CVPR 2026 | SounDiT: 地理语境声景到景观生成

CVPR 2026 | SounDiT: 地理语境声景到景观生成

时空探索之旅
发布于 2026-04-02 12:23:05
发布于 2026-04-02 12:23:05
📚论文题目: SounDiT: Geo-Contextual Soundscape-to-Landscape Generation
🖊作者: Junbo Wang, Haofeng Tan, Bowen Liao, Albert Jiang, Teng Fei, Qixing Huang, Bing Zhou, Zhengzhong Tu, Shan Ye, Yuhao Kang
📄论文链接: https://arxiv.org/abs/2505.12734
🗄️Project:https://gisense.github.io/SounDiT-Page/
🔗代码:https://github.com/GISense/SounDiT
🔥关键词:景观生成,地理人工智能(GeoAI),DiT
未名时空:学术成果 | SounDiT: 地理语境声景到景观生成
点击文末阅读原文跳转本文arXiv链接
内容导读
一阵鸟鸣,会把你的思绪带到哪里?林荫小径,还是城市绿地?当车流声响起,我们脑海里浮现的也不止是一辆车,而是整条喧嚣而繁忙的街道。环境声景蕴含着丰富的地理信息,其表达往往超越了作为声音来源的具体单一对象。正是因为声景与视觉景观之间这种强烈的地理语境关联,地理学、城市规划以及环境心理学等领域的研究者已围绕声景与街景展开了大量探索。那么,AI 能否模拟人类这种“听声想景”的能力,仅凭声景生成与地点语境一致的环境图像?
作为“以人为中心的地理人工智能(Human-centered GeoAI)”的一次实践:从人的感知与体验出发,探索 AI对场所的理解,我们提出了“地理语境声景到景观生成”(Geo-contextual Soundscape-to-Landscape, GeoS2L)问题,并围绕它贡献三件事:(1)作者团队构建了两套大规模多模态地理语境数据集 SoundingSVI 与 SonicUrban(合计约41万对声景–图像配对);(2)研发了面向地理一致性声景到景观生成的生成模型 SounDiT;(3)提出了实用导向的评测框架“场所相似性分数”(Place Similarity Score,PSS)(涵盖要素、场景与感知三层相似度)。大量实验表明,SounDiT 在多项指标上优于基线方法,在地理、环境与城市规划等下游应用中具有显著价值;同时,这两套数据集与 PSS 指标为 GeoS2L 任务提供了稳健的基准体系。本文被计算机视觉与人工智能领域顶级国际会议CVPR 2026主会(IEEE/CVF Conference on Computer Vision and Pattern Recognition)接收。

图1. “地理语境声景到景观生成”(Geo-contextual Soundscape-to-Landscape, GeoS2L)问题
图1. “地理语境声景到景观生成”(Geo-contextual Soundscape-to-Landscape, GeoS2L)问题
数据集构建
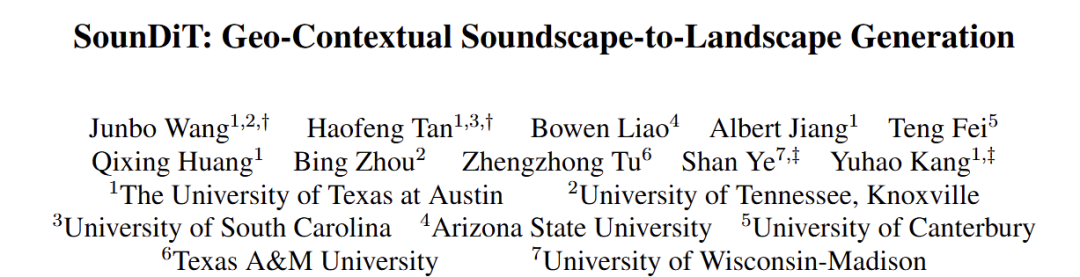
以往音频到图像研究多依赖通用音视数据集,主要用于声源定位与视听对应学习,缺乏GeoS2L所需的地理语境(例如青蛙鸣叫更可能指向湿地而非青蛙本身,鸣笛声更可能指向拥堵的街道而非一辆车)。少数声景–图像配对数据集覆盖与场景多样性有限。为此,本文构建了两套面向 GeoS2L 的大规模多模态数据集:SoundingSVI(来自 Aporee 地理标注录音,匹配附近街景,切分 10 秒片段并过滤人声/对齐时间,用 VLM 生成场景提示;共 169,221 对,覆盖 90 国)与 SonicUrban(基于 YouTube 城市实景视频提取 10 秒音频与代表帧,过滤人声并生成场景提示;共 236,674 对,覆盖 131 城市、97 国)。
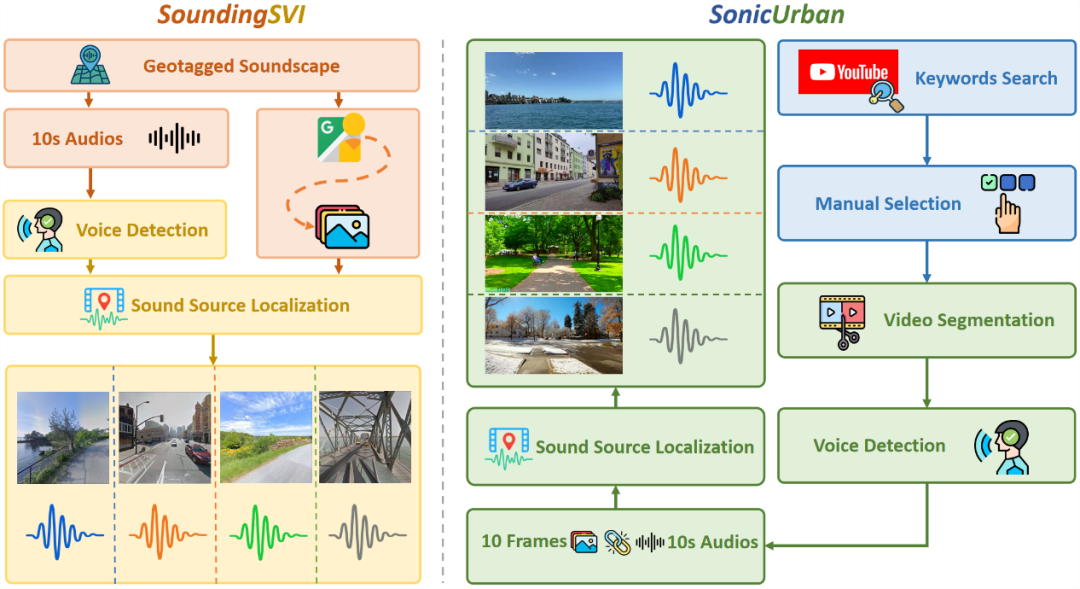
图2. SoundingSVI与SonicUrban数据集构建流程
图2. SoundingSVI与SonicUrban数据集构建流程
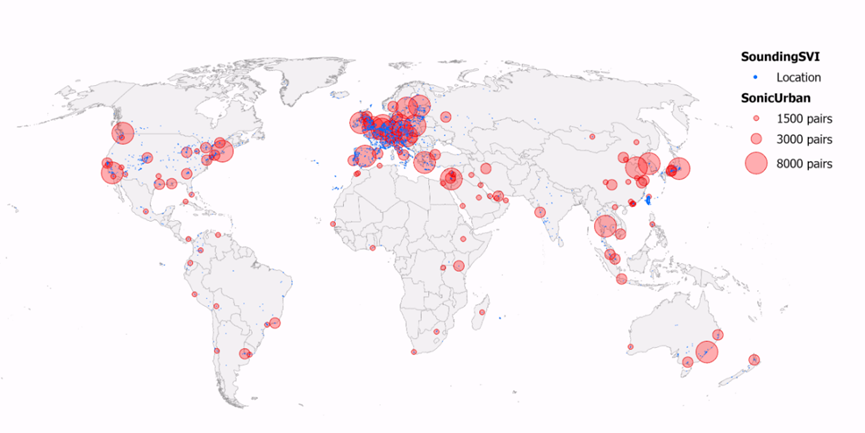
图3. SoundingSVI与SonicUrban数据集覆盖范围
图3. SoundingSVI与SonicUrban数据集覆盖范围
研究方法
GeoS2L(地理语境声景到景观生成)旨在从某地的环境声景生成与该地点语境一致的景观图像。输入包括环境声景,并可选提供一个场景提示词(如街道、公园、海滩等)作为语义地理约束。模型需要生成既视觉逼真、又在地理与语义层面同时符合声景线索和场景语境的图像。场景提示词的引入用于缓解声景本身可能带来的歧义,并提升生成的可控性。
基于潜空间扩散模型,SounDiT 在扩散Transformer (DiT)主干中高效注入声景与场景信息,包含三项核心模块:混合专家声景条件模块(用于将声学特征与视觉生成对齐)、场景低秩混合器(以较低计算成本注入场景语境)、场景自适应归一化(进一步强化场景一致性)。通过分层融合声学、语义与视觉线索,SounDiT 实现可控且地理一致的声景到景观生成。
图4. SounDiT模型架构
图4. SounDiT模型架构
场所相似性分数 PSS
以往音频到图像评测多用 FID、AIS、IIS 等指标,主要衡量画面质量或音视匹配,但无法判断生成图像是否与真实地理环境或目标场景一致。从地理与城市规划实践视角出发,我们提出了基于“声景与景观在同一空间共现,其环境特征应相似”的假设,并设计了实用导向的“场所相似性分数”(Place Similarity Score,PSS),从三层面评估生成结果的地理语境与环境一致性:
1)要素层:比较树木、天空、水体、建筑等地理要素的构成一致性(用语义分割提取要素比例);
2)场景层:判断整体场景类别(如森林、海滩、居住区等)是否一致(用场景分类模型);
3)感知层:评估图像唤起的主观感受是否接近(如安全、活力、美感等,用地点感知模型)。
三者结合,使评测从“好不好看/像不像”扩展到“是否与输入声景所对应的场所环境一致”。
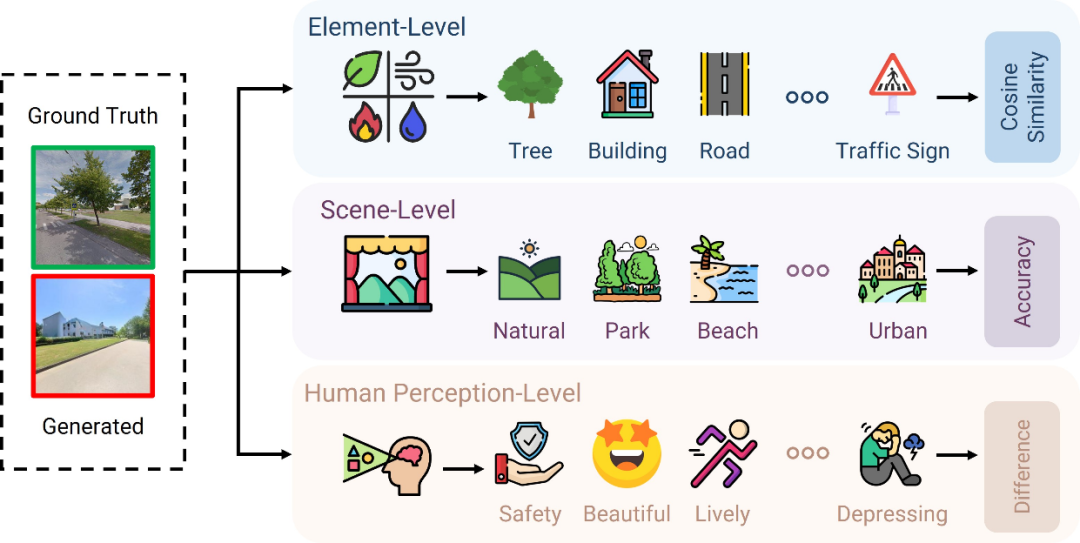
图5. 场所相似性分数(Place Similarity Score,PSS)框架图
图5. 场所相似性分数(Place Similarity Score,PSS)框架图
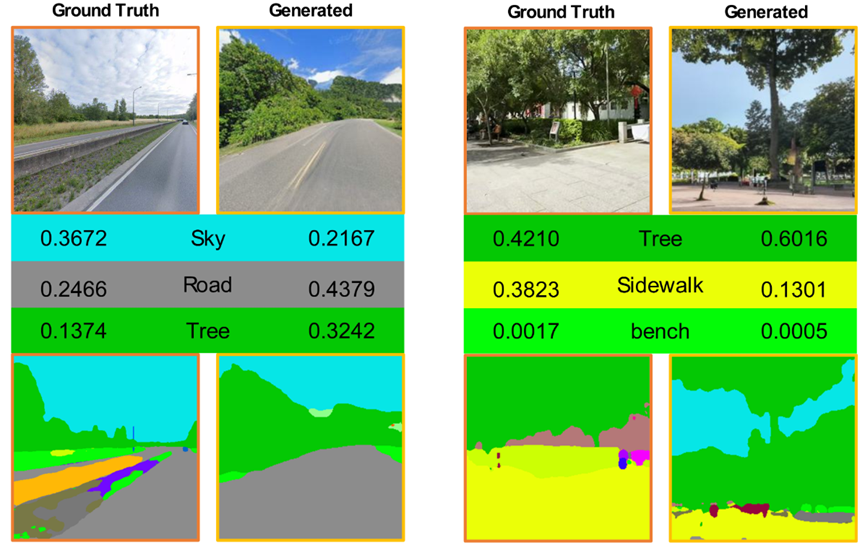
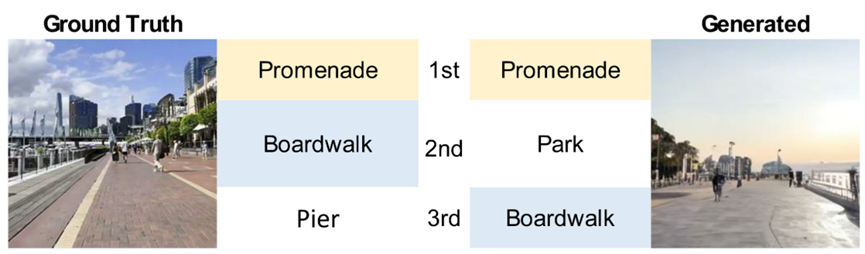
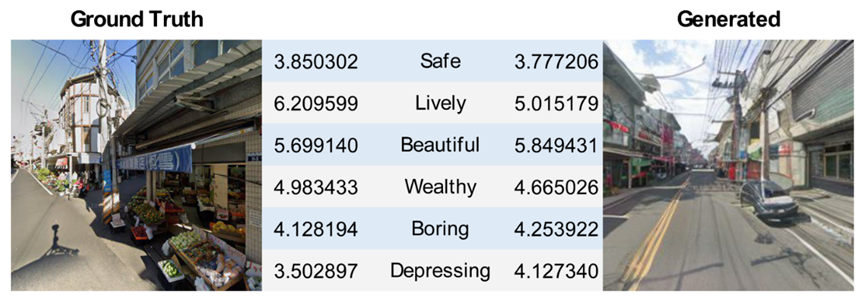
图6. 基于PSS从三个层面评估生成结果的地理语境与环境一致性的案例
图6. 基于PSS从三个层面评估生成结果的地理语境与环境一致性的案例
实验结果
在多样的声学条件与地理环境下,SounDiT 生成的景观更贴近目标场所的整体结构与地理语境,能够更稳定地呈现连贯的场景构图、声景所暗示的区域与场所典型视觉模式,以及一致的“物体—背景”关系。相比之下,基线方法更容易生成孤立前景或泛化纹理,难以完整表达声景对应的场景信息,场景层面的地理一致性较弱。
定量评估进一步验证了这一点:SounDiT 在通用生成质量与跨模态一致性指标上整体最优,同时在场所相似性分数(PSS)上持续领先,说明其优势不仅体现在视觉逼真度,更体现在与输入声景相匹配的地理语境一致性。

图7. SounDiT图片生成结果与基线方法对比
图7. SounDiT图片生成结果与基线方法对比
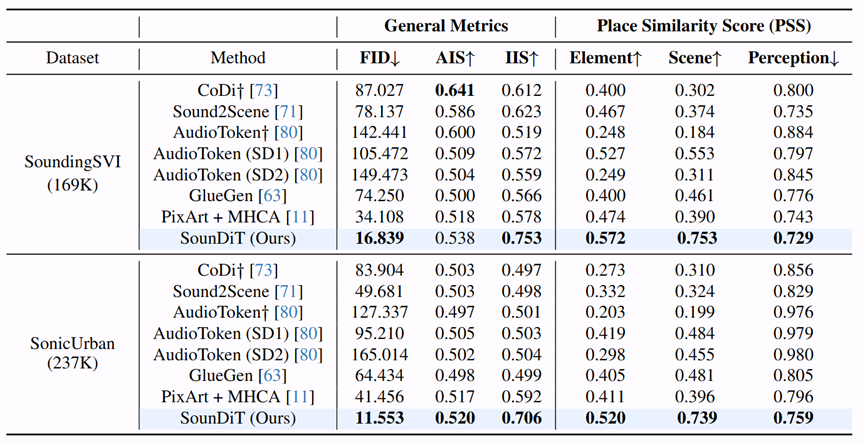
图8. SounDiT图片生成结果与基线方法对比定量评估
图8. SounDiT图片生成结果与基线方法对比定量评估
讨论
研究结果显示,SounDiT 可将地理语境声景到景观生成同时做到可控与可解释,并将听觉线索与场所语境连接起来,支持下游分析与设计。具体而言,它支持场景条件生成:在固定声景输入下,通过调整场景提示词即可生成视觉上不同、但在听觉线索与场景语境上保持一致的图像。
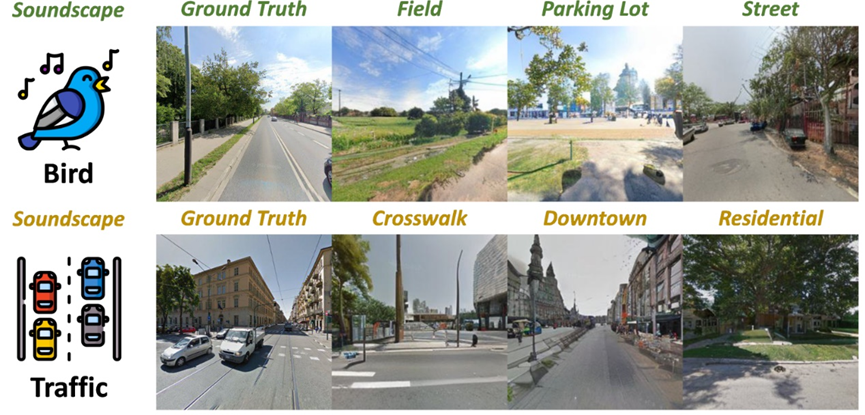
图9. 基于场景提示词的可控SounDiT图片生成结果
图9. 基于场景提示词的可控SounDiT图片生成结果
除可控生成外,SounDiT 还能把录制到的声景转化为其地理环境的可解释视觉呈现,支持推断环境噪声来源,支持城市环境治理方案,成为连接“听到什么”与“能改变什么”的快速诊断与沟通工具。同时,它可将音频转为标准化的视觉场所可视化,便于研究愉悦度、压力或安全感如何由“听到的声音”与“看到的环境”共同作用形成,并生成可解释环境线索替代仅靠分贝或抽象音频特征的表述。进一步地,这种声景可视化方法也可能提升参与式设计的包容性,为听障群体提供更友好的声环境表达方式,促进更广泛的评估与规划参与。
总结
本文将地理环境知识、城市规划实践与生成式 AI 融合,构建了两套大规模多模态数据集 SoundingSVI 与 SonicUrban,提出声景到景观生成模型 SounDiT,以及覆盖元素、场景、感知三层相似度的地理语境评测体系 PSS。它们共同支持了可复现的“地理语境声景到景观生成”(Geo-contextual Soundscape-to-Landscape, GeoS2L)基准,在数据、模型与评测三方面推进该任务。
除技术贡献外,该框架通过可视化“声环境—景观结构”的关联,支撑人地关系、环境心理与城市规划研究:例如在固定场景下改变声景以考察安全感/活力的感知变化,或模拟增设绿化缓冲、交通减速等规划方案,直观展示声环境改变如何重塑体验到的景观。
作者介绍
王俊博,美国田纳西大学诺克斯维尔分校硕士生,GRIND实验室和GISense实验室成员;
共同一作谭浩锋,美国南卡大学博士生,GISense实验室成员;主要指导老师康雨豪教授,美国德克萨斯大学奥斯汀分校GISense实验室主任。
参考文献
Wang, J., Tan, H., Liao, B., Jiang, A., Fei, T., Huang, Q., Zhou, B., Tu, Z., Ye, S. and Kang, Y., 2025. SounDiT: Geo-Contextual Soundscape-to-Landscape Generation. arXiv preprint arXiv:2505.12734.
Zhuang, Y., Kang, Y., Fei, T., Bian, M. and Du, Y., 2024. From hearing to seeing: Linking auditory and visual place perceptions with soundscape-to-image generative artificial intelligence. Computers, Environment and Urban Systems, 110, p.102122.
Zhuang, Y., Gui, Y. and Fei, T., 2025. Soundscape-to-panorama: spatialize auditory perception by linking acoustic environment to panorama. International Journal of Digital Earth, 18(1), p.2545584.
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号