Codex Windows 客户端来了,深读官方文档后我有 5 个判断

Codex Windows 客户端来了,深读官方文档后我有 5 个判断

Ai学习的老章
发布于 2026-03-27 12:33:32
发布于 2026-03-27 12:33:32
OpenAI 一周四连发,没想到大家对Codex Windows 端的兴趣超过了 GPT-5.4-Thinking
OpenAI 也十分豪爽,免费用户都能在 CodeX 体验到 GPT-5.4,本文就完完整整把 Codex 介绍清楚,OpenAI官方建议对玩法,以及我的建议。

最近 OpenAI 对 Codex 的更新很密,很多朋友一上来就问:这玩意儿到底是个 CLI、一个网页版,还是一个能自己干活的编程 Agent?
如果你只看一两篇“5 分钟上手”教程,很容易得出一个很浅的结论:哦,Codex 不就是在终端里帮我改代码嘛。
但我把 OpenAI 官方产品页、开发者文档、OpenAI Academy 教程,以及几篇日期比较新的社区教程重新过了一遍之后,结论反而更明确了:
Codex 现在已经不是“补全代码”的工具思维了,而是“可监督、可配置、可并行、可审计的软件工程代理”。
而且这个判断不是吹出来的,是 OpenAI 自己在 2025 年 5 月到 2026 年 3 月这条时间线上,一步一步把它做成这样的。
本文我按 AI/开发者 视角来写,重点是:
- Codex 现在到底是什么。
- 官方推荐的高阶用法是什么。
- 为什么很多社区教程只能带你入门,带不了你深入生产环境。
- 我更建议你用什么姿势,真正把 Codex 用起来。

先说结论:2026 年 3 月的 Codex,已经是“一套统一代理”
如果只看 OpenAI 最新几份官方材料,Codex 的轮廓已经非常清楚了。
2025 年 5 月 16 日,OpenAI 发布《Introducing Codex》,把它定义成一个运行在云端、可并行处理多个任务的软件工程 Agent。当时它强调的是:
- 每个任务都在独立沙箱里运行。
- 它能读代码、改代码、跑测试、跑 lint、跑 type check。
- 任务通常耗时 1 到 30 分钟。
- 结果里会给你终端日志、测试输出、修改证据,方便你复核。
到了 2026 年 3 月 4 日,OpenAI 发布《Introducing the Codex app》,这个定位进一步升级了。官方已经不再把 Codex 只讲成一个“会写代码的模型”,而是讲成一套跨多个入口的一致代理系统:
- App
- CLI
- Web
- IDE extension
- GitHub integration
OpenAI Academy 在 2025 年 8 月发布、并于 2026 年 2 月更新的《Codex for Builders》里,也明确把 Codex 描述为 one unified agent, one product。
这句话很关键。
因为它意味着,你不应该把 Codex 理解成一个单点工具,而应该把它理解成一个统一代理,在不同工作界面里用不同“壳子”呈现出来。
更直白一点说:
- CLI 是它最贴近工程师日常工作的入口
- Web / App 更适合任务委派、后台排队和多线程管理
- IDE extension 更像把 agent 能力嵌回你最熟悉的编辑环境
- GitHub integration 则把它推进到代码评审和协作链路里
所以,今天再问“Codex 到底是 CLI 还是网页端”,其实已经问偏了。更准确的问法应该是:你准备在哪个工作界面里调度同一个 Codex agent。
这和传统 AI 编程工具最大的区别是什么?
我觉得核心不是“它能写多少代码”,而是它的工作模式变了。
以前很多 AI 编程工具,本质还是“你问一句,它答一句;你改一点,它补一点”。这是一种“陪打字”模式。
Codex 不是。
官方文档和产品文案反复强调的是三件事:
- 异步 delegation 你把任务派给它,它自己去执行。
- parallel agents 多个任务可以并行开跑,而且互相隔离。
- reviewable evidence 它不是只给你一个结果,而是给你过程证据。
这三点合起来,才是 Codex 真正值钱的地方。
也就是说,Codex 最适合的,不是“帮我把这行代码补全一下”,而是:
- 去陌生仓库里梳理一段链路
- 批量改一个旧接口
- 补测试
- 起草一个 PR
- 在后台跑一个需要较长上下文的任务
这也是 OpenAI 自己内部的使用方式。
OpenAI 自己怎么用 Codex?
这一点我最推荐你读官方那篇《How OpenAI uses Codex》。
因为很多产品页会告诉你“它能做什么”,但真正能告诉你“它适合怎么进入工程流程”的,往往是这种内部使用总结。
OpenAI 在这篇文章里给出的信息很关键:Codex 不是只被某一个实验团队试用,而是已经进入多个一线技术团队的日常,包括:
- Security
- Product Engineering
- Frontend
- API
- Infrastructure
- Performance Engineering
这说明两件事。
第一,Codex 不是只能在“新项目、绿地项目、Demo 项目”里表现好,它也在老代码、复杂系统、跨模块协作里被使用。 第二,它被真正拿去做的,恰恰不是最炫的工作,而是最工程化、最讲究稳定交付的工作。
他们的典型用法,不是“让它从零写个项目”,而是下面这些特别工程化的工作。
1. 理解陌生代码库
比如:
- 认证逻辑到底在哪
- 某个请求从入口到响应怎么流转
- 哪些模块和某个模块有交互
这一类问题,工程师自己翻代码当然也能翻,但非常消耗上下文切换成本。Codex 在这里的价值,不是替你“理解”,而是先把地图摊开,再把几个可疑入口、关键文件和数据流标出来。你最后仍然要判断,但你不必再从黑盒开始。
2. 重构和迁移
比如一个旧模式要统一切到新模式,影响十几个文件、几十个调用点。
这种改动最怕两件事:一是漏改,二是改得不一致。Codex 的优势不是单点生成能力,而是它能在读到上下文后,把同一种迁移模式稳定地复制到多个位置。这个能力在“结构性改动”里,远比写一段新函数更有价值。
3. 性能和可靠性问题
官方提到,他们会让 Codex 去扫描慢路径、重复数据库调用、低效循环,然后给出可执行修改建议。
我觉得这里最重要的,不是它能不能一把改对,而是它很适合先做第一轮排查:把热路径、可疑调用点、潜在重复工作先框出来。对于性能问题,这一步本来就很费人。
4. 补测试
这个我特别认同。
很多人让 AI 写代码,最容易忽略测试;但 OpenAI 内部反而把 Codex 大量用在补边界条件测试、补失败路径测试、补低覆盖率区域上。
这个路子非常对。因为测试补全本身往往规则清晰、验收明确、但人工又很容易嫌麻烦。把这类“重要但不性感”的工作交给 Agent,性价比非常高。
你会发现,OpenAI 自己给出的这些案例,几乎都不是“让 Codex 完成一个从产品定义到上线的全流程”,而是把它嵌进现有研发流程里,去吃掉那些高成本、强上下文、但规则相对明确的工作。
这其实比“AI 一键生成整个项目”更现实,也更接近大多数团队真正能落地的用法。
真正理解 Codex,要看它背后的“harness”
如果你想把 Codex 用深,而不是停留在“终端里敲两句 prompt”,我强烈建议你看 OpenAI 2026 年 2 月 4 日那篇官方技术文章:
《Unlocking the Codex harness: how we built the App Server》
这篇文章讲明白了一件很多人没意识到的事:
Codex 的关键不是某个 UI,而是同一套 agent loop 和 tool/runtime 逻辑。
官方在文中说得很清楚:
- Codex 存在于 Web、CLI、IDE extension、桌面 App 等多个入口
- 这些入口背后共用同一个 Codex harness
- 中间的关键层是 App Server,一个面向客户端的双向 JSON-RPC API
这个架构设计有什么意义?
我理解有三点。
第一,它让多个“前端界面”共享同一套能力
今天你在 CLI 里做的事情,和你在 App、IDE 里做的事情,并不是三套完全不同的系统。
所以官方才会强调:
- 配置可以共享
- 历史可以共享
- 技能可以共享
第二,它让“审批、线程、工具调用”变成一等公民
在这篇文章里,OpenAI 不只是说 Codex 会跑工具,而是把下面这些概念都定义得很明确:
- thread
- turn
- item
- approval request
- diff
- tool execution
换句话说,Codex 不是简单调用模型回复文本,而是在管理一整套可恢复、可中断、可审批、可回放的执行流。
第三,它解释了为什么 Codex 能走向多代理协作
官方在 2026 年 3 月 4 日的 app 文章里说得更直接:现在很多开发者已经在同时调度多个 agent,让它们并行处理不同任务。
这不是一句空话。
如果没有统一的线程模型、审批模型、工具模型、工作区隔离模型,多代理基本就是灾难。
Codex 现在之所以能往这个方向走,靠的就是这一层底座。
你如果只会“装 CLI”,那只用了 Codex 的 20%
我看了 OpenAI 的官方帮助文档《Codex CLI》,也看了社区教程。很多教程把重点都放在安装:
npm i -g @openai/codex
codex
装上当然重要。
但说实话,这只是最浅的一层。它解决的是“你能不能启动 Codex”,没有解决“Codex 进来以后按谁的规则干活”。
如果把 Codex 只当命令行工具,你关注的通常只有三个问题:能不能装、能不能登录、命令怎么写。可一旦你想把它用进真实仓库,你马上会遇到另外一组问题:
- 它应该先读哪些文件
- 哪些目录能改,哪些目录不能动
- 改完必须跑哪些验证
- 什么命令要审批,什么命令可以自动通过
- 团队里的隐性约定,怎么稳定传给它
也就是说,CLI 只是入口,不是方法论。真正决定效果差距的,是你有没有把仓库、权限和验证链路准备好。
OpenAI 官方真正想让你掌握的,是下面几件事。
第一件事:学会用 AGENTS.md 给 Codex“立规矩”
这是我认为 Codex 最容易被低估、也最容易拉开效果差距的点。
官方在最早的《Introducing Codex》里就说了,Codex 可以被仓库中的 AGENTS.md 文件引导。OpenAI Developers 后来专门写了一整篇《Custom instructions with AGENTS.md》来解释它。
它不是一个装饰文件。
它的本质,是把你原来只存在于团队脑子里的隐性规则,显式交给 Agent。
比如你可以告诉它:
- 先看哪些目录
- 改完必须跑什么命令
- 优先用什么包管理器
- 哪些文件不要动
- 哪些模块有历史坑
- PR 要遵循什么风格
官方文档里有个非常关键、但很多二手教程不会细讲的点:Codex 会按从根目录到当前目录的路径逐层发现 AGENTS.md,近处规则覆盖远处规则。
这个机制为什么重要?因为它意味着 AGENTS.md 不是单一总规章,而是可以分层治理:仓库根目录写通用原则,子目录写局部例外,离当前任务越近的规则优先级越高。这对 monorepo、多人协作项目、或者存在历史包袱的服务拆分仓库都非常实用。
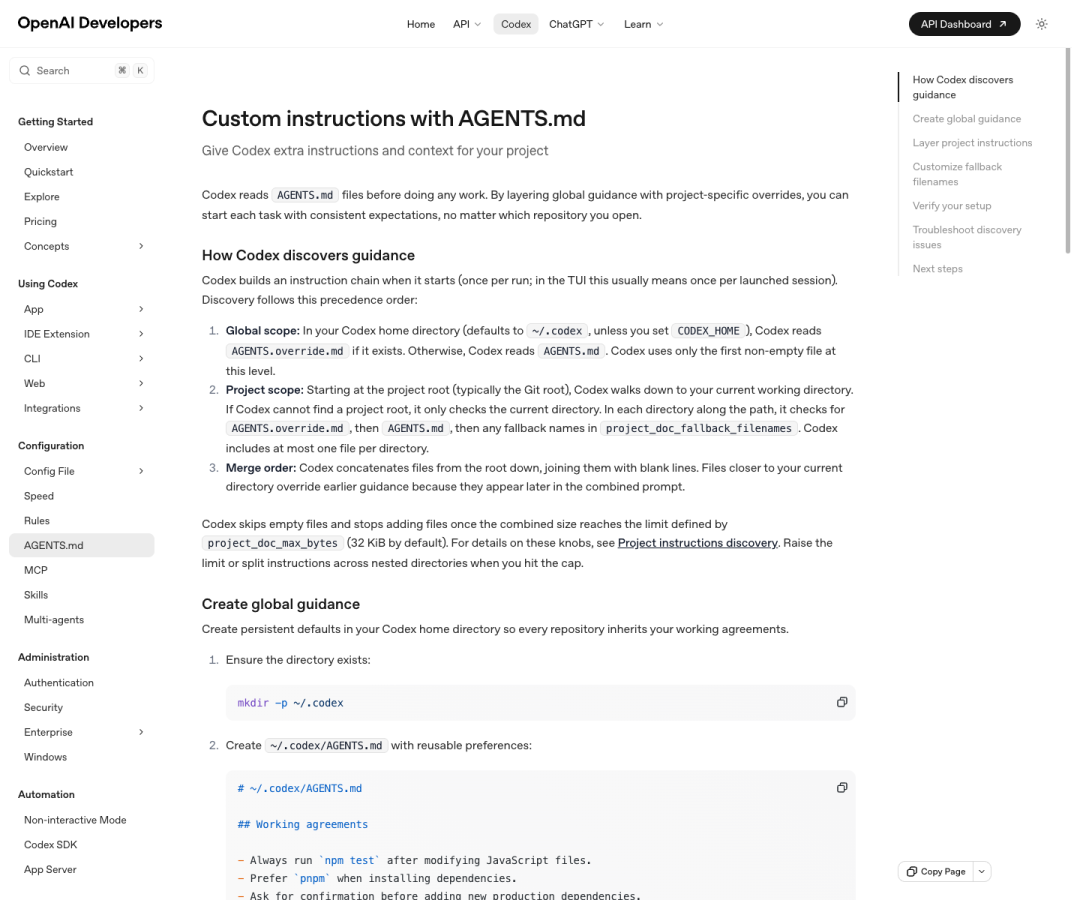
我建议你至少写到这个程度:
# AGENTS.md
## 项目目标
- 这是一个 React + TypeScript 项目。
- 优先保持现有设计系统和目录结构,不要引入新的 UI 框架。
## 工作约束
- 修改前先阅读相关文件,不要直接大改。
- 修改前先给出简短计划。
- 优先使用 `rg` 搜索代码。
## 验证要求
- 改完前必须运行:
- `pnpm lint`
- `pnpm test`
## 风格要求
- 不要无意义重命名。
- 不要新增与任务无关的依赖。
- 对用户可见行为变化,要补测试或明确说明。
这不是形式主义。
你给 Codex 的上下文越稳定,它越像你团队里的工程师;你不给,它就更像一个“很强但不熟你家规矩的外援”。
更进一步说,AGENTS.md 的真正价值不是“让它听话”,而是把原本依赖口口相传的工程经验,变成可重复、可审计、可继承的工作协议。等你把这个文件写好以后,Codex 才不是每次进仓库都重新猜一遍,而是从进门那一刻起就知道边界在哪。
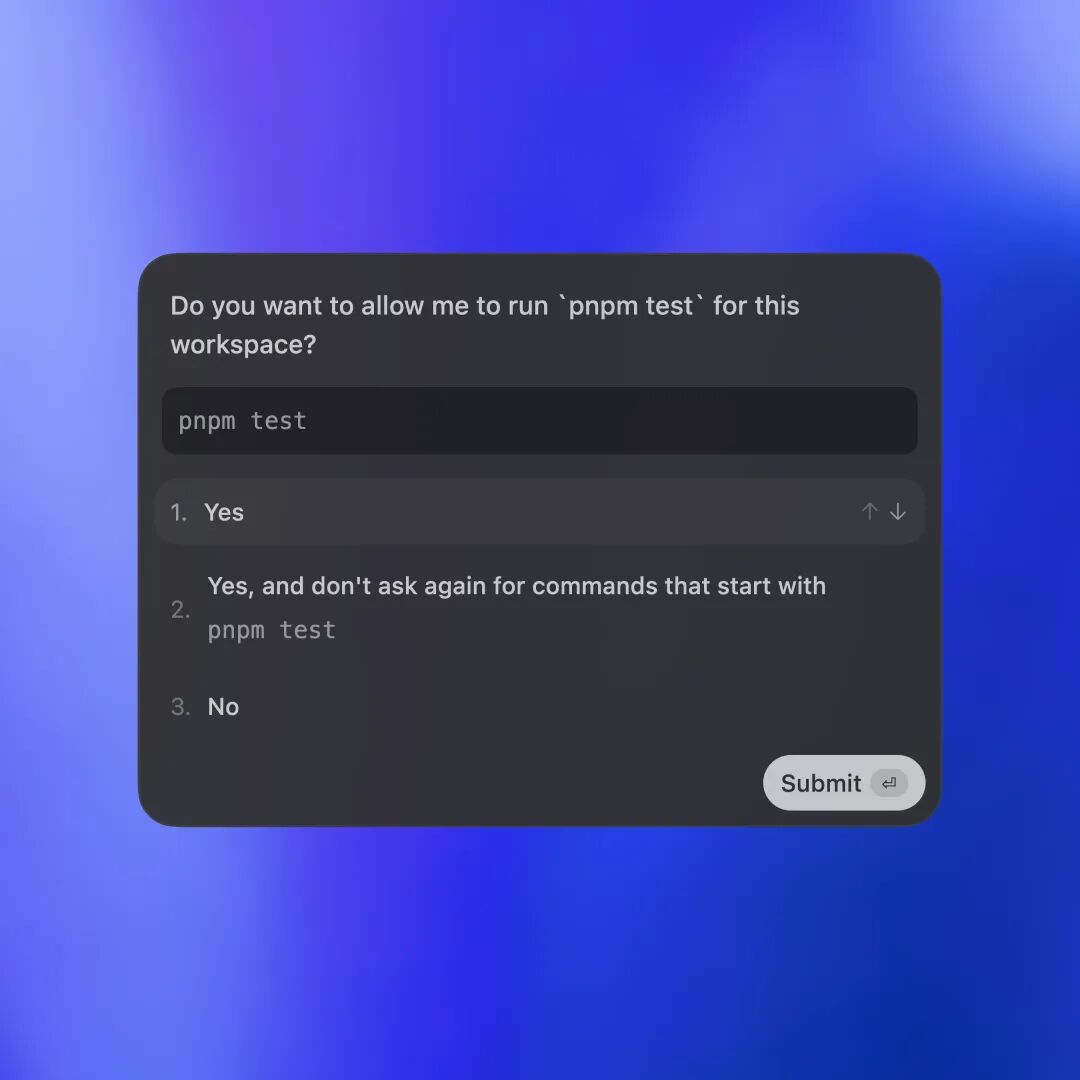
第二件事:别忽视 approval 和 sandbox
这一点,官方最近讲得越来越细。
在 2025 年 5 月最初那篇《Introducing Codex》里,OpenAI 说得比较保守:云端 agent 默认跑在隔离容器里,执行任务时互联网是关闭的。
但到了后续文档和 app 文章,策略明显更成熟了。
OpenAI 现在强调的是:
- 默认尽量在受限范围内运行
- 对高权限动作发起审批
- 可以通过规则配置让某些命令自动放行
- Web search 默认也可以走缓存或 live 模式
这背后的逻辑很简单:
你想让 Agent 真能干活,就不能把它锁成废物;但你想让它进入生产流程,也不能完全放飞。
所以 Codex 的正确姿势不是“全自动”或者“全手动”二选一,而是:
- 小任务高审批
- 熟悉仓库逐步放权
- 高风险命令单独立规则
- 外网访问按需开启
第三件事:把 Codex 当“异步同事”,不要只当“同步助手”
这是我看完官方材料之后,感受最深的一点。
很多人拿到 Codex,还是下意识按 ChatGPT 的方式用:
- 提一个问题
- 等回答
- 再提一个问题
这当然能用,但浪费了它最强的能力。
OpenAI 自己在《How OpenAI uses Codex》里提到,他们会把 Codex 当成一个轻量 backlog 池,把附带修复、背景任务、补测试、问题排查等任务丢给它后台跑。
而 2026 年 3 月 4 日的 Codex app 文章,则明确在产品层面支持这种使用方式:
- 多线程
- 多项目
- worktrees
- 多 agent 并行
- 长时间任务协作
这套思路我特别赞同。
因为这才是 Agent 和传统 AI 助手的分水岭。
它最值钱的不是把一句话回答得多漂亮,而是帮你把被会议打断、被上下文切碎、被琐事拖慢的工程工作重新组织起来。
第四件事:你要学会区分“配对模式”和“委派模式”
我把官方资料看完以后,基本把 Codex 的使用分成两种。
模式一:配对模式
适合:
- 问代码问题
- 看一段逻辑
- 让它快速草拟局部改动
- 一边看、一边改、一边聊
这个模式更接近 CLI、IDE 里的即时协作。
模式二:委派模式
适合:
- 一次跨多个文件修改
- 重构
- 批量迁移
- 补测试
- 背景排查
- 起草 PR
这个模式更接近 Codex Web、App、GitHub 集成,或者 CLI 里的长任务。
很多人为什么觉得 Codex“还行,但没想象中神”?
往往不是模型不行,而是把该委派的任务,硬当配对任务来做;或者把该高频互动的任务,扔给它一口气跑到底。
第五件事:把环境配置好,效果会差很多
这个官方也反复说了。
在《Introducing Codex》《Codex CLI》《Codex Prompting Guide》这些材料里,都能看到同一个意思:
Codex 在“环境可复现、测试可运行、项目约束清晰”的仓库里,效果明显更稳定。
所以我建议你别只装 CLI,至少把下面这些也补上:
- 仓库根目录写
AGENTS.md - 保证测试命令真的能跑
- 把依赖安装脚本整理好
- 把高风险命令审批规则理清楚
- 关键目录和模块边界写清楚
如果这些都没有,Codex 依旧能工作,但更容易出现:
- 改对了代码,没跑对验证
- 不知道该从哪进代码库
- 不清楚哪些行为变化可接受
- 过度保守,或者过度大胆
官方文档里,哪些最值得读?
如果你想少走弯路,我建议按这个顺序读。
这里不是简单按“谁更基础、谁更进阶”排序,而是按认知搭建顺序来排:先知道产品长什么样,再知道它怎么被约束,最后再知道它为什么能在工程体系里跑起来。
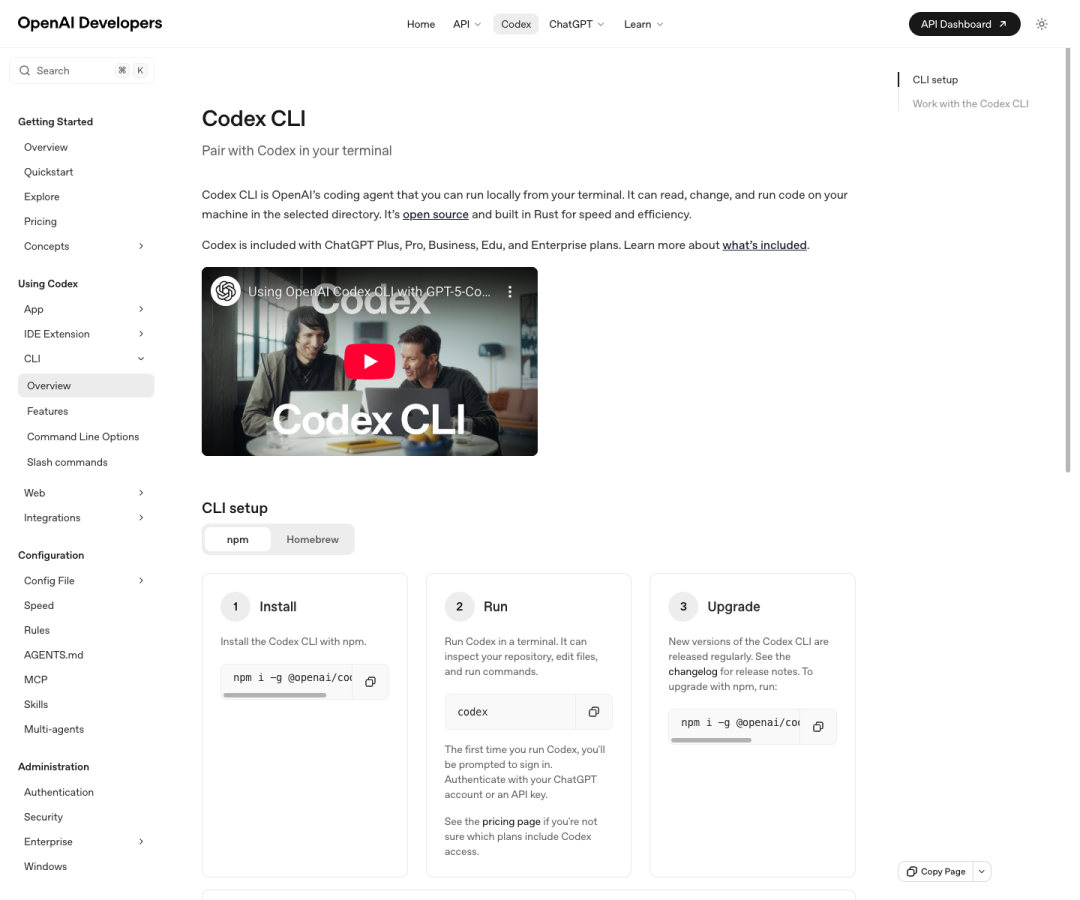
1. 入门先看:Codex CLI / Codex Overview
这是把“能跑起来”搞定的部分。
你至少得知道:
- 怎么安装
- 怎么登录
- 它有哪些入口
- 它在什么订阅计划下可用
OpenAI 文档里给的安装方式很直接:
npm i -g @openai/codex
codex
首次运行时,可以用 ChatGPT 账号 或 API key 登录。
但这篇文档真正重要的,不只是安装命令,而是它把 CLI 放回整个 Codex 产品版图里。你会看到本地交互、云端任务、多代理、审批模式、Web search、MCP 这些能力,实际上都不是“额外插件”,而是同一条能力线的不同开口。
2. 真正进阶先看:AGENTS.md 指南
这篇我认为是“效果分水岭”。
因为它讲的不是怎么把 prompt 写得更花,而是怎么把团队规范、目录边界、验证约束和局部规则稳定传递给 Agent。很多人觉得自己在“调模型”,其实真正决定稳定性的,是你有没有把规则系统化。
如果只读一篇偏实践、又能立刻提升效果的文档,我会优先推这篇。
3. 再往上走:Codex harness 技术文章
如果你想理解:
- 为什么 Codex 能跨 CLI / IDE / App 一致工作
- 为什么审批和线程这么重要
- 为什么它能走向多 agent
那篇《Unlocking the Codex harness》一定要看。
它的价值在于,把很多表面上看像“产品体验”的东西,落回到执行流、线程模型、JSON-RPC、审批流和工具调用这些底层机制上。你读完以后,就不太会把 Codex 误解成“换了个壳子的聊天模型”。
4. 最后看:How OpenAI uses Codex
这篇最适合你建立“工程场景感”。
它会帮你判断,什么样的任务值得委派给 Codex,什么样的任务更适合先 Ask、再 Code,什么样的任务应该由你自己握住最后决策权。
换句话说,前面几篇是在教你“Codex 是什么”,这篇是在教你“Codex 在团队里应该坐哪张椅子”。
5. 补齐方法论:Codex Prompting Guide
这篇我建议一定读,而且别把它当“提示词技巧文”。
它真正有价值的部分,不是教你写漂亮 prompt,而是说明 Codex 在高质量工程工作里,到底吃什么:
- 结构化任务描述
- 明确的工具边界
- 并行读文件
- 长任务中的中途更新
- 持续保留
phase等执行元信息
也就是说,它更像 Codex 的“协作手册”,不是“营销式教程”。
互联网上较新的教程,哪些值得看,哪些要保留怀疑?
这一段我专门挑了日期较新的教程。
但这里我要提前说一句:
社区教程很适合帮你建立手感,不适合代替官方文档。
原因很简单,Codex 这半年变化太快了。2025 年中期你看到的一些讲法,到 2026 年 3 月已经很可能只剩“历史阶段的合理说法”,不再适合作为当前定义。
我推荐优先看的
1. OpenAI Academy “Codex for Builders”
优点:
- 日期新,2026-02-26 还更新过
- 不是只讲安装,而是讲使用场景
- 明确区分了 CLI、IDE、Web、GitHub 等多个入口
- 讲到了 headless mode、CI/CD、ChatGPT plan 登录等实操点
这篇很适合建立全局认识。它的价值在于把 Codex 当成完整产品来讲,而不是单一终端工具。
2. OpenAI Developers “Codex Prompting Guide”
这篇不是面向普通用户的“教程”,但如果你真想把 Codex 用深,它其实比很多社区教程都更重要。
因为它讲的是:
- Codex 更吃什么样的上下文
- 怎么组织任务描述
- 为什么
AGENTS.md重要 - 为什么要减少零碎读文件
- 为什么并行工具调用很关键
这篇更像“怎么和 Codex 协作”的方法论文档。
3. DataCamp “OpenAI Codex CLI Tutorial”
这篇的优点是够直观,有具体案例和截图,适合第一次建立体感。
但我不建议你把它当作“官方标准答案”。
原因是它明显保留了 Codex 早期阶段的一些说法,比如用较旧的模型描述和较旧的 approval mode 叙事框架。 这是我的判断,不是 OpenAI 官方原话。
也就是说,这类教程适合你理解“怎么上手”,不适合你拿来定义“Codex 现在到底是什么”。
4. RYZ Labs / agentsmd.io 这类补充材料
这类文章可以当“辅助理解材料”,尤其适合看别人怎么把 AGENTS.md 真写进项目流程里。
但我建议你保持一个判断标准:凡是没有把发布日期、更新日期、适用入口、权限模型讲清楚的教程,都不要直接拿来当当前规范。 因为 Codex 的产品边界和文档表述都还在快速演进。
那么,怎么才算“深度使用”Codex?
如果是我来给一个更实用的工作流,我会这么用。
第一步:先把仓库变成“对 Agent 友好”的仓库
至少做三件事:
- 写
AGENTS.md - 确保测试命令和 lint 命令可运行
- 把项目结构和禁区写清楚
这一阶段的目标不是立刻提效,而是先减少 Codex 误判。很多人觉得 Agent“不稳定”,其实不是模型不行,而是仓库本身对外包工程师就不友好,对 Agent 当然更不友好。
第二步:先让 Codex 做理解和规划,不急着直接改
比如先问:
- 这个仓库里认证逻辑在哪
- 某个请求链路怎么走
- 如果要改 X,涉及哪些模块
- 先给我一个实现计划
这个阶段,目的是让它先“看图识路”。先让它画地图、列影响面、拆工作包,再进入修改,往往比一上来就“帮我改”稳定得多。
第三步:把任务切成 30 分钟到 2 小时级别的工程单元
这是我从官方材料里读出来的一个隐藏共识。
Codex 很适合的任务,不是漫无边际的大项目,也不是只有一行代码的小改动,而是:
- 边界明确
- 可验证
- 有完成标准
- 涉及多个文件但不至于无限发散
你可以把它理解成:最好把任务切到“一个靠谱工程师拿到后,半天内能闭环”的粒度。这个粒度,最适合 Agent 发挥。
第四步:让多个 agent 并行,而不是让一个 agent 背所有锅
比如:
- 一个 agent 查问题根因
- 一个 agent 补测试
- 一个 agent 起草重构
最后你来 review 和收口。
这才是官方一直强调的 parallel agents 真正的价值。它不是为了炫酷,而是为了把原本只能串行完成的工作,拆成几个相互隔离、可回收、可审阅的子任务。
第五步:只把“可验证任务”交给它闭环
我现在越来越觉得,判断一个任务该不该交给 Codex,不是看任务大不大,而是看:
它有没有明确验收标准。
比如:
- 测试通过
- lint 通过
- 某个接口行为符合预期
- 某个文件迁移完成
这种任务就特别适合 Agent。
反过来,如果是:
- 需求本身还模糊
- 多方利益还没对齐
- 架构决策还没定
那你最好先别把希望全压给它。Agent 在“定义已明确、执行成本高”的任务上最强,在“问题本身还没定义清楚”的任务上并不会自动替你做出正确决策。
我对 Codex 的最终判断
如果只把 Codex 当作“OpenAI 版 Cursor/Claude Code CLI 替代品”,你会低估它。
如果把它当成一个可以:
- 理解代码库
- 被
AGENTS.md驯化 - 在审批与沙箱中安全运行
- 在多个界面里共享能力
- 支持并行多代理协作
- 能给出日志、diff、测试证据
的统一工程代理系统,那你就更接近它现在真正的定位了。
我自己的看法很明确:
Codex 最强的地方,不是“会写代码”,而是开始具备“像工程团队成员一样被管理、被配置、被监督、被并行调度”的能力。
这才是它和“聊天式写代码”真正拉开差距的地方。
如果你只是偶尔写点脚本,装个 CLI 玩玩就够了。
但如果你真的想把它用进日常研发流程,那你必须把注意力放到这些更深的层面上:
- AGENTS.md
- approval / sandbox
- worktrees
- parallel agents
- 可验证任务设计
- 统一入口下的一致工作流
我最后给你的阅读顺序
如果你今天只想花 1 小时把 Codex 看明白,我建议这样读:
Introducing the Codex app先建立 2026 年的产品全貌。How OpenAI uses Codex再看真实工程场景。Custom instructions with AGENTS.md然后学会怎么把它调成“你的人”。Unlocking the Codex harness最后理解它为什么能跨 App、CLI、IDE 工作。
你会发现,真正高阶的 Codex 用法,从来不是“prompt 写得多花”,而是把工程上下文、权限边界、验证机制和任务拆分,喂给一个统一代理系统。
制作不易,如果这篇文章觉得对你有用,可否点个关注。给我个三连击:点赞、转发和在看。若可以再给我加个🌟,谢谢你看我的文章,我们下篇再见!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号