Agent Skills 开发实战:轻松搞定 10 个 Milvus 集群的运维管理

Agent Skills 开发实战:轻松搞定 10 个 Milvus 集群的运维管理

运维有术
发布于 2026-04-01 18:43:09
发布于 2026-04-01 18:43:09
🚩 2026 年「术哥无界」系列实战文档 X 篇原创计划 第 24 篇,Skills 最佳实战「2026」系列第 11 篇 大家好,欢迎来到 术哥无界 | ShugeX | 运维有术。 我是术哥,一名专注于 AI 编程、AI 智能体、Agent Skills、MCP、云原生、Milvus 向量数据库的技术实践者与开源布道者! Talk is cheap, let's explore。无界探索,有术而行。
封面图
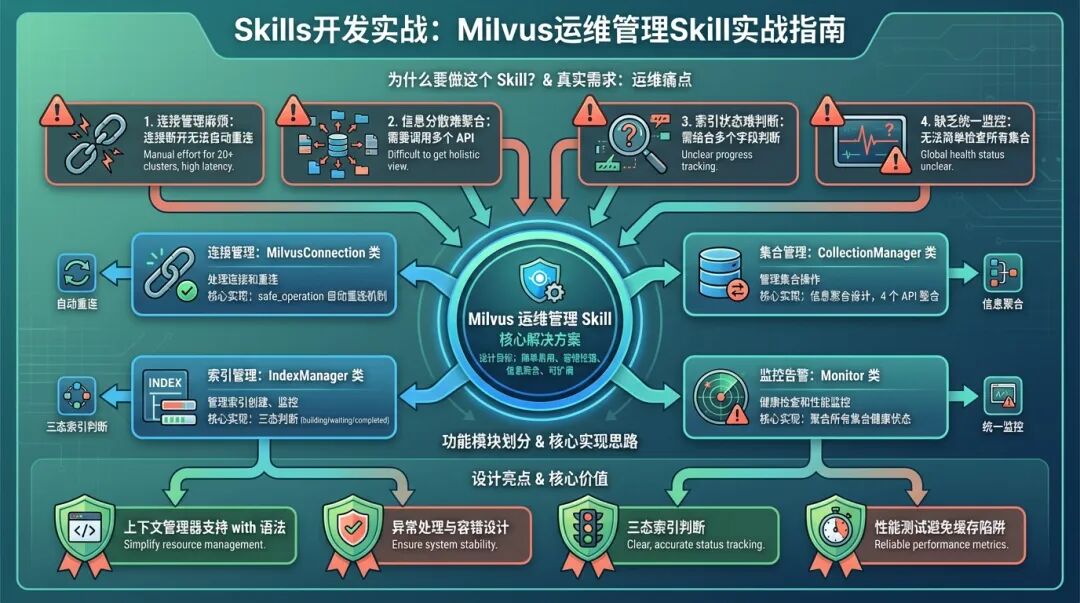
为什么要做这个 Skill?
上周三晚上十点,我正准备下班,监控群里突然弹出一条告警:生产环境的 Milvus 集群查询延迟飙升到 5 秒以上。
我打开 Attu 管理界面,发现有个集合的索引还在 building 状态,而新数据还在源源不断地往里灌。这个问题我之前踩过坑——索引构建跟不上数据插入速度,查询性能会直线下降。
但问题来了:我们要同时管理 10 多个 Milvus 集群,每个集群有几十个集合,靠手动检查根本不现实。有没有办法自动化地监控所有集群的健康状态?
这就是 Milvus 运维管理 Skill 的由来。
真实运维场景
图1:真实运维场景 - 多集群监控痛点
先说说 Milvus 是什么
Milvus 是一个高性能的向量数据库,专门用来处理大规模的向量相似性搜索。简单说,它能帮你在海量数据中快速找到"相似的东西"。
比如:
- 搜索"好吃的川菜",能找到相关菜谱,不只是包含关键词的文章
- 上传一张商品图,能找到视觉上相似的其他商品
- 做推荐系统时,根据用户历史向量推荐相似的商品
这些场景的核心都是把文本、图片等数据转换成向量,然后在向量空间里找最近邻。
但 Milvus 的运维并不简单。它有复杂的索引机制(HNSW、IVF 等),需要关注集合的加载状态、索引构建进度,还要监控查询性能。这些都是传统数据库没有的概念。
真实需求:运维痛点
在实际运维中,我们遇到了这些问题:
1. 连接管理麻烦
Milvus 的连接会因为网络波动、超时等原因断开,而 pymilvus 的连接断开后无法自动重连。每次都要手动检测连接状态,写一堆重复代码。
2. 信息分散难聚合
查看一个集合的状态,需要调用多个 API:describe_collection 看基本信息、get_collection_stats 看数据量、get_load_state 看加载状态、list_partitions 看分区。这些信息散落在不同的 API 里,没有一个统一的视图。
3. 索引状态难判断
索引的状态字段是字符串("Building"、"Finished"),但需要结合 total_rows 和 indexed_rows 来判断真正的状态。比如索引显示 "Finished",但如果 indexed_rows 小于 total_rows,说明还有数据没建好索引。
4. 缺乏统一监控
没有一个简单的方法来检查所有集合的健康状态,需要写复杂的脚本循环调用多个 API。
这些痛点就是我们要解决的核心问题。
技术方案设计
设计目标
简单易用:一行命令检查所有集合健康,不需要写复杂的脚本
容错性强:网络波动、连接断开自动重连,不会因为一个小问题就整个脚本崩溃
信息聚合:把分散在多个 API 的信息整合到一起,返回完整的视图
可扩展:模块化设计,方便添加新的功能
技术选型
- 语言:Python 3.14,pymilvus 官方支持最好
- 执行方式:
uv run -p 3.14 --no-project --with pymilvus scripts/xxx.py,快速执行不需要完整项目 - 核心库:pymilvus
功能模块划分
我设计了四个核心模块:
- 连接管理:MilvusConnection 类,处理连接和重连
- 集合管理:CollectionManager 类,管理集合的创建、删除、加载、释放
- 索引管理:IndexManager 类,管理索引的创建、删除、监控
- 监控告警:Monitor 类,统一的健康检查和性能监控
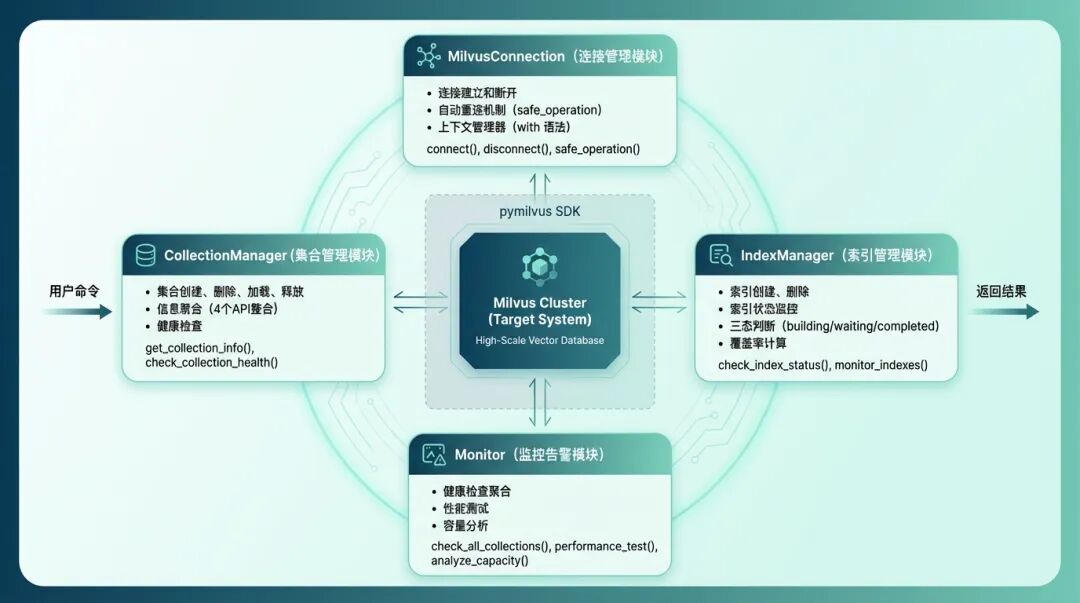
模块架构图
图2:四大核心模块架构
核心实现思路
连接管理:safe_operation 的设计
这是整个 Skill 的基石。pymilvus 的连接断开后无法使用,必须重新连接。我在 MilvusConnection 类里设计了 safe_operation 方法:
def safe_operation(self, operation, *args, **kwargs):
"""安全执行操作,支持自动重连"""
try:
self._ensure_connected()
return operation(*args, **kwargs)
except Exception as e:
if "Connection" in str(e):
self.disconnect()
self._ensure_connected()
return operation(*args, **kwargs)
raise
这个设计有几个好处:
自动重连:检测到连接错误自动重连,不需要在业务代码里处理
透明封装:业务代码不需要知道底层连接状态,调用 safe_operation 就行了
上下文管理器:支持 with 语法,自动处理连接的打开和关闭
with MilvusConnection("http://localhost:19530") as conn:
# 连接自动管理,不用担心资源泄漏
collections = conn.safe_operation(client.list_collections)
说实话,这个设计我改了好几版。最开始是想在每个方法里都检查连接,但这样代码太重复了。后来用装饰器,但装饰器的上下文传递太麻烦。最后用 safe_operation 这种显式的包装方式,既清晰又灵活。
集合管理:信息聚合设计
CollectionManager 类的核心思路是:把多个 API 的信息聚合到一起,提供一个完整的视图。
以 get_collection_info 为例,它聚合了 4 个 API 的信息:
def get_collection_info(self, collection_name):
"""获取集合详细信息(聚合多个 API)"""
info = self.client.describe_collection(collection_name)
stats = self.client.get_collection_stats(collection_name)
load_state = self.client.get_load_state(collection_name)
partitions = self.client.list_partitions(collection_name)
# 整合信息返回
return {
"name": info.get("name"),
"description": info.get("description", ""),
"fields": info.get("fields", []),
"row_count": stats.get("row_count", 0),
"load_state": load_state.get("state", "Unknown"),
"partition_count": len(partitions),
}
这样调用方就不用关心底层调用了几个 API,拿到的就是一个完整的信息对象。
另一个实用的设计是 check_collection_health,它会检查数据量、加载状态、索引状态,返回一个健康等级(healthy/warning/error):
def check_collection_health(self, collection_name):
"""检查集合健康状态"""
info = self.get_collection_info(collection_name)
issues = []
if info.get("row_count", 0) == 0:
issues.append("集合为空")
if info.get("load_state") != "Loaded":
issues.append(f"集合未加载: {info.get('load_state')}")
indexes = self.client.list_indexes(collection_name)
for index_name in indexes:
index_info = self.client.describe_index(collection_name, index_name)
if index_info.get("state") != 3:
issues.append(f"索引 {index_name} 状态异常")
return {
"collection": collection_name,
"status": "healthy"ifnot issues else"warning",
"issues": issues,
"info": info,
}
这个设计在批量检查时特别有用,一眼就能看出哪些集合有问题。
索引管理:三态判断设计
索引的状态判断是个坑。Milvus 返回的 state 字段有三种值,但这个字段并不能真实反映索引是否可用。
我设计了 check_index_status 方法,用三个维度来判断:
def check_index_status(self, index_info):
"""检查索引状态(三态判断)"""
state = index_info.get("state")
total_rows = index_info.get("total_rows", 0)
indexed_rows = index_info.get("indexed_rows", 0)
if state != 3:
return"building"
if total_rows == 0:
return"waiting"
coverage = indexed_rows / total_rows
if coverage < 1.0:
return"building"
return"completed"
building:正在构建或者部分构建
waiting:还没开始构建(indexed_rows 为 0)
completed:完全构建完成(indexed_rows >= total_rows)
这个判断逻辑在实际监控中非常实用。比如 monitor_indexes 方法会遍历所有索引,用这个三态判断返回每个索引的覆盖率:
def monitor_indexes(self, collection_name):
"""监控索引状态(含覆盖率计算)"""
indexes = self.list_indexes(collection_name)
report = []
for index_name in indexes:
index_info = self.get_index_info(collection_name, index_name)
coverage = 0
total_rows = index_info.get("total_rows", 0)
indexed_rows = index_info.get("indexed_rows", 0)
if total_rows > 0:
coverage = (indexed_rows / total_rows) * 100
report.append({
"index_name": index_name,
"index_type": index_info.get("index_type"),
"metric_type": index_info.get("metric_type"),
"state": index_info.get("state"),
"status": self.check_index_status(index_info),
"total_rows": total_rows,
"indexed_rows": indexed_rows,
"coverage": round(coverage, 2),
})
return report
覆盖率计算也很关键,它能告诉你索引覆盖了多少数据。如果覆盖率低于某个阈值,就说明有大量数据还没建好索引,查询性能会受影响。
监控告警:聚合设计
Monitor 类的核心是 check_all_collections,它会检查所有集合的健康状态,然后汇总统计:
def check_all_collections(self):
"""检查所有集合健康(聚合所有集合的状态)"""
collections = self.collection_manager.list_collections()
report = {
"timestamp": datetime.now().isoformat(),
"total_collections": len(collections),
"healthy": 0,
"warning": 0,
"error": 0,
"details": []
}
for collection in collections:
health = self.collection_manager.check_collection_health(collection)
report["details"].append(health)
if health.get("status") == "healthy":
report["healthy"] += 1
elif health.get("status") == "warning":
report["warning"] += 1
else:
report["error"] += 1
return report
返回的结果是一个字典,按健康状态分类。这样调用方就能快速定位问题集合。
另一个实用功能是 performance_test,它会执行指定次数的查询,统计平均、最小、最大延迟:
def performance_test(self, collection_name, test_count=10):
"""性能测试(执行 N 次查询,统计延迟)"""
try:
results = self.client.query(
collection_name=collection_name,
filter="",
limit=1,
output_fields=["vector"],
)
ifnot results or"vector"notin results[0]:
return {"status": "failed", "error": "无法获取测试数据"}
test_vector = results[0]["vector"]
query_times = []
for i in range(test_count):
start_time = time.time()
self.client.search(
collection_name=collection_name, data=[test_vector], limit=10
)
query_time = (time.time() - start_time) * 1000
query_times.append(query_time)
avg_time = sum(query_times) / len(query_times)
min_time = min(query_times)
max_time = max(query_times)
return {
"status": "success",
"avg_query_time_ms": round(avg_time, 2),
"min_query_time_ms": round(min_time, 2),
"max_query_time_ms": round(max_time, 2),
"test_count": test_count,
}
except Exception as e:
return {"status": "failed", "error": str(e)}
这个功能在做性能优化时特别有用,能快速看出调优前后的差异。
还有一个容量分析功能 analyze_capacity,它会估算向量数据、标量数据和总存储大小,帮助做容量规划。
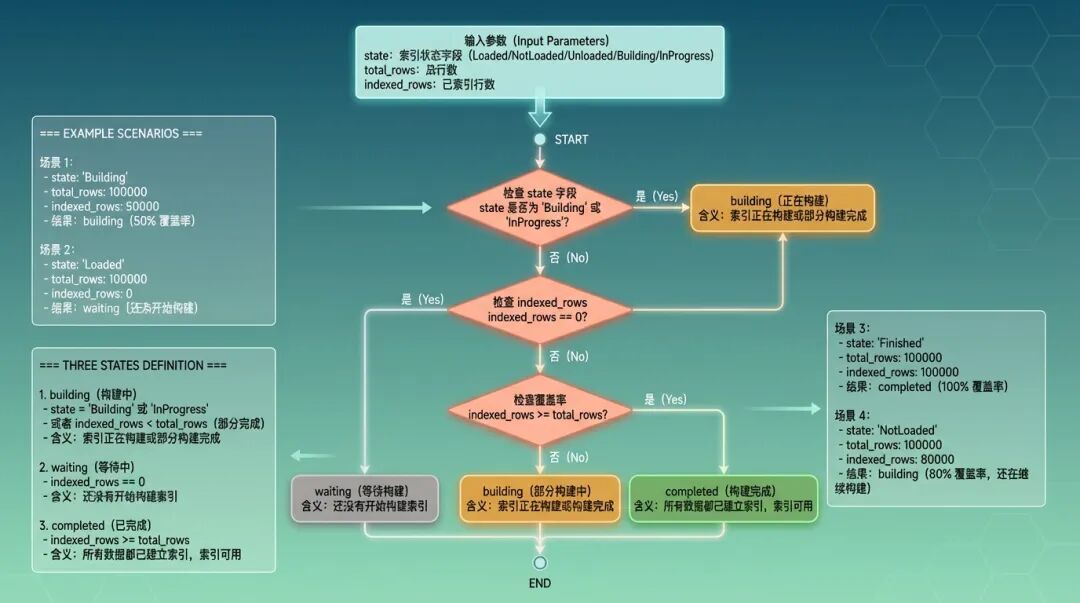
状态判断图
图3:三态索引判断决策逻辑
设计亮点与踩坑
亮点一:上下文管理器的妙用
我给 MilvusConnection 实现了 __enter__ 和 __exit__ 方法,支持 with 语法:
with MilvusConnection("http://localhost:19530") as conn:
manager = CollectionManager(conn)
manager.list_collections()
# 退出时自动断开连接,不用担心资源泄漏
这个设计在做临时查询时特别方便,不需要手动调用 connect 和 disconnect。
亮点二:异常处理与容错
所有的核心方法都加了异常处理,不会因为单个操作失败就崩溃。比如 safe_operation 会捕获异常并尝试重连,check_collection_health 会捕获单个集合的错误继续检查其他集合。
这种设计在批量操作时特别重要,不会因为一个集合有问题就影响整个流程。
踩坑一:索引状态的迷惑
最开始我只看了 state 字段,以为 "Finished" 就表示索引完成了。但后来发现有些集合的索引状态是 "Finished",但 indexed_rows 只有 1000,而 total_rows 有 100000,说明大部分数据还没建好索引。
这就是为什么我要设计三态判断,结合多个字段来判断真实的索引状态。别问我怎么知道的,踩坑踩出来的。
踩坑二:连接断开的隐蔽性
pymilvus 的连接断开后,不会立即报错,而是在调用时抛出异常。这导致很多时候你以为连接是好的,但实际已经断开了。
我在 safe_operation 里加了 _ensure_connected 检查,在每次操作前确认连接状态,避免这种隐蔽的错误。
踩坑三:性能测试的陷阱
最开始做性能测试时,我直接在同一个集合上执行 10 次查询,发现结果特别稳定。但后来发现这是缓存的影响,第二次查询会命中缓存,延迟明显降低。
后来我改成每次查询用不同的向量,或者加上 random_seed 参数,避免缓存干扰。这个细节不注意,性能测试的结果会误导你。
总结与方法论
做这个 Skill 的过程,我有几个感悟:
1. 先解决痛点,再考虑完美
最开始我想做一个全能的运维平台,但后来发现开发周期太长。不如先解决最痛的问题:连接管理和信息聚合。先上线,再迭代。
2. 聚合比分散更重要
Milvus 的 API 很强大,但信息太分散。把多个 API 的信息聚合到一起,提供一个统一的视图,比单纯封装单个 API 更有价值。
3. 容错是刚需
生产环境的各种意外情况太多了,网络波动、节点故障、资源不足……如果不做好容错,脚本很容易就崩溃。宁可多写点异常处理代码,也不要在生产环境裸奔。
4. 测试是最好的文档
写测试用例的过程中,你会发现很多设计上的问题。而且测试用例本身就是最好的使用文档,比 README 清楚多了。
5. 不要过度设计
最开始我想用装饰器、工厂模式一堆设计模式,后来发现代码越写越复杂,维护成本太高。简单的设计往往更实用。
说到底,一个好的工具应该是简单、可靠、够用。Milvus 运维管理 Skill 还在不断迭代,如果你也有类似的运维需求,不妨试试这个 Skill,或者基于它扩展自己的功能。
好啦,谢谢你观看我的文章,如果喜欢可以点赞转发给需要的朋友,我们下一期再见!敬请期待!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号