70 行 Markdown 拿下 70K Star,Karpathy 的 AI 编程四原则到底写了什么
原创
70 行 Markdown 拿下 70K Star,Karpathy 的 AI 编程四原则到底写了什么
原创
运维有术
发布于 2026-04-28 00:25:58
发布于 2026-04-28 00:25:58
🚩 2026 年「术哥无界」系列实战文档 X 篇原创计划 第 90 篇,AI 星探「2026」系列第 10 篇
大家好,欢迎来到 术哥无界 | ShugeX | 运维有术。
我是术哥,一名专注于 AI 编程、AI 智能体、Agent Skills、MCP、云原生、AIOps、Milvus 向量数据库的技术实践者与开源布道者!
Talk is cheap, let's explore。无界探索,有术而行。
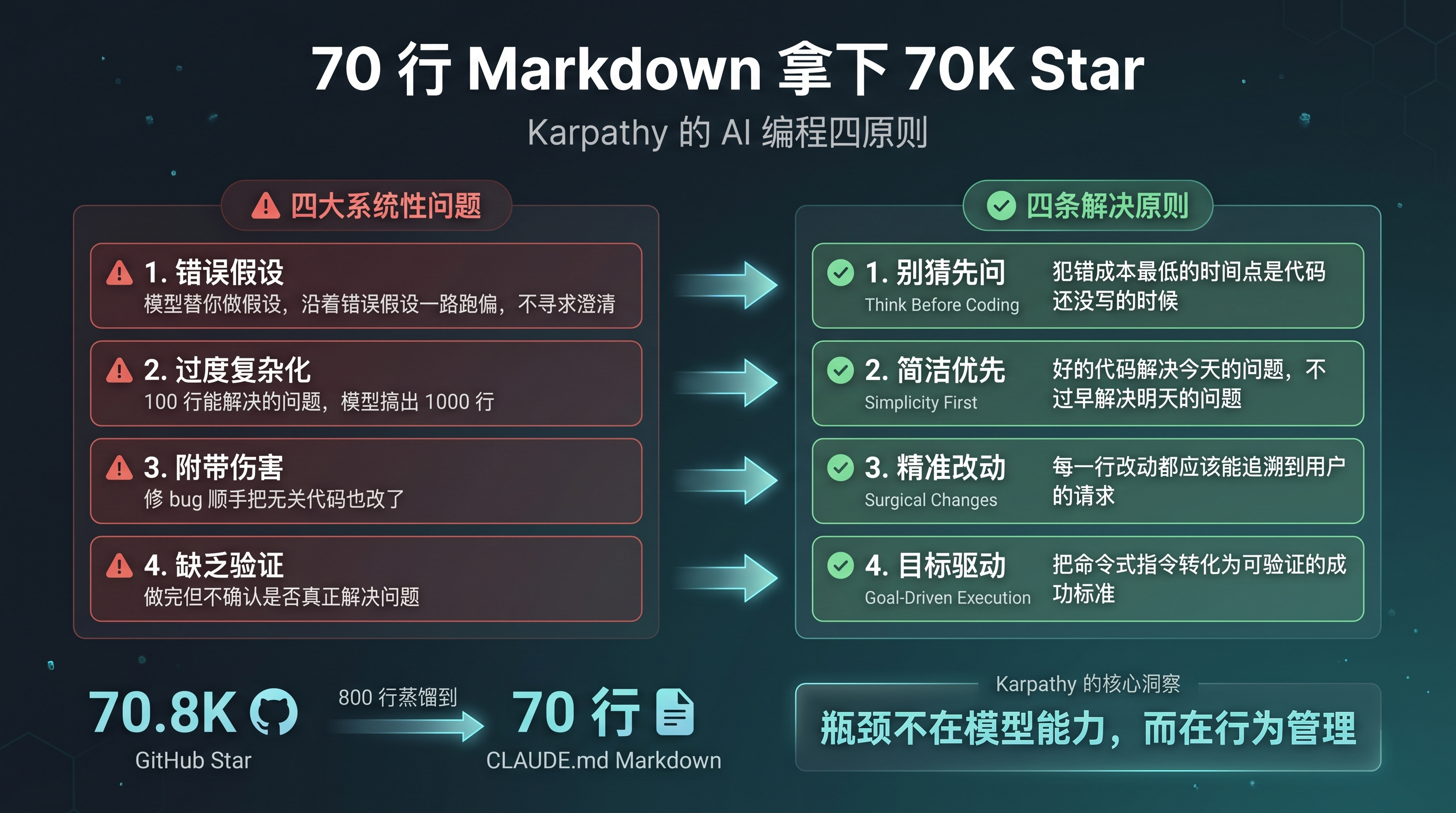
信息图封面 - CLAUDE.md 四原则全景图
2026 年 1 月,Andrej Karpathy 在 X 上发了一篇长文,描述自己编程工作流的剧变:11 月还是 80% 手写 + 20% AI 辅助,到 12 月就翻转为 80% agent 编码 + 20% 人工收尾。
这是我近二十年编程生涯里,对基础工作流影响最大的一次变化,而且它是在短短几周内发生的。
但 Karpathy 没有止步于"AI 编程真好用"。他紧接着指出了 LLM 编程的系统性缺陷:模型替你做假设然后一路跑偏、100 行能搞定的事非要写 1000 行、修 bug 顺手把无关代码也改了。
社区开发者 Forrest Cheung(Jiayuan Zhang)当天就把这些观察转化为一个 CLAUDE.md 文件,约 65 行 Markdown。四个月后,这个仓库单周暴涨 44K Star,总计 70.8K Star,连续三天霸榜 GitHub Trending。
一个 Markdown 文件凭什么?答案是:它精准地约束了 LLM 编程中四个反复出现的行为偏差。
1. 问题的根源:LLM 编程的四大系统性缺陷
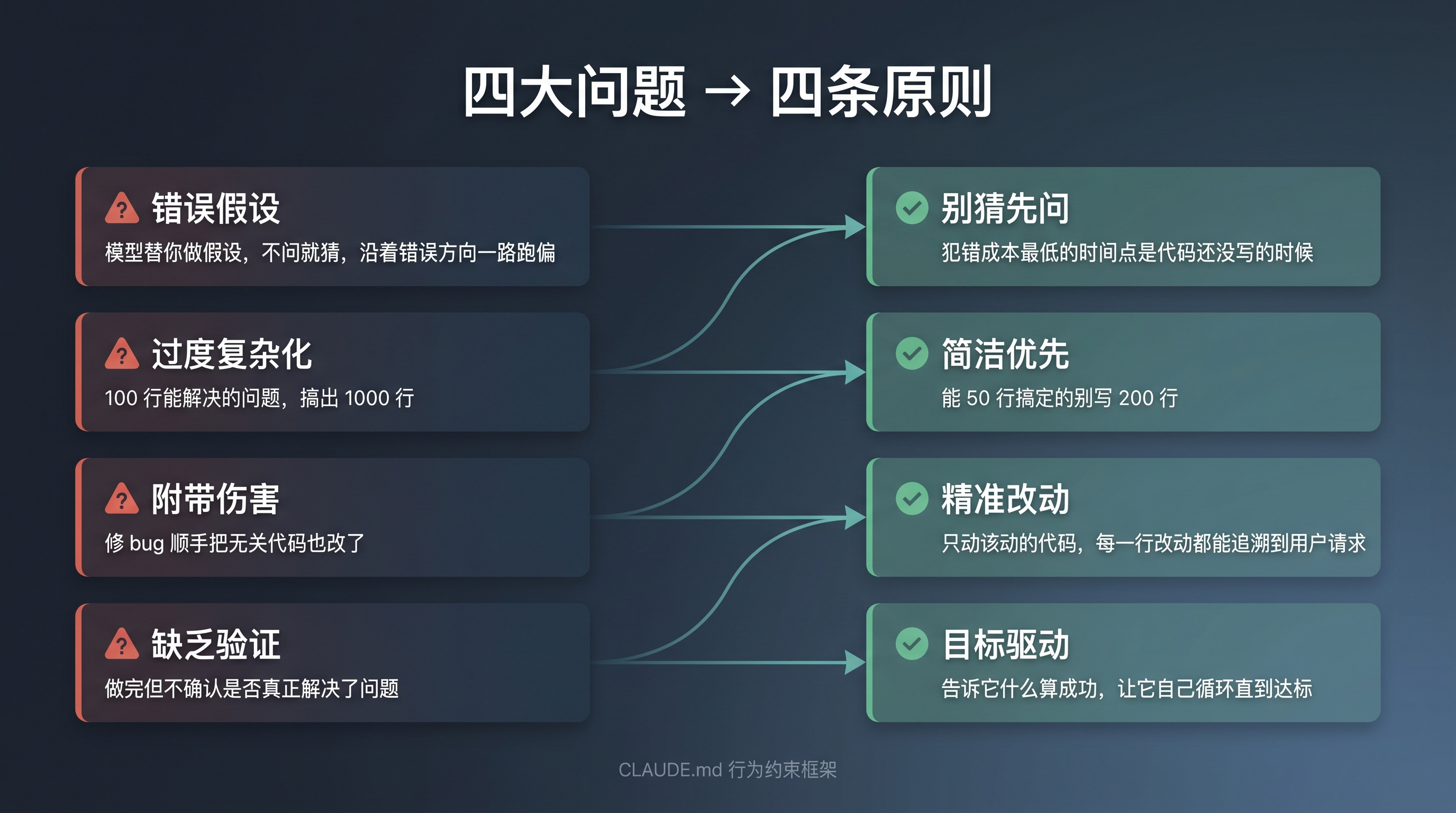
四大问题 → 四条原则:映射关系图
图 1:LLM 编程的四大系统性问题与 CLAUDE.md 四条原则的对应映射
Karpathy 的诊断非常具体,不是泛泛地抱怨"AI 写的代码不好"。他识别出三个可预测的、系统性的问题。
在 CLAUDE.md 仓库的 README 中,Karpathy 的原始推文被直接引用:
The models make wrong assumptions on your behalf and just run along with them without checking. They don't manage their confusion, don't seek clarifications, don't surface inconsistencies, don't present tradeoffs, don't push back when they should.
翻译过来:模型替你做了假设,然后沿着错误假设一路跑下去。不管理自己的困惑,不寻求澄清,不暴露矛盾,不展示权衡,不在该反驳的时候反驳。
They really like to overcomplicate code and APIs, bloat abstractions, don't clean up dead code... implement a bloated construction over 1000 lines when 100 would do.
模型倾向于过度复杂化。100 行能解决的问题,它给你搞出 1000 行,塞满抽象层和扩展点。
They still sometimes change/remove comments and code they don't sufficiently understand as side effects, even if orthogonal to the task.
模型会顺手改掉和任务无关的注释与代码。你以为只修了个 bug,结果 git diff 一看,半文件都是"格式优化"。
KnightLi 博客把这三类问题总结得很到位:错误假设(不问就猜)、过度复杂化(100 行变 1000 行)、附带伤害(顺手改无关代码)。再加上社区普遍反馈的第四类问题——缺乏验证回路(做完但不解决问题),就有了 CLAUDE.md 试图约束的四个行为偏差。
这四个问题不是随机出现的 bug,而是 LLM 训练数据偏差的必然结果。想想看,GitHub 上获得高赞的代码通常是什么样的?是那些展示了完整架构、设计模式、类型系统的代码,而不是一个三行就解决问题的函数。LLM 在这些数据上训练,自然倾向于输出"看起来专业"的复杂代码。
IT Note TK 的评测文章把这一点讲得很透:
CLAUDE.md 本质上是在对抗训练数据的偏差。LLM 的训练数据大量来自 GitHub、Stack Overflow、技术文章,这些内容天生偏向展示"完整解决方案"而不是"最小可行修改"。从这个角度看,CLAUDE.md 不只是 prompt,它是行为配置文件。
说清楚了问题,接下来看 CLAUDE.md 是怎么逐条解决的。
2. Think Before Coding:别猜,先问
CLAUDE.md 第一个原则只有一句话作为标题:
Don't assume. Don't hide confusion. Surface tradeoffs.
具体要求四件事:
State your assumptions explicitly. If uncertain, ask. If multiple interpretations exist, present them - don't pick silently. If a simpler approach exists, say so. Push back when warranted. If something is unclear, stop. Name what's confusing. Ask.
这条原则直指 LLM 编程中代价最高的行为:隐性假设。
EXAMPLES.md 中有一个非常典型的例子。用户说"添加用户数据导出功能",模型直接实现了以下代码:
def export_users(format='json'):
"""Export all users to a file."""
users = User.query.all()
if format == 'json':
with open('users.json', 'w') as f:
json.dump([u.to_dict() for u in users], f)
elif format == 'csv':
with open('users.csv', 'w') as f:
writer = csv.DictWriter(f, fieldnames=['id', 'email', 'name'])
writer.writeheader()
writer.writerows([u.to_dict() for u in users])
return f"Exported {len(users)} users"看起来没毛病?但模型做了至少四个未经确认的假设:导出全部用户(不考虑隐私和分页)、写成本地文件(不是 API 下载)、固定字段(没确认哪些字段敏感)、默认 JSON 和 CSV 两种格式。
正确的做法不是写代码,而是先提问:
Before implementing, I need to clarify:
1. Scope: Export all users or filtered subset? (privacy implications)
2. Format: You mentioned "export" - did you mean:
- Download file in browser?
- Background job with email notification?
- API endpoint returning data?
3. Fields: Which user fields? (some might be sensitive)
4. Volume: How many users typically? (affects approach)社区里有个很扎心的评论,来自用户 Surajdotdot7:
模型选错了分支,运行了 40 分钟,最后碰壁失败。而提前澄清只需要 30 秒。
这条原则的价值在于:把犯错的时间点从"代码写完"提前到"代码还没写"。代价极低,收益极高。
另一个容易忽略的场景是"多种解读"。EXAMPLES.md 的第二个例子中,用户说"让搜索变快",模型直接加了缓存、数据库索引和异步处理。但"快"至少有三种理解:响应时间快(latency)、并发处理量大(throughput)、用户体感快(perceived speed)。三种理解对应三种完全不同的技术方案。Think Before Coding 要求模型把这三种理解都列出来,让人类做选择。
3. Simplicity First:能 50 行搞定的别写 200 行
第二个原则的标题是:
Minimum code that solves the problem. Nothing speculative.
具体约束包括:
No features beyond what was asked. No abstractions for single-use code. No "flexibility" or "configurability" that wasn't requested. No error handling for impossible scenarios. If you write 200 lines and it could be 50, rewrite it.
最后附了一个自检标准:
Ask yourself: "Would a senior engineer say this is overcomplicated?" If yes, simplify.
这条原则对抗的是 LLM 的"过度工程"倾向。EXAMPLES.md 中的折扣计算案例堪称教科书级别的对比。
用户说"添加一个折扣计算功能",模型给出了这个:
from abc import ABC, abstractmethod
from enum import Enum
from typing import Protocol, Union
from dataclasses import dataclass
class DiscountStrategy(ABC):
@abstractmethod
def calculate(self, amount: float) -> float:
pass
class PercentageDiscount(DiscountStrategy):
def __init__(self, percentage: float):
self.percentage = percentage
def calculate(self, amount: float) -> float:
return amount * (self.percentage / 100)
class FixedDiscount(DiscountStrategy):
def __init__(self, fixed_amount: float):
self.fixed_amount = fixed_amount
def calculate(self, amount: float) -> float:
return min(self.fixed_amount, amount)
@dataclass
class DiscountConfig:
strategy: DiscountStrategy
min_purchase: float = 0.0
max_discount: float = float('inf')
class DiscountCalculator:
def __init__(self, config: DiscountConfig):
self.config = config
def apply_discount(self, amount: float) -> float:
if amount < self.config.min_purchase:
return 0
discount = self.config.strategy.calculate(amount)
return min(discount, self.config.max_discount)策略模式、抽象基类、配置类、多级继承,全套"设计模式最佳实践"。问题是:用户只是要一个折扣计算。实际需要的代码是:
def calculate_discount(amount: float, percent: float) -> float:
"""Calculate discount amount. percent should be 0-100."""
return amount * (percent / 100)三行搞定。EXAMPLES.md 对此有一句精准的总结:
Good code is code that solves today's problem simply, not tomorrow's problem prematurely.
社区反馈的数据也印证了这一点。据 IT Note TK 收集的非正式反馈,加了 Simplicity First 规则后,生成的代码行数平均减少 30-40%,功能完全一样。
EXAMPLES.md 特别指出,过度复杂的代码"不是明显错误的"——它符合设计模式教科书,有完整的类型注解,甚至有不错的可扩展性。问题出在时机:它在不该出现复杂度的时候引入了复杂度,让代码更难理解、更容易出 bug、更难测试。
Simplicity First 并不是反对抽象,而是反对投机性的抽象。当需求明确要求多种折扣类型时,策略模式就是正确选择。但在需求只要求计算百分比折扣的当下,一个三行函数就够了。需求变化时再重构,代码库不会因此变得更糟——恰恰相反,从一个简单的起点开始重构,比从一个过度设计的起点开始修改要容易得多。
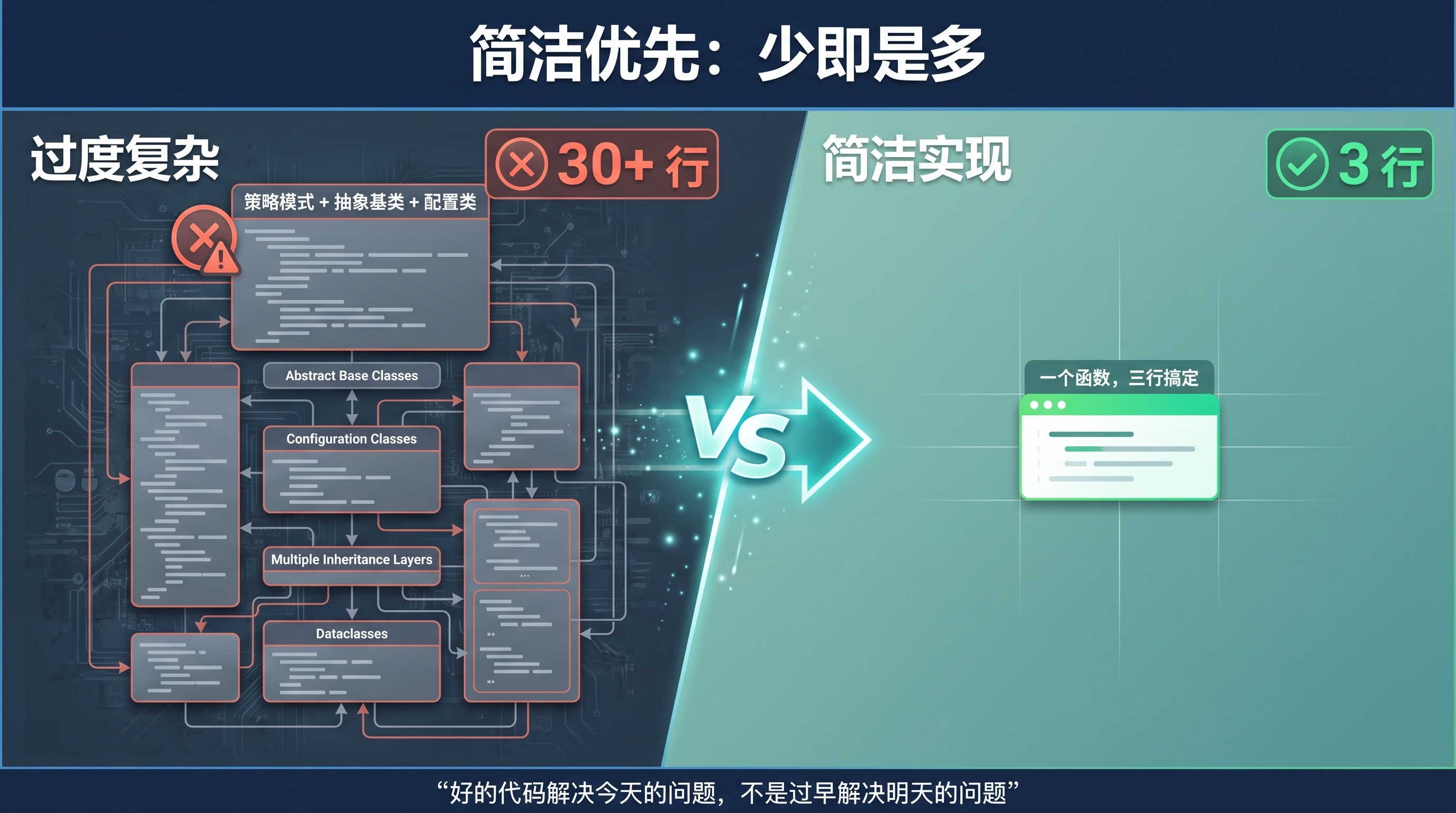
过度复杂 vs 简洁实现:代码量对比
图 2:Simplicity First 原则——30+ 行策略模式 vs 3 行函数,视觉重量一目了然
4. Surgical Changes:只动该动的代码
第三个原则标题是:
Touch only what you must. Clean up only your own mess.
具体约束分两组。编辑现有代码时:
Don't "improve" adjacent code, comments, or formatting. Don't refactor things that aren't broken. Match existing style, even if you'd do it differently. If you notice unrelated dead code, mention it - don't delete it.
你的改动产生了孤立代码时:
Remove imports/variables/functions that YOUR changes made unused. Don't remove pre-existing dead code unless asked.
有一个检验标准:
The test: Every changed line should trace directly to the user's request.
这条原则解决的是 code review 的噩梦。你让 LLM 修个空邮箱的 bug,它把注释改了、加了 docstring、顺手增强了用户名校验、把单引号换成双引号。git diff 看过去一屏幕红红绿绿,review 的人根本分不清哪些是修 bug、哪些是"顺手优化"。
EXAMPLES.md 中有个经典的 diff 对比。用户说"修复空邮箱导致验证器崩溃的 bug",模型给出的 diff 长这样(简化版):
def validate_user(user_data):
- # Check email format
- if not user_data.get('email'):
+ """Validate user data."""
+ email = user_data.get('email', '').strip()
+
+ # Validate email
+ if not email:
raise ValueError("Email required")
-
- # Basic email validation
- if '@' not in user_data['email']:
+ if '@' not in email or '.' not in email.split('@')[1]:
raise ValueError("Invalid email")
- # Check username
- if not user_data.get('username'):
+ # Validate username
+ username = user_data.get('username', '').strip()
+ if not username:
raise ValueError("Username required")
+ if len(username) < 3:
+ raise ValueError("Username too short")
+ if not username.isalnum():
+ raise ValueError("Username must be alphanumeric")看起来在"改进代码",实际上:
- 改了注释措辞(没人要求)
- 增强了邮箱验证规则(超出范围)
- 新增了用户名长度和字符校验(完全无关)
- 加了 docstring(没人要求)
Surgical Changes 原则下,正确的 diff 应该只改和空邮箱 bug 直接相关的行:
def validate_user(user_data):
# Check email format
- if not user_data.get('email'):
+ email = user_data.get('email', '')
+ if not email or not email.strip():
raise ValueError("Email required")
# Basic email validation
- if '@' not in user_data['email']:
+ if '@' not in email:
raise ValueError("Invalid email")
# Check username
if not user_data.get('username'):
raise ValueError("Username required")
return True只改了处理空邮箱的两行,其他代码纹丝不动。这才是 code review 友好的 diff。
EXAMPLES.md 里还有一个关于"风格漂移"的例子也很有代表性。用户说"给上传函数加日志",模型在加日志的同时顺手加了 type hints、改了引号风格、加了 docstring、重构了布尔逻辑。每一项单独看都是"改进",但合在一起,真正和用户请求相关的改动被淹没了。Surgical Changes 的要求很明确:匹配已有风格,只改必须改的行。如果已有代码用单引号,你也用单引号。如果已有代码没有 type hints,你也别加。

精准改动 vs 顺手改一堆:diff 热力对比
图 3:Surgical Changes 原则——改动散布全文件 vs 只改与 bug 直接相关的行
5. Goal-Driven Execution:别告诉它怎么做,告诉它什么算成功
第四条原则被 Karpathy 本人认为是杠杆最大的一条。标题是:
Define success criteria. Loop until verified.
CLAUDE.md 给出了具体的转化规则:
"Add validation" → "Write tests for invalid inputs, then make them pass" "Fix the bug" → "Write a test that reproduces it, then make it pass" "Refactor X" → "Ensure tests pass before and after"
对于多步骤任务,要求给出一个带验证的计划:
1. [Step] → verify: [check]
2. [Step] → verify: [check]
3. [Step] → verify: [check]最后一句点明了核心:
Strong success criteria let you loop independently. Weak criteria ("make it work") require constant clarification.
Karpathy 在原帖中把这条原则的底层逻辑讲透了:
LLMs are exceptionally good at looping until they meet specific goals... Don't tell it what to do, give it success criteria and watch it go.
把你的指令从 imperative(命令式)转成 declarative(声明式),会让 agent 循环更久,从而获得更大的杠杆。
这是一个反直觉的洞察。多数人使用 AI 编程工具的方式是命令式:"在这个文件里加一段验证逻辑"、"把这个函数改成异步的"、"加个缓存层"。但 LLM 的优势不在于执行单步指令,而在于循环迭代直到满足条件。
EXAMPLES.md 中的"修复认证系统"案例对比了两种方式。
模糊的方式:
I'll fix the authentication system by:
1. Reviewing the code
2. Identifying issues
3. Making improvements
4. Testing the changes然后直接开始改代码,没有成功标准,改完也不知道算不算"修好了"。
Goal-Driven 的方式:
If the issue is "users stay logged in after password change":
Plan:
1. Write test: Change password → verify old session invalidated
Verify: Test fails (reproduces bug)
2. Implement: Invalidate sessions on password change
Verify: Test passes
3. Check edge cases: Multiple active sessions, concurrent changes
Verify: Additional tests pass
4. Verify no regression: Existing auth tests still pass
Verify: Full test suite green每一步都有可验证的完成标准。LLM 可以独立循环:测试没通过就继续改,通过了就进入下一步。不需要人类在每一步后面盯着说"这个不对,再试试"。
这条原则本质上改变了人机协作的分工方式。人类负责定义"什么算成功",LLM 负责循环试错直到成功。人类从"逐步指挥"的监工变成了"设定目标"的架构师。
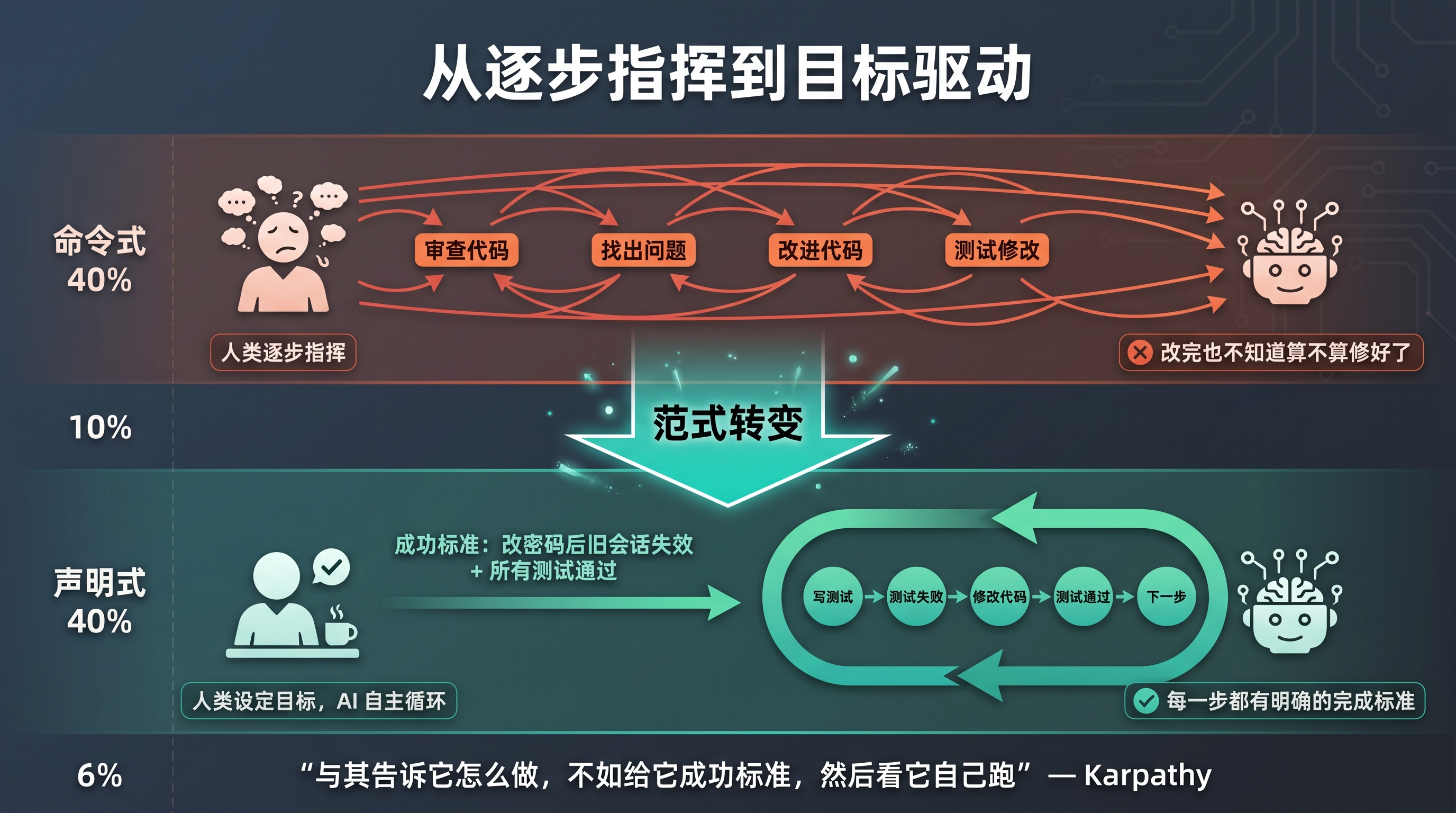
命令式 vs 声明式:AI 编程的范式转变
图 4:从"人类逐步指挥"到"人类设定目标,AI 自主循环"的范式转变
EXAMPLES.md 中还有一个"先复现再修复"的案例,也体现了 Goal-Driven 的思维。用户说"重复分数排序会出 bug",模型直接改排序逻辑。但 Goal-Driven 的方式是:先写一个测试复现 bug,确认测试失败,然后再改代码让测试通过。这样做的好处是:你确确实实知道 bug 被修好了,而不是"应该修好了"。
Karpathy 对 LLM 这种循环能力的描述很有画面感:
看一个 agent 不知疲倦地死磕某件事真的很有意思。它们不会累,不会灰心,就是持续尝试——很多时候如果换成人,早就放弃、改天再战了。
6. 为什么是 70 行 Markdown,而不是 800 行配置
项目作者 Jiayuan Zhang 在 36 氪的采访中透露了一个有意思的细节:初版 CLAUDE.md 大约 800 行,是用 Claude Code 把 Karpathy 的帖子自动转化成 skills 文件的。然后让 Claude 自己审查自己,最后砍到约 70 行。
从 800 行到 70 行,这个过程本身就是 Simplicity First 原则的完美实践。800 行的 skills 文件把 Karpathy 的每一句话都展开成详细指令,看起来很全面,实际上信息密度很低。70 行只保留了四条核心原则和具体的约束清单,每一行都有明确的指向性。
这种"蒸馏"的过程,和 Karpathy 本人提倡的编程哲学完全一致。他在长文中提到:
LLM 辅助带来的"加速"其实不太好衡量。我当然感觉自己做原本要做的事更快了,但更大的变化是:我做了更多,原因主要是两点:1)我可以写很多以前根本不值得写的东西;2)我可以去碰以前因为知识/技能门槛而不敢碰的代码。所以这当然是 speedup,但可能更像是一种"扩张"。
70.8K Star 的背后,是开发者社区对一种共识的投票:当前 AI 编程的瓶颈不在模型能力,而在行为管理。
GitHub Trending 下面有条来自 Kraggich 的高赞评论,说得很直白:
一个 Markdown 文件冲上趋势榜第一,说明现在的瓶颈不在模型,而在模型周围的脚手架。这些"胶水"才是产品本身。
ABMedia 的分析也指向同一个结论:
当 92% 的美国开发者已在使用 AI 编程工具时,决定代码品质的不再只是模型能力,而是你怎么管理这个 AI 伙伴的行为。一份好的 CLAUDE.md 可能比选择更强的模型更有效。
从 Vibe Coding 到 Agentic Engineering,Karpathy 自己的认知也在进化。2025 年 2 月他提出 Vibe Coding 的概念——完全放手让 LLM 写代码,不关心代码细节。到 2026 年 1 月,他补充说:对于真正在乎的代码,需要更多的结构和纪律,而不是完全放手。
CLAUDE.md 正好处于这个认知升级的交汇点上。它不限制模型的能力上限,只约束模型的行为边界。70 行 Markdown 做的事情很简单:告诉 LLM 什么不该做。而一旦把"不该做的事"排除掉,剩下的"该做的事",LLM 可以做得很好。
Karpathy 在长文中描述过这种体验:
看它为一个问题挣扎很久,30 分钟后又突然赢了。你会意识到:耐力本身就是工作的核心瓶颈之一,而 LLM 把这条上限显著抬高了。
但前提是:它挣扎的方向得是对的。CLAUDE.md 就是那个校准方向的文件。
CLAUDE.md 末尾有一段很务实的自我检验标准:
These guidelines are working if: fewer unnecessary changes in diffs, fewer rewrites due to overcomplication, and clarifying questions come before implementation rather than after mistakes.
三个可观测的指标:diff 里的无关改动少了,过度复杂化导致的返工少了,澄清问题出现在写代码之前而不是犯错之后。
7. 抄作业指南:把四原则装进你的项目
这套规范不局限于 Claude Code。已经有人把它适配到 OpenAI Codex CLI,Cursor 也有专门的适配方案。
方式一:Claude Code Plugin(推荐)
在 Claude Code 中执行两条命令即可:
# 添加 marketplace
/plugin marketplace add forrestchang/andrej-karpathy-skills
# 安装插件
/plugin install andrej-karpathy-skills@karpathy-skills装完之后,所有项目自动生效,不需要每次手动配置。
方式二:项目级 CLAUDE.md
适合已有项目或不想装插件的场景:
# 新项目:直接下载
curl -o CLAUDE.md https://raw.githubusercontent.com/forrestchang/andrej-karpathy-skills/main/CLAUDE.md
# 已有项目:追加到现有 CLAUDE.md
echo "" >> CLAUDE.md
curl https://raw.githubusercontent.com/forrestchang/andrej-karpathy-skills/main/CLAUDE.md >> CLAUDE.md方式三:Cursor 适配
仓库自带 .cursor/rules/karpathy-guidelines.mdc 文件(设置了 alwaysApply: true)。把仓库 clone 下来用 Cursor 打开,规则自动生效。
如果要在其他 Cursor 项目中使用,把 karpathy-guidelines.mdc 复制到目标项目的 .cursor/rules/ 目录下就行。
定制化建议
CLAUDE.md 的设计是可合并的。作者在 README 中建议把它和项目专属规则叠加使用:
## Project-Specific Guidelines
- Use TypeScript strict mode
- All API endpoints must have tests
- Follow the existing error handling patterns in src/utils/errors.ts先装默认的四条原则,跑几天看看效果。如果觉得某条过于严格(比如 Surgical Changes 对快速原型开发来说可能太保守),可以根据团队情况调整。但建议先完整试过再修改,而不是一上来就删减——很多人最初觉得"问太多问题"的 Think Before Coding 原则会拖慢速度,用了之后才发现,省下来的返工时间远超提问的时间。
这套原则的普适性也在被验证。已经出现了 OpenAI Codex CLI 的适配版(nguyenphutrong/andrej-karpathy-skills-codex),社区也在讨论如何把这些理念应用到 GitHub Copilot 和 Windsurf 等工具。约束 LLM 行为的需求是跨工具的,CLAUDE.md 只是第一个把这种需求具象化的项目。
有个需要注意的 tradeoff。README 里写得很清楚:
These guidelines bias toward caution over speed. For trivial tasks, use judgment.
四条原则偏向谨慎而非速度。改个 typo、加个一行注释这种事情,不需要走完整的 Think Before Coding 流程。判断哪些任务需要完整约束、哪些可以放松,这本身就是 agentic engineering 的一部分。
总结
CLAUDE.md 的四条原则,本质上是在回答一个问题:怎样把一个能力很强但行为不受控的编程助手,变成一个行为可预测的协作伙伴?
- Think Before Coding:犯错成本最低的时间点是代码还没写的时候
- Simplicity First:好的代码解决今天的问题,不是过早解决明天的问题
- Surgical Changes:每一行改动都应该能追溯到用户的请求
- Goal-Driven Execution:把命令式指令转化为可验证的成功标准
Karpathy 最重要的一个洞察值得反复琢磨:
与其告诉它怎么做,不如给它成功标准,然后看它自己跑。
一个 70 行的 Markdown 文件能拿下 70K Star,不是因为它做了什么惊天动地的事,而是因为它精准地界定了 LLM 不该做什么。排除掉不该做的事之后,LLM 的长处才能充分发挥。
说实话,如果你现在正在用 Claude Code 或 Cursor 但还没配置任何行为约束,建议先把这个文件装上试试。不需要认同每一条,用几天再调整。社群反馈的规律是:用过的人回去的很少。
你怎么看这种"用 Markdown 文件管理 AI 行为"的方式?你在项目里试过类似的配置吗?欢迎在评论区聊聊。
相关资源
GitHub 仓库:https://github.com/forrestchang/andrej-karpathy-skills
CLAUDE.md 原始文件:https://github.com/forrestchang/andrej-karpathy-skills/blob/main/CLAUDE.md
Karpathy 原始推文:https://x.com/karpathy/status/2015883857489522876
Codex CLI 适配版:https://github.com/nguyenphutrong/andrej-karpathy-skills-codex
好啦,谢谢你观看我的文章,如果喜欢可以点赞转发给需要的朋友,我们下一期再见!敬请期待!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号