为什么在 Kibana 中分配自定义数据视图 ID 很重要
原创
为什么在 Kibana 中分配自定义数据视图 ID 很重要
原创
点火三周
发布于 2025-06-17 11:46:55
发布于 2025-06-17 11:46:55
Kibana 中一个意想不到的强大功能是,在创建数据视图时可以分配自定义数据视图 ID。
在详细展开之前,我先简要概述一下本文的内容:
- 介绍我自己和我见过的一些事情
- 一个实际的使用案例
- 为什么事情会偏离预期
- 通过 Young Sheldon 的例子逐步讲解
- 团队容易遇到的问题
- 几个建议(老实说,你可以跳过前面的内容,直接看这一部分。)
- 总结
作为 Elastic 的咨询架构师,我每天都有机会直接与客户合作。职业生涯中,我使用过多种类似 SIEM 的工具,知道有些解决方案有多复杂——自定义语法像代码一样,界面让人望而生畏,上手慢,投资回报时间长。因此,我最喜欢 Kibana 的地方之一是看到用户发现它的直观性。
一旦数据被导入并可用,用户就能立即上手。仪表板和可视化随处可见。用户充满了兴奋和创造力。但随之而来的也有些混乱。
我经常看到这样的情况:有人为了熟悉 Kibana 而构建了一个仪表板,结果发现它非常好用,于是开始在生产中使用。这样做没有问题!但问题是:数据视图通常是临时创建的,带有相似甚至重复的属性。
为什么重复的数据视图很重要
让我通过一个场景来说明数据视图及其自定义数据视图 ID 如何影响可视化和仪表板。
3 个用户,3 个数据视图,1 个数据集
我们的用户是:Sheldon、Missy、Georgie 和 Paige。Sheldon、Missy 和 Georgie 是新的且充满热情的安全分析师,渴望探索和贡献。Paige 则是一位经验丰富的管理员和流程标准化专家,她不喜欢数字杂乱。他们一起在企业号宇宙飞船上工作。
星期一 – Sheldon:
Sheldon 在 Kibana 中研究 zeek 日志。他注意到没有现成的数据视图,于是创建了一个名为 Zeek 的数据视图,索引模式为 zeek-*。Kibana 为其分配了一个随机的数据视图 ID,例如 e4f6268b-9c4a-4f36-8a56-49ef18fbd147。他开始构建仪表板和可视化,并对结果印象深刻,认为它们可以投入生产使用。他的团队开始使用这些工具,大家都很喜欢,获得了认可。
星期二 – Missy:
Missy 第一次登录 Kibana。她知道 Zeek 数据已导入,但不知道 Sheldon 已经创建了一个数据视图。急于上手的她创建了一个自己的数据视图,名为 Zeek Logs,同样指向 zeek-*。Kibana 为其分配了一个不同的数据视图 ID,例如 04851901-723f-41fe-bdc7-3917b41aa1f7。她开始在 Discover 中探索,构建了一些可视化,并留待以后改进。
星期三 – Georgie:
Georgie 也新接触 Kibana,被界面吸引,迫不及待地开始。他又创建了一个 zeek-* 的数据视图,这次命名为 Dem Zeeky Zeek Logs,并分配了另一个随机生成的数据视图 ID,例如 b331a8a5-d7e1-412d-b83f-c5d9672ab0c1。然后他开始构建自己的可视化。
星期四 – Paige:
Paige 作为团队的专家,注意到多个针对相同 Zeek 索引的数据视图。她认为这些视图是多余的,于是开始清理,删除了 Sheldon 和 Georgie 的数据视图。在她看来,这只是整理工作。
星期五 – 混乱:
Sheldon 和 Georgie 再次登录后发现他们的仪表板坏掉了。可视化不再可用。为什么?因为仪表板中的可视化与现在已删除的数据视图相关联,而这些数据视图有唯一的随机生成的 ID。与此同时,Missy 的仪表板仍然正常工作。
为什么会这样?
这归结于 Kibana 如何处理保存的对象,比如数据视图。
当用户创建可视化、仪表板、数据视图等时,它们作为保存的对象在 Kibana 中被保存。这些对象之间存在关系。在这种情况下,可视化直接与用于创建它们的数据视图的 ID 相关联。因此,当 Paige 删除数据视图时,她无意中破坏了可视化与其依赖的特定自定义数据视图 ID 之间的关系。
这就是为什么我认为分配自定义数据视图 ID 应该被视为一种最佳实践。
如前所述,默认情况下,Kibana 会为数据视图分配长且随机生成的数据视图 ID。这些值是随意的,大多数用户难以记住以便重用。问题是,当一个数据视图被删除时,使用它构建的任何可视化都继续引用那个现在缺失的数据视图 ID。
从技术上讲,用户可以重新创建已删除的数据视图,并手动为其分配相同的随机生成数据视图 ID——如果他们保存了它的话。这样做将恢复损坏的可视化。但请注意:即便在这种恢复场景下,解决方案也需要分配自定义数据视图 ID。
那么为什么不从这里开始呢?
从一开始就创建一个直观的自定义数据视图 ID 命名标准,比如 zeek,可以显著改善工作流程。具体如下:
- 避免重复数据视图: Kibana 不允许多个数据视图使用相同的自定义数据视图 ID。如果有人尝试创建一个具有相同 ID 的新视图,他们会收到已存在的提醒。
- 简化恢复: 如果数据视图意外删除,用户可以快速使用相同的自定义数据视图 ID(例如 zeek)重新创建它,而不必记住复杂的值如 b331a8a5-d7e1-412d-b83f-c5d9672ab0c1。
- 支持更好的可扩展性: 当您的环境增长并管理数百个可视化时,这种小小的实践会带来巨大的差异。否则,用户可能在不知情的情况下创建多个与 Zeek 相关的数据视图,并在仪表板中传播它们。如果其中一些被删除,相关的可视化会崩溃——导致混乱和浪费时间。
这看似一个可以忽略的小细节,但我已经看到太多团队因为这个问题而陷入困境。事情很快就会变得混乱。从一开始就分配自定义数据视图 ID 可以为这种混乱带来秩序。
使用 Young Sheldon 数据进行演示(因为为什么不呢?)
Sheldon 使用 demo-young-sheldon 索引创建了一个数据视图。使用了以下参数:
- 名称: demo-young-sheldon
- 索引模式: demo-young-sheldon
- 自定义数据视图 ID: demo-young-sheldon
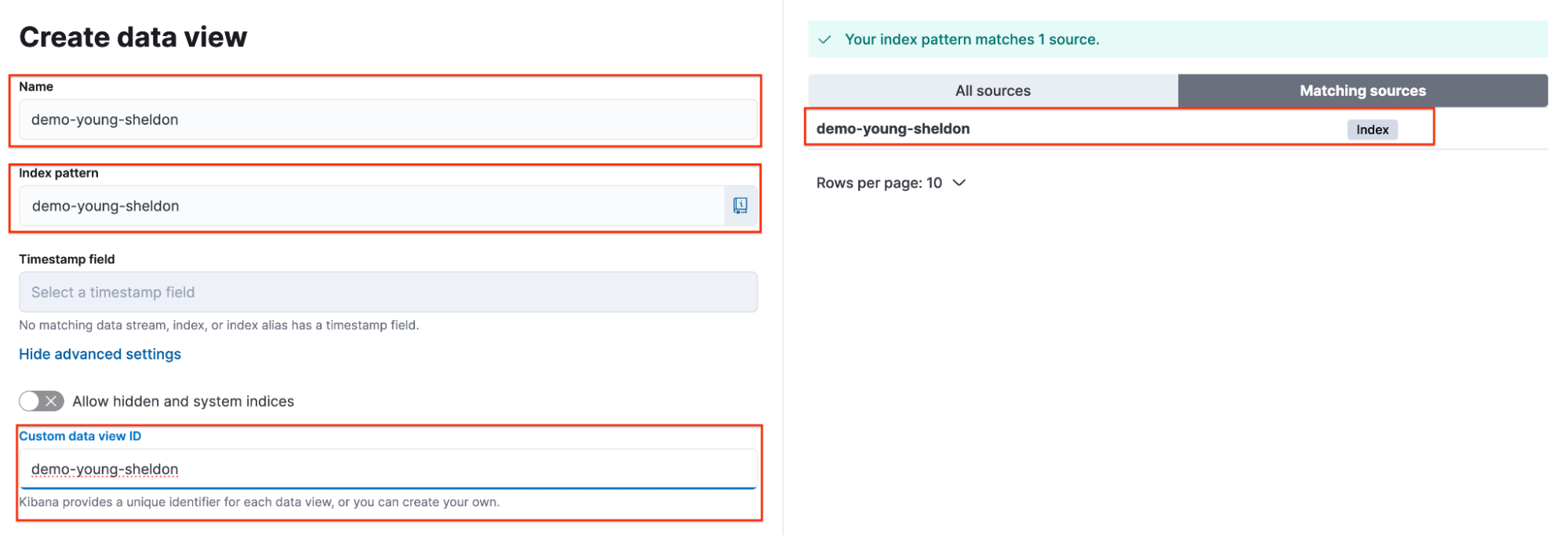
create data view
Sheldon 选择了数据视图并确认自定义数据视图 ID已正确设置。
注意: 这可以通过浏览器 URL 快速验证。
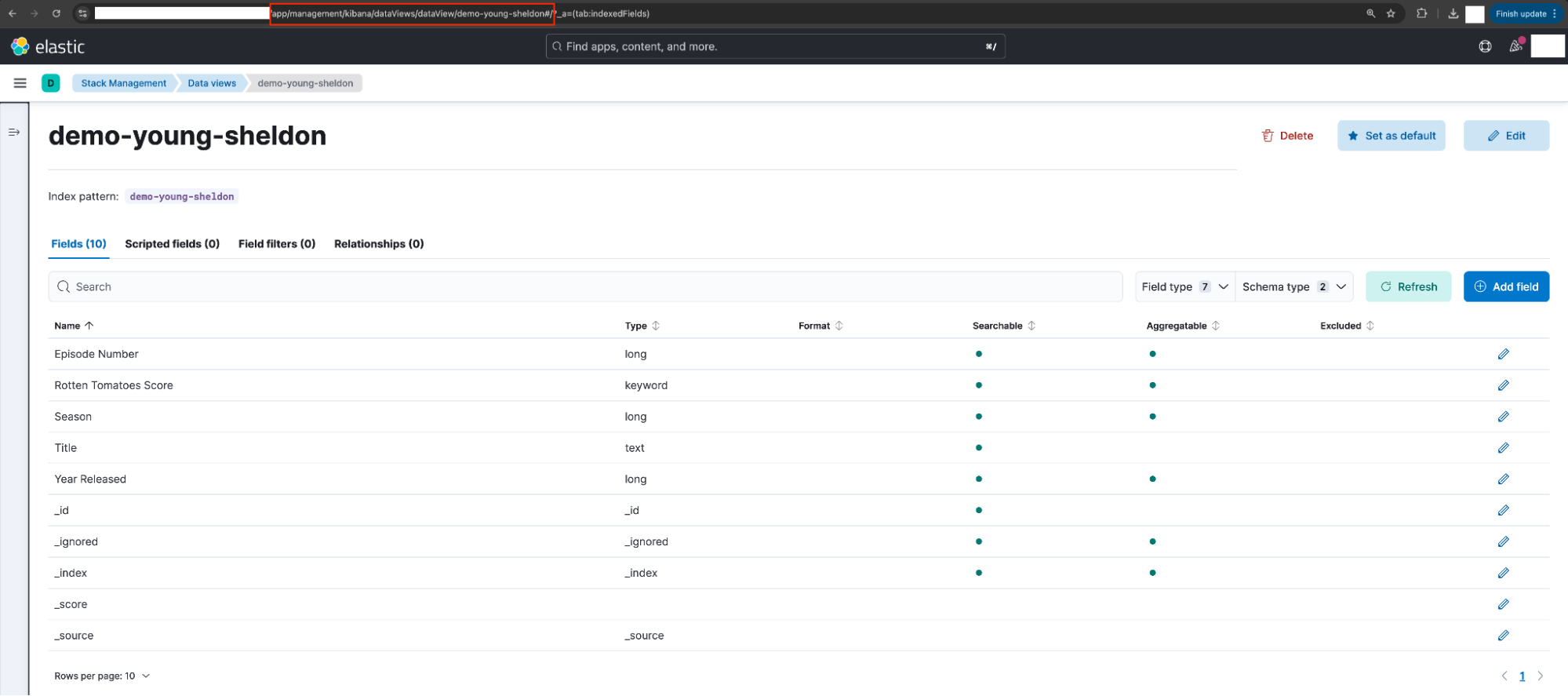
demo young sheldon
Georgie 使用 demo-young-sheldon 索引创建了一个数据视图。使用了以下参数:
- 名称: demo-young-sheldon-test
- 索引模式: demo-young-sheldon
- 自定义数据视图 ID: 空(未填写)
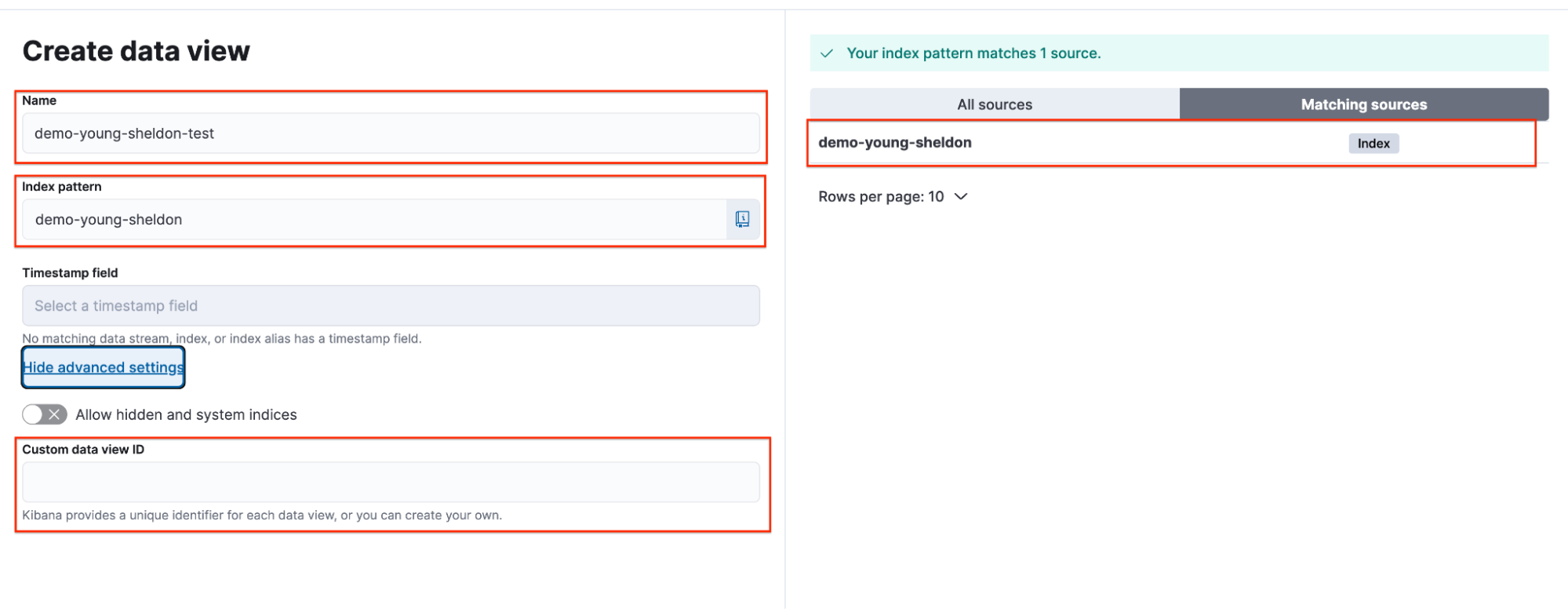
demo young sheldon test index
Georgie 选择了数据视图并确认因为 ID 留空,已被设置为自动生成的随机字符串。
注意: 这可以通过浏览器 URL 快速验证。
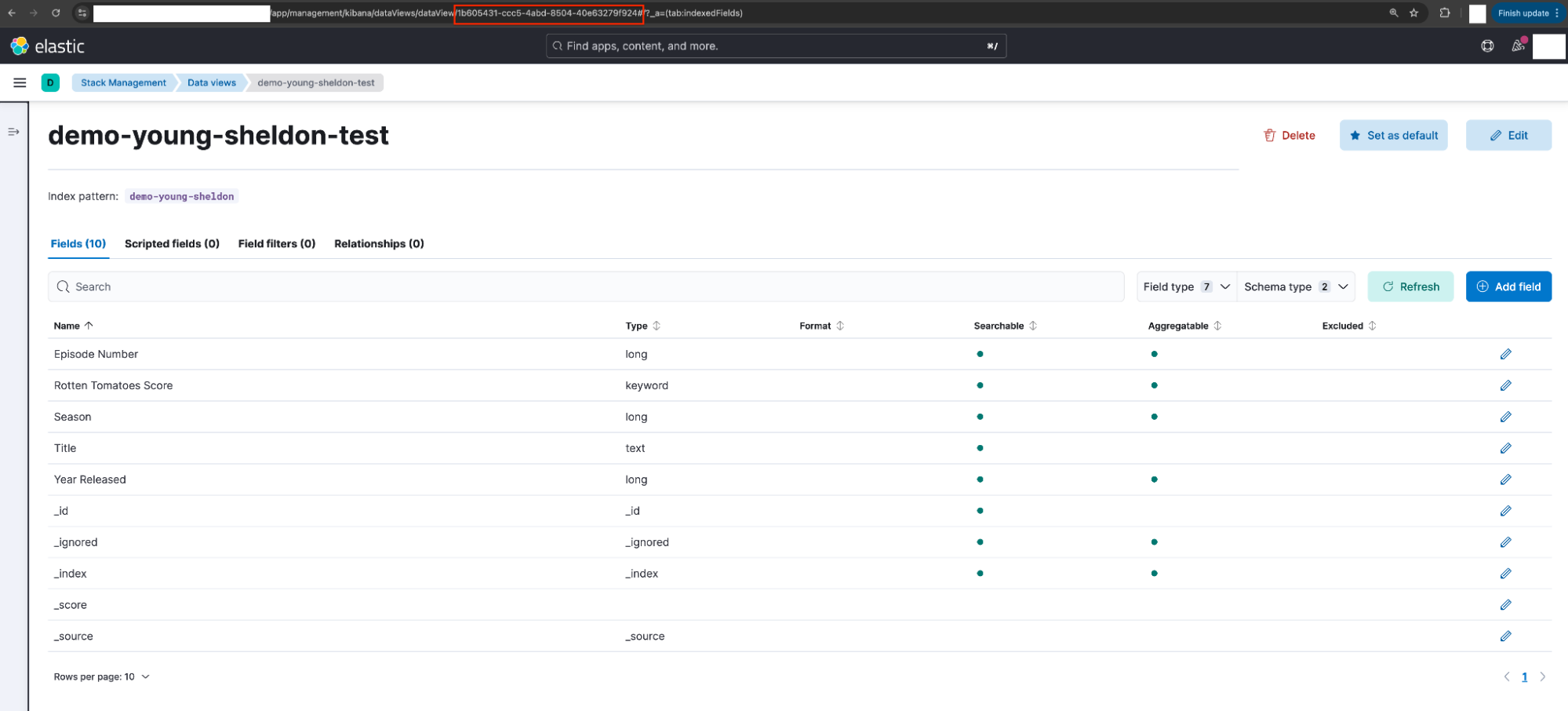
demo young sheldon test
Sheldon(demo-young-sheldon)和 Georgie(demo-young-sheldon-test)分别使用他们的数据视图创建了可视化并将其添加到共享的仪表板中。
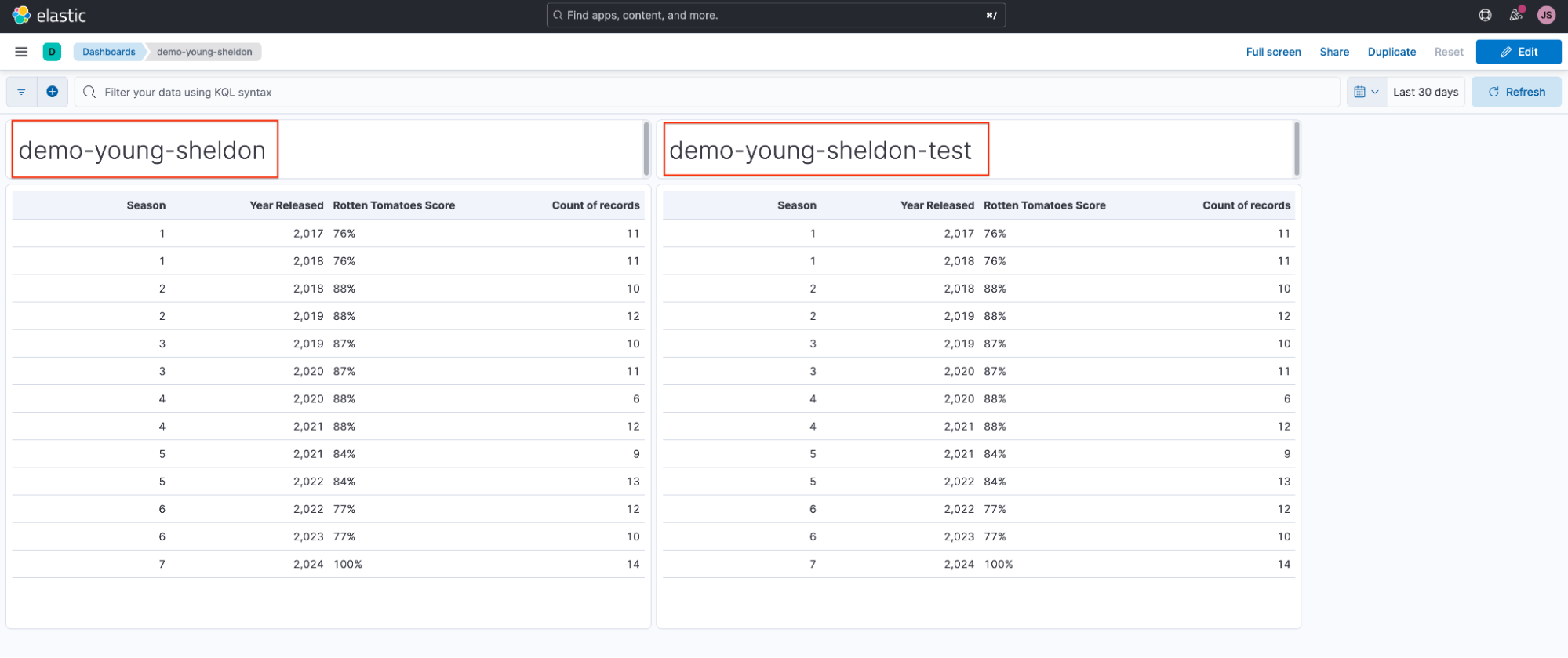
demo young sheldon two dashboards
Sheldon 和 Georgie 不小心删除了他们的数据视图,当他们返回到仪表板时,发现他们的可视化已损坏。
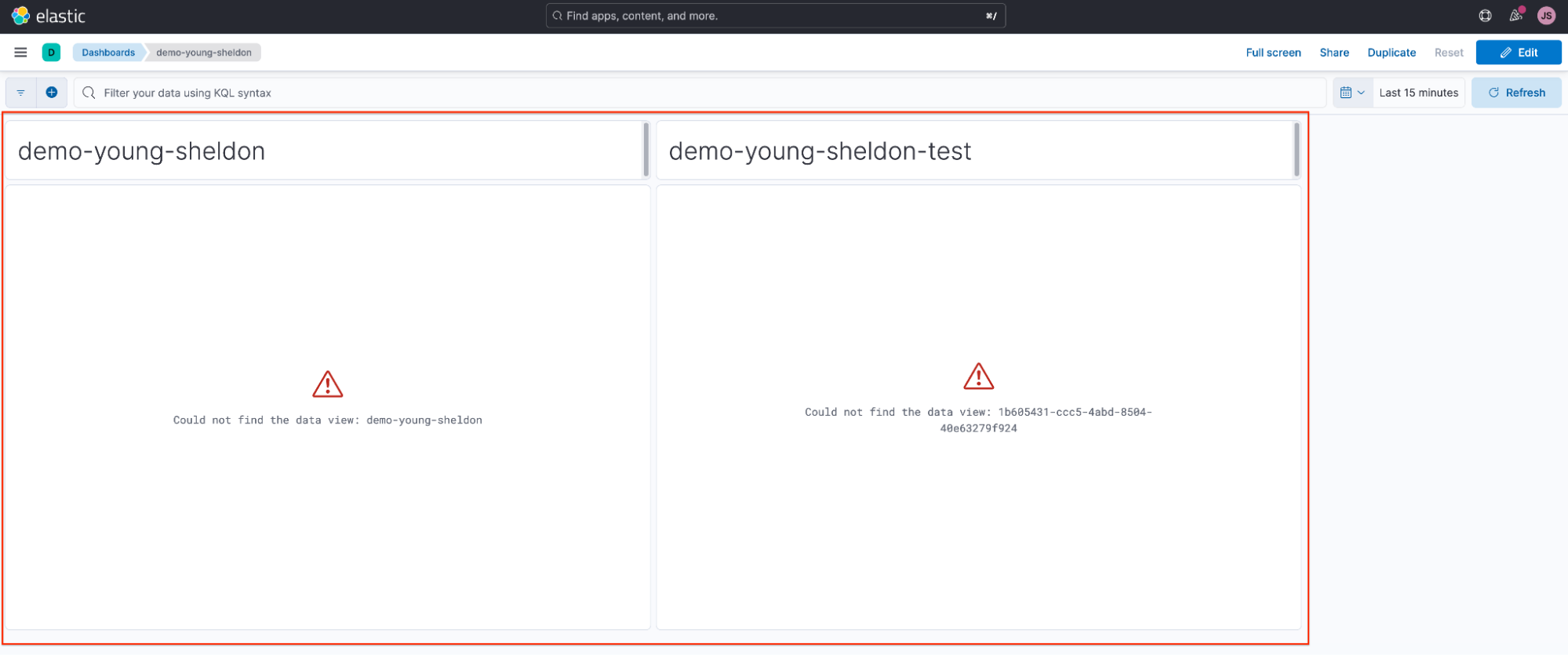
could not find data view
Sheldon 明智地为他的数据视图分配了一个自定义数据视图 ID,使恢复变得简单。为了恢复他的可视化,他只需重新创建数据视图并重用相同的自定义数据视图 ID: demo-young-sheldon。
使用了以下参数:
- 名称: demo-young-sheldon-recreated
- 索引模式: demo-young-sheldon
- 自定义数据视图 ID: demo-young-sheldon
注意: 在这个演示中,我稍微修改了数据视图名称以便清晰和区分早期步骤(名称: demo-young-sheldon → demo-young-sheldon-recreated)。
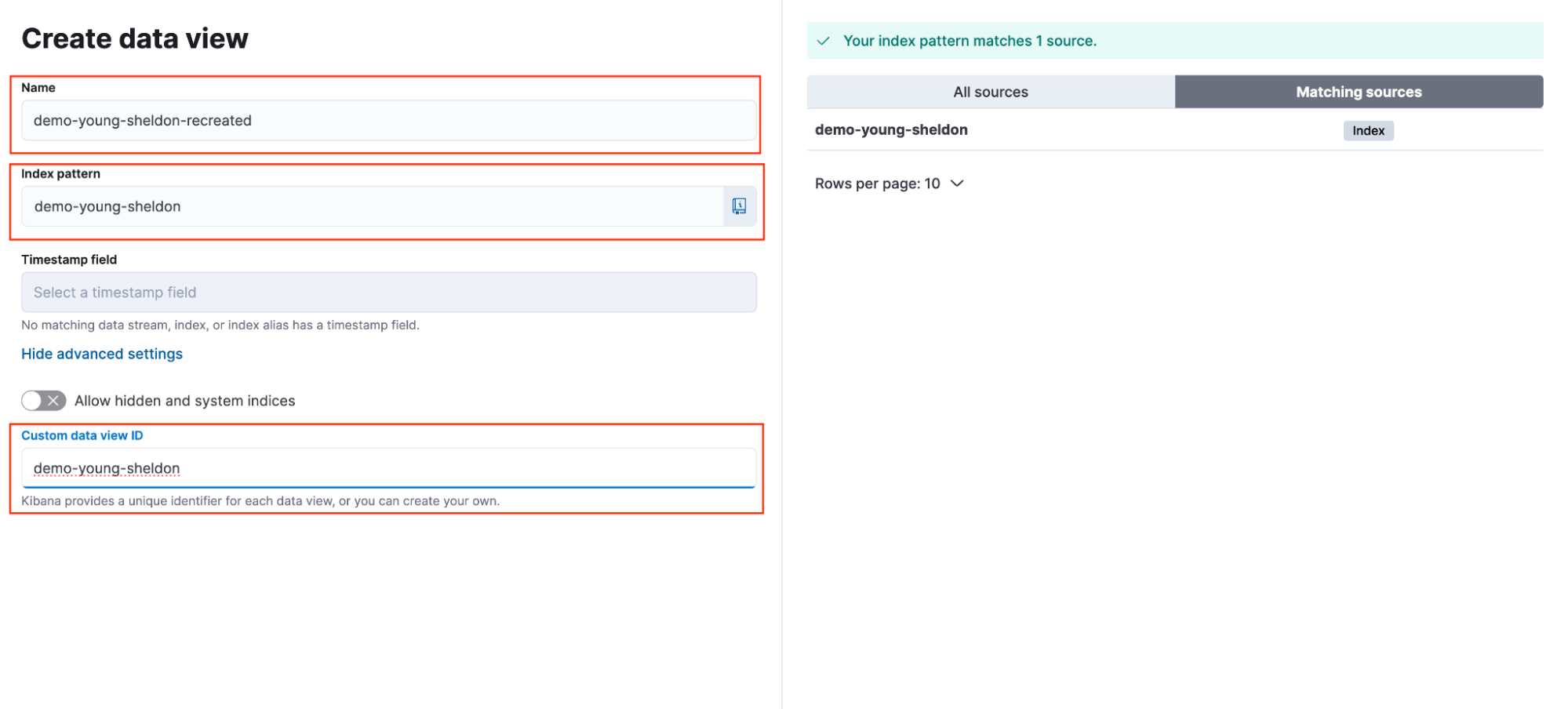
create data view
Sheldon 返回到共享的仪表板并确认他的可视化已成功恢复。
Georgie 可以按照类似的过程来恢复他的可视化。然而,他必须设置自定义数据视图 ID以匹配右侧图像中显示的随机生成字符串。
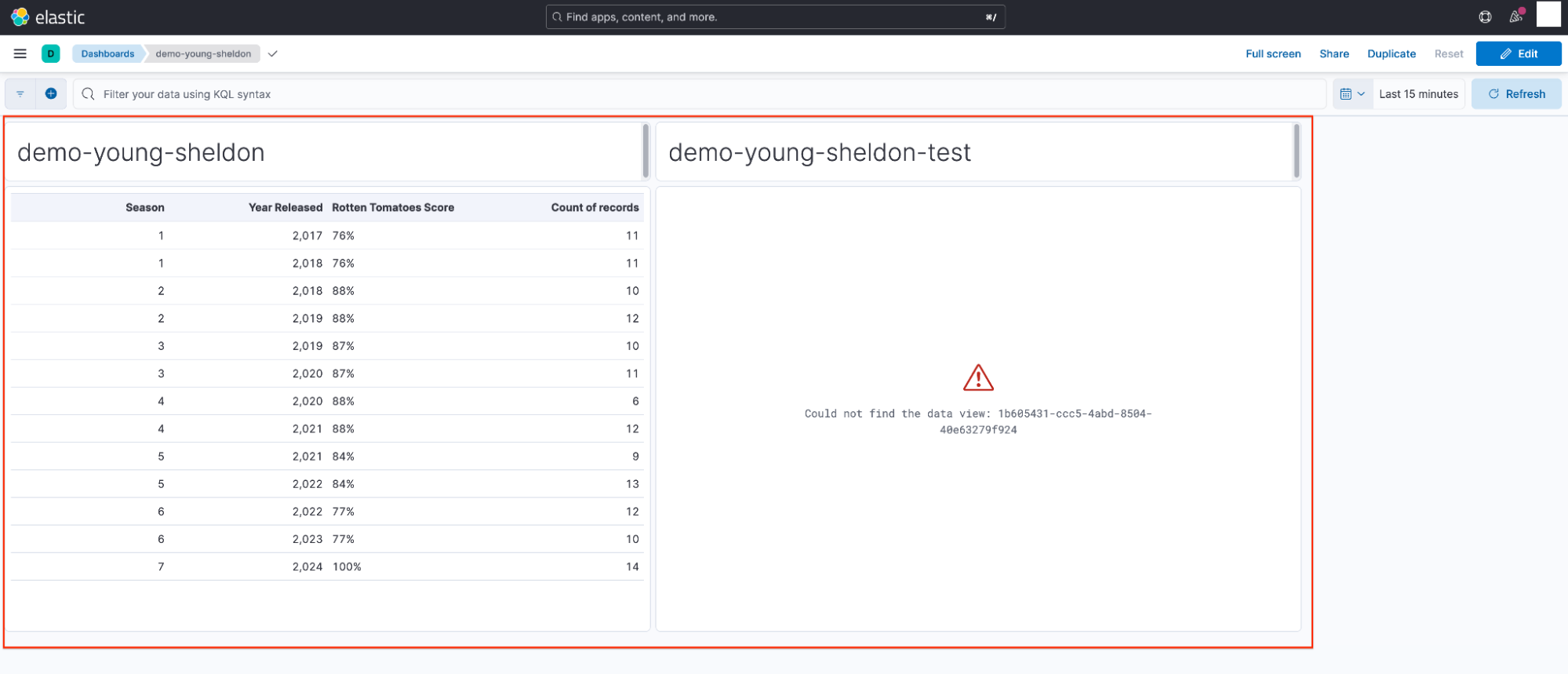
dashboard-demo-young-sheldon
你可能在想(也不完全错,但也不完全对)
你可能在想,“嗯,我可以重新创建_demo-young-sheldon-test_数据视图,并手动分配可视化中引用的相同随机生成的数据视图 ID。”

hmmm
你说得完全正确,这种方法确实有效——理论上。
但现在,让我们扩大这种情况。
假设你有 30 名用户,其中 10 名用户各自创建了他们自己的 demo-young-sheldon 数据视图变体,每个都有不同的、随机生成的数据视图 ID。他们使用这些不同的数据视图构建了数百个可视化,然后将这些可视化分布在多个仪表板中。
后来,有人查看环境时,看到有 10 个数据视图具有相似的名称和相同的索引模式。他们假设这些视图是重复的,删除了其中 9 个,未意识到每个视图通过数据视图 ID 独特地绑定到特定的可视化。
现在,你遇到了问题。 许多这些可视化分布在多个仪表板中,用户在很多情况下并不知道单个仪表板中的可视化没有使用相同的数据视图。例如,用户会注意到以下数据视图:zeek-1, zeek-2, zeek-3, zeek-4 和 zeek-5。
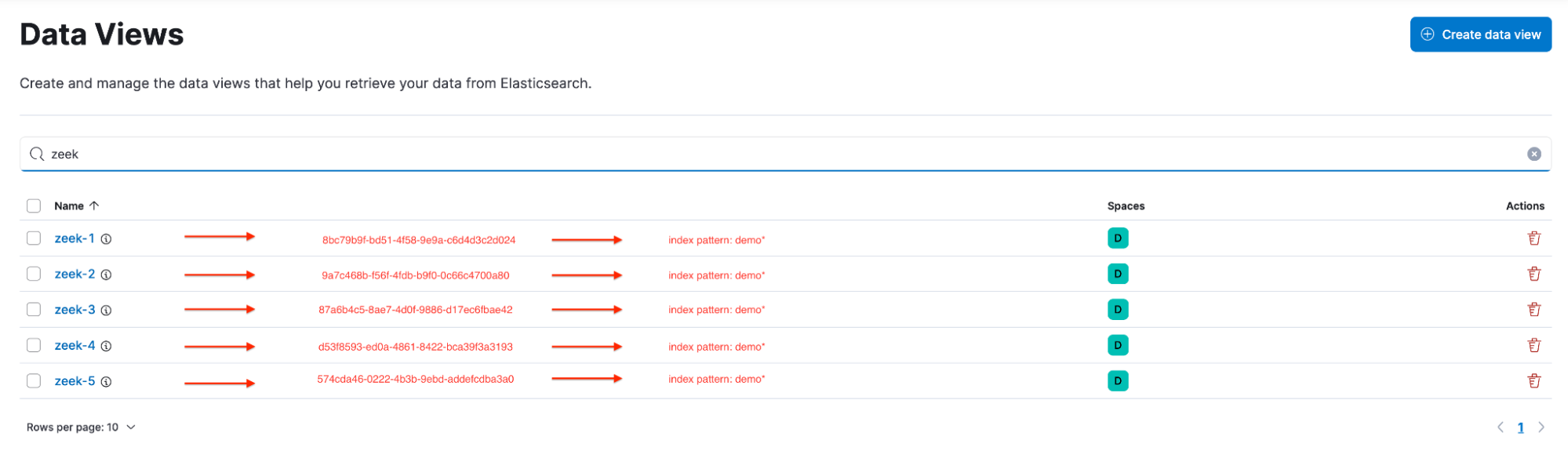
data views
由于所有的数据视图都指向相同的索引模式,用户在构建可视化并将其添加到共享仪表板时通常不会多想。
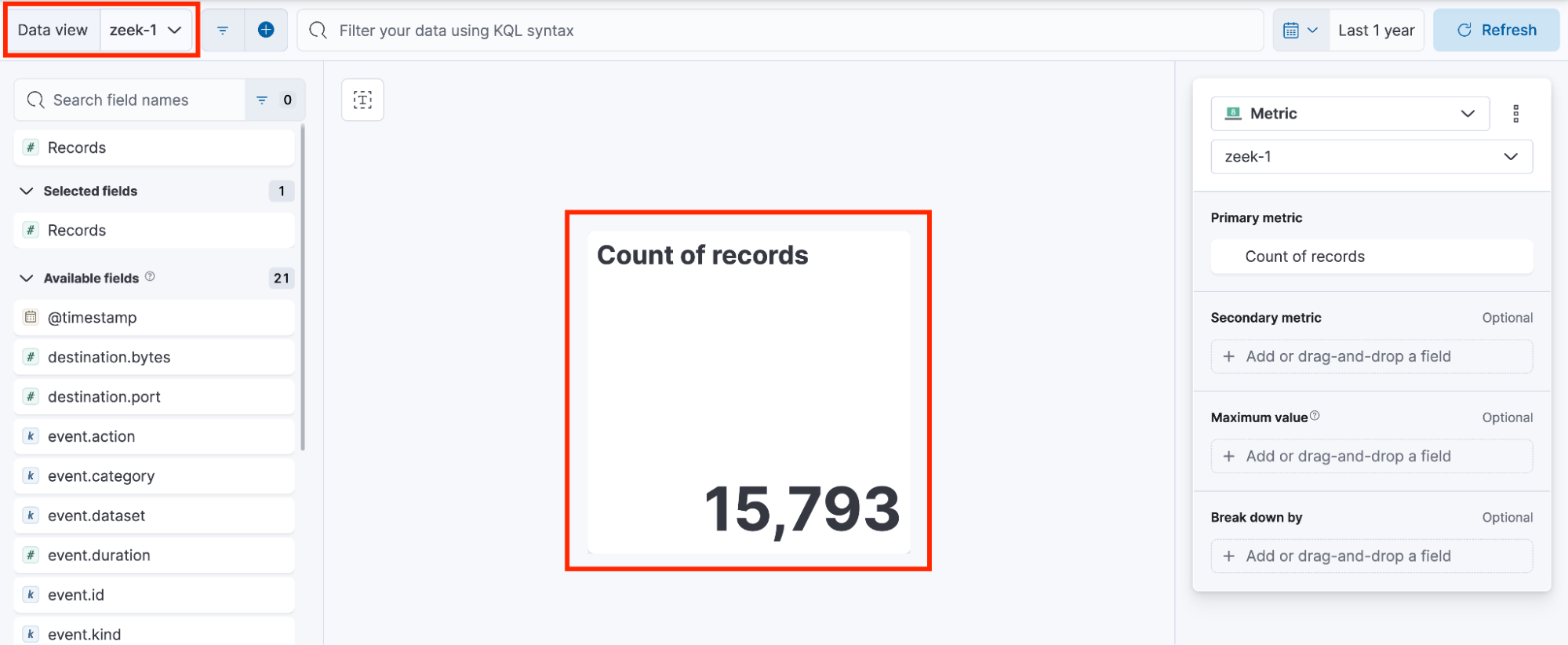
count of records number
可视化 1 使用 zeek-1 数据视图创建
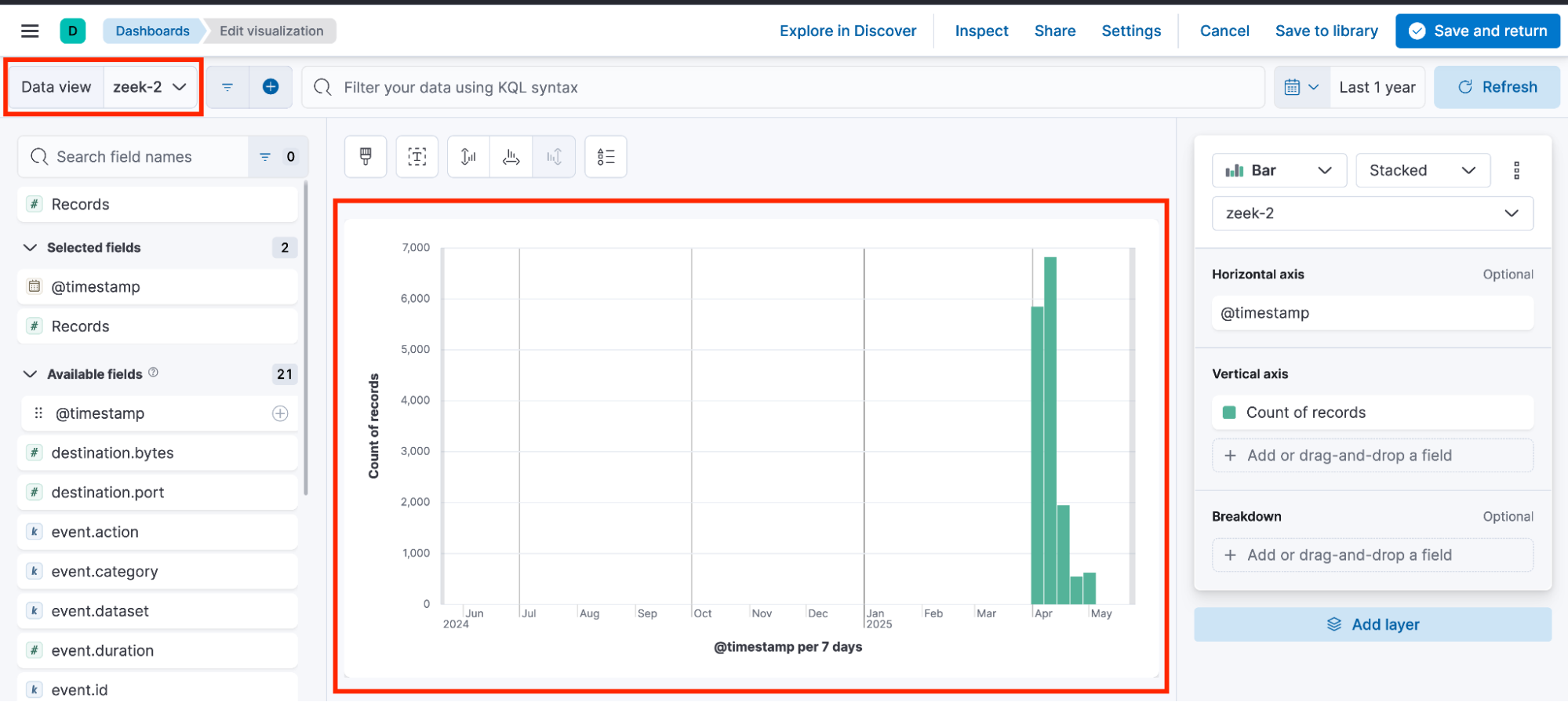
Visualization 2 built with zeek-2 data view
可视化 2 使用 zeek-2 数据视图创建
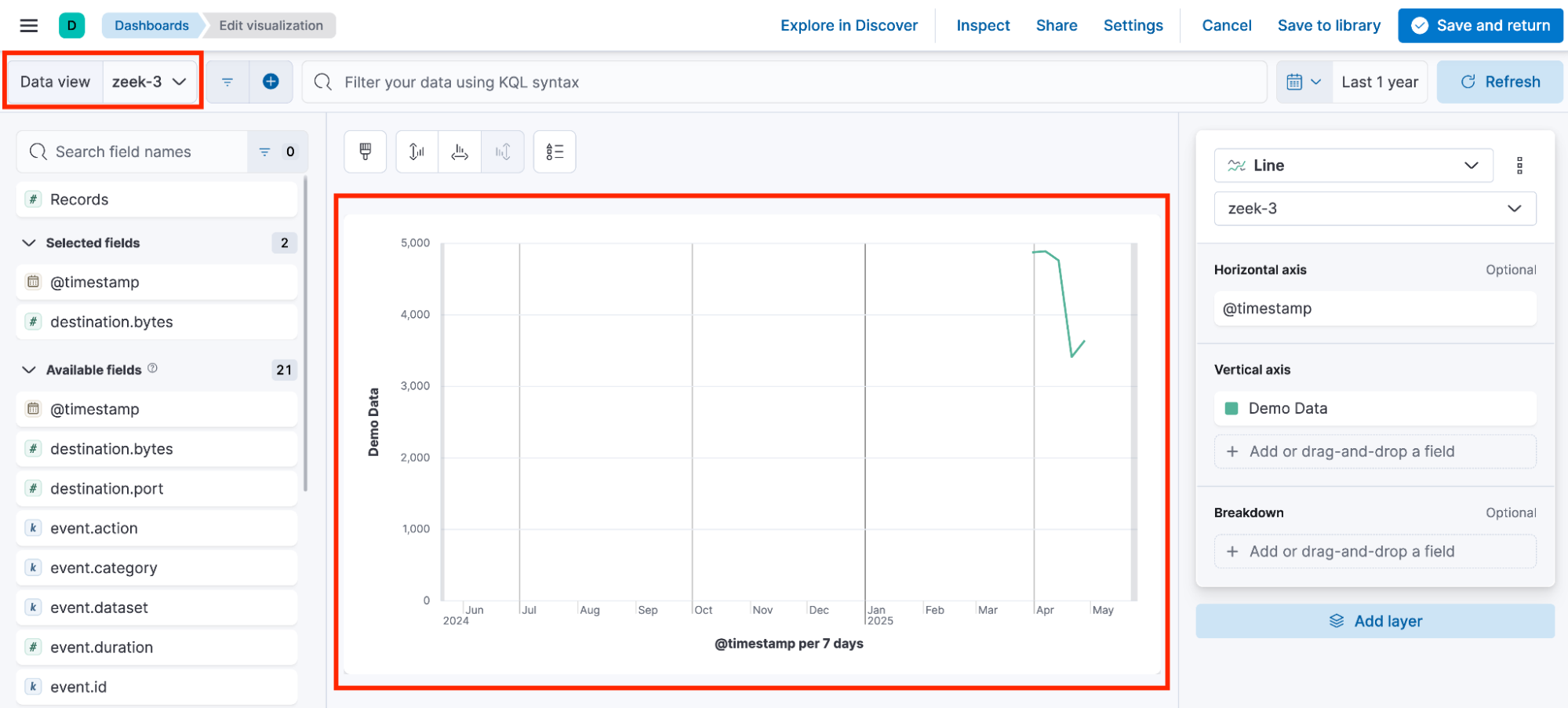
Visualization 3 built with zeek-3 data view.
可视化 3 使用 zeek-3 数据视图创建
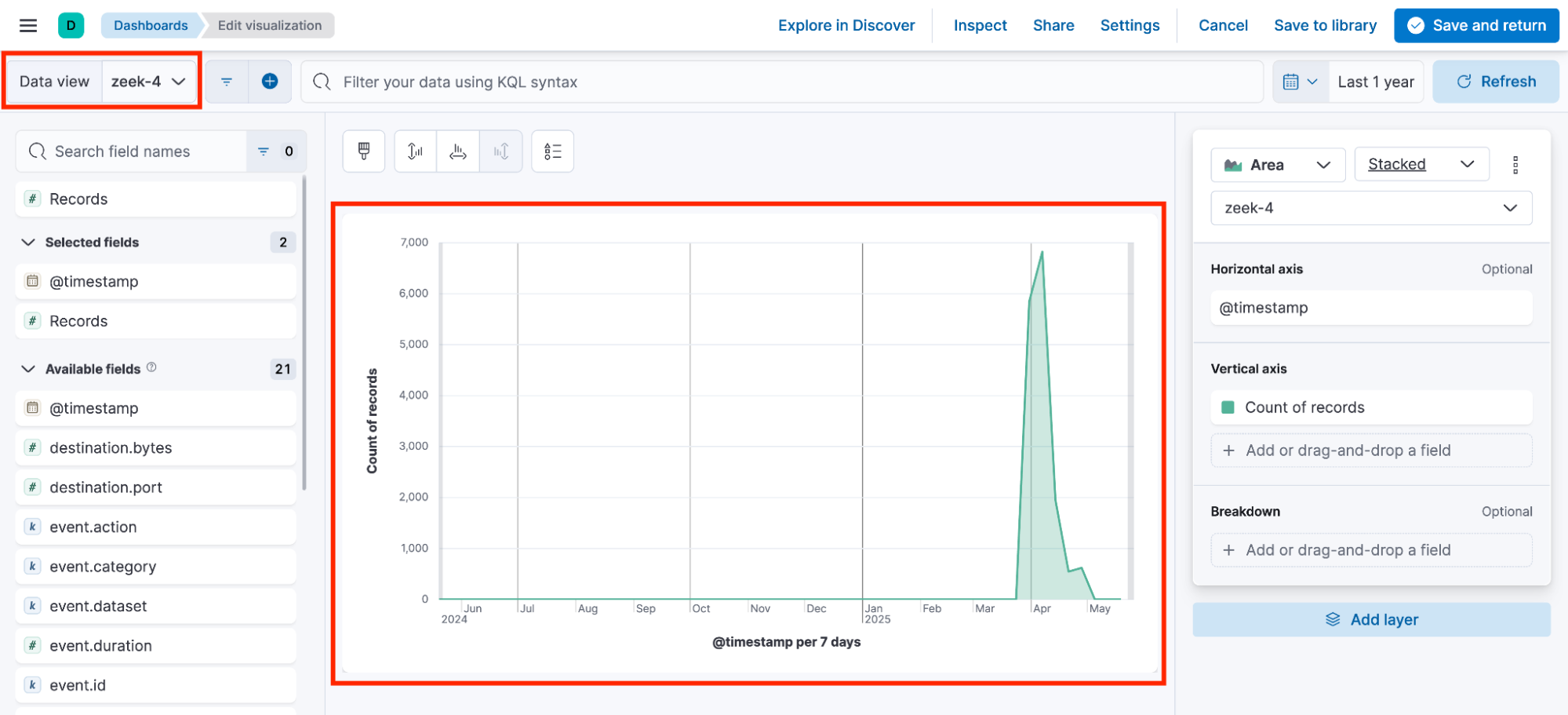
Visualization 4 built with zeek-4 data view.
可视化 4 使用 zeek-4 数据视图创建
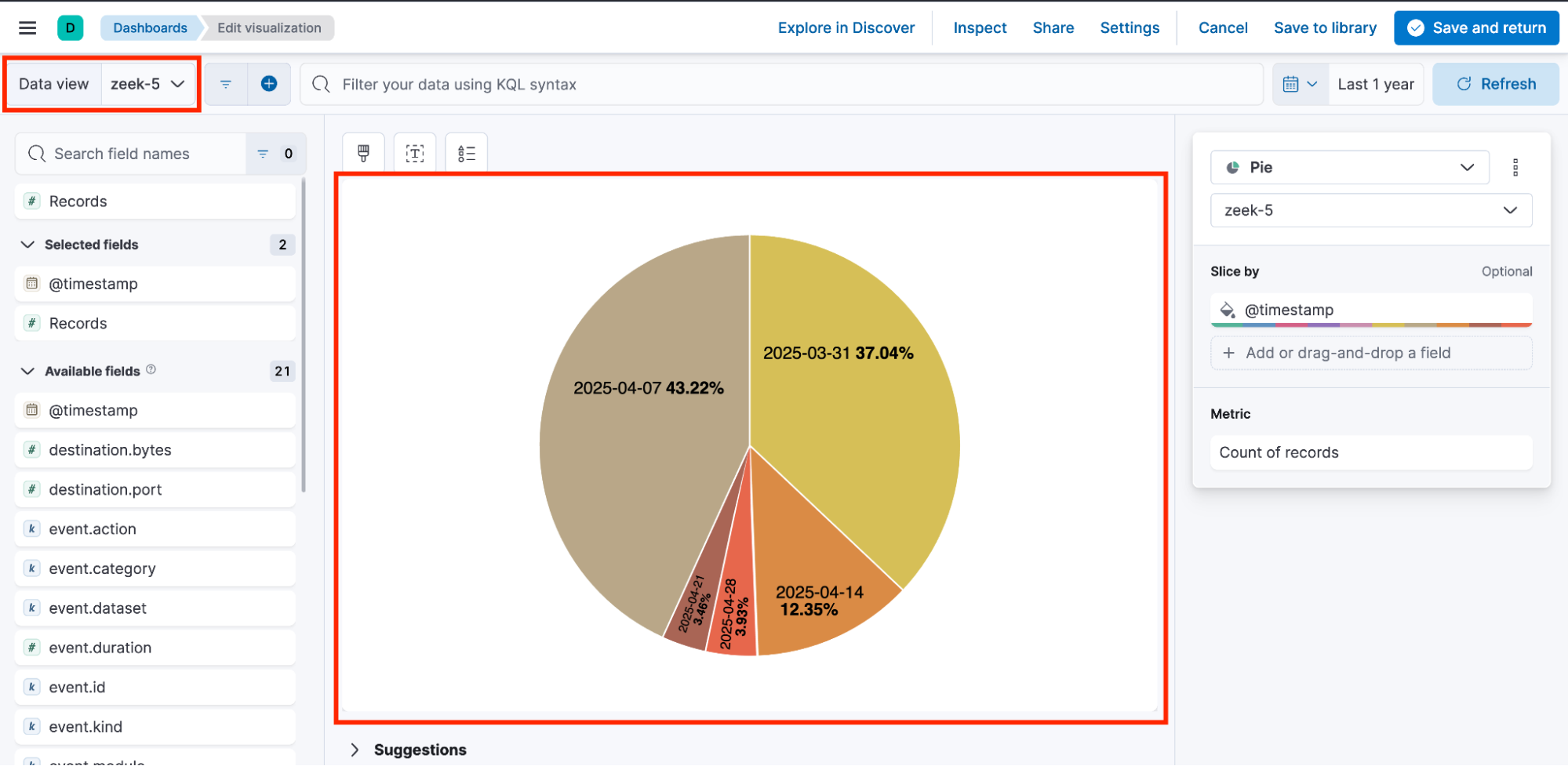
Visualization 5 built with zeek-5 data view.
可视化 5 使用 zeek-5 数据视图创建
结果,仪表板中包含了依赖于不同数据视图的可视化,每个可视化都有自己独立的随机生成 ID。
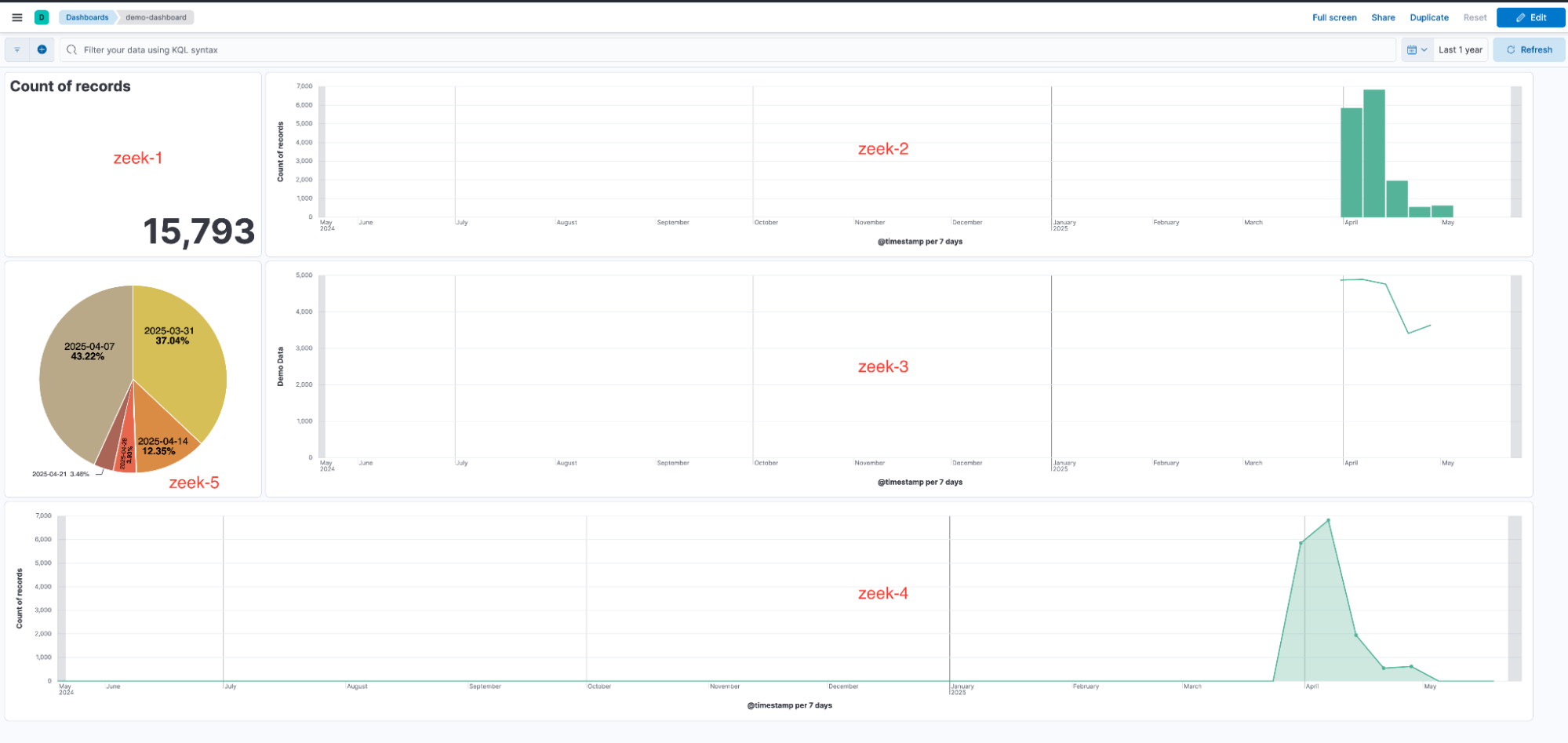
Shared dashboard containing five visualizations, each linked to a different data view, resulting in five unique data view IDs
共享仪表板包含五个可视化,每个可视化都链接到不同的数据视图,导致五个唯一的数据视图 ID
这些不一致会导致当其中一个相关数据视图被删除时,可视化崩溃,正如之前在 Young Sheldon 演示中所示。
协作环境中的常见问题
这是协作环境中的常见问题。要修复它们,你需要手动重新创建每个被删除的 9 个数据视图,并以某种方式恢复并重新分配原始 UUID,或者修改每个可视化以使用唯一剩下的数据视图——这是一项繁琐且容易出错的任务。
与此替代方案相比: 如果所有用户都使用共享的自定义数据视图 ID,比如 demo-young-sheldon,你只需要重新创建一个具有相同 ID 的数据视图,就可以恢复一切。无需猜测、无需分散的 ID,也无需不必要的清理。
简而言之: 自定义数据视图 ID 在协作环境中显著减少了复杂性和风险。
一些建议
如果你坚持看到这里,我相信你已经准备好开始使用这个被严重低估的自定义数据视图 ID 功能。你做出了明智的决定,我为你感到骄傲!
既然你已经加入了这个行列,我要给你一些关键的建议。
制定自定义数据视图 ID 策略有多种方法。我推荐的方法简单、可扩展且易于管理。
第一步:选择一个清晰、易记的名称,反映数据集的特点
让它一目了然。
示例: Demo Young Sheldon Data 变为 demo-young-sheldon
第二步:附加创建数据视图的空间名称
这有助于区分环境,避免命名冲突。
示例: demo-young-sheldon-demo
Spaces
第三步:记录并保持简单
在共享的知识库中记录命名约定和策略,便于访问和参考。一个一致的命名方法有助于保持环境的有序,并使得在协作团队中重新创建或识别数据视图更加容易。
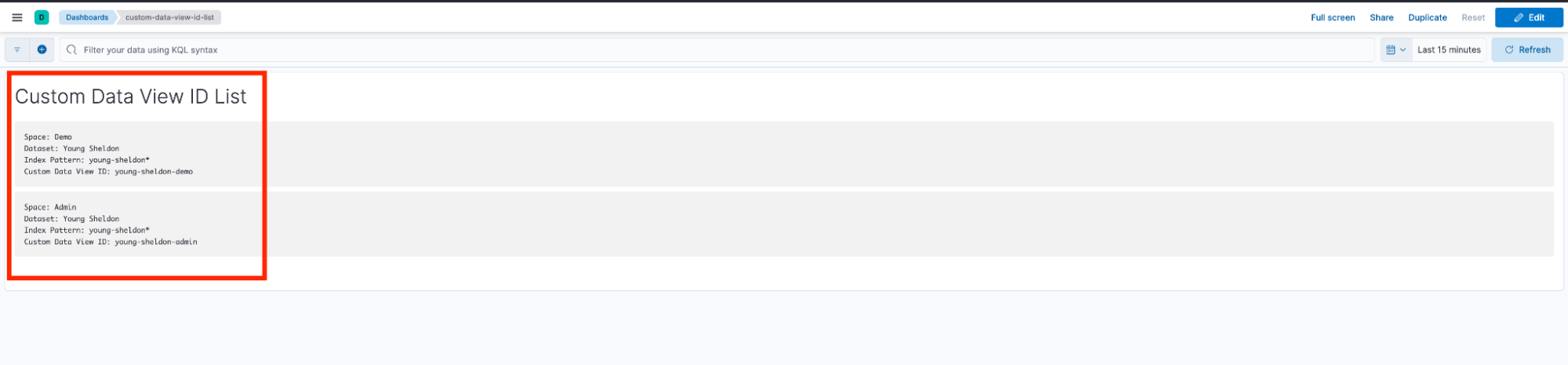
custom data view id list
注意: 如果你想稍微花哨一点,可以直接在 Kibana 中使用文本面板记录策略,如上图所示。或者,你也可以使用团队 wiki、GitHub 仓库,甚至一个简单的电子表格(根据工作流程选择最合适的)。
总结
本文内容较多,所以这里是整个博客文章的简要总结:
自定义数据视图 ID 功能在你的环境中值得成为主角。 就像 Young Sheldon 中的 Georgie,他在观众意识到他是故事核心部分之前已经出现了七季。而现在 Georgie and Mandy 已经成为了一个独立的故事。同样地,自定义数据视图 ID 一直都很重要,只是现在才得到了应有的重视。
当你与更大的团队合作时,自定义数据视图 ID 变得极其有价值。它们允许用户在关键数据视图被删除时快速恢复可视化。依赖随机自动生成的 ID 会使恢复成为一项令人沮丧且耗时的任务。自定义 ID 让一切变得更整洁、更快速,也更少混乱。
此外,我们进行了一个使用案例的演练,进行了一个动手的示例,我甚至分享了我的个人建议(即所谓的)最佳实践。虽然这可能看似一个小细节,但根据我的经验,忽视这个小细节会导致一些非常真实且非常大的问题。
你坚持到了最后。这太棒了。感谢你坚持与我一起。现在就登录 Kibana 试试自定义数据视图 ID 策略。我想你会喜欢的。
想要自动化创建自定义数据视图 ID 吗?查看这个 Terraform 资源。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号