索方向的重要信号,Reward不准自然导致搜出来的推理空间轨迹质量就不够高。rStar-Math在这里综合了三个策略:一个是把推理轨迹改成代码的形式,这样可以通过程序验证筛掉不靠谱的路径,等于用代码验证的方式对搜索空间进行了剪枝,干掉了大量肯定错误的中间节点;另外一个提出了Process Preference Model (PPM),这个类似DPO的思路,引入正负例一起评估,评估的对象其实是从问题根结点出发,到S步骤之前所有推理步骤的质量;再一个是传统的从S出发多次Rollout,这个评价的是从S步骤往后走导向正确答案的概率。三者结合就能筛选出高质量的推理轨迹路径了,克服了只靠Rollout评估不准的问题。
PRM应该是限制MCST方法的关键,但是目前看这个问题基本得到了解决,核心思想是不能只靠经典的rollout来评估结果作为PRM,要结合其它因素一起。比如阿里改进PRM的策略除了Rollout,还引入其它大模型作为判断者(LLM as a dudge),两者评判一致才算数,且极大增强了PRM判断的准确性。如果后续做MCST方案,建议可以直接用阿里发布的新型PRM或者参考rStar-math的思路,相信效果提升会比较明显。MCST方案的核心是提高PRM的准确性,随着改进方案的逐步提出,MCST方案的效果也会越来越好。
Deepseek R1和Kimi K1.5采用的方法是MCST方法的特例
在复刻类o1模型的赛道里,怎样的算法是好的算法呢?我觉得评判标准是:找到高质量推理轨迹COT数据的效率,效率越高的算法越好。比如说前面提到一般我们需要对模型SFT+RL跑多个阶段,争取做到后一阶段产生的推理轨迹COT数据质量比前一阶段的更好些。假设有两个方法A和B,若方法A迭代两轮获得的推理轨迹COT数据质量相当于方法B迭代4轮获得的数据质量,我们就可以说方法A是个效率更高的方法,也是更好的方法。
MCST从机制上讲应该是效率非常高的算法,它等价于在巨大的可能推理轨迹COT组合空间里,通过PRM的指导和搜索策略尽快找到质量最高的路径,所以原则上第一轮迭代就能找到高质量的推理轨迹COT数据,肯定比随机产生的推理轨迹效率要高。而Deepseek R1和Kimi K1.5的做法则是给定某个问题,使用大模型产生一个答案正确的推理轨迹COT,直接使用这个COT,这等价于在树搜索空间里随机采样了一条最终答案正确的推理轨迹路径,如果PRM靠谱,推理轨迹COT的质量肯定不如MCST方法选出的数据质量高,所以很明显MCST是种效率更高的方法。我觉得,可以这么看这个问题:Kimi K1.5方法可看作Deepseek R1的特例,而Deepseek R1的做法本质上是MCST做法的特例(随机选择路径VS. 搜索高质量路径)。阻碍MCST的主要是不准的PRM,但如上所述,这个问题基本得到了解决,而且我相信未来会有更好的PRM技术方案出来进一步大幅提升MCST的效果。
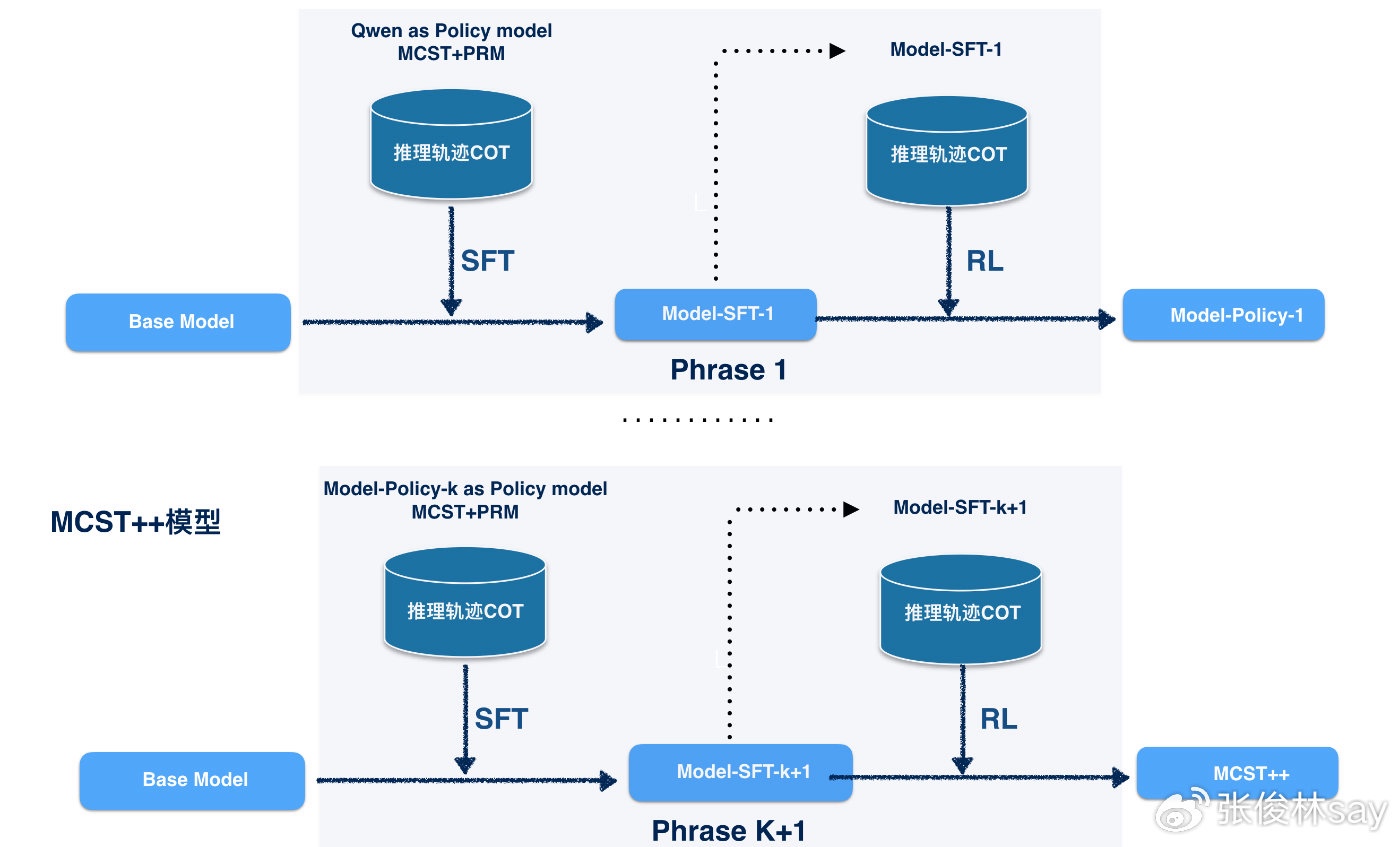
MCST++
既然是特例,若R1和K1.5方法有效,那么一定能推导出更通用的树搜索版本。我在这里推导一下,为后文指称方便,给推导出的模型随便起个名字比如叫“MCST++”。
如上图所示,MCST++本质上是对rStar-math这种有效MCST方法的改进,改进思路是引入R1里面的RL阶段,或者把它看成rStar-math和R1的结合版本也可以。
比如我们可以类似rStar-Math的做法,把训练过程分为符合课程学习原则,逻辑题目由易到难的4个阶段。rStar-Math每轮是通过策略网络(Policy Model)在树搜索过程中,针对某个中间节点S,扩展出m个子推理步骤内容扩展树结构,再结合PRM找到更好的路径,两者结合来搜索高质量的推理轨迹。在形成树结构后,找到一批高质量轨迹数据,用来调整Base模型,来作为下一轮MCST搜索的新的策略网络,此时策略网络经过训练,提出的子推理步骤质量会更高。PRM也会跟着更新,寻找好的节点也越来越准。这样形成通过自我迭代越来越好的效果。
rStar-math每一轮只通过从MCST树中找到更高质量的推理轨迹COT数据来SFT base模型,以改进策略网络的效果,并没有类似R1的RL过程。很明显,此时,我们可以把R1的RL过程引入策略网络,在策略网络进行SFT后,叠加类似R1 的RL阶段,通过强化学习进一步提升策略网络的能力。在下一轮启动时,用经过SFT+RL两个子阶段强化过的模型作为新的策略网络,形成了策略网络的自我进化(PRM也可以跟着进化,策略类似rStar-Math,此处不展开谈了)。
这是从rStar-math角度看的,如果从R1角度来看,参考上面提到的“由R1和K1.5可推导出的更通用的方法”部分,其实改动的部分是把SFT阶段使用的推理轨迹COT数据来源,从由大模型随机生成推理轨迹COT,换成了MSCT树搜索的方式来获得SFT阶段的训练数据,RL部分是一样的。所以,本质上MCST++是融合了R1方法和rStar-Math的基于树搜索的模式,如果R1的RL阶段是有效的,而且如果“MCST树搜索相比随机采样能获得更高质量的数据”成立,那么必然就是一种有效的基于MSCT的树方法。所以这是为何前文说如果R1方法有效,一定可以推导出有效的MCST方法的原因。而且很明显,这种多阶段的方案是一种流程上更通用的方法。
三.All You Need is High Quality Logic Trajectory Data
目前看,对于打造更好的o1模型来说,最重要的是如何获得更多高质量的推理轨迹COT数据。这包括如何获得更多的<问题,答案>数据,尤其是有难度的问题。拿到<问题,答案>数据后,如何获得质量越来越高的中间推理轨迹COT数据,这里的质量很可能是根据错误中间步骤占比来衡量的,由此得到高质量的<问题,推理轨迹COT,答案>数据。这里的推理轨迹COT,可以是人工产生的,可以是大模型自己生成的,也可以是从其它模型蒸馏来得。获得方法貌似也不重要,重要的是质量是否越来越好,在此前提下,再考虑成本是否足够低。
从做推理轨迹COT数据的若干种方法来说,貌似大家对蒸馏都有发自种内心的回避感,都怕自己被人说用的是蒸馏数据,貌似自己用蒸馏来的数据就会被人瞧不起。我觉得这里有误区,数据质量好最重要,怎么得来的其实关系不大。那你说R1是蒸馏吗?其实本质上也是蒸馏(阶段一给阶段二蒸馏数据),无非是用自己的模型来蒸馏而已。蒸馏的本质含义是由模型来做数据而不是靠人,体现了数据制作自动化的思想,差别无非用的这个模型来自于自己的、还是开源或者闭源模型而已,这是符合制作高等AI所有环节尽量自动化的发展趋势的。
四.低成本快速增强大模型逻辑推理能力的方法
首先,找到大量<问题,答案>数据,包括STEM、代码、数学、逻辑等方面题目集合;
第二,对问题进行改写,从问题侧来扩充<问题,答案>数据的数量;
第三,引入开源的类o1模型,比如Deepseek发布的各种R1开源模型,
第四,使用R1模型制作推理轨迹数据,并标注出问题的难易程度:可以通过对问题使用R1模型多次Rollout生成推理步骤轨迹,比如一个问题生成8个推理轨迹,根据最终正确答案是否正确进行过滤,过滤掉最终答案错误的例子;形成<问题,推理轨迹COT,答案>数据集合。
第五,(此步骤可选非必需,但可能比较重要)找到一个好的PRM模型,比如阿里开源的PRM模型,对某个推理轨迹COT整体质量进行评估,比如回答某个问题的推理轨迹由10个推理步骤构成,根据每个推理步骤PRM得分的平均分,得出整个推理轨迹的得分,得分低者意味着轨迹中包含错误推理步骤比较多,说明整体质量低,把整体质量低的<问题,推理轨迹COT,答案>数据过滤掉,只用剩下的高质量推理轨迹数据。这一步等于提升推理步骤整体正确率,等价于提升训练数据质量。
第六,使用剩下的高质量正例对基座模型进行SFT,数据使用顺序采取课程学习思路,由简单题目到难题,或者逐步增加难题比例,由此得到最强逻辑推理模型
第七,如果你想让自己的技术方案看着更有技术含量一些,可以引入部分负例(最终答案错误的推理轨迹COT数据),结合正例做个DPO,我感觉是这步骤可选非必需。
这本质上是种数据蒸馏方法,好处是成本极低、实现起来速度快,能很快制作当前最强逻辑推理模型,如果都这么做,那谁更强取决于三个因素:谁有更多的题目,尤其是难题;类o1模型给出的推理轨迹质量,质量高者胜出;PRM模型的准确性,更准确者胜。
但是这个方法的缺点是缺乏自我进化机制,上面三个因素基本共同决定了能达到的效果天花板,缺乏通过模型不断迭代增强能力的机制。要想引入自我提升的模式,可参考上文提到的R1、K1.5或者MCST++的思路。
本文系转载,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文系转载,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号