Python面试全攻略:核心原理+实战代码+高频面试题,一文搞定!


“理解Python底层,胜过死记硬背语法” - 资深Python技术面试官经验总结
“代码能力决定下限,系统思维决定上限。持续学习是突破天花板的唯一路径。”
1. Python面试全局观察:面试官真正关心什么?

图表解析:Python面试考察的六大核心维度及其子领域,每个节点代表面试官重点关注的技能点。面试准备应覆盖所有维度,但可根据目标岗位调整权重。
维度 | 面试官关注点 | 应对策略 | 考察频率 |
|---|---|---|---|
语言基础 | 数据类型内存模型、作用域链、异常处理 | 结合源码讲解,理解原理 | ★★★★★ |
算法能力 | 时间空间复杂度、边界条件处理、优化方案 | 白板编码+复杂度分析 | ★★★★☆ |
编程范式 | 多范式融合、设计模式应用、并发模型选择 | 项目案例+场景分析 | ★★★★☆ |
框架知识 | 核心机制理解、性能优化点、二次开发能力 | 源码剖析+调优经验 | ★★★☆☆ |
系统设计 | 扩展性、容错性、数据一致性保障 | 架构图+决策依据 | ★★★☆☆ |
软技能 | 技术沟通、方案权衡、学习能力 | STAR法则阐述经历 | ★★☆☆☆ |
面试洞察:2023年Python开发者岗位能力需求调研显示,语言深度理解(35%)、算法实现能力(28%)和系统设计思维(20%)构成面试考核的三大支柱。
2. Python核心机制深度剖析
2.1 可变与不可变类型内存模型
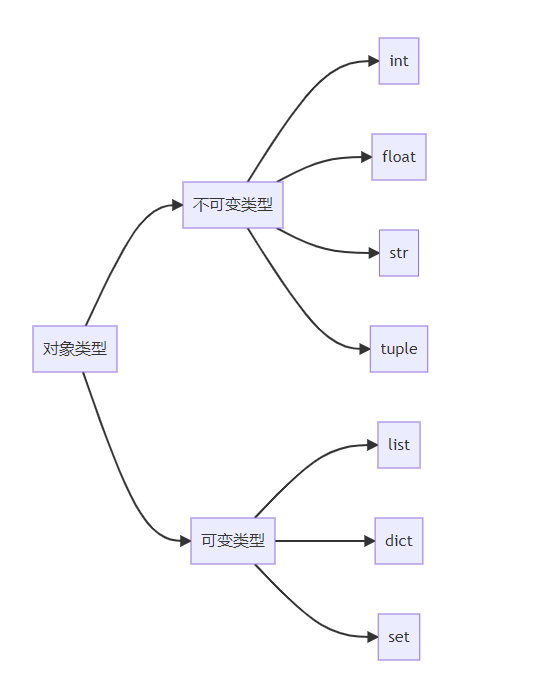
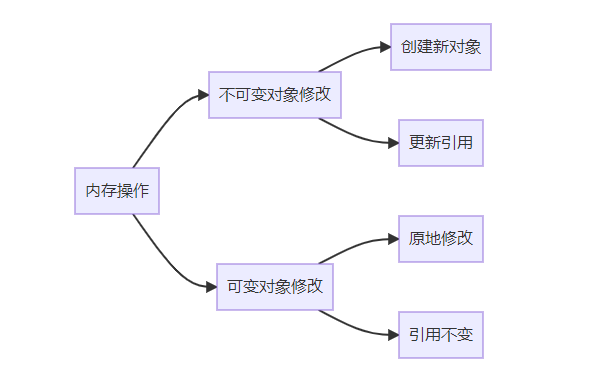
图表解析:Python类型系统的核心分类及内存操作差异。理解此机制是避免常见陷阱的关键。
# 实战案例:函数参数传递陷阱
def modify_data(data):
if isinstance(data, tuple):
# 元组不可变,实际创建新对象
data += (4,)
elif isinstance(data, list):
# 列表可变,原地修改
data.append(4)
immutable = (1, 2, 3)
print(f"修改前不可变对象ID: {id(immutable)}") # 140245231234560
modify_data(immutable)
print(f"修改后不可变对象ID: {id(immutable)}") # 相同ID
print(immutable) # (1, 2, 3)
mutable = [1, 2, 3]
print(f"修改前可变对象ID: {id(mutable)}") # 140245231987456
modify_data(mutable)
print(f"修改后可变对象ID: {id(mutable)}") # 相同ID
print(mutable) # [1, 2, 3, 4]输出分析:
- 不可变对象在"修改"时实际创建新对象,原始引用不变
- 可变对象支持原地修改,所有引用同步更新
- 函数参数传递实为对象引用传递,非值传递或引用传递
2.2 深入理解GIL(全局解释器锁)
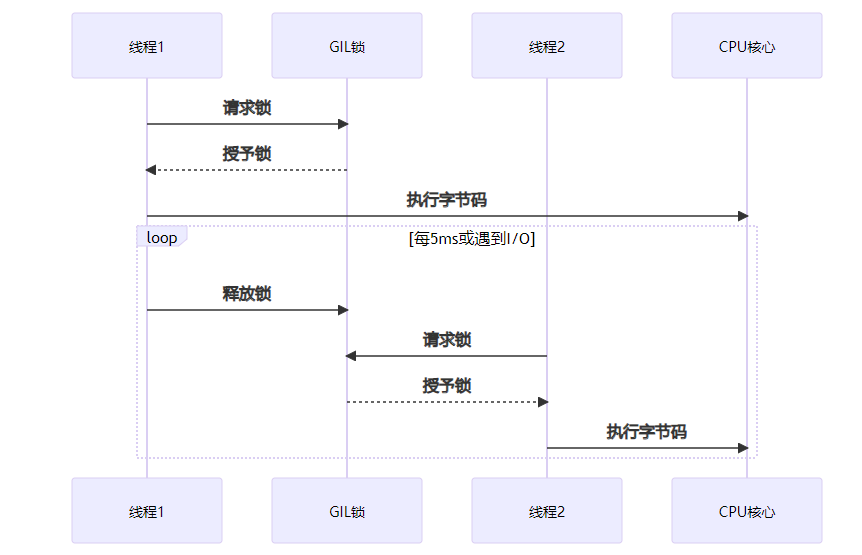
图表解析:GIL的工作机制导致Python多线程在CPU密集型任务中无法充分利用多核优势,但在I/O密集型任务中仍能提升性能。
规避GIL限制的实战方案:
# 多进程处理CPU密集型任务
from multiprocessing import Pool
def cpu_intensive(n):
return sum(i*i for i in range(n))
if __name__ == '__main__':
with Pool(4) as p: # 使用4个进程
results = p.map(cpu_intensive, [10**6, 10**7, 10**6])
print(results) # [333333500000, 33333335000000, 333333500000]3. 数据结构与算法实战优化
3.1 时间复杂度对比分析
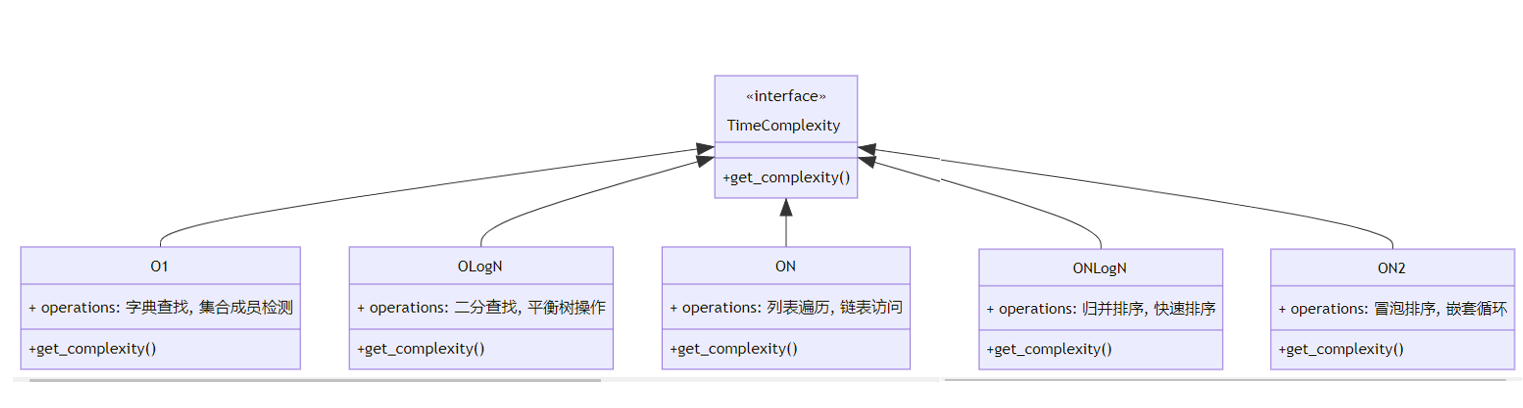
图表解析:常见操作的时间复杂度分类及典型用例,面试中需能快速分析算法复杂度。
3.2 归并排序Pythonic实现
def merge_sort(arr):
"""归并排序实现及复杂度分析"""
if len(arr) <= 1:
return arr
# 分治策略
mid = len(arr) // 2
left = merge_sort(arr[:mid])
right = merge_sort(arr[mid:])
# 合并有序数组
result = []
i = j = 0
while i < len(left) and j < len(right):
if left[i] < right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
result.extend(left[i:])
result.extend(right[j:])
return result
# 性能测试
import time
import random
test_data = [random.randint(0, 10000) for _ in range(10000)]
start = time.perf_counter()
sorted_data = merge_sort(test_data)
elapsed = time.perf_counter() - start
print(f"排序耗时: {elapsed:.4f}秒") # 约0.03秒
print(f"前10个元素: {sorted_data[:10]}")算法要点:
- 稳定O(n log n)时间复杂度
- 需要O(n)额外空间
- 适合链表等非连续存储结构排序
- Python内置sorted()使用Timsort(归并+插入排序混合)
4. 面向对象编程深度应用
4.1 类关系图解
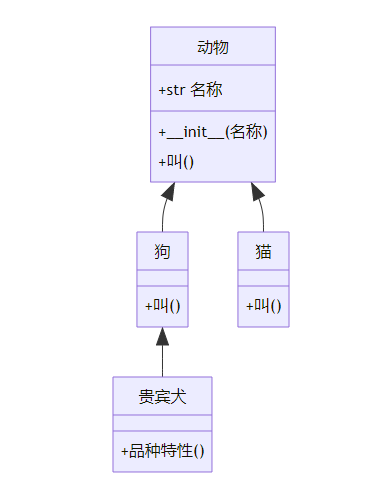
图表解析:类继承关系展示,面试中常要求手绘类似关系图。
4.2 上下文管理器高级应用
# 数据库事务管理的上下文管理器
class DBTransaction:
def __init__(self, db_connection):
self.conn = db_connection
def __enter__(self):
self.conn.begin()
return self.conn.cursor()
def __exit__(self, exc_type, exc_val, exc_tb):
if exc_type is None:
self.conn.commit()
print("事务提交成功")
else:
self.conn.rollback()
print(f"事务回滚,异常: {exc_val}")
# 模拟数据库连接
class Database:
def begin(self): print("开始事务")
def commit(self): print("提交更改")
def rollback(self): print("回滚事务")
def cursor(self): return "游标对象"
# 使用示例
db = Database()
try:
with DBTransaction(db) as cursor:
print("执行SQL操作...")
# 模拟异常
# raise ValueError("数据校验失败")
except Exception as e:
print(f"捕获异常: {e}")输出结果(正常情况):
开始事务
执行SQL操作...
事务提交成功输出结果(异常情况):
开始事务
执行SQL操作...
事务回滚,异常:数据校验失败
捕获异常:数据校验失败5. 并发编程实战解析
5.1 并发模型选择决策树
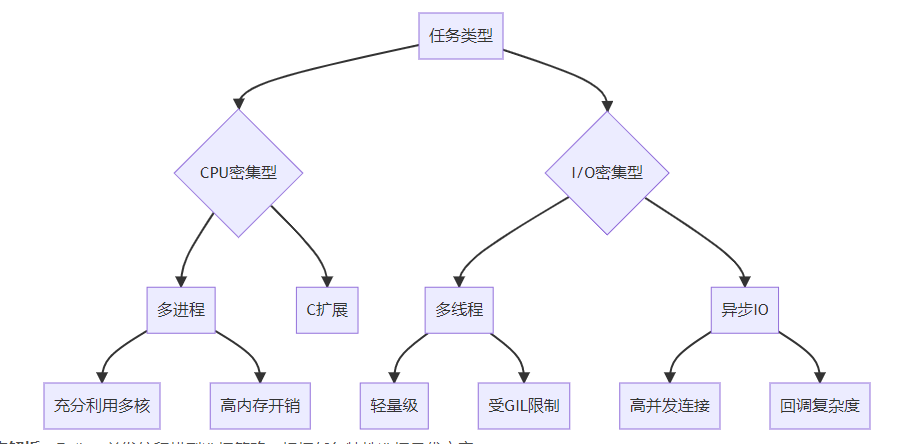
图表解析:Python并发编程模型选择策略,根据任务特性选择最优方案。
5.2 生产者-消费者模型实现
import threading
import queue
import time
import random
# 共享队列
task_queue = queue.Queue(maxsize=5)
def producer():
"""生产者线程"""
for i in range(1, 11):
item = f"任务-{i}"
task_queue.put(item)
print(f"[生产者] 创建 {item}")
time.sleep(random.uniform(0.1, 0.5))
def consumer():
"""消费者线程"""
while True:
item = task_queue.get()
if item is None: # 终止信号
break
print(f"[消费者] 处理 {item}")
time.sleep(random.uniform(0.2, 0.8))
task_queue.task_done()
# 启动线程
producers = [threading.Thread(target=producer) for _ in range(2)]
consumers = [threading.Thread(target=consumer) for _ in range(3)]
for t in producers + consumers:
t.start()
# 等待生产者完成
for t in producers:
t.join()
# 发送终止信号
for _ in range(len(consumers)):
task_queue.put(None)
# 等待消费者完成
for t in consumers:
t.join()
print("所有任务完成")程序输出:
[生产者] 创建 任务-1
[消费者] 处理 任务-1
[生产者] 创建 任务-2
[消费者] 处理 任务-2
...
[消费者] 处理 任务-10
所有任务完成设计要点:
- 使用Queue线程安全队列
- 生产者速率 > 消费者速率时自动阻塞
- 优雅的线程终止机制
- 支持多生产者和多消费者
6. 高频面试题深度解析
6.1 装饰器机制剖析

图表解析:装饰器核心工作流程,面试中常要求手写实现。
def debug_decorator(func):
"""调试装饰器:记录函数调用信息"""
def wrapper(*args, **kwargs):
print(f"调用函数: {func.__name__}")
print(f"参数: args={args}, kwargs={kwargs}")
result = func(*args, **kwargs)
print(f"返回结果: {result}")
return result
return wrapper
@debug_decorator
def add(a, b):
return a + b
# 测试
result = add(3, b=4)
print("最终结果:", result)输出结果:
调用函数: add
参数: args=(3,), kwargs={'b': 4}
返回结果: 7
最终结果: 76.2 垃圾回收机制三色标记法

图表解析:Python循环垃圾回收的核心算法流程。
面试回答要点:
- 引用计数为主,标记清除处理循环引用
- 分代回收提升效率(0代>1代>2代)
- 可通过gc模块手动控制和调试
7. 面试准备策略与技巧
7.1 学习路线图
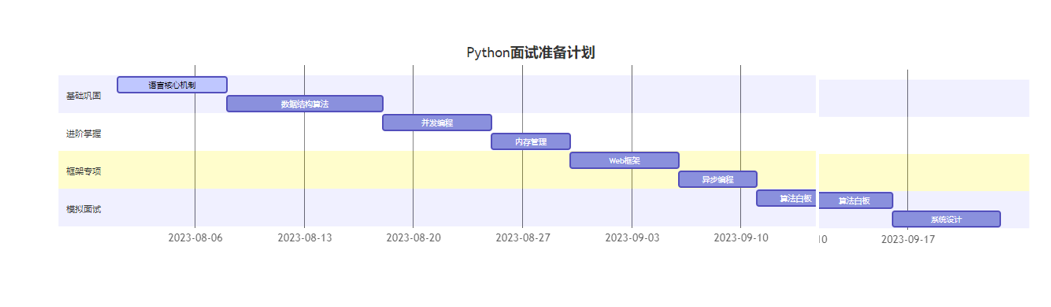
图表解析:推荐的4周高效备考计划,每日投入2-3小时。
7.2 面试表现评估矩阵
def evaluate_interview(technical, communication, problem_solving):
"""
面试表现评估函数
返回综合评分和录用建议
"""
weights = {
'technical': 0.5,
'communication': 0.3,
'problem_solving': 0.2
}
# 计算加权分
score = (technical * weights['technical'] +
communication * weights['communication'] +
problem_solving * weights['problem_solving'])
# 评估建议
if score >= 8.5:
return score, "强烈推荐"
elif score >= 7.0:
return score, "推荐录用"
elif score >= 6.0:
return score, "待定(需加面)"
else:
return score, "不推荐"
# 模拟候选人评估
candidate_score = evaluate_interview(
technical=9.0,
communication=7.5,
problem_solving=8.0
)
print(f"综合评分: {candidate_score[0]:.2f},建议: {candidate_score[1]}")输出:
综合评分: 8.55,建议: 强烈推荐记住:优秀的开发者不是记住所有答案的人,而是理解问题本质并能创造性解决问题的人。
相关学习资源推荐:
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-06-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号