【Multi-agent实战】教你如何用Multi-agent分析开源Github项目
原创
【Multi-agent实战】教你如何用Multi-agent分析开源Github项目
原创
论文三秒被秒拒
修改于 2025-11-23 09:51:54
修改于 2025-11-23 09:51:54
前言
✍ 你现在的 Deepfake 检测项目,大概率长这样:
- 一坨
train.py:argparse一大堆;- 里面 new
Trainer,跑完顺带做验证;
- 一坨
eval_pretrained.py:- 单独读取权重、加载
DETECTOR,做多数据集评估;
- 单独读取权重、加载
- 再加一个
tsne_vis.py:- 从某个 log / pkl 里读特征,画 t-SNE;
- 最后你自己看 tensorboard / 日志,心里默念: “这实验到底是不是跑对了?”
这其实就是典型 Single Agent / 单体脚本模式:一个脚本包揽所有流程,逻辑重叠、复用困难、很难自动化。
这篇我们做三件事:
- 把你现有的 Deepfake 实验流程拆成「可以被 Agent 调度」的几个任务节点;
- 用 LangGraph 搭一个 Multi-Agent 工作流:Config → Train → Eval → t-SNE → Report;
- 给出可直接改造的代码骨架,你可以把自己现有的
Trainer/DETECTOR直接塞进去。
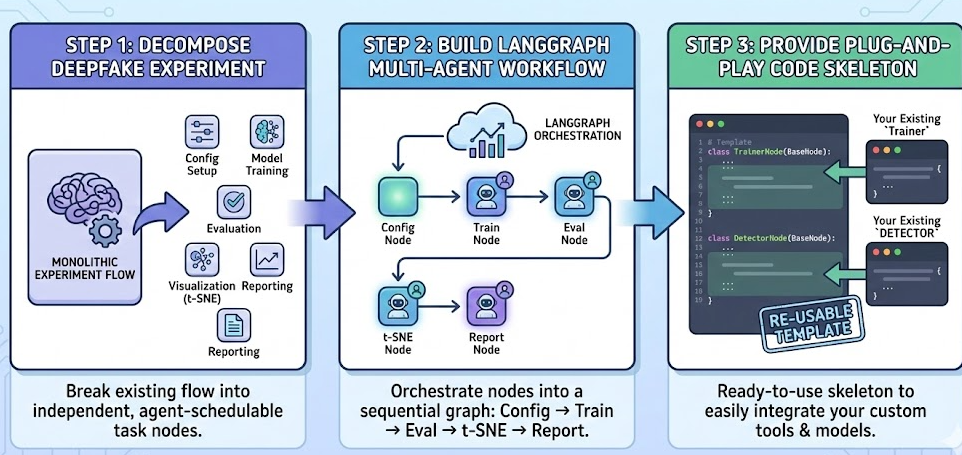
🧩 一、先认清现状:单体脚本 = 隐形 Single Agent
我们先抽象一下你现在的典型 train.py / eval_pretrained.py(我用简化版伪代码写一下结构):
# train.py(典型写法)
import argparse
from training.detectors import DETECTOR
from trainer.trainer import Trainer
from dataset.ffpp import FFPPDataset
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument('--config', type=str, default='configs/effb4_ffpp.yaml')
parser.add_argument('--seed', type=int, default=42)
parser.add_argument('--save_dir', type=str, default='exp/effb4_ffpp/')
# ... 乱七八糟一堆参数
return parser.parse_args()
def main():
args = parse_args()
# 1. 读 config + set seed
config = load_yaml(args.config)
set_seed(args.seed)
# 2. 构建 model / dataset / trainer
model = DETECTOR(config)
train_set = FFPPDataset(config, split='train')
val_set = FFPPDataset(config, split='val')
trainer = Trainer(model, train_set, val_set, config)
# 3. 训练 + 验证
trainer.train()
# 4. 保存 best model / log / tsne buffer 等等
# ...
if __name__ == "__main__":
main()
# eval_pretrained.py(典型写法)
from training.detectors import DETECTOR
from dataset.abstract_dataset import DeepfakeAbstractBaseDataset
from metrics.utils import get_test_metrics
def main():
# 1. 解析参数(模型路径、测试数据集名字等)
# 2. 构建 model 和指定 dataset(比如 CelebDF-v2 / DFDC / 自建)
# 3. load_state_dict
# 4. 跑一遍 forward,收集 preds / labels
# 5. 调用 get_test_metrics 计算 AUC/EER/AP
pass问题在哪?
- 所有流程(配置、训练、评估、可视化、结果总结)都耦合在脚本里;
- 想做一个「跨数据集 benchmark」需要自己写 for-loop + 手动改 config / 模型路径;
- 想让「别的 Agent / Web 前端 / CLI 工具」来调用它,非常不友好。
换句话说: 你的系统其实就是一个「人肉 Single Agent」:
接收自然语言需求(在你大脑里解析) 决定调哪个脚本 / 改哪些参数 手动执行 / 观察结果 / 再跑一次
我们现在要做的,就是把这个人肉 orchestrator,逐步演化成一个真正可编排的 Multi-Agent Deepfake 实验系统。
🧱 二、第一步:把流程拆成清晰的任务节点
先不急着上 LangGraph。先抽象出「这件事到底有哪些步骤」。
以典型「训练 + 多数据集评估 + 特征可视化」为例,我们可以拆成:
ConfigAgent:从「人的描述」→ 实验配置;TrainAgent:根据 config 调用你的Trainer.train();EvalAgent:在若干数据集上,统一调用评估脚本;VizAgent:t-SNE / ROC、PR 曲线画图;ReportAgent:汇总所有结果,输出 markdown 报告。
我们先把这些节点对应的纯 Python 函数定义出来,后面再让 LangGraph 接手。
🧪 三、封装核心能力:让你的 Trainer/DETECTOR 变成「工具」
3.1 把训练过程封装成一个工具函数
# exp_core/train_runner.py
import os
import yaml
import torch
from training.detectors import DETECTOR
from trainer.trainer import Trainer
from dataset.ffpp import FFPPDataset # 你可以按实际拆不同数据集
from utils.misc import set_seed # 自己实现一个就行
def run_training(config_path: str, override: dict | None = None) -> dict:
"""
单次训练任务入口函数。
输入:
- config_path: YAML 配置路径
- override: 可选的参数覆盖(例如 {'train.lr': 1e-4})
输出:
- 一个 dict,包括:
- exp_dir: 实验目录
- best_ckpt: 最佳模型路径
- best_val_auc: 最佳验证集 AUC
- log_path: 训练日志文件
"""
# 1. 读取 config
with open(config_path, "r") as f:
config = yaml.safe_load(f)
# 2. 应用 override(简单示例)
override = override or {}
for k, v in override.items():
# 支持类似 train.lr 的层级覆盖
keys = k.split(".")
d = config
for kk in keys[:-1]:
d = d.setdefault(kk, {})
d[keys[-1]] = v
# 3. set seed
seed = config.get("seed", 42)
set_seed(seed)
# 4. 实验目录
exp_dir = config.get("exp_dir", "exp/default_run")
os.makedirs(exp_dir, exist_ok=True)
# 5. 构建模型 & 数据集 & trainer
model = DETECTOR(config)
train_set = FFPPDataset(config, split="train")
val_set = FFPPDataset(config, split="val")
trainer = Trainer(
model=model,
train_dataset=train_set,
val_dataset=val_set,
config=config,
exp_dir=exp_dir,
)
# 6. 开始训练
best_val_auc = trainer.train() # 假设返回 best val AUC
# 7. 构建返回信息
best_ckpt = os.path.join(exp_dir, "checkpoints", "best.pt")
log_path = os.path.join(exp_dir, "train.log")
return {
"exp_dir": exp_dir,
"best_ckpt": best_ckpt,
"best_val_auc": best_val_auc,
"log_path": log_path,
}3.2 把多数据集评估封装成工具
# exp_core/eval_runner.py
import yaml
from training.detectors import DETECTOR
from metrics.utils import get_test_metrics
from dataset.ffpp import FFPPDataset
from dataset.celebdf_v2 import CelebDFV2Dataset
from dataset.dfdc import DFDCValDataset
import torch
DATASET_MAP = {
"ffpp": FFPPDataset,
"celebdfv2": CelebDFV2Dataset,
"dfdc": DFDCValDataset,
# 你按实际情况加
}
def run_eval(ckpt_path: str, base_config_path: str, eval_datasets: list[str]) -> dict:
"""
对指定 checkpoint 在多个数据集上做评估。
返回:
{
'ffpp': {'auc': 0.9, 'eer': 0.1, ...},
'celebdfv2': {...},
...
}
"""
with open(base_config_path, "r") as f:
config = yaml.safe_load(f)
# 构建模型
model = DETECTOR(config)
state = torch.load(ckpt_path, map_location="cpu")
model.load_state_dict(state["model"] if "model" in state else state)
model.eval().cuda()
results = {}
for name in eval_datasets:
DatasetCls = DATASET_MAP[name]
dataset = DatasetCls(config, split="test")
# 这里你可以封装一个统一的 test_loop
all_logits, all_labels = [], []
for batch in dataset.get_loader(batch_size=config.get("test_bs", 32)):
imgs, labels = batch["img"].cuda(), batch["label"].cuda()
with torch.no_grad():
logits = model(imgs)
all_logits.append(logits.detach().cpu())
all_labels.append(labels.detach().cpu())
import torch as th
logits = th.cat(all_logits, dim=0)
labels = th.cat(all_labels, dim=0)
metrics = get_test_metrics(logits, labels)
results[name] = metrics
return results3.3 t-SNE 可视化封装成工具
你原来训练时就有 TSNEBuffer,或者把中间特征存 .pkl,直接基于这个实现可视化。
# exp_core/tsne_runner.py
import os
import pickle
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
def run_tsne(feat_pkl_path: str, save_path: str):
"""
读取特征 pkl,执行 t-SNE,并保存到图片。
pkl 假设格式:
{
'feat': np.ndarray [N, D],
'label': np.ndarray [N],
'domain': np.ndarray [N] (可选)
}
"""
os.makedirs(os.path.dirname(save_path), exist_ok=True)
with open(feat_pkl_path, "rb") as f:
data = pickle.load(f)
feat = data["feat"]
label = data["label"]
tsne = TSNE(n_components=2, perplexity=30, learning_rate=200, random_state=42)
feat_2d = tsne.fit_transform(feat)
plt.figure(figsize=(6, 6))
# 简单画:正样本一种标记,负样本另一种
pos = label == 1
neg = label == 0
plt.scatter(feat_2d[pos, 0], feat_2d[pos, 1], s=5, alpha=0.6, label="fake")
plt.scatter(feat_2d[neg, 0], feat_2d[neg, 1], s=5, alpha=0.6, label="real")
plt.legend()
plt.tight_layout()
plt.savefig(save_path, dpi=300)
plt.close()
return {"tsne_path": save_path}到这一步,你已经把「训练 / 评估 / 可视化」拆成了 3 个可以被 Agent 调用的 Python 工具函数。下一步就是把它们塞进 Multi-Agent 工作流里。
🤖 四、用 LangGraph 搭一个 Multi-Agent Deepfake 实验流
目标:给一个「自然语言实验需求」,例如:
“帮我用 EfficientNet-B4 在 FF++ 上训练一个 baseline,然后在 CelebDF-v2 / DFDC 上做跨数据集评估,并输出一份实验报告(包含表格 + t-SNE 图路径)”
我们希望系统自动完成:
- 分析需求 → 生成 config_path / override / eval_datasets;
- 调
run_training; - 调
run_eval; - 挑一个特征文件做
run_tsne; - 汇总结果 → 输出 markdown 报告。
4.1 定义实验 State
# exp_graph/state_defs.py
from typing import TypedDict, Dict, Any, List
class ExpState(TypedDict):
# 输入
user_request: str # 用户自然语言描述
base_config: str # 基础配置 YAML 路径
override: Dict[str, Any] # 配置覆盖,例如 {"train.lr": 1e-4}
eval_datasets: List[str] # 需要评估的数据集列表
# 中间 & 输出
train_result: Dict[str, Any] # run_training 返回
eval_result: Dict[str, Any] # run_eval 返回
tsne_result: Dict[str, Any] # run_tsne 返回
report_markdown: str # 最终报告4.2 ConfigAgent:从自然语言解析出实验配置
# exp_graph/nodes.py
from langchain_openai import ChatOpenAI
import json
def config_agent_node(state: ExpState) -> ExpState:
"""ConfigAgent:把人话 → 实验配置。"""
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0.0)
prompt = f"""
你是一个 Deepfake 实验配置助手。
用户需求如下(中文):
{state['user_request']}
我们目前有如下可用配置模板(示例):
- configs/effb4_ffpp.yaml : EfficientNet-B4, 训练集 FF++, baseline
- configs/clipvit_ffpp.yaml : CLIP-ViT backbone, 训练集 FF++
可用的评估数据集别名:
- "ffpp"
- "celebdfv2"
- "dfdc"
请你根据用户的需求,生成一个 JSON,对应字段:
- base_config: 选择一个合适的基础配置路径
- override: 一个 dict,用于对 config 中的参数进行覆盖(比如学习率 / 训练轮数)。如果不需要覆盖,就用空 dict。
- eval_datasets: 需要评估的数据集列表,例如 ["celebdfv2", "dfdc"]
只输出 JSON,不要写解释。
"""
resp = llm.invoke(prompt)
try:
cfg = json.loads(resp.content)
except Exception:
cfg = {
"base_config": "configs/effb4_ffpp.yaml",
"override": {},
"eval_datasets": ["celebdfv2", "dfdc"],
}
new_state = dict(state)
new_state["base_config"] = cfg["base_config"]
new_state["override"] = cfg.get("override", {})
new_state["eval_datasets"] = cfg.get("eval_datasets", ["celebdfv2", "dfdc"])
return new_state4.3 TrainAgent:调用你封装好的 run_training
from exp_core.train_runner import run_training
def train_agent_node(state: ExpState) -> ExpState:
"""TrainAgent:根据 base_config + override 跑一次训练。"""
result = run_training(
config_path=state["base_config"],
override=state["override"],
)
new_state = dict(state)
new_state["train_result"] = result
return new_state4.4 EvalAgent:多数据集评估
from exp_core.eval_runner import run_eval
def eval_agent_node(state: ExpState) -> ExpState:
"""EvalAgent:在多个数据集上跑评估。"""
ckpt = state["train_result"]["best_ckpt"]
base_cfg = state["base_config"]
eval_datasets = state["eval_datasets"]
result = run_eval(
ckpt_path=ckpt,
base_config_path=base_cfg,
eval_datasets=eval_datasets,
)
new_state = dict(state)
new_state["eval_result"] = result
return new_state4.5 VizAgent:t-SNE 可视化
假设你在训练时已经在 exp_dir/feat/val_feat.pkl 里存了一份 feature buffer。
from exp_core.tsne_runner import run_tsne
import os
def viz_agent_node(state: ExpState) -> ExpState:
"""VizAgent:对验证集(或者某个数据集)的特征做 t-SNE 可视化。"""
exp_dir = state["train_result"]["exp_dir"]
feat_pkl = os.path.join(exp_dir, "feat", "val_feat.pkl")
tsne_path = os.path.join(exp_dir, "vis", "tsne_val.png")
result = run_tsne(feat_pkl_path=feat_pkl, save_path=tsne_path)
new_state = dict(state)
new_state["tsne_result"] = result
return new_state4.6 ReportAgent:生成一份完整实验报告(Markdown)
from langchain_openai import ChatOpenAI
def report_agent_node(state: ExpState) -> ExpState:
"""ReportAgent:汇总训练/评估/可视化结果,输出 markdown 报告。"""
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0.2)
user_req = state["user_request"]
train_res = state["train_result"]
eval_res = state["eval_result"]
tsne_res = state["tsne_result"]
prompt = f"""
你是一个 Deepfake 实验报告撰写助手。
用户最初的实验需求:
{user_req}
训练结果(JSON):
{json.dumps(train_res, ensure_ascii=False, indent=2)}
多数据集评估结果(JSON):
{json.dumps(eval_res, ensure_ascii=False, indent=2)}
特征可视化结果:
{json.dumps(tsne_res, ensure_ascii=False, indent=2)}
请生成一份结构化的中文实验报告,用 Markdown 格式,包含:
1. 实验配置概览(模型、训练数据集、关键超参)
2. 训练与验证表现(包含 best_val_auc)
3. 跨数据集评估结果(用表格展示各数据集 AUC/EER/AP)
4. 特征可视化分析(引用 tsne 图像路径)
5. 简要讨论:
- 模型在 within-domain vs cross-domain 的表现差异
- 可能的性能瓶颈与改进方向
注意:报告中要清楚给出 tsne 图像的相对路径,方便后续插入论文/博客。
"""
resp = llm.invoke(prompt)
md = resp.content
new_state = dict(state)
new_state["report_markdown"] = md
return new_state4.7 串成 LangGraph:真正的 Multi-Agent 实验工作流
# exp_graph/build_graph.py
from langgraph.graph import StateGraph, START, END
from exp_graph.state_defs import ExpState
from exp_graph.nodes import (
config_agent_node,
train_agent_node,
eval_agent_node,
viz_agent_node,
report_agent_node,
)
def build_exp_graph():
g = StateGraph(ExpState)
g.add_node("config_agent", config_agent_node)
g.add_node("train_agent", train_agent_node)
g.add_node("eval_agent", eval_agent_node)
g.add_node("viz_agent", viz_agent_node)
g.add_node("report_agent", report_agent_node)
g.add_edge(START, "config_agent")
g.add_edge("config_agent", "train_agent")
g.add_edge("train_agent", "eval_agent")
g.add_edge("eval_agent", "viz_agent")
g.add_edge("viz_agent", "report_agent")
g.add_edge("report_agent", END)
return g.compile()4.8 一行调用:从「人话」到完整实验报告
# run_experiment.py
from exp_graph.build_graph import build_exp_graph
from exp_graph.state_defs import ExpState
if __name__ == "__main__":
graph = build_exp_graph()
user_req = """
用 EfficientNet-B4 在 FF++ 上训练一个 baseline,
在 CelebDF-v2 和 DFDC 上做跨数据集评估,
并输出一份包含 AUC/EER/AP + t-SNE 可视化分析的实验报告。
学习率可以稍微保守一点,训练轮数不要太多。
"""
init_state: ExpState = {
"user_request": user_req,
"base_config": "",
"override": {},
"eval_datasets": [],
"train_result": {},
"eval_result": {},
"tsne_result": {},
"report_markdown": "",
}
final_state = graph.invoke(init_state)
print("=== 实验完成!===")
print("Best checkpoint:", final_state["train_result"]["best_ckpt"])
print("Eval result:", final_state["eval_result"])
print("\n=== 实验报告(Markdown)===\n")
print(final_state["report_markdown"])
# 你也可以直接写入文件
with open("exp_report.md", "w", encoding="utf-8") as f:
f.write(final_state["report_markdown"])🧠 五、Single vs Multi:这套改造在面试里怎么讲?
如果你把这套东西写进简历 / 博客,面试官很可能会问:
你为什么要用 Multi-Agent / LangGraph,而不是一个脚本搞定? Multi-Agent 带来的真实价值是什么?会不会只是“炫技”?
你可以这样回答:
5.1 为什么从 Single 演化到 Multi?
- 一开始确实是 Single Script:
train.py/eval_pretrained.py全都一个脚本搞定,能跑就行。 - 随着需求增加:
- 需要「批量跑不同配置」;
- 需要固定评估流程:训练完自动跑多数据集 + 可视化 + 报告;
- 需要给未来的 Web UI / CLI / Agent 留一个干净接口;
- Single Script 会变得非常难维护和复用,于是自然演化成: 「把训练/评估/可视化 抽成工具函数 → 用 Multi-Agent 工作流来 orchestrate」。
5.2 Multi-Agent 真正带来的东西?
- 流程显式化:
- Config / Train / Eval / Viz / Report 都是独立节点;
- 修改任意一环不影响其他节点。
- 可观测性好:
- 某次实验挂了,很容易知道是在哪个节点(训练崩了?评估脚本错了?tsne 特征缺失?)。
- 可扩展性:
- 后续你可以加:
HyperParamSearchAgent:自动做超参搜索;AblationPlannerAgent:自动生成 ablation 组合;PaperWriterAgent:根据多个实验报告生成论文里的实验章节初稿。
- 后续你可以加:
- 统一入口:
- 上层只需要给一段自然语言: “帮我跑一个跨数据集 baseline”
- Multi-Agent 工作流负责把这段话变成真正的可执行实验计划。
六、小结
这一篇我们做了几件事:
- 用你的 Deepfake 项目当例子,把原始单体脚本分析成一种「隐形 Single Agent」;
- 把训练 / 多数据集评估 / t-SNE 可视化,封装成可复用工具函数;
- 用 LangGraph 建了一条完整的 Multi-Agent 实验流水线:
ConfigAgent → TrainAgent → EvalAgent → VizAgent → ReportAgent;
- 给出了完整的 Python 骨架,基本就是:
- 把你现有的
Trainer/DETECTOR/ dataset 类塞进去就能用;
- 把你现有的
- 额外送了你一套面试话术,可以在“Agentic RL / 实验平台建设”类岗位直接用。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号