AI测试从入门到专家:联通结算系统全流程实战指南(1)


第一部分:架构与Git智能分析
1. 开场 & 痛点对齐
1.1 联通结算系统测试现状分析
传统自动化测试的困境
在引入AI之前,大多数企业级系统的测试处于以下状态:
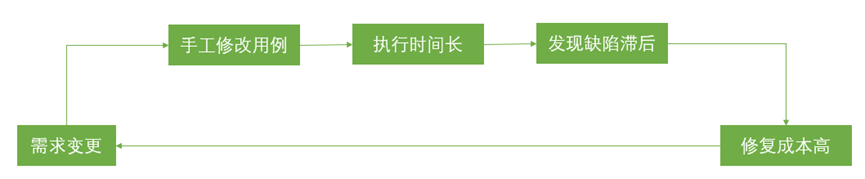
具体表现:
维度 传统方式 痛点
用例编写 手工编写,每人每天20-30条 劳动密集,效率低
用例维护 代码变更后手动更新 维护成本占总成本50%以上
影响分析 依赖人工经验,凭感觉 变更遗漏率达30%
失败分析 手工逐条排查日志 平均定位时间30分钟/用例
报告解读 静态报告,缺乏洞察 难以指导质量改进
联通结算系统的特殊挑战:
- 业务规则极复杂
- 国内漫游、国际漫游、增值服务等数百种计费规则
- 规则之间相互依赖,牵一发而动全身
- 数据一致性要求极高
- 任何金额错误都可能导致数千万级资损
- 需要对账、审计、回溯
- 多语言技术栈
java
// Java层:业务编排
@Service
public class BillingService {
public BigDecimal calculate(BillRequest req) {
// 调用Golang微服务
List<CDR> cdrs = golangClient.collectCDRs(req);
// 调用C库进行加密计算
byte[] encrypted = cLib.encrypt(cdrs.toString());
// ...
}
}
AI驱动测试的范式转变
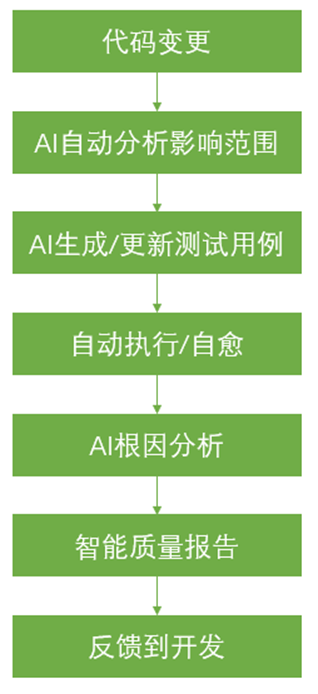
核心转变:
- 从被动响应到主动预测
- 从全量执行到精准测试
- 从人工维护到AI自愈
- 从结果报告到根因分析
1.2 典型痛点场景演示
场景:运营商调整了"国际漫游夜间时段优惠"规则
- 变更内容:夜间优惠时段从23:00-07:00改为00:00-06:00
- 传统方式:
- 测试人员收到变更通知
- 手动查找所有涉及夜间优惠的用例(约320个)
- 逐个修改用例中的时间参数和预期结果
- 重新执行,耗时约3人天
- 遗漏了边缘场景(跨时区通话),上线后产生生产问题
AI方式:
- Git钩子触发AI分析
- 5秒内识别出所有受影响测试点
- 自动生成更新后的用例
- 额外生成跨时区边缘测试用例
1.3 课程目标
学习路径:
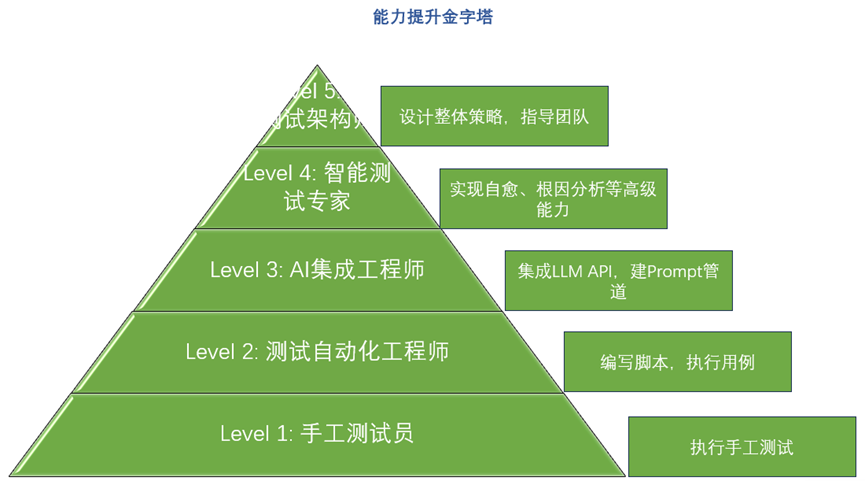
您当前水平 → 目标水平(Level 3-4)
2天后您将能够:
- 独立设计AI测试架构
- 编写高效的测试Prompt
- 实现Git变更智能分析
- 构建多语言AI测试方案
- 设计成本可控的AI调用策略
2. AI测试自动化架构设计
2.1 分层AI测试架构全景
架构图
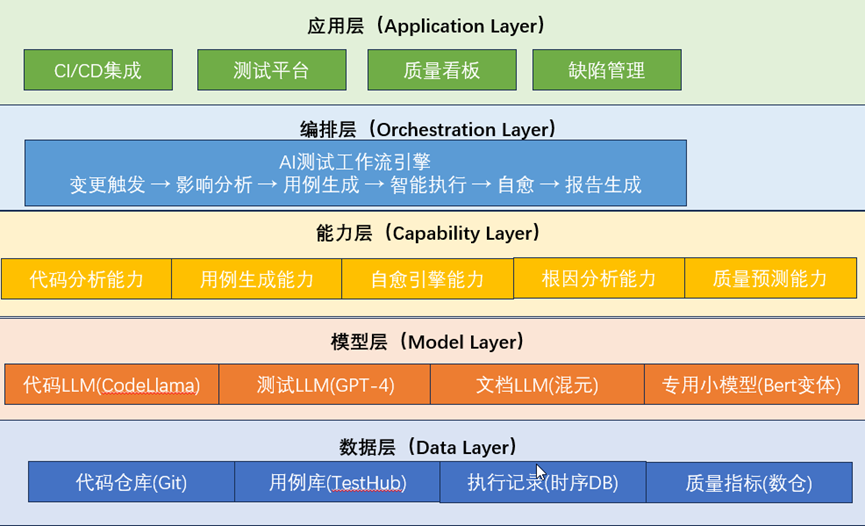
各层职责详解
1. 代码层:Git变更分析 → AI圈定影响范围
python
# 代码层核心逻辑伪代码
class CodeAnalysisLayer:
def analyze_change(self, commit_id):
# 1. 获取变更内容
diff = self.git.get_diff(commit_id)
# 2. 提取变更元数据
changed_files = self.extract_files(diff)
changed_methods = self.extract_methods(diff)
changed_fields = self.extract_fields(diff)
# 3. AI影响分析
prompt = build_impact_prompt(
diff=diff,
changed_methods=changed_methods,
context=self.get_code_context(changed_files)
)
impact = self.llm.analyze(prompt)
# 4. 输出影响范围
return ImpactReport(
affected_apis=impact.apis,
affected_db_tables=impact.tables,
affected_business_rules=impact.rules,
risk_level=impact.risk
)
输出示例:
json
{
"affected_apis": ["/api/billing/calculate", "/api/invoice/generate"],
"affected_db_tables": ["t_settlement_detail", "t_discount_rule"],
"affected_business_rules": ["夜间优惠规则", "节假日双倍积分规则"],
"risk_level": "HIGH",
"recommended_tests": ["边界值测试", "跨时段场景测试", "并发测试"]
}
2. 用例层:AI生成/更新用例
python
class TestCaseLayer:
def generate_test_cases(self, impact_report, business_rules):
test_cases = []
for api in impact_report.affected_apis:
# 1.获取API定义和参数约束
api_spec = self.get_api_spec(api)
# 2.AI生成测试用例
prompt = build_testgen_prompt(
api_spec=api_spec,
business_rules=business_rules,
test_types=["正常", "边界", "异常", "并发"]
)
cases = self.llm.generate(prompt)
test_cases.extend(cases)
return test_cases
3. 执行层:自适应断言 + 自愈机制
python
class ExecutionLayer:
def execute_with_self_healing(self, test_case):
try:
result = self.run_test(test_case)
self.assert_result(result, test_case.expected)
except AssertionError as e:
# 1.尝试自愈
healed = self.self_healing_engine.heal(
test_case=test_case,
actual_result=result,
error=e
)
if healed.success:
#2.更新断言
self.update_assertion(test_case, healed.new_expected)
#3.重新执行
return self.run_test(test_case)
else:
raise
4. 分析层:AI根因分析 + 质量热力图
python
class AnalysisLayer:
def analyze_failures(self, failures):
# 1.聚类分析
clusters = self.cluster_failures(failures)
# 2.根因分析
for cluster in clusters:
prompt = build_root_cause_prompt(
failure_logs=cluster.logs,
code_context=self.get_code_context(cluster.location),
environment=cluster.env
)
cluster.root_cause = self.llm.analyze(prompt)
# 3.生成质量热力图
heatmap = self.generate_heatmap(clusters)
return AnalysisReport(clusters=clusters, heatmap=heatmap)
质量热力图就是将质量问题或指标以"温度"形式可视化:颜色越"热"(红),代表问题越严重或数值越高;颜色越"冷"(蓝/绿),则代表情况越好。它就像一个"温度计",帮你一眼看穿数据,快速定位问题集中区域。
2.2 结合联通结算系统的架构实例
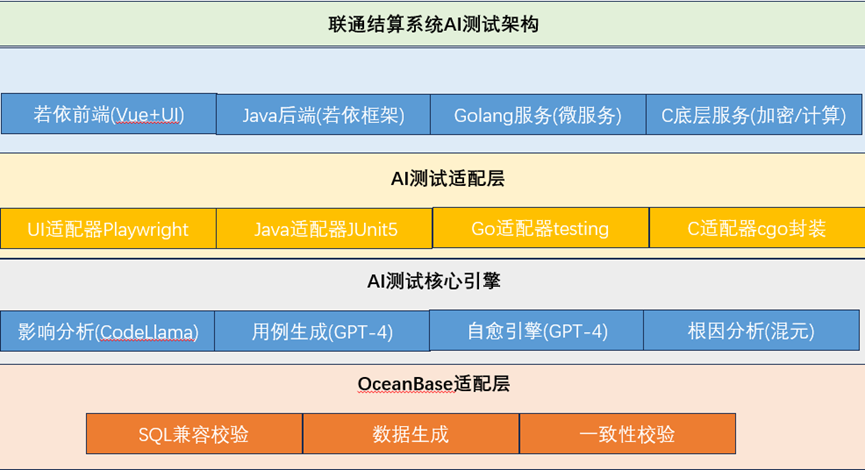
2.3 实操:画出适合自己业务的AI测试架构草图
实操步骤:
- 识别测试对象:列出您的系统有哪些组件(如:前端、API、数据库、消息队列)
- 确定AI能力点:哪些环节可以用AI增强
- 设计数据流:变更如何触发AI分析,结果如何使用
- 评估可行性:技术难度、成本、收益
小组讨论模板:
markdown
## 我们的AI测试架构
### 1. 系统组件清单
- [ ] 前端UI(类型:_____)
- [ ] 后端API(语言:_____,框架:_____)
- [ ] 数据库(类型:_____)
- [ ] 消息队列(类型:_____)
- [ ] 微服务(语言:_____)
### 2. AI赋能点(勾选)
- [ ] 代码变更影响分析
- [ ] 测试用例自动生成
- [ ] 测试数据智能构造
- [ ] 断言自动更新
- [ ] 失败根因分析
- [ ] 质量报告生成
### 3. 数据流设计
[画图区域]
### 4. 技术选型
- LLM模型:_____
- 集成方式:_____
- 成本预算:_____
3. Git集成与代码变更分析
3.1 核心能力详解
3.1.1从Git Diff提取信息
1.Git Diff基础
1) 输出
新增的行(绿色,以+开头) 删除的行(红色,以-开头) 修改的文件列表
2) 等价命令
git diff HEAD~1 HEAD
git diff HEAD^ HEAD
git diff HEAD~1..HEAD
3) 相关常用命令
# 获取两个版本之间的差异
git diff HEAD~1 HEAD
# 获取特定文件的差异
git diff HEAD~1 HEAD -- src/main/java/Calculator.java
# 获取统计信息
git diff --stat HEAD~1 HEAD
# 只显示修改的文件名
git diff --name-only HEAD~1 HEAD
# 显示更紧凑的差异(获取统计信息)
git diff --stat HEAD~1 HEAD
# 查看最近两个提交的详细变化
git log -p -2
# 查看最新提交的变化(相对于父提交)
git show HEAD
4) Python解析Git Diff
Python
git_diff.py
import subprocess
import re
import sys
class GitAnalyzer:
def get_diff(self, commit_hash):
"""获取指定commit的diff"""
cmd = f"git show {commit_hash}"
# 修复编码问题:指定使用 UTF-8 编码,并忽略错误
result = subprocess.run(
cmd,
shell=True,
capture_output=True,
text=True,
encoding='utf-8', # 指定使用 UTF-8 编码
errors='ignore' # 忽略无法解码的字符
)
return result.stdout
def parse_diff(self, diff_text):
"""解析diff提取变更信息"""
changes = {
'added_files': [],
'modified_files': [],
'deleted_files': [],
'code_changes': []
}
current_file = None
for line in diff_text.split('\n'):
# 识别文件变更
if line.startswith('diff --git'):
match = re.search(r'b/(.+)$', line)
if match:
current_file = match.group(1)
changes['modified_files'].append(current_file)
# 识别新增行
elif line.startswith('+') and not line.startswith('+++'):
changes['code_changes'].append({
'file': current_file,
'type': 'added',
'content': line[1:],
'line_number': self._extract_line_number(line)
})
# 识别删除行
elif line.startswith('-') and not line.startswith('---'):
changes['code_changes'].append({
'file': current_file,
'type': 'deleted',
'content': line[1:],
'line_number': self._extract_line_number(line)
})
return changes
def extract_dependencies(self, file_path, changes):
"""提取依赖变更"""
# 对于Java文件,分析import变更
if file_path.endswith('.java'):
return self._analyze_java_imports(changes)
# 对于Python文件,分析import变更
if file_path.endswith('.py'):
return self._analyze_python_imports(changes)
# 对于Go文件,分析package import
elif file_path.endswith('.go'):
return self._analyze_go_imports(changes)
# 对于C文件,分析头文件
elif file_path.endswith(('.c', '.h')):
return self._analyze_c_includes(changes)
return []
def _analyze_java_imports(self, changes):
"""分析Java文件的import变更"""
dependencies = []
for change in changes['code_changes']:
content = change['content'].strip()
# 匹配 import 语句
if content.startswith('import ') and content.endswith(';'):
# 提取完整的import路径
import_path = content[7:-1].strip() # 移除 'import ' 和 ';'
dependencies.append({
'type': 'import',
'dependency': import_path,
'action': change['type'],
'file': change['file']
})
# 匹配静态导入
elif content.startswith('import static '):
static_import = content[14:-1].strip()
dependencies.append({
'type': 'static_import',
'dependency': static_import,
'action': change['type'],
'file': change['file']
})
return dependencies
def _analyze_python_imports(self, changes):
"""分析Python文件的import变更"""
dependencies = []
for change in changes['code_changes']:
content = change['content'].strip()
# 匹配 import xxx
if content.startswith('import '):
imports = content[7:].split(',')
for imp in imports:
imp = imp.strip()
if imp:
dependencies.append({
'type': 'import',
'dependency': imp,
'action': change['type'],
'file': change['file']
})
# 匹配 from xxx import yyy
elif content.startswith('from '):
match = re.match(r'from\s+([\w.]+)\s+import\s+(.+)', content)
if match:
module = match.group(1)
imports = match.group(2).split(',')
for imp in imports:
imp = imp.strip()
if imp == '*':
dependencies.append({
'type': 'import_all',
'dependency': module,
'action': change['type'],
'file': change['file']
})
else:
dependencies.append({
'type': 'import',
'dependency': f"{module}.{imp}",
'action': change['type'],
'file': change['file']
})
# 匹配相对导入 from . import xxx 或 from .. import xxx
elif content.startswith('from .'):
match = re.match(r'from\s+(\.+)(\w*)\s+import\s+(.+)', content)
if match:
relative_level = len(match.group(1))
module = match.group(2) if match.group(2) else ''
imports = match.group(3).split(',')
for imp in imports:
imp = imp.strip()
dependencies.append({
'type': 'relative_import',
'dependency': f"{'.' * relative_level}{module}.{imp}" if module else f"{'.' * relative_level}{imp}",
'action': change['type'],
'file': change['file']
})
return dependencies
def _analyze_go_imports(self, changes):
"""分析Go文件的import变更"""
dependencies = []
in_import_block = False
for change in changes['code_changes']:
content = change['content'].strip()
# 匹配单个import
if content.startswith('import "') and content.endswith('"'):
import_path = content[8:-1]
dependencies.append({
'type': 'import',
'dependency': import_path,
'action': change['type'],
'file': change['file']
})
# 匹配带别名的import
elif re.match(r'import\s+\w+\s+"[^"]+"', content):
match = re.match(r'import\s+(\w+)\s+"([^"]+)"', content)
if match:
alias, path = match.groups()
dependencies.append({
'type': 'import',
'dependency': path,
'alias': alias,
'action': change['type'],
'file': change['file']
})
# 匹配import块开始
elif content == 'import (' or content.startswith('import('):
in_import_block = True
# 匹配import块内的内容
elif in_import_block and content and not content == ')':
# 移除可能的前导空格
content = content.strip()
if content and not content.startswith('//'):
# 处理带别名的import
alias_match = re.match(r'(\w+)\s+"([^"]+)"', content)
if alias_match:
alias, path = alias_match.groups()
dependencies.append({
'type': 'import',
'dependency': path,
'alias': alias,
'action': change['type'],
'file': change['file']
})
# 处理普通import
elif content.startswith('"') and content.endswith('"'):
path = content[1:-1]
dependencies.append({
'type': 'import',
'dependency': path,
'action': change['type'],
'file': change['file']
})
# 匹配import块结束
elif in_import_block and content == ')':
in_import_block = False
return dependencies
def _analyze_c_includes(self, changes):
"""分析C/C++文件的include变更"""
dependencies = []
for change in changes['code_changes']:
content = change['content'].strip()
# 匹配系统头文件 #include <...>
match_system = re.match(r'#include\s+<([^>]+)>', content)
if match_system:
header = match_system.group(1)
dependencies.append({
'type': 'system_include',
'dependency': header,
'action': change['type'],
'file': change['file']
})
continue
# 匹配本地头文件 #include "..."
match_local = re.match(r'#include\s+"([^"]+)"', content)
if match_local:
header = match_local.group(1)
dependencies.append({
'type': 'local_include',
'dependency': header,
'action': change['type'],
'file': change['file']
})
continue
# 匹配条件编译中的include
if '#ifdef' in content or '#ifndef' in content:
# 可以扩展分析条件编译中的依赖
pass
return dependencies
def _extract_line_number(self, line):
"""从diff行中提取行号(简化版本)"""
# 这个方法的完整实现需要解析diff中的@@行
# 这里返回None作为简化实现
return None
def main():
"""主函数:分析Python文件的依赖变更"""
# 创建分析器实例
analyzer = GitAnalyzer()
# 示例1:分析特定的commit(替换为你的commit hash)
commit_hash = "HEAD" # 或者使用具体的commit hash,如 "abc123"
print(f"正在分析 commit: {commit_hash}")
print("-" * 50)
try:
# 获取diff(使用修复后的方法)
diff_text = analyzer.get_diff(commit_hash)
if not diff_text or not diff_text.strip():
print("没有获取到diff内容")
print("提示:请确保你在一个Git仓库目录中运行此脚本")
return
# 解析diff
changes = analyzer.parse_diff(diff_text)
# 分析每个Python文件的依赖变更
python_files = []
for file in changes['modified_files']:
if file.endswith('.py'):
python_files.append(file)
if not python_files:
print("没有找到Python文件的变更")
else:
print(f"找到 {len(python_files)} 个Python文件变更:")
for file in python_files:
print(f" - {file}")
print("\n" + "=" * 50)
print("依赖变更分析结果:")
print("=" * 50)
# 针对每个Python文件提取依赖
all_dependencies = []
for file in python_files:
# 只分析该文件的变更
file_changes = {
'code_changes': [c for c in changes['code_changes'] if c.get('file') == file]
}
deps = analyzer._analyze_python_imports(file_changes)
if deps:
all_dependencies.extend(deps)
# 显示结果
if all_dependencies:
for dep in all_dependencies:
print(f"\n文件: {dep['file']}")
print(f" 类型: {dep['type']}")
print(f" 依赖: {dep['dependency']}")
print(f" 操作: {dep['action']}")
else:
print("没有检测到依赖变更")
except Exception as e:
print(f"分析过程中出现错误: {e}")
import traceback
traceback.print_exc()
print("\n提示:请确保你在一个Git仓库目录中运行此脚本")
# 示例2:使用模拟的diff文本进行测试(如果不想使用真实的git命令)
print("\n" + "=" * 50)
print("使用模拟数据进行测试:")
print("=" * 50)
mock_diff = """
diff --git a/test.py b/test.py
index abc123..def456 100644
--- a/test.py
+++ b/test.py
@@ -1,5 +1,7 @@
import os
+import sys
from datetime import datetime
+from collections import defaultdict
import json
def main():
@@ -10,4 +12,5 @@ def main():
- print("old code")
+ print("new code")
+ import requests
"""
mock_changes = analyzer.parse_diff(mock_diff)
mock_deps = analyzer._analyze_python_imports(mock_changes)
if mock_deps:
for dep in mock_deps:
print(f"文件: {dep['file']}")
print(f" 类型: {dep['type']}")
print(f" 依赖: {dep['dependency']}")
print(f" 操作: {dep['action']}")
print()
else:
print("模拟数据中没有检测到依赖变更")
if __name__ == "__main__":
main()
5) 案例
xiang@xiang MINGW64 ~ $
cd /C/Code/python/ebusiness/ebusiness_mysql/ebusiness\goods
xiang@xiang MINGW64 /C/Code/python/ebusiness/ebusiness_mysql/ebusiness/goods (master)
$ git config core.autocrlf true
xiang@xiang MINGW64 /C/Code/python/ebusiness/ebusiness_mysql/ebusiness/goods (master)
$ git add .
xiang@xiang MINGW64 /C/Code/python/ebusiness/ebusiness_mysql/ebusiness/goods (master)
$ git commit -m "first commit"
[master (root-commit) 1999adc] first commit
77 files changed, 1768 insertions(+)
create mode 100644 .scannerwork/.sonar_lock
…
编辑文件
xiang@xiang MINGW64 /C/Code/python/ebusiness/ebusiness_mysql/ebusiness/goods (master)
$ git add .
warning: in the working copy of 'util.py', LF will be replaced by CRLF the next time Git touches it
warning: in the working copy of 'views.py', LF will be replaced by CRLF the next time Git touches it
xiang@xiang MINGW64 /C/Code/python/ebusiness/ebusiness_mysql/ebusiness/goods (master)
$ git commit -m "second commit"
[master d8a0ae4] second commit
2 files changed, 18 insertions(+), 22 deletions(-)
xiang@xiang MINGW64 /C/Code/python/ebusiness/ebusiness_mysql/ebusiness/goods (master)
$ git diff HEAD~1 HEAD
diff --git a/util.py b/util.py
index 21c17c7..7aee798 100644
--- a/util.py
+++ b/util.py
@@ -20,7 +20,6 @@ class Util:
else:
return username
-
#通过addressId判断这个地址是否属于当前登录用户
def check_User_By_Address(self,request,username,addressId):
#获取addressId对应的address信息
@@ -109,29 +108,29 @@ class Util:
#定义单个订单变量
def set_order_list(self,key):
order_list = Order_list()
- order_list.set_id(key.id)#主键
+ order_list.set_id(key.id) #主键
good_list = get_object_or_404(Goods,id=key.goods_id)#获得当前商品信息
- order_list.set_good_id(good_list.id)#订单中商品编号
- order_list.set_name(good_list.name)#订单中商品名字
- order_list.set_price(good_list.price)#订单中商品价格
- order_list.set_count(key.count)#购买数量
:
…
Run git_diff.py
正在分析 commit: HEAD
--------------------------------------------------
找到 2 个Python文件变更:
- util.py
- views.py
==================================================
依赖变更分析结果:
==================================================
没有检测到依赖变更
==================================================
使用模拟数据进行测试:
==================================================
文件: test.py
类型: import
依赖: sys
操作: added
文件: test.py
类型: import
依赖: collections.defaultdict
操作: added
文件: test.py
类型: import
依赖: requests
操作: added
2使用LLM分析变更影响
1)构建Prompt的原则:
- 提供足够的上下文:不仅仅是变更代码,还有相关文件
- 明确输出格式:使用JSON或结构化文本
- 限定分析范围:避免LLM发散
- 提供示例:Few-shot learning提升准确率
2)完整Prompt模板
python
def build_impact_analysis_prompt(diff,code_context,business_rules):
return f"""
你是一位资深的测试架构师,擅长分析代码变更对系统的影响。 s
## 任务
分析以下代码变更,输出影响分析报告。
## 变更代码 (Git Diff)
{diff}
text
## 代码上下文
{code_context}
## 业务规则上下文
{business_rules}
## 输出格式 (JSON)
{{
"change_intent": "变更意图描述(一句话概括)",
"affected_components": {{
"frontend": ["受影响的页面/组件列表"],
"backend": ["受影响的API/服务列表"],
"database": ["受影响的表/字段列表"],
"business_rules": ["受影响的业务规则列表"]
}},
"test_recommendations": {{
"regression_tests": ["建议回归的测试场景"],
"new_tests": ["建议新增的测试场景"],
"edge_cases": ["需要注意的边缘场景"]
}},
"risk_level": "HIGH/MEDIUM/LOW",
"risk_reason": "风险评估理由"
}}
## 分析要求
1. 变更意图:基于代码变更推断开发人员的意图
2. 影响范围:考虑调用链、数据流、UI展示
3. 测试建议:具体、可执行、覆盖正常/异常/边界
4. 风险评估:考虑业务敏感度、变更复杂度、影响广度
请开始分析:
"""
3)实际调用示例
python
import openai
class LLMImpactAnalyzer:
def __init__(self, api_key, model="gpt-4"):
self.api_key = api_key
self.model = model
openai.api_key = api_key
def analyze(self, diff, code_context, business_rules):
prompt = build_impact_analysis_prompt(diff, code_context, business_rules)
response = openai.ChatCompletion.create(
model=self.model,
messages=[
{"role": "system", "content": "你是一位资深的测试架构师,擅长分析代码变更影响。"},
{"role": "user", "content": prompt}
],
temperature=0.3, # 降低随机性,提高准确性
response_format={"type": "json_object"}
)
return json.loads(response.choices[0].message.content)
3.2 Prompt工程实例详解
3.2.1案例:Java结算方法的变更
1.原始代码(变更前)
java
public class SettlementCalculator {
/**
* 计算国际漫游结算金额
* @param cdr 通话详单
* @param userType 用户类型(1:普通用户, 2:VIP用户)
* @return 结算金额(单位:分)
*/
public long calculateRoamingFee(CDR cdr, int userType) {
long baseFee = cdr.getDuration() * 10; // 10分/秒
// VIP用户8折
if (userType == 2) {
baseFee = baseFee * 8 / 10;
}
// 夜间优惠(23:00-07:00)
if (isNightTime(cdr.getCallTime())) {
baseFee = baseFee * 7 / 10; // 7折
}
return baseFee;
}
private boolean isNightTime(LocalDateTime time) {
int hour = time.getHour();
return hour >= 23 || hour < 7;
}
}
2.变更后代码
java
public class SettlementCalculator {
public long calculateRoamingFee(CDR cdr, int userType) {
long baseFee = cdr.getDuration() * 12; // 变更: 10分/秒 → 12分/秒
if (userType == 2) {
baseFee = baseFee * 8 / 10;
}
// 变更: 夜间优惠时段 23:00-07:00 → 00:00-06:00
// 变更: 折扣 7折 → 6折
if (isNightTime(cdr.getCallTime())) {
baseFee = baseFee * 6 / 10;
}
return baseFee;
}
private boolean isNightTime(LocalDateTime time) {
int hour = time.getHour();
return hour >= 0 && hour < 6; // 变更: 00:00-06:00
}
}
3.Git Diff
diff
@@ -1,7 +1,7 @@
public long calculateRoamingFee(CDR cdr, int userType) {
- long baseFee = cdr.getDuration() * 10;
+ long baseFee = cdr.getDuration() * 12;
if (userType == 2) {
baseFee = baseFee * 8 / 10;
}
- // 夜间优惠(23:00-07:00)
+ // 夜间优惠(00:00-06:00)
if (isNightTime(cdr.getCallTime())) {
- baseFee = baseFee * 7 / 10;
+ baseFee = baseFee * 6 / 10;
}
return baseFee;
}
@@ -15,6 +15,6 @@
private boolean isNightTime(LocalDateTime time) {
int hour = time.getHour();
- return hour >= 23 || hour < 7;
+ return hour >= 0 && hour < 6;
}
4.合成代码
prompt.py
import openai
import json
import re # 用于辅助提取JSON
import os
class LLMImpactAnalyzer:
def build_impact_analysis_prompt(self, diff, code_context, business_rules):
# ... (这个方法的内容保持不变,和原来完全一样) ...
return f"""
你是一位资深的测试架构师,擅长分析代码变更对系统的影响。
## 任务
分析以下代码变更,输出影响分析报告。
## 变更代码 (Git Diff)
{diff}
## 代码上下文
{code_context}
## 业务规则上下文
{business_rules}
## 输出格式 (JSON)
{{
"change_intent": "变更意图描述(一句话概括)",
"affected_components": {{
"frontend": ["受影响的页面/组件列表"],
"backend": ["受影响的API/服务列表"],
"database": ["受影响的表/字段列表"],
"business_rules": ["受影响的业务规则列表"]
}},
"test_recommendations": {{
"regression_tests": ["建议回归的测试场景"],
"new_tests": ["建议新增的测试场景"],
"edge_cases": ["需要注意的边缘场景"]
}},
"risk_level": "HIGH/MEDIUM/LOW",
"risk_reason": "风险评估理由"
}}
## 分析要求
1. 变更意图:基于代码变更推断开发人员的意图
2. 影响范围:考虑调用链、数据流、UI展示
3. 测试建议:具体、可执行、覆盖正常/异常/边界
4. 风险评估:考虑业务敏感度、变更复杂度、影响广度
请开始分析:
"""
def __init__(self, api_key, model="gpt-3.5-turbo"): # 建议先用 gpt-3.5-turbo 测试
self.api_key = api_key
self.model = model
# 【修改点1】: 创建客户端实例
self.client = openai.OpenAI(api_key=api_key)
def analyze(self, diff, code_context, business_rules):
prompt = self.build_impact_analysis_prompt(diff, code_context, business_rules)
# 【修改点2】: 使用新的 API 调用方式
response = self.client.chat.completions.create(
model=self.model,
messages=[
{"role": "system", "content": "你是一位资深的测试架构师,擅长分析代码变更影响。"},
{"role": "user", "content": prompt}
],
temperature=0.3,
# 【修改点3】: 移除 response_format 参数,新版中它可能不兼容
)
# 【修改点4】: 安全地获取返回的文本内容
content = response.choices[0].message.content
# 【修改点5】: 增强的 JSON 解析,尝试从返回文本中提取 JSON 块
try:
# 直接解析
return json.loads(content)
except json.JSONDecodeError:
# 如果失败,尝试用正则表达式提取 {} 内的内容
json_match = re.search(r'\{.*\}', content, re.DOTALL)
if json_match:
try:
return json.loads(json_match.group())
except json.JSONDecodeError as e:
raise Exception(f"无法解析LLM返回的JSON: {e}\n原始返回内容: {content}")
else:
raise Exception(f"LLM返回内容中未找到有效的JSON块。原始返回内容: {content}")
# ========== 融合你提供的 Java 代码变更示例 ==========
if __name__ == "__main__":
# ... (diff_text, code_context, business_rules 的赋值保持不变) ...
diff_text = """
变更前:
public long calculateRoamingFee(CDR cdr, int userType) {
long baseFee = cdr.getDuration() * 10; // 10分/秒
// ... (省略部分内容,请保留你原来的完整diff)
}
"""
code_context = """
类名:SettlementCalculator
方法:calculateRoamingFee
依赖:CDR对象(包含通话时长、通话时间)
调用方:国际漫游计费模块
"""
business_rules = """
1. 国际漫游基础费率:12分/秒(原10分/秒)
2. VIP用户8折
3. 夜间时段(00:00-06:00)6折(原7折,原时段23:00-07:00)
4. 最终金额单位为分
"""
# 请替换为你的真实 API Key
api_key = os.getenv("DASHSCOPE_API_KEY")
model = os.getenv("QWEN_MODEL", "qwen-plus")
analyzer = LLMImpactAnalyzer(api_key=api_key, model=model)
result = analyzer.analyze(diff_text, code_context, business_rules)
print(json.dumps(result, indent=2, ensure_ascii=False))
AI分析输出:
json
{
"change_intent": "将国际漫游基础费率从10分/秒调整为12分/秒,并同步适配VIP折扣、夜间时段折扣规则变更(时段缩窄至00:00-06:00、折扣力度由7折增强至6折),以符合最新资费政策要求。",
"affected_components": {
"frontend": [],
"backend": [
"SettlementCalculator.calculateRoamingFee",
"国际漫游计费模块(调用方服务)"
],
"database": [],
"business_rules": [
"国际漫游基础费率(10分/秒 → 12分/秒)",
"夜间时段定义(23:00-07:00 → 00:00-06:00)",
"夜间折扣率(7折 → 6折)",
"VIP用户折扣率(保持8折,但计算基数变更影响最终金额)"
]
},
"test_recommendations": {
"regression_tests": [
"非VIP用户日间普通通话(验证基础费率12分/秒是否生效)",
"VIP用户日间通话(验证12分/秒 × 0.8 = 9.6分/秒等效费率)",
"非VIP用户原夜间时段23:30-00:30通话(跨旧夜间时段,应仅00:00-00:30部分享受新6折)",
"非VIP用户05:00-05:30通话(全量命中新夜间时段,验证6折应用正确性)",
"边界时间00:00:00和06:00:00的CDR处理(含毫秒级时间精度)"
],
"new_tests": [
"00:00-06:00外但紧邻的时段测试:23:59-00:01(验证00:00前不打折、00:00起打折)",
"跨日夜间通话:23:50-00:10(验证仅00:00-00:10部分适用6折)",
"VIP + 夜间双重优惠叠加场景(确认折扣顺序:先按12分/秒算基费,再按VIP打8折,最后夜间打6折,即12 × 0.8 × 0.6 = 5.76分/秒)",
"时长为0秒、1秒、最大Long值秒的CDR(验证整数溢出与边界计算)",
"CDR通话时间字段为null或非法格式(如'24:61:00')的异常处理路径"
],
"edge_cases": [
"CDR时间戳时区未标准化(如UTC vs 本地时区),导致夜间判断错误",
"系统时钟漂移或NTP同步延迟影响00:00/06:00判定",
"高并发下同一秒内大量CDR触发夜间规则临界点竞争条件",
"费率计算结果含小数分(如5.76分),需确认是否四舍五入到分(业务要求单位为‘分’,必须整数)",
"VIP标识字段userType取值范围变更(如新增userType=3表示企业VIP),当前逻辑是否兼容"
]
},
"risk_level": "HIGH",
"risk_reason": "该变更是核心计费逻辑的多维度调整(费率+时段+折扣率),直接影响收入准确性;夜间时段收缩与折扣加深易引发漏打折/多打折;所有计费结果以‘分’为单位,小数处理不当将导致资金差错;且无前端或数据库变更掩盖问题,错误将直接透传至账单与结算系统,具备强财务敏感性和监管审计风险。"
}
3.2.2对比传统人工分析:
维度 人工分析 AI分析
时间 30-60分钟 5-10秒
覆盖度 依赖个人经验,遗漏率30% 系统性分析,遗漏率<5%
一致性 不同人结果不同 标准化的输出
可追溯性 难以记录分析过程 完整记录Prompt和输出
边缘场景 容易忽略 自动识别
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-14,如有侵权请联系 cloudcommunity@tencent.com 删除
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号