Milvus CDC 最佳实践:5 层容错与同步链路,构建 CDC 高可靠性的五重防护机制
原创
Milvus CDC 最佳实践:5 层容错与同步链路,构建 CDC 高可靠性的五重防护机制
原创
运维有术
发布于 2026-05-02 10:18:08
发布于 2026-05-02 10:18:08
🚩 2026 年「术哥无界」系列实战文档 X 篇原创计划 第 99 篇,Milvus 最佳实战「2026」系列第 8 篇
大家好,欢迎来到 术哥无界 | ShugeX | 运维有术。
我是术哥,一名专注于 AI 编程、AI 智能体、Agent Skills、MCP、云原生、AIOps、Milvus 向量数据库的技术实践者与开源布道者!
Talk is cheap, let's explore。无界探索,有术而行。

封面图 - Milvus CDC 数据同步架构概念图
你在生产环境跑 Milvus 的时候,有没有想过一个问题:如果主集群挂了怎么办?
向量数据库里存的数据往往不是简单的 KV,而是经过模型计算后的高维向量,加上 Collection 的 schema、索引配置、分区信息……这些东西要是一下子没了,重建的成本不低。
Milvus CDC 就是来解决这个问题的。它能把上游 Milvus 集群的变更实时捕获并同步到下游,实现主备容灾。听起来不复杂,但翻完源码之后,我发现里面的设计比想象中要精巧不少——尤其是在容错和消息一致性方面。
今天这篇文章,我会基于源码把 Milvus CDC 的架构、核心流程、配置调优和容错机制拆开来看。如果你正在评估或已经用上了 Milvus CDC,这篇应该能帮你少踩一些坑。
说明:本文内容基于 Milvus CDC 源码(zilliztech/milvus-cdc)和 Milvus 官方文档分析整理而成,源码分析基于笔者本地仓库版本,尚未在生产环境中完成全场景验证。文中的配置模板和参数建议仅供参考,实际效果请以你的业务数据和环境测试结果为准。如果有实际使用经验,欢迎在评论区分享交流。
1. 为什么向量数据库需要 CDC
传统数据库的 CDC 方案已经相当成熟,MySQL 有 Canal、Debezium,PostgreSQL 有 pgoutput 逻辑复制。但向量数据库的数据同步有个特殊挑战:同步的不是行数据,而是高维向量加上 schema 元信息。
一个 Milvus Collection 的完整状态包括:Database 定义、Collection schema、Partition 划分、Index 配置、Insert/Delete 数据、Load/Release 状态。这些变更分散在 etcd(元数据)和消息队列(数据流)两个存储里,要保证一致性地把它们搬到另一个集群,需要一套专门的机制。
Milvus CDC 的做法是:从 etcd 读元信息,从消息队列订阅数据变更,然后在目标集群上重放。 这和传统 CDC 的逻辑复制思路一致,但适配了 Milvus 的存储架构。
2. 架构解析:两大核心组件
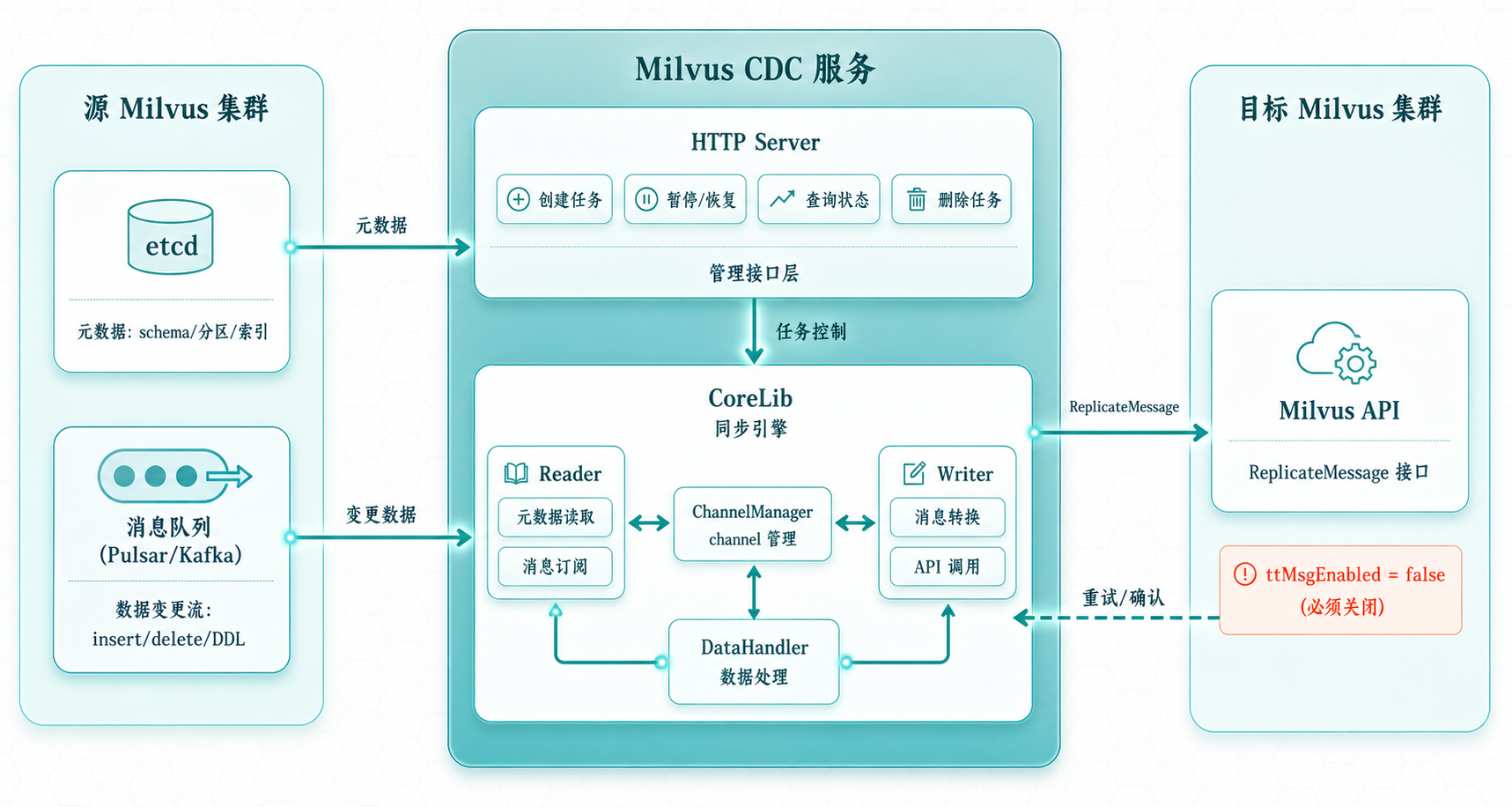
Milvus CDC 整体架构图
源码层面,CDC 的代码结构非常清晰,就两大块(源码位置:README.md):
HTTP Server(server 包)
负责对外暴露管理接口。接受用户的 HTTP 请求,控制任务的创建、暂停、恢复、删除,同时维护元信息。所有的 API 都走统一的请求格式:
{
"request_type": "create",
"request_data": {
"milvus_connect_param": {
"uri": "http://localhost:19530",
"token": "root:Milvus"
},
"collection_infos": [{"name": "*"}]
}
}支持的 request_type 有 6 种:create、delete、pause、resume、get、list。其中 collection_infos 目前必须传 [{"name": "*"}],表示全量同步——这是一个已知的限制,后面会细说。
CoreLib(core 包)
这是 CDC 的引擎。拆成两个角色:
- Reader:从源 Milvus 的 etcd 读元信息,从消息队列(Pulsar 或 Kafka)订阅变更数据
- Writer:把读到的消息转换成 Milvus API 调用,写入目标集群
这两个角色通过 4 组核心接口(源码位置:core/api/)解耦:
接口 | 职责 | 关键方法 |
|---|---|---|
| 读取变更数据 |
|
| 写入目标集群 |
|
| 管理 Channel 读写生命周期 | 协调 Reader 和 Writer 的 Channel 分配 |
| 数据操作处理器 | Milvus 和 Kafka 两种实现 |
这个设计的好处是 Reader 和 Writer 可以独立替换。比如你想把数据写到 Kafka 而不是另一个 Milvus,只需要换一个 DataHandler 实现。
3. 核心流程:从创建任务到数据同步
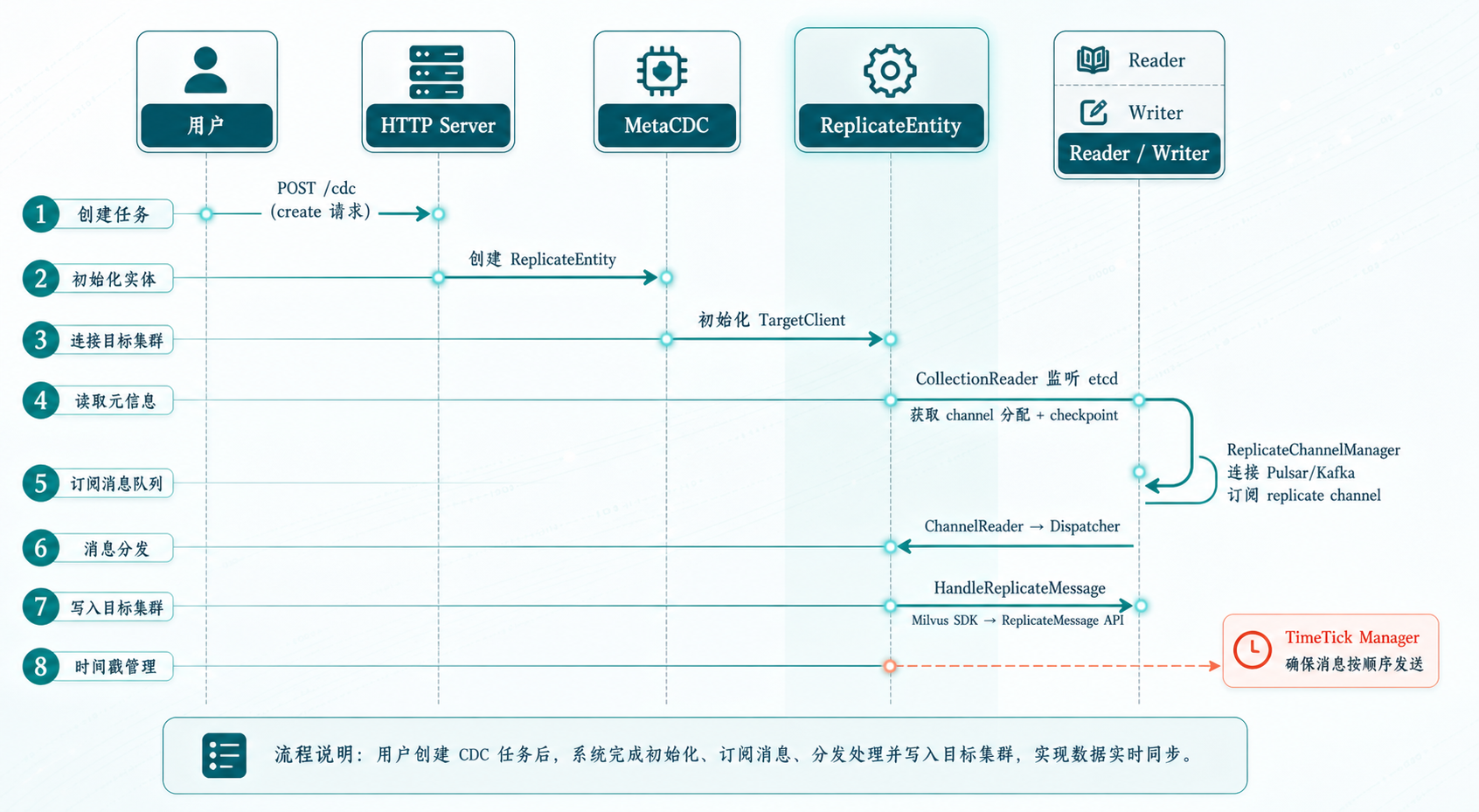
CDC 任务创建到数据同步的时序图
用户调用 create API 后,整个链路是这样的(源码位置:server/cdc_impl.go):
第一步:创建 ReplicateEntity
每个 CDC 任务对应一个 ReplicateEntity,这是源码里最核心的数据结构:
type ReplicateEntity struct {
channelManager api.ChannelManager // Channel 管理器
targetClient api.TargetAPI // 目标集群客户端
metaOp api.MetaOp // 元数据操作
writerObj api.Writer // 消息写入器
mqDispatcher msgdispatcher.Client // 消息分发器
entityQuitFunc func() // 实体退出清理函数
}它会初始化连接目标集群的客户端、Channel 管理器和消息分发器。
第二步:从 etcd 获取元信息
CollectionReader(源码位置:core/reader/collection_reader.go)监听源集群的 Collection 和 Partition 变更事件,获取 channel 分配信息和 checkpoint。
第三步:订阅消息队列
ReplicateChannelManager(源码位置:core/reader/replicate_channel_manager.go)根据元信息中的 channel 分配,连接 Pulsar 或 Kafka,开始订阅 replicate channel 的消息。
第四步:消息分发与写入
ChannelReader 读到消息后,经过 Dispatcher(源码位置:core/msgdispatcher/dispatcher.go)分发到对应的 ChannelWriter。Writer 调用 HandleReplicateMessage,通过 Milvus Go SDK 把消息转发到目标集群。
整个过程中,TimeTick Manager(源码位置:core/reader/ts_manager.go)负责管理消息的时间戳排序,确保消息按正确顺序发送。这一点在分布式同步中非常关键——乱序消息会导致目标集群数据不一致。
4. 配置最佳实践:基于源码的参数调优
Milvus CDC 的配置项不多,但有几个参数直接影响同步性能和稳定性。以下是逐项分析(源码位置:server/config.go、server/configs/cdc.yaml)。
服务端配置
# CDC 服务监听地址,默认 0.0.0.0:8444
address: 0.0.0.0:8444
# 最大并发任务数,默认 100
# 建议:根据源集群 Collection 数量和服务器内存调整
# 每个 ReplicateEntity 会占用一定的内存和 goroutine
maxTaskNum: 100
# 批处理模式,默认 true
# 建议:生产环境务必开启,减少 API 调用次数
batchMode: true
# 日志级别,默认 info
# 建议:排查问题时改为 debug,日常运维用 info
logLevel: infobatchMode 这个参数值得多说一句。开启后,Writer 会将多条消息打包成一个批次发送到目标 Milvus,减少网络开销和 API 调用。在高写入量场景下,这个开关对吞吐量的影响很大。
元数据存储配置
CDC 支持两种元数据存储:etcd 和 MySQL。
metaStoreConfig:
storeType: mysql # 或 etcd
mysqlSourceUrl: "root:root@tcp(127.0.0.1:3306)/milvuscdc?charset=utf8"
rootPath: cdc-by-dev # 多实例部署时用作隔离前缀建议:如果 CDC 本身是单实例部署,用 etcd 就够了,少维护一个组件。如果是多实例或者需要更方便地查询任务状态,MySQL 更适合,毕竟可以直接用 SQL 查任务元信息。
源端配置
sourceConfig:
etcd:
address: ["http://127.0.0.1:2379"]
rootPath: by-dev
metaSubPath: meta
# 读缓冲长度,默认 4
# 这个值控制 ChannelReader 内部的消息缓冲队列大小
readChanLen: 4
# 复制通道名,必须和源 Milvus 的配置一致
replicateChan: by-dev-replicate-msgreadChanLen 默认只有 4,这个值偏保守。如果你的写入量比较大,ChannelReader 的缓冲队列可能会成为瓶颈——消息生产速度超过消费速度时,队列满了会导致背压。建议在高吞吐场景下调大到 16 或 32,但要注意内存消耗会相应增加。
重试配置
type RetrySettings struct {
RetryTimes int // 重试次数
InitBackOff int // 初始退避时间(秒)
MaxBackOff int // 最大退避时间(秒)
}这三个参数控制 Writer 写入目标集群失败时的重试行为。建议:InitBackOff 设为 2-5 秒,MaxBackOff 设为 60 秒左右。太短会导致频繁重试加重目标集群负担,太长又会影响同步延迟。
5. 异常处理与容错:5 层防护机制
这一部分是我读完源码后觉得最有价值的内容。Milvus CDC 的容错设计足足有 5 层防护,我逐层拆开来看:
第一层:ErrorProtect - 快速失败保护
源码位置:core/writer/fail_protect.go
这是最让我意外的一层。ErrorProtect 机制的核心逻辑是:限制单位时间内的错误次数,超过阈值就停止处理。
具体策略是 FastFail:每分钟只允许 1 次错误。超过这个频率,直接 fail fast,不再重试。
这个设计乍一看有点反直觉——为什么不无限重试?但仔细想想是对的。在分布式同步场景下,如果目标集群已经出问题了,疯狂重试只会让情况更糟。快速失败、等集群恢复后再继续,反而更安全。
这也是本文的社交货币点:在数据同步中,知道什么时候该放弃,比知道怎么重试更重要。
第二层:WaitObjReady - 对象就绪检查
源码位置:core/writer/channel_writer.go
Writer 在执行任何操作之前,会先检查依赖的对象是否已经就绪:
WaitDatabaseReady:确保目标数据库已创建WaitCollectionReady:确保目标 Collection 已创建WaitPartitionReady:确保目标 Partition 已创建
检查方式是基于时间戳判断对象状态(Created/Dropped/Unknown)。这避免了在 DDL 操作还没完成就去执行 DML 操作的竞态问题。
比如要往一个 Collection 里 Insert 数据,Writer 会先等 Collection 创建完成。如果 Collection 还没创建好就执行 Insert,目标集群会返回错误。
第三层:Barrier - Drop 操作屏障
源码位置:core/data_barrier.go
Barrier 机制确保 Drop 类操作在所有 Channel 上都完成后才继续。为什么需要这个?因为一个 Collection 的数据可能分布在多个 Channel 上,Drop 操作必须等所有 Channel 都处理完毕,否则可能出现:A Channel 已经 Drop 了,B Channel 还在往已删除的 Collection 写数据。
第四层:重试与退避
RetrySettings 提供了指数退避重试能力。结合 ErrorProtect 的快速失败,形成了有限重试 + 快速失败的双重保护。不会无限重试把系统拖垮,也不会一次失败就放弃。
第五层:ReplicateInfo - 循环复制防护
源码位置:core/writer/channel_writer.go HandleReplicateMessage
CDC 在转发消息时会附加 ReplicateInfo 标记,包含 ReplicateID。如果目标集群也配了 CDC 把数据同步回来,接收端看到这个标记就知道这是复制消息,不再转发,从而避免 A → B → A 的循环复制。
你在项目中用过类似的容灾方案吗?欢迎在评论区聊聊你的实践经验。
6. 性能优化:Channel 映射与消息转发
Channel 映射机制
源码位置:core/reader/replicate_channel_manager.go
这里有一个容易被忽略的设计:源端和目标端的 Channel 数量可能不同。
Milvus 的数据按 Channel 分片,每个 Collection 的数据分布在一组 Channel 上。当你用 CDC 把数据同步到另一个集群时,目标集群的 Channel 数量可能和源端不一样(比如目标集群节点数不同)。
CDC 的处理方式是 ForeachChannel——按排序方式一一映射,当 Channel 不匹配时通过消息转发(forward)来适配。这意味着在 Channel 数量差异大的场景下,会有额外的转发开销。建议:尽量让源端和目标端的集群配置一致,减少 Channel 映射的性能损耗。
名称映射
源码位置:core/writer/channel_writer.go mapDBAndCollectionName
CDC 支持通过 nameMappings 配置源端和目标端的 Database/Collection 名称映射。所有写操作前都会调用这个映射函数。如果你想在目标集群用不同的命名规范,这是个很有用的功能——但要注意,映射配置错误会导致数据写到错误的 Collection,排查起来不太容易。
支持的操作范围
CDC 覆盖了 Milvus 的主要操作类型:
DDL 操作:Create/Drop Collection、Create/Drop Partition、Create/Drop Index、Create/Drop Database
DML 操作:Insert/Delete、Load/Release、Flush
安全操作(源码位置:core/writer/channel_writer.go initOPMessageFuncs):User/Role/Privilege 管理,包括 Create/Delete/Update User、Create/Drop Role、Operate UserRole/Privilege/PrivilegeV2、Create/Drop/Operate PrivilegeGroup
安全操作的同步是个亮点——这意味着主备集群的权限配置也能保持一致,不需要手动维护两套权限体系。
7. 部署注意事项
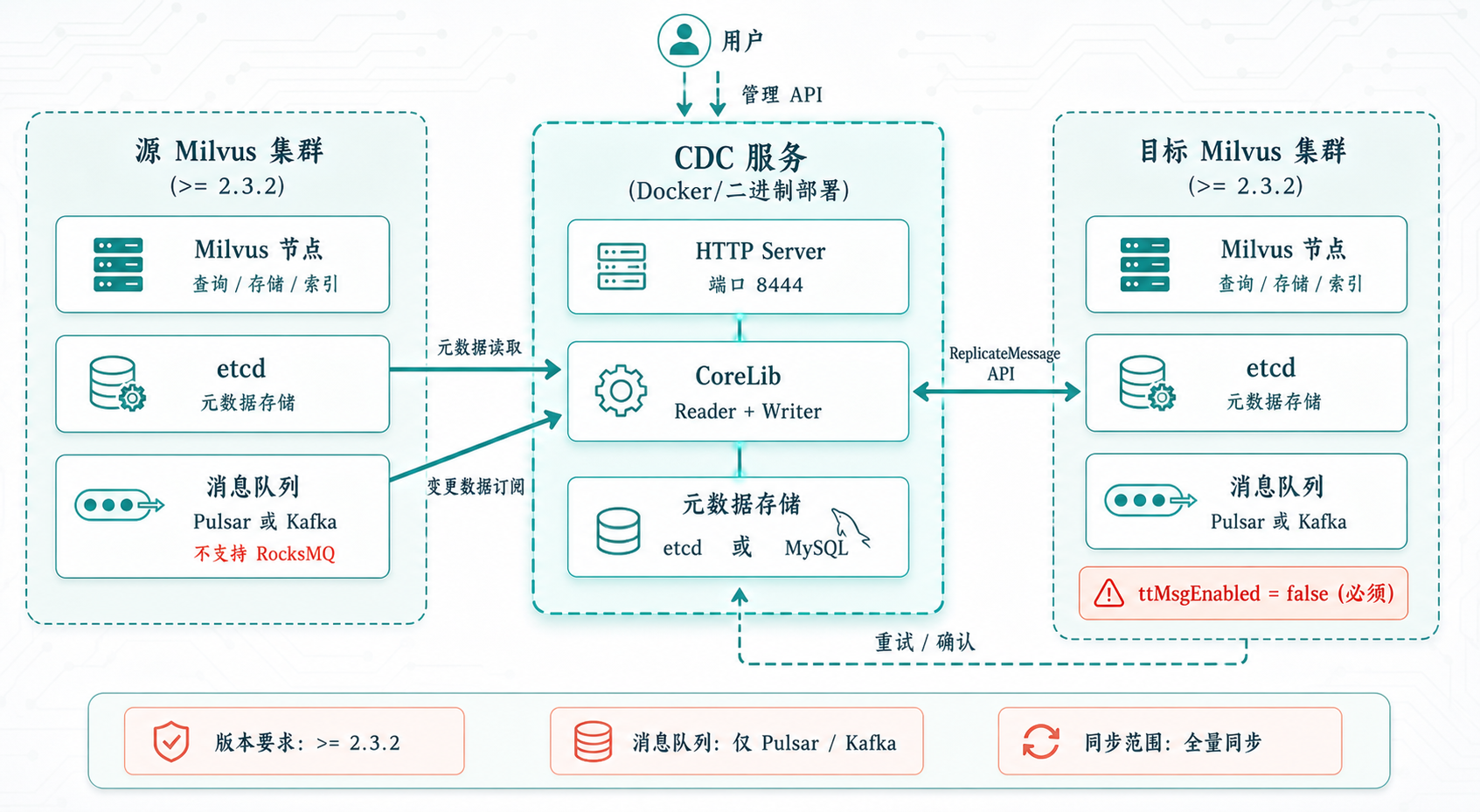
Milvus CDC 部署拓扑图
翻完源码和官方文档(源码位置:doc/cdc-usage.md),有几个硬性限制必须注意。
版本兼容
源和目标 Milvus 版本必须 >= 2.3.2。这是因为 ReplicateMessage API 从这个版本开始支持。CDC 的核心消息转发机制依赖这个 API,低于这个版本的 Milvus 无法作为目标端。
消息队列选型
仅支持 Pulsar 和 Kafka,RocksMQ 不行。
RocksMQ 是 Milvus 内置的消息队列(基于 RocksDB),主要用于单机部署和测试。CDC 需要独立的消息队列客户端来订阅 replicate channel,RocksMQ 不提供这个能力。
如果你的源集群用的是 RocksMQ,要么切换到 Pulsar/Kafka,要么就没法用 CDC。
目标集群配置
目标集群必须设置 common.ttMsgEnabled = false。
这个参数控制 TimeTick 消息的处理。CDC 在同步数据时已经有自己的 TimeTick Manager 来管理时间戳,如果目标集群也开启 TimeTick 处理,会产生冲突。不关掉这个参数,同步过来的数据会被目标集群的 TimeTick 机制拒绝。
同步粒度
目前创建任务时,collection_infos 必须传 [{"name": "*"}],即全量同步所有 Collection。不支持只同步指定的 Collection。
如果你的源集群有很多 Collection,但你只需要同步其中几个,目前没有办法做精细化控制。这在大规模部署场景下可能是个痛点——不必要的数据同步会浪费带宽和计算资源。
部署方式
CDC 支持 Docker 部署(源码位置:deployment/docker/)和直接二进制部署。Docker 方式更方便,二进制部署适合需要深度定制的场景。
总结
翻完 Milvus CDC 的源码,几个关键印象:
- 架构清晰:HTTP Server + CoreLib 的分层,Reader/Writer 通过接口解耦,代码组织得很干净
- 容错扎实:5 层防护机制不是堆砌,每一层都解决了具体的工程问题
- 限制明确:只支持 Pulsar/Kafka、必须全量同步、目标集群要关闭 ttMsgEnabled——这些是使用前必须确认的前提条件
说实话,CDC 目前的限制也不少:不支持增量指定 Collection 同步、不支持 RocksMQ、没有可视化的运维界面。如果你的场景是大规模生产环境的精细化容灾,这些限制可能需要绕一绕。
但如果你的需求是 Milvus 主备集群的跨区域数据同步,CDC 已经提供了从 DDL 到 DML 到权限管理的完整覆盖,加上 5 层容错机制,作为容灾方案的基础是够用的。
建议先在测试环境完整跑通一遍,重点验证 Channel 映射和重试配置是否匹配你的写入量级,再上生产。
如果你也在做向量数据库的容灾方案,你觉得 CDC 的这些限制能接受吗?评论区聊聊你的看法。
好啦,谢谢你观看我的文章,如果喜欢可以点赞转发给需要的朋友,我们下一期再见!敬请期待!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号