PCIe 6.0:AI时代的算力互连枢纽与架构翻转

PCIe 6.0:AI时代的算力互连枢纽与架构翻转

数据存储前沿技术
发布于 2025-12-21 14:19:43
发布于 2025-12-21 14:19:43
阅读收获
- 掌握AI服务器Scale-Up架构的底层逻辑:理解PCIe Switch如何从存储I/O中心转变为GPU算力互连枢纽,实现CPU卸载和数据直通。
- 洞察PCIe 6.0/PAM-4等关键技术在解决信号完整性、实现160 Lane超大规模互连中的核心作用。
- 明确LLM训练与推理场景下CPU:GPU的资源配比差异(如训练最高可达1:64),为云数据中心或边缘计算的服务器选型提供精准指导。
全文概览
在AI大模型训练和推理的浪潮下,服务器架构正经历一场深刻的“翻转”。你是否还在将PCIe交换机视为简单的“存储扩展器”?如果是,那么你可能错过了AI时代最关键的互连革命。
随着GPU集群的规模化和异构计算的普及,传统的I/O瓶颈已转移到算力互连上。PCIe Switch不再是配角,而是承载GPU-GPU高速通信、实现CPU卸载、构建Scale-Up节点的“大动脉”。PCIe 6.0、160 Lane、PAM-4等技术正将Switch推向一个全新的高度。面对动辄数十张卡的AI集群,如何利用先进的PCIe Fabric实现无阻塞带宽、构建高可用性(NTB)的异构生态?CPU与GPU的配比策略又该如何根据训练和推理场景精准适配? 本文将深入解析PCIe Switch在AI服务器架构中的角色转变、核心技术特性,以及它如何成为打破专有互连垄断、实现开放算力生态的物理基石。
👉 划线高亮 观点批注
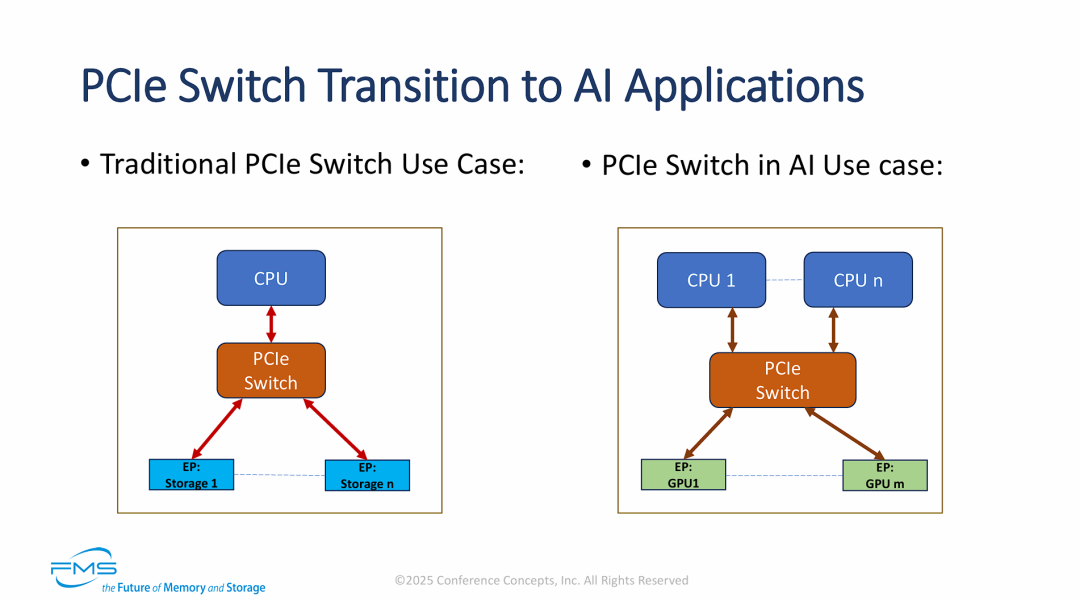
PCIe交换机向AI应用的转型
PCIe交换机向AI应用的转型
PCIe交换机的应用重心正在从传统的“存储扩展”向AI时代的“算力互连”转移。
- 连接对象的质变(从Storage到GPU):
- 传统场景下,PCIe Switch主要用于连接CPU和大量NVMe SSD,解决的是存储I/O扩展和聚合的问题。
- AI场景下,PCIe Switch成为连接CPU集群与GPU集群的关键通道,解决的是高带宽、低延迟的异构计算互连问题。
- 架构复杂度的提升(单机 vs 多机):
- 从左侧的“单CPU控制多存储”演变为右侧的“多CPU协同多GPU”。这意味着PCIe交换机在AI场景下需要具备更强的多主机(Multi-Host)支持能力,以及在复杂拓扑下的数据交换能力。
- 流量模式的改变:
- AI应用不仅需要CPU到GPU的通信,更强调GPU到GPU(P2P)的高速通信(如模型训练中的All-Reduce操作)。PCIe Switch在这里不仅是通道,更是AI集群内部数据高速流转的“大动脉”。
在AI大爆发的背景下,PCIe交换机不再仅仅是存储系统的组件,它已成为AI服务器内部架构(Scale-up)的核心组件。未来的PCIe Switch(如PCIe 5.0/6.0/7.0)设计将更侧重于低延迟、高吞吐量以及对CXL等缓存一致性协议的支持,以服务于GPU互连。

PCIe 交换机特性集概览
PCIe 交换机特性集概览
现代PCIe交换机已经超越了简单的“数据分发”角色,演变成了一个具备高度可配置性、高可用性和智能化管理能力的“互连Fabric”核心。
- 极致的灵活性(Elasticity): 通过动态端口拆分(Bifurcation)和分区,PCIe Switch可以适应从极高带宽的GPU(x16)到低速I/O设备的各种组合,且支持动态调整。
- 企业级高可用(Reliability): 强调了NTB(非透明桥接)和Crosslink的重要性。这是存储阵列(双控架构)和AI集群(参数同步、故障切换)中实现多机互连、消除单点故障的基石。
- 智能化运维(Intelligence): 内置DMA、虚拟端点和遥测功能,意味着交换机开始承担部分CPU的管理任务(数据搬运、状态监控),这对于大规模AI集群的性能优化至关重要。
结合上一页PPT,这页解释了为什么PCIe Switch能支撑AI应用。AI训练集群需要极高的稳定性和复杂的拓扑(如多机多卡),只有具备NTB跨域互连和全端口错误隔离的高级Switch,才能构建出既高性能又不会因为单个GPU故障而导致整个训练任务崩溃的坚固集群。
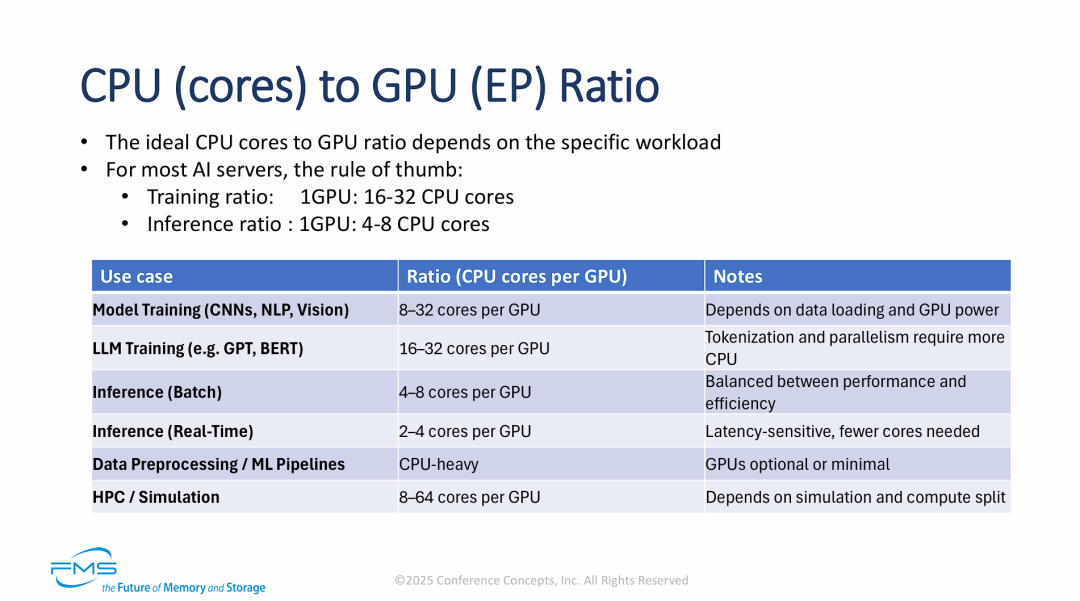
系统架构设计与资源配比
系统架构设计与资源配比
AI服务器架构设计必须拒绝“一刀切”,CPU与GPU的配比需根据“训练 vs 推理”以及具体模型类型进行精准适配。
上图数据为云数据中心服务器ODM设计提供有利参考
- 训练是“CPU吞噬者”: 特别是LLM(大语言模型)训练,不仅吃GPU显存,为了喂饱GPU,CPU需要进行繁重的Tokenization和数据加载任务,因此需要高达1:32的配比。
- 推理轻量化: 推理场景下,CPU的作用退居其次,主要负责简单的I/O转发,1:4甚至1:2的配比即可满足,这对于降低边缘计算或推理集群的成本至关重要。
- HPC的不确定性: 传统的HPC场景波动最大,最高可能需要1:64的配比,这暗示了在某些科学计算中,GPU只是协处理器,CPU依然是主力。
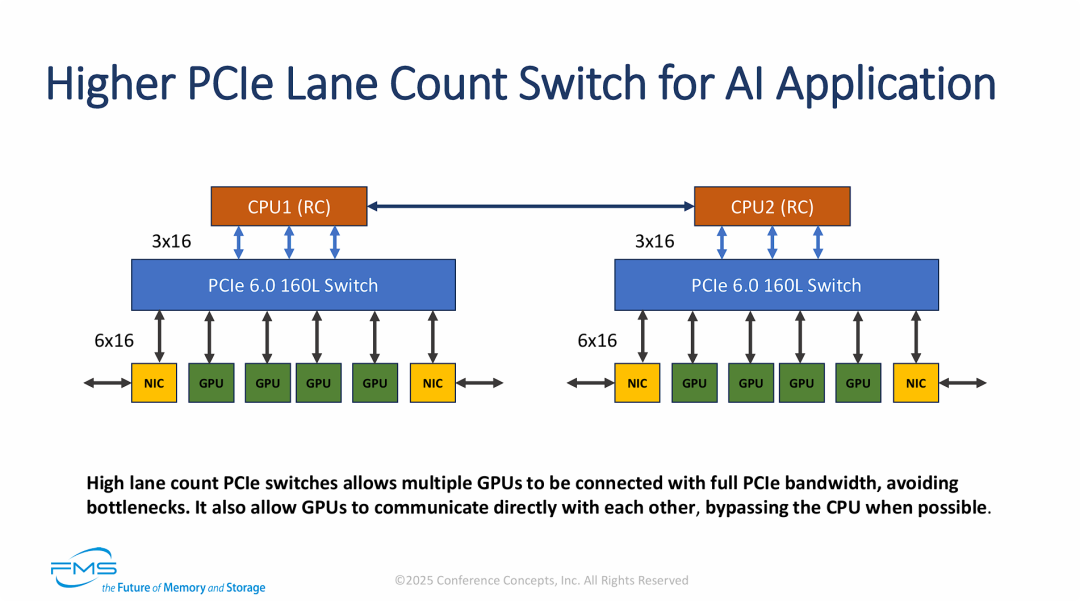
具体的连接拓扑和带宽分配
具体的连接拓扑和带宽分配
PCIe 6.0时代的160通道交换机,是构建高密度、低延迟AI集群的物理基础。
- 带宽无阻塞设计: 图中展示了单Switch下挂载4个GPU和2个NIC。通过PCIe 6.0 x16连接,确保了每个GPU都能满速运行,消除了I/O瓶颈。
- 网络与计算的融合: 此时Switch不仅连接GPU,还直接连接NIC(网卡)。这是AI集群(如基于InfiniBand或RoCE网络)的标准配置,为了支持集群间的横向扩展(Scale-out)。
- CPU卸载(Offloading): 再次强调了“Bypass CPU”。在Switch内部,GPU互访和GPU与NIC的数据交换不再经过CPU RC,这极大降低了CPU负载和通信延迟。
===
洞察(技术细节深挖):
- 收敛比(Oversubscription)分析:
- 下行带宽: 6个设备 x 16 Lane = 96 Lanes。
- 上行带宽: 3个链路 x 16 Lane = 48 Lanes。
- 比例: 这是一个 2:1 的收敛比(96:48)。
- 解读: 在AI训练中,大部分流量是GPU之间的参数同步(Switch内部交换)或GPU到网络的通信,而不是GPU到CPU的通信。因此,上行带宽减半是合理的架构优化,既节省了CPU的PCIe Lane资源,又保证了Switch内部的高速互通。
- 通道利用率计算:
- Switch总通道:160 Lanes。
- 已用通道:48 (上行) + 96 (下行) = 144 Lanes。
- 剩余通道: 16 Lanes。这预留的16条通道非常关键,通常用于:
- 连接两个Switch的Crosslink(虽然图中未画出,但为了形成Unified Fabric,通常需要连接),或者
- 连接本地NVMe存储,或者
- 管理端口。

异构加速器
异构加速器
现代AI计算平台正在演变为复杂的“异构生态系统”,而PCIe交换机是维系这个生态系统稳定运行的物理基石。
- 计算极度多样化: 系统不再是简单的x86 CPU + Nvidia GPU,而是变成了包含TPU、FPGA等多种ASIC(专用集成电路)的“大杂烩”。
- 互连面临物理挑战: 这种多样性带来了物理连接的噩梦——设备多了,距离远了,信号弱了。PCIe Switch在这里不仅做逻辑交换,还承担了信号中继(Repeater) 的角色,确保高速信号在复杂的机箱内部能够准确传输。
- 流量管理的复杂性: 交换机必须足够智能,才能在一个管道里同时调度好不同加速器的混合流量,避免互相阻塞。
===
洞察(技术深挖):
- 为什么信号中继是个大问题? 在PCIe 4.0时代,信号衰减还不是致命问题。但在PCIe 6.0时代,电信号在PCB板上跑不了多远就会失真。因此,这页提到的“Extending Reach”实际上是在暗示Retimer(重定时器) 技术和Switch内置Retimer功能的重要性。没有高质量的Switch/Retimer,异构计算的高性能就是空中楼阁。
- CXL的伏笔: 既然提到了异构加速器(特别是FPGA和加速卡),这就为引入 CXL (Compute Express Link) 埋下了伏笔。因为异构计算最大的痛点是内存不共享,CXL正是解决CPU与其他加速器之间内存一致性问题的关键协议。
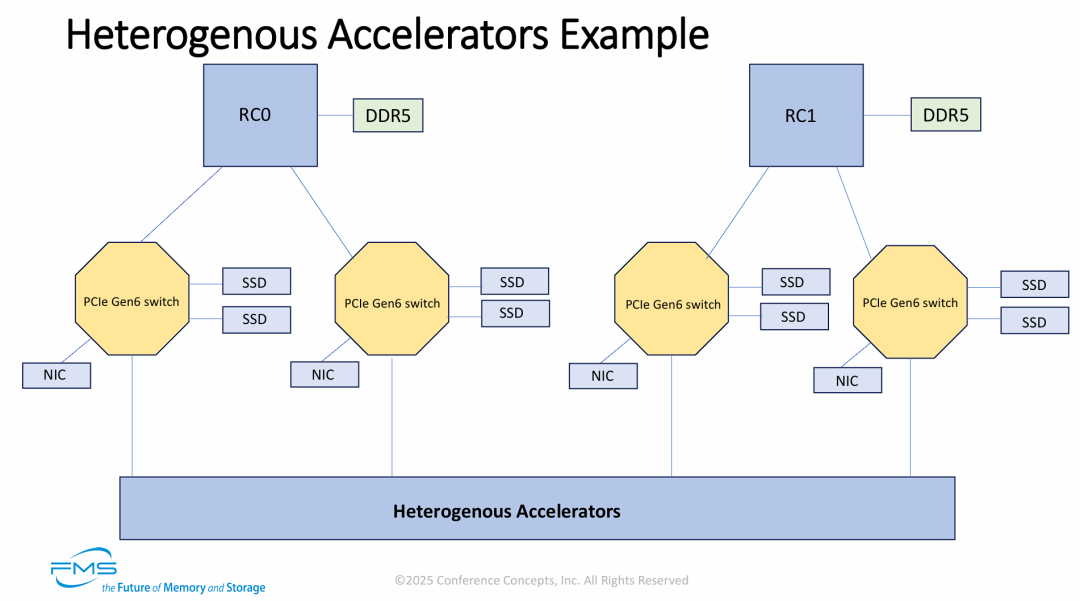
双路(Dual-Socket)服务器架构
双路(Dual-Socket)服务器架构
PCIe Gen6交换机是构建“存算网一体化”高性能AI架构的关键枢纽。
- 带宽为王(PCIe Gen6): 全链路采用PCIe Gen6,这是为了匹配DDR5内存和下一代GPU/TPU的极高I/O需求。
- 去中心化的I/O路径: 存储(SSD)和网络(NIC)被分散挂载在四个交换机下。这种分布式设计避免了单个I/O Hub的拥堵,支持数据通过RDMA直接注入加速器显存。
- 巨大的吞吐量聚合: 架构展示了四个Switch并行工作,共同为一个庞大的异构加速器池提供数据通道。这解释了为什么我们需要单芯片160 Lane这种级别的交换机——因为要支撑这种密集的扇入/扇出拓扑。
===
洞察(架构评价): 这是一个非常先进且典型的 Scale-Up(纵向扩展) 节点架构。
- 在传统的通用服务器中,NIC和SSD通常直接连在CPU上。
- 但在AI服务器中,CPU算力相对较弱,核心资产是底部的加速器池。因此,架构发生了翻转:交换机成为了真正的中心,CPU退化为控制节点,而网卡和存储则紧贴着交换机,只为服务底部的加速器而存在。
传统围绕CPU的服务器架构设计,随着加速业务负载的特征,将激变为围绕机架内网络互联,牢记新架构的设计核心,对于理解未来服务器架构选型设计有帮助。

高性能的PCIe交换机不仅仅是为了快,更是为了省钱。它通过技术手段(PAM-4/ECC)解决了信号完整性问题,使得廉价、开放、多厂商混用的硬件组合成为可能。
- 从“专用”走向“通用”: 通过PCIe标准构建开放生态,打破专有互连的高价壁垒,让企业能用标准件搭建AI服务器。
- 做减法(Simplifying): 利用Switch的“多合一”连接能力,消除冗余的互连组件,简化物理设计,降低硬件成本。
- 用技术换可靠性: 明确指出利用 PAM-4 和 ECC 技术,来弥补低成本硬件或复杂拓扑可能带来的信号质量下降问题,确保“便宜”但“稳定”。
===
洞察(技术与商业的结合):
- 为什么提PAM-4? 这再次印证了PPT在谈论 PCIe 6.0。PCIe 6.0之前的版本使用NRZ编码,而PAM-4是PCIe 6.0的标志。这意味着,只有到了PCIe 6.0时代,我们才能真正拥有足够大的带宽(64 GT/s)在单一Fabric上承载所有流量,从而实现真正的架构简化和成本降低。
- 市场定位: 这页PPT实际上是在对标那些想通过自建AI集群(On-premise)但预算有限的企业,或者是二线云服务提供商(Tier-2 Cloud Providers)。他们买不起全套NVIDIA DGX SuperPOD,但通过这种基于PCIe 6.0 Switch的开放架构,可以用更低的成本组装出性能不俗的算力集群。

核心观点可以提炼为:“AI定义了新一代PCIe交换机。”
- 市场转型: PCIe交换机市场的主要增长动力已从存储(Storage)不可逆转地转向了AI算力互连(AI Fabric)。
- 技术门槛剧增: 这里的“Switch”不再是简单的桥接芯片,而是演变成了具备 160 Lane超大规模、PCIe 6.0超高带宽、PAM-4信号调制、且支持异构协议 的复杂通信处理器。
- 生态价值: PCIe Switch的最大价值在于开放性(Openness)。它打破了单一厂商对AI互连的垄断,允许数据中心利用低成本、多厂商的加速器构建高效能集群,这对于AI技术的普及至关重要。
延伸思考
这次分享的内容就到这里了,或许以下几个问题,能够启发你更多的思考,欢迎留言,说说你的想法~
- PCIe Fabric的边界: 既然PCIe Switch正在向AI Fabric演进,那么它与InfiniBand/RoCE等传统网络Fabric相比,在构建超大规模(Scale-out)AI集群时,其性能、成本和管理复杂度的边界在哪里?
- CXL的颠覆性: 文章提到CXL是解决异构计算内存一致性的伏笔。在PCIe Switch成为中心的架构中,CXL协议将如何具体改变GPU、CPU和内存之间的拓扑关系,它是对现有PCIe互连的增强还是潜在的取代者?
- 软件定义I/O挑战: 架构从“CPU中心”翻转到“Switch中心”,意味着CPU退化为控制节点。这是否会引发新的软件定义I/O(SDI)挑战,即如何高效地管理和调度一个由Switch主导的、高度异构的加速器池?
原文标题:PCIe Switch Applications in AI System[1]
Notice:Human's prompt, Datasets by Gemini-3-Pro
#FMS25 #PCIe互联与服务器架构
---【本文完】---
👇阅读原文,搜索🔍更多历史文章。
- https://files.futurememorystorage.com/proceedings/2025/20250807_AIML-302-1_Do.pdf ↩
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号