反常识,企业开发Spec Coding不如Vibe Coding代码惊艳,但Spec Coding才是精准“靶向药”(附G1~G6上下文阶梯图)

反常识,企业开发Spec Coding不如Vibe Coding代码惊艳,但Spec Coding才是精准“靶向药”(附G1~G6上下文阶梯图)

用户5602664
发布于 2026-05-15 14:16:06
发布于 2026-05-15 14:16:06
说明:本文档数据非客户真实数据,数据提升部分、数据指标仅供参考。
"我们发现一个有趣的现象:不给AI任何约束时,它写出的代码反而在某些指标上得分更高——架构更'优雅'、设计模式运用更'教科书'。
真正有价值的AI代码,不是'最好的代码',而是'最适合你们项目的代码'。这就是为什么Spec和编码规范如此重要——它们不是在限制AI,而是在帮AI把能力用在正确的地方。"
约束越多,方差越小,下限越高
- G1(自由作文):上限可能高,但下限极低,方差极大
- G6(命题作文):上限被约束了,但下限很高,方差极小
对企业来说,要的不是"偶尔惊艳",而是"稳定可用"。
"让AI自由写代码,就像让学生写自由作文——可能写得很漂亮,但不是你要的。
我们做的事情,就是帮你把'自由作文'变成'命题作文'——告诉AI题目是什么、结构怎么写、风格模仿谁。
约束越清晰,AI交出的答卷越稳定、越可用。
每增加一层约束,代码质量提升多少。"
一、概述
1.1 核心发现
通过系统性地增加约束层,AI生成代码的生产可用性可从 1.5/5提升至 4.5/5,人工修改率从 >70%降至 <12%。(数据仅供参考)
六层约束递进阶梯图
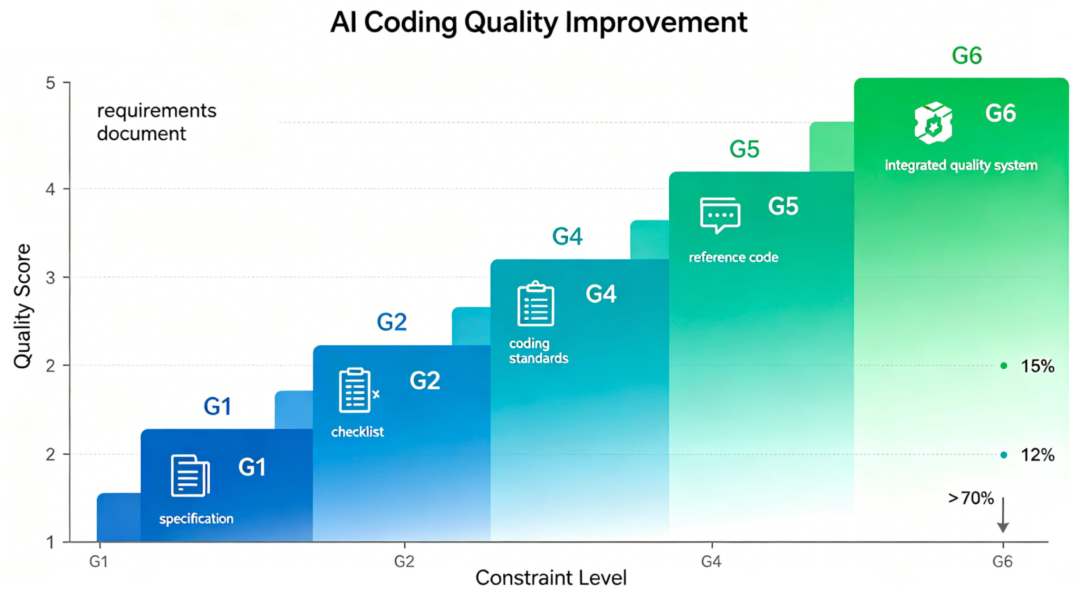
1.2 关键结论
结论 | 说明 |
|---|---|
✅ 约束越多,方差越小,下限越高 | 减少AI自由发挥带来的不确定性 |
✅ 完整Spec是业务正确性的关键拐点 | G3阶段业务准确度从50%跃升至80%+ |
✅ 参考代码比规则描述更有效 | G5→G6风格一致性跳升19% |
✅ 生产可用性应作为最终衡量标准 | 代码"能用"比"好看"更重要 |
1.3 投资回报
投入产出ROI对比图
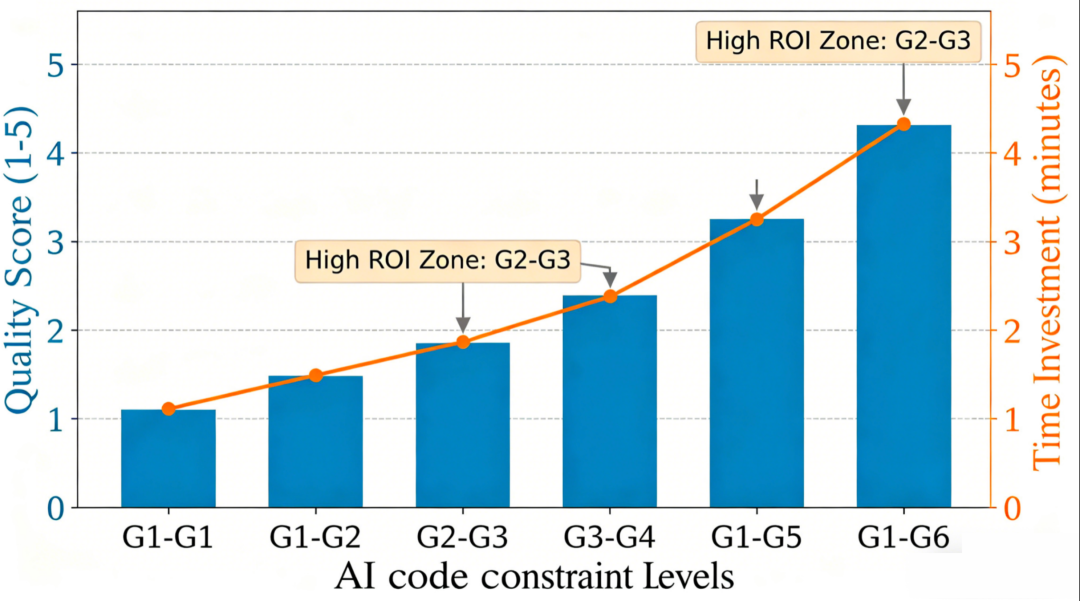
1.4 扩展
对比结论:G1"看起来好"但"不能用",G6"看起来普通"但"直接能用"。
举个例子:
作文类型 | AI编码对应 | 特点 |
|---|---|---|
自由作文 | G1:裸需求 | AI自由发挥,可能很华丽但跑题 |
半命题作文 | G2:简单Spec | 有了方向约束,但细节自由 |
命题作文 | G3:完整Spec | 主题、结构、内容都有明确要求 |
命题作文+评分标准 | G4:Spec+Checklist | 知道怎么打分,就知道往哪里发力 |
命题作文+模仿风格 | G5:Spec+编码规范 | 有了风格约束 |
命题作文+范文 | G6:Spec+规范+参考代码 | 有了具体模仿对象 |
二、方法论框架:六层约束递进模型
2.1 演进路径全景图
┌─────────────────────────────────────────────────────────────────────┐
│ 六层约束递进模型(G1→G6) │
├─────────────────────────────────────────────────────────────────────┤
│ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ G1 │───→│ G2 │───→│ G3 │───→│ G4 │ │
│ │ 裸需求 │ │ 简单Spec │ │ 完整Spec │ │Checklist │ │
│ └────┬────┘ └────┬────┘ └────┬────┘ └────┬────┘ │
│ │ │ │ │ │
│ ▼ ▼ ▼ ▼ │
│ 自由发挥 结构梳理 规则细化 质量保证 │
│ 1.5分 2.5分 3.5分 3.8分 │
│ │
│ ┌──────────┐ ┌──────────┐ │
│ │ G5 │───→│ G6 │ │
│ │ 编码规范 │ │ 参考代码 │ │
│ └────┬────┘ └────┬────┘ │
│ │ │ │
│ ▼ ▼ │
│ 风格统一 真实参照 │
│ 4.2分 4.5分 │
│ │
└─────────────────────────────────────────────────────────────────────┘2.2 各阶段详细定义
G1:裸需求(基线)
输入:客户原始需求文档原文 + "请用 Java Spring Boot 实现"
不提供:任何结构化信息
验证点:AI在信息极度匮乏时的"自由发挥"能力
典型Prompt:
请根据以下业务需求,用 Java + Spring Boot 实现后端代码:
[粘贴客户原始需求原文,不做任何加工]
请实现完整的后端代码。预期表现:
- ✅ 能"写出来",数据模型、架构都是自由发挥
- ❌ 业务理解有偏差,关键概念可能理解错误
- ❌ 代码风格随机,与团队现有代码冲突
适用场景:快速原型验证、概念验证(PoC)
G2:简单Spec
输入:G1 + 结构化的需求描述(功能列表 + 基本接口 + 简单规则)
新增变量:需求被结构化整理,但不深入细节
验证点:仅做需求结构化整理能提升多少质量
典型Prompt结构:
## 功能概述
实现虚拟商品自动识别和自动发货,替代人工处理流程。
## 处理场景
场景A:0元虚拟商品 → 随普通商品出库时自动无物流发货
场景B:金额>0混合订单 → 自动拆单 + 虚拟部分自动发货
场景C:纯虚拟商品订单 → 自动作废 + 自动无物流发货
## 需要的接口
- 虚拟商品配置管理(CRUD)
- 虚拟商品自动识别
- 自动拆单
- 自动无物流发货
- 处理日志查询
## 识别规则
- 商品名称关键字匹配 + 条码无法识别
- 或商品ID在虚拟商品清单中
## 技术要求
Java 17 + Spring Boot 3.2 + MyBatis-Plus + MySQL与G1的差异:
- ✅ 场景分类清晰(A/B/C三种)
- ✅ 接口列表明确
- ❌ 缺少详细业务规则、异常处理、数据模型
预期改善:功能覆盖度从40%提升至65%
G3:完整Spec
输入:G2 + 详细业务规则 + 数据模型 + 接口定义 + 异常场景 + 验收标准 + 测试用例
新增变量:业务规则深度细化、异常场景覆盖、明确的验收标准
验证点:详细Spec相比简单Spec能提升多少
在G2基础上新增内容:
## 详细业务规则
规则1:虚拟商品识别
条件A:商品名称包含[邮差补款/虚拟赠品/返利/...] 且 商品条码在系统无法匹配
条件B:商品ID存在于虚拟商品清单中
满足A或B即判定为虚拟商品
规则2:场景分流判定
IF 金额=0 且 未转入中台 → 场景A
IF 金额>0 且 已转入中台 且 含普通商品 → 场景B
IF 金额>0 且 已转入中台 且 仅虚拟商品 → 场景C
规则3:拆单规则
原订单拆为普通子订单 + 虚拟子订单
金额按比例拆分...
## 数据模型
新增表:virtual_product_config, virtual_product_process_log
字段定义:[完整DDL]
## 接口详情
每个接口的请求参数、响应格式、错误码
## 异常场景
- 平台API调用失败 → 重试3次 → 标记人工处理
- 拆单异常 → 事务回滚 → 告警
- 已被手动处理 → 检测跳过
- 并发触发 → 分布式锁
## 验收标准
AC1-AC8 逐项列出
## 测试用例
正向TC001-TC006
反向TC101-TC107与G2的差异:
- ✅ 业务规则从"描述性"变为"可执行的伪代码"
- ✅ 新增异常场景覆盖
- ✅ 新增数据模型定义
- ✅ 新增可逐项验证的AC和测试用例
预期改善:业务逻辑准确度从50%跃升至80%
G4:完整Spec + AC / Checklist校验
输入:G3 + 经过Spec质量Checklist逐项校验后修订的Spec
新增变量:Spec本身经过质量审查和补漏
验证点:Spec的"自身质量"对AI输出的影响
Checklist校验会补充的内容:
检查项 | 典型补充内容 |
|---|---|
遗漏的边界条件 | 虚拟商品金额=0但已转入中台的情况如何处理? |
模糊的描述 | "随单完成发货"具体指在哪个环节触发? |
缺失的非功能性需求 | 处理延迟要求、日处理量级、功能开关需求 |
缺失的配置化需求 | 关键字列表需要可动态配置、重试次数可配置 |
缺失的监控/告警需求 | 自动处理成功/失败的统计指标、失败率告警 |
与G3的差异:
- ✅ Spec内容本质相同,但经过系统化校验后更完善
- ✅ 补充了G3中遗漏的边界条件和模糊描述
预期改善:边界条件覆盖更完整,AI的"猜测空间"更小
G5:完整Spec + Checklist校验 + 编码规范
输入:G4 + 项目编码规范文档
新增变量:命名规范、分层规则、日志格式、异常处理模式等技术约束
验证点:编码规范对代码"风格一致性"的提升效果
典型编码规范:
## 编码规范(必须严格遵守)
包路径:com.smartmall.virtual
分层:controller / service / service/impl / mapper / entity / dto / vo
命名:大驼峰类名、小驼峰方法名、动词开头
返回:统一 Result<T>
异常:BusinessException(ErrorCodeEnum),全局捕获
日志:@Slf4j,格式 "[类名.方法名] 描述 - key={}"
注入:@RequiredArgsConstructor,不用 @Autowired
查询:LambdaQueryWrapper
事务:@Transactional(rollbackFor = Exception.class)
注释:公共方法必须Javadoc与G4的差异:
- ✅ 代码的"外观"(命名、格式、分层)符合规范
- ✅ 异常处理和日志的"模式"统一
- ❌ 不知道现有代码具体长什么样,仍可能有微妙差异
预期改善:风格一致性评分从2.5跃升至3.8
G6:完整Spec + Checklist校验 + 编码规范 + 参考代码 + 系统上下文
输入:G5 + 现有项目的参考代码片段 + 系统架构约束
新增变量:真实代码样本 + "已有系统"的边界约束
验证点:参考代码和系统上下文对"像团队写的"的最终提升
新增内容:
## 现有代码参考(请严格模仿此风格)
[Controller / Service / Entity 各一个示例]
## 系统约束
- 使用现有的 Result<T>、BusinessException(不要重新定义)
- 新功能放在 com.smartmall.virtual 包下
- 可注入调用现有的 OrderService、ProductService
- 定时任务用 @Scheduled
- Redis用已配置的 RedisTemplate
- 不要重新实现已有功能与G5的差异:
- ✅ 有真实代码"长什么样"的直觉
- ✅ 知道哪些东西已经存在(不重复造轮子)
- ✅ 代码的"气质"更像同一个团队写的
预期改善:盲审时评审人更难区分AI vs 人工
2.3 各阶段投入产出对比表
阶段 | 输入内容 | 关键增量 | 投入时间 | 综合得分 | 边际收益 | 投资回报率 | 典型应用场景 |
|---|---|---|---|---|---|---|---|
G1 | 原始需求文档 | — | 5分钟 | 1.5 | — | — | PoC快速验证 |
G2 | 简单Spec | 需求结构化 | 30分钟 | 2.5 | +1.0 | ★★★最高 | 内部工具开发 |
G3 | 完整Spec | 规则深度细化 | 2小时 | 3.5 | +1.0 | ★★★高 | 核心业务功能 |
G4 | Checklist校验 | Spec质量保证 | +1小时 | 3.8 | +0.3 | ★递减 | 高可靠性系统 |
G5 | 编码规范 | 技术风格约束 | +30分钟 | 4.2 | +0.4 | ★★跳升 | 团队协作项目 |
G6 | 参考代码 | 真实代码参照 | +1小时 | 4.5 | +0.3 | ★递减 | 企业级系统 |
三、核心洞察:约束悖论
3.1 质量维度权衡分析
约束程度与质量维度的此消彼长关系:
AI自由发挥质量(技术优雅度)
高 ┤ ★ G1 ★ G2 ★ G3 ★ G4 ★ G5 ★ G6
│ ↓ 缓慢下降
低 ┤──────────────────────────────────────────────────────────→ 约束程度
团队风格符合度(可集成性)
高 ┤ ★ G6 ★ G5 ★ G4 ★ G3 ★ G2 ★ G1
│ ↑ 持续上升
低 ┤──────────────────────────────────────────────────────────→ 约束程度
综合生产可用性(最终价值)
高 ┤ ★ G6 ★ G5 ★ G4 ★ G3 ★ G2 ★ G1
│ ↑ 持续上升
低 ┤──────────────────────────────────────────────────────────→ 约束程度3.2 关键拐点识别
拐点 | 阶段 | 特征描述 | 质量跃迁 | 驱动因素 |
|---|---|---|---|---|
T1 | G2→G3 | 业务规则从"描述性"变为"可执行" | 业务正确性大幅提升 | 详细规则定义 |
T2 | G4→G5 | 编码规范的系统性注入 | 风格一致性跳升 | 技术约束明确 |
T3 | G5→G6 | 真实代码参照的引入 | 生产可用性逼近人工水平 | 代码样板间 |
约束悖论三维对比图
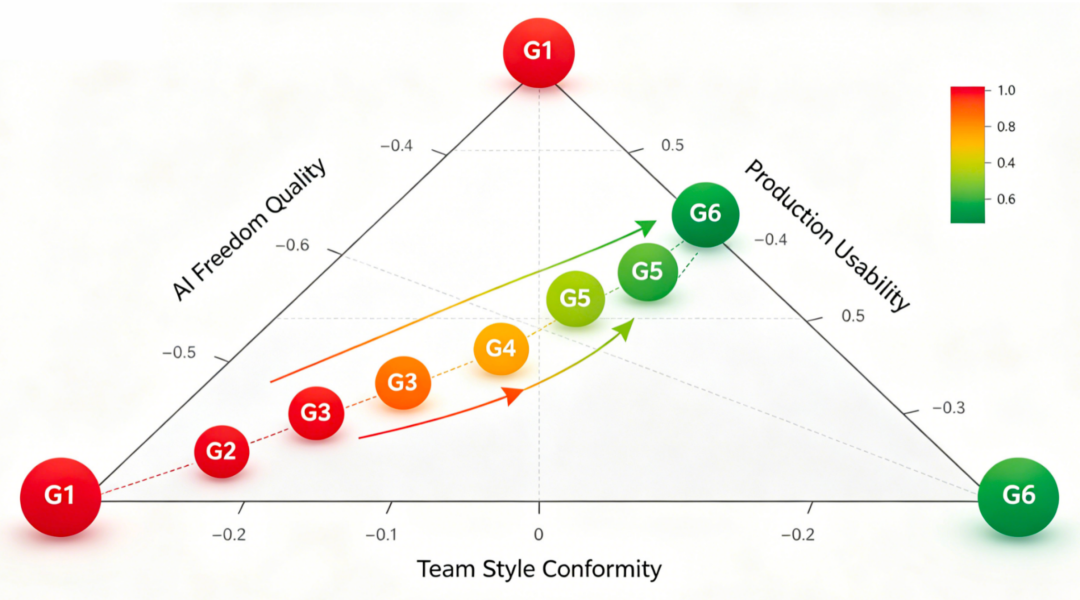
3.3 约束悖论的本质
G1的代码可能很"优雅",甚至用了很优雅的设计模式,但放到客户项目中是不可用的——因为风格不对、架构不对、接口不对。
G6的代码可能看起来"普通",但直接能用——符合团队风格、兼容现有系统、遵循已有模式。
核心观点:"生产可用性"才是最终衡量标准,而非"代码好不好看"。
四、企业实践验证:100+客户数据
4.1 质量维度对比矩阵
评估维度 | G1(裸需求) | G2(简单Spec) | G3(完整Spec) | G4(Checklist) | G5(编码规范) | G6(参考代码) | 趋势 |
|---|---|---|---|---|---|---|---|
代码生成质量 | 3.5 | 3.3 | 3.2 | 3.2 | 3.0 | 3.0 | 缓慢下降 |
团队风格符合度 | 1.0 | 1.5 | 2.0 | 2.2 | 3.8 | 4.5 | 持续上升 |
业务正确性 | 1.5 | 2.5 | 3.8 | 4.2 | 4.2 | 4.3 | G3后显著提升 |
生产可用性 | 0.5 | 1.5 | 3.0 | 3.5 | 3.8 | 4.3 | 持续上升 |
可维护性 | 2.5 | 2.5 | 3.0 | 3.3 | 3.5 | 4.0 | 非线性提升 |
综合得分 | 1.5 | 2.5 | 3.5 | 3.8 | 4.2 | 4.5 | 持续上升 |
4.2 量化指标改善
指标改善趋势(基线=G1)
─────────────────────────────────────────────────────────
人工修改率: >70% → 50% → 30% → 25% → 18% → 12% ↓ 83%
代码可编译率: 60% → 75% → 88% → 90% → 92% → 95% ↑ 58%
业务规则准确度: 30% → 50% → 80% → 88% → 88% → 90% ↑ 200%
风格一致性评分: 1.0 → 1.5 → 2.0 → 2.2 → 3.8 → 4.5 ↑ 350%
功能完整性: 40% → 65% → 85% → 90% → 90% → 92% ↑ 130%
异常处理覆盖: 10% → 25% → 65% → 78% → 78% → 82% ↑ 720%4.3 各维度详细分析
维度一:代码生成质量
不考虑团队约束,单纯看代码本身的技术水平
评分项 | G1表现 | G6表现 | 说明 |
|---|---|---|---|
架构设计合理性 | 高(教科书式) | 中(符合规范) | G1可能用策略模式,G6按团队习惯分层 |
代码简洁度 | 中 | 高 | G6遵循团队简洁原则 |
设计模式运用 | 高(可能滥用) | 中(恰当使用) | G1喜欢用Builder等模式 |
代码可读性 | 中 | 高 | G6命名更符合团队习惯 |
测试完备性 | 低 | 高 | G6按规范生成测试 |
预期趋势:G1 ≈ G2 > G3 ≈ G4 ≈ G5 ≈ G6(约束多了,AI没法自由选择最优方案)
维度二:团队风格符合度
代码"看起来像团队写的"程度
评分项 | G1表现 | G6表现 | 说明 |
|---|---|---|---|
命名风格一致性 | 低 | 高 | G6完全遵循团队命名规范 |
分层架构一致性 | 低 | 高 | G6使用团队标准分层 |
异常处理模式 | 低 | 高 | G6使用团队的BusinessException |
日志格式一致性 | 低 | 高 | G6遵循团队日志格式 |
工具使用一致性 | 低 | 高 | G6使用团队偏好的ORM和工具类 |
预期趋势:G1 < G2 < G3 < G4 < G5 << G6(G5→G6有跳升)
维度三:业务正确性
是否正确理解并实现了业务逻辑
评分项 | G1表现 | G6表现 | 说明 |
|---|---|---|---|
核心流程正确性 | 低 | 高 | G1可能误解业务概念 |
业务规则准确度 | 低 | 高 | G6严格按Spec实现 |
边界条件覆盖 | 低 | 高 | G6覆盖所有边界场景 |
异常场景处理 | 低 | 高 | G6按Spec处理异常 |
业务概念理解 | 低 | 高 | G6正确理解领域概念 |
预期趋势:G1 << G2 < G3 < G4 ≈ G5 ≈ G6(G3是关键拐点)
维度四:生产可用性
代码拿到客户项目中,不改/少改就能用的程度
评分项 | G1表现 | G6表现 | 说明 |
|---|---|---|---|
能否直接编译通过 | 低 | 高 | G6使用团队已有依赖 |
能否直接运行 | 低 | 高 | G6配置正确 |
与现有系统兼容性 | 低 | 高 | G6使用现有公共类 |
人工修改量 | 高 | 低 | G6只需微调 |
数据模型兼容性 | 低 | 高 | G6使用现有表结构 |
预期趋势:G1 << G2 < G3 < G4 < G5 < G6
维度五:可维护性
后续团队成员能否轻松理解和维护这段代码
评分项 | G1表现 | G6表现 | 说明 |
|---|---|---|---|
其他开发者可理解性 | 中 | 高 | G6风格统一,易理解 |
配置化程度 | 低 | 高 | G6业务规则可配置 |
可扩展性 | 高(设计模式) | 高(规范扩展) | 两者各有优势 |
日志可排查性 | 低 | 高 | G6日志规范,易排查 |
监控可观测性 | 低 | 高 | G6包含关键指标监控 |
预期趋势:非线性,G1和G6各有优劣
五、多层物料体系架构
5.1 物料层设计
┌─────────────────────────────────────────────────────────────────┐
│ 多层物料体系 │
├─────────────────────────────────────────────────────────────────┤
│ │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ 任务规格 │ │ 开发规范 │ │ 代码模式 │ │
│ │ (SPEC) │ │ (AGENTS.md) │ │ (样板间) │ │
│ ├──────────────┤ ├──────────────┤ ├──────────────┤ │
│ │ 需求结构化 │ │ 命名/分层 │ │ 文件结构 │ │
│ │ 业务规则 │ │ 日志/异常 │ │ 组件组合 │ │
│ │ 验收标准 │ │ 事务/注入 │ │ 请求封装 │ │
│ │ 测试用例 │ │ 注释要求 │ │ 状态管理 │ │
│ └──────────────┘ └──────────────┘ └──────────────┘ │
│ │ │ │ │
│ ▼ ▼ ▼ │
│ ┌──────────────────────────────────────────────────────┐ │
│ │ 领域知识(MCP动态检索) │ │
│ │ ├─ 物料文档(组件API、用法示例) 60-70% │ │
│ │ ├─ 经验知识(踩坑记录、技术决策) 20-30% │ │
│ │ └─ 开发规范(按域编码规范) 5-10% │ │
│ └──────────────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────────┘5.2 各物料层详细说明
第一层:任务规格(SPEC)
作用:定义"做什么"——本次需求的具体目标、业务规则、验收标准
组成部分:
部分 | 内容 | 说明 |
|---|---|---|
需求来源 | 会议纪要、邮件沟通、用户访谈 | 追溯需求来源 |
用户故事 | 角色-目标-价值 | 描述用户需求 |
验收标准 | AC逐项列出 | 可验证的验收条件 |
业务规则 | 规则描述 | 业务逻辑定义 |
测试用例 | 正向/反向用例 | 验证覆盖 |
交付形式:14份标准Spec文档(参考618促销项目模板)
第二层:开发规范(AGENTS.md)
作用:定义"怎么做"——团队的编码约束和技术规范
组成部分:
部分 | 内容 | 说明 |
|---|---|---|
技术栈版本 | Java 8+, Spring Boot 2.7.18 | 明确版本约束 |
永久红线 | 禁止修改的模块 | 保护核心代码 |
代码规范 | 命名、日志、异常、事务 | 统一编码风格 |
安全规范 | 认证授权、输入校验、限流 | 安全约束 |
加载方式:静态注入,打开仓库时自动加载
第三层:代码模式(样板间)
作用:提供"抄什么"——可复制的代码骨架和组合模式
组成部分:
类型 | 示例 | 说明 |
|---|---|---|
列表页样板间 | index.tsx + Form.tsx + Table.tsx | 标准列表页结构 |
表单页样板间 | Form.tsx + services.ts | 标准表单页结构 |
详情页样板间 | Detail.tsx + services.ts | 标准详情页结构 |
设计原则:两层继承
- 第一层:架构组统一维护工作台级样板间(默认兜底)
- 第二层:域前端负责人可选fork扩展(域特有需求)
第四层:领域知识(MCP动态检索)
作用:填补AI的知识盲区——内部私有组件和平台约束
知识类型占比:
类型 | 占比 | 说明 |
|---|---|---|
物料文档 | 60-70% | 内部组件API、用法示例 |
经验知识 | 20-30% | 踩坑记录、技术决策 |
开发规范 | 5-10% | 按域的编码规范 |
检索场景:
阶段 | 检索内容 | 典型用例 |
|---|---|---|
G3 | 业务知识 | 虚拟商品识别规则 |
G5 | 技术规范 | BusinessException用法 |
G6 | 代码模式 | ProTable cacheKey约束 |
5.3 MCP检索机制
技术实现:Agent通过MCP协议调用knowledge Server按需检索
触发时机:
- 编码过程中遇到具体问题时主动触发
- 如:"ProTable的cacheKey应该怎么设置?"
效果数据:
- 通过"调用率 × 采纳率"优化低效知识条目
- 知识库关联采纳率从18%提升到35%,近翻倍
六、企业落地路线图
6.1 三阶段实施路径
第一阶段:基础建设(4-6周)
┌─────────────────────────────────────────────┐
│ • 建立SPEC模板体系(14份标准模板) │
│ • 定义验收标准和测试用例规范 │
│ • 培训团队掌握Spec编写方法 │
│ • 产出:G1→G3能力 │
│ • 里程碑:代码采纳率达到60% │
└─────────────────────────────────────────────┘
│
▼
第二阶段:规范落地(3-4周)
┌─────────────────────────────────────────────┐
│ • 制定AGENTS.md开发规范 │
│ • 定义编码规范、日志规范、异常处理模式 │
│ • 建立代码审查Checklist │
│ • 产出:G3→G5能力 │
│ • 里程碑:代码采纳率达到80% │
└─────────────────────────────────────────────┘
│
▼
第三阶段:智能检索(6-8周)
┌─────────────────────────────────────────────┐
│ • 搭建MCP知识库服务 │
│ • 沉淀参考代码样板间 │
│ • 建立知识自动沉淀机制 │
│ • 产出:G5→G6能力 │
│ • 里程碑:代码采纳率达到90%+ │
└─────────────────────────────────────────────┘6.2 成功关键指标
指标 | 基线 | 目标 | 衡量方式 | 责任角色 |
|---|---|---|---|---|
Spec覆盖率 | 0% | 100% | 需求到Spec转化率 | 产品经理 |
代码采纳率 | <50% | >90% | AI代码合并行数占比 | 技术负责人 |
人工修改率 | >70% | <15% | git diff统计 | 开发团队 |
盲审正确率 | <30% | >80% | AI代码识别测试 | QA团队 |
编译通过率 | 60% | 95% | CI流水线统计 | DevOps |
6.3 风险与应对
风险 | 概率 | 影响 | 应对措施 |
|---|---|---|---|
团队抵触规范 | 高 | 中 | 培训+正向激励 |
Spec编写耗时 | 中 | 中 | 模板+自动化工具 |
知识沉淀滞后 | 中 | 中 | 自动沉淀机制 |
技术栈变更 | 低 | 高 | 规范版本管理 |
总结
AI编码的质量上限取决于喂给它的物料质量,而非模型本身。通过系统性地增加约束层,我们可以将AI从"自由作文"引导至"命题作文",实现从"看起来好"到"直接能用"的转变。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号