从设计稿到生产代码:小红书如何用多阶段流水线自动化客户端开发

从设计稿到生产代码:小红书如何用多阶段流水线自动化客户端开发

梯度不陡
发布于 2026-05-18 20:26:13
发布于 2026-05-18 20:26:13
📋 论文信息
- • 标题: Production-Grade AI Coding System for Client-Side Development
- • 作者: Ruihan Wang, Chencheng Guo, Guangjing Wang
- • 机构/单位: Shanghai Jiao Tong University, Xiaohongshu
- • 论文链接: https://arxiv.org/abs/2603.01460
- • 发布日期: 2026-03-02
- • 开源地址: 未提供
导读
大语言模型生成代码看起来很美好,但在真实的客户端工程场景中,需求文档(PRD)模糊、设计规范严格、UI框架复杂——现有工具很难产出直接可用的生产级代码。小红书团队的这项工作展示了如何用结构化流水线接管从 Figma 到移动端可编译代码的完整链路,把"一次性生成"变成可审查、可恢复、可增量迭代的工程流程。
实用摘要
- • 问题: 客户端开发的代码生成面临三重挑战:设计和需求文档分离、交互逻辑用自然语言描述不清、平台约束(SwiftUI/Jetpack Compose)严格,现有工具只能做原型,无法直接进生产环境
- • 创新: 用多阶段流水线分解任务——先把 Figma 和 PRD 规范化为中间表示(IR),再提取 UI 组件实体并映射交互逻辑(类似 NER),最后用任务依赖图(DAG)调度增量代码生成
- • 结果: PRD解构准确率 F1=0.848(多模态微调),UI保真度 83%-89%(对比设计稿清单),PRD逻辑落地成功率 75%,在真实小红书工程项目上验证
- • 可借鉴做法:
- • 用中间产物(requirement 文档 + task tree JSON)做 checkpoint,不把规划和执行混在一次 prompt 里
- • 把 PRD 理解视作"UI组件实体识别 + 逻辑绑定"任务,降低自由文本的歧义
- • 用 topological sort 确保 task 执行顺序正确,避免依赖错乱
- • 边界与风险: 评估数据集来自内部项目、无法开源;UI保真度检查清单仍依赖人工终审;大型重构任务(超过当前单屏 UI 修改范围)还需进一步验证
方法拆解
核心思路:用流水线取代端到端生成
系统采用 client-server 架构:
- • Server 端(Node.js + MCP 协议):负责上下文规范化(Context Canonicalization)、任务规划(Task Planning)、执行编排(Execution Orchestration)
- • Client 端(IDE Extension):托管 coding agent,调用 server 工具,对代码库做实际修改
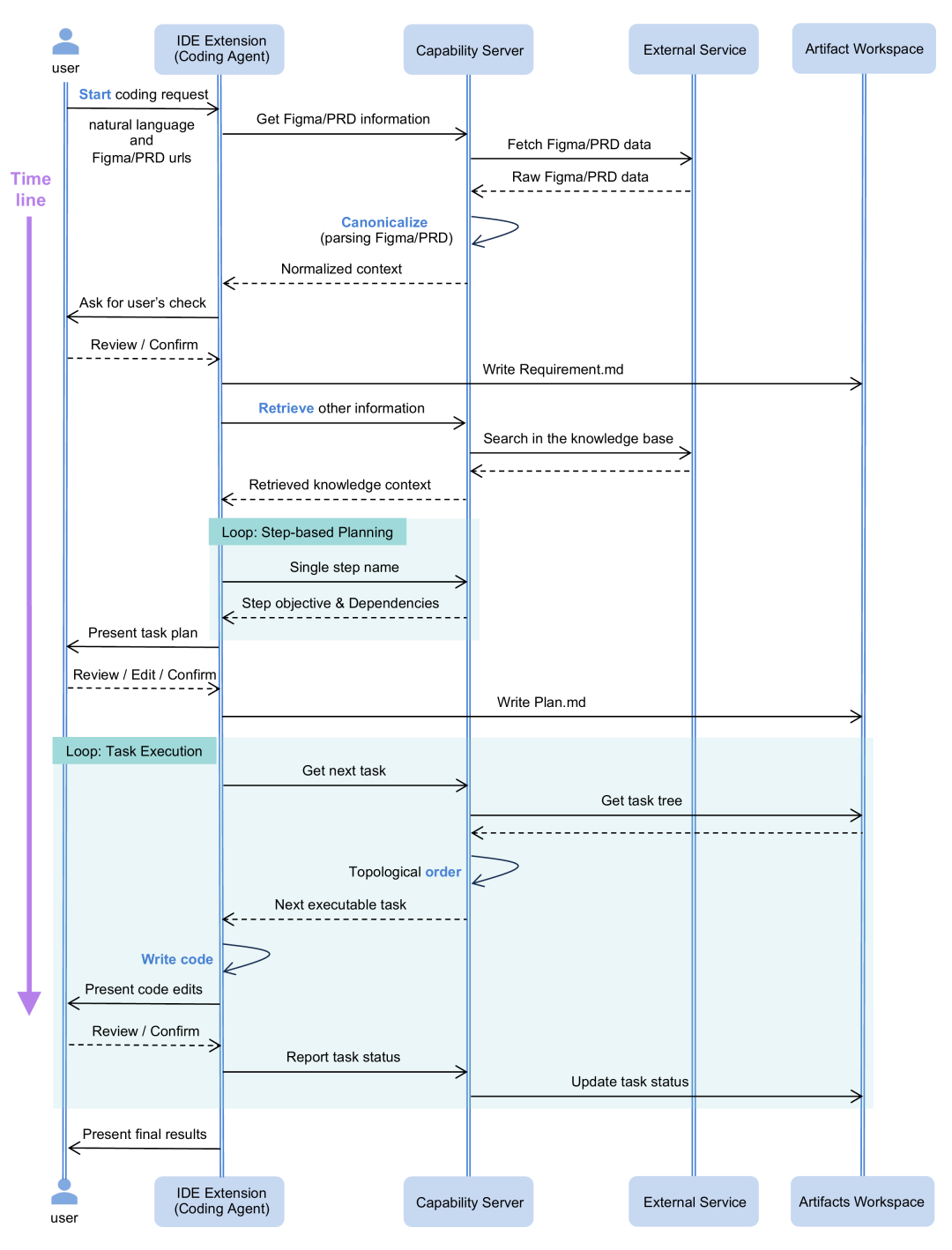
图1:从自然语言输入到代码的完整流水线——每一步产生持久性中间产物,可人工审查和恢复
第一阶段:上下文规范化
输入:Figma URL + PRD 文档 + 内部工程规范 输出:规范化的设计 IR + 逻辑单元列表 + 检索增强上下文
- 1. Figma 规范化
- • 通过 API 获取设计树,转化为"节点层级 + 布局几何 + 样式 token"的中间表示
- • 可选:用 YOLO 检测 UI 渲染图中的元素,辅助展平过深层级或修复结构
- • 产生组件集合(component set),供后续绑定逻辑
- 2. PRD 分解(借鉴 NER 思路)为什么用 NER 思路?
- • 每个逻辑单元锚定到具体组件,减少模糊推理
- • 分类空间可扩展(新业务类型追加新类别)
- • 可独立生成和验证子任务
- • 把 UI 组件视为实体,自然语言描述视为实体上下文
- • 微调 Qwen2.5-VL-72B 模型,从 PRD 中识别 7 类 UI 组件(输入框、按钮、弹窗、列表等)并提取逻辑
- • 输出结构化的
requirement understandingartifact,一次确认后锁定,避免后续隐式改写
- 3. 知识库检索
- • 从内部文档空间(设计规范 + 工程标准)中向量检索相关片段
- • 用 TTL=1h 的缓存降低外部依赖风险
NER 任务 | PRD 分解任务 |
|---|---|
识别实体(人名/地点/机构) | 识别 UI 组件实体(按钮/输入框/列表) |
实体边界(起止位置) | 控制逻辑范围 |
语义关系 | UI 组件交互关系 |
上下文依赖 | UI 组件功能上下文 |
第二阶段:任务规划
设计:有限状态机(FSM)协议,单步单步推进,每步完成才能进入下一步
- • 两种模式:
- • PRD-only 模式:仅生成 requirement understanding 文档就停止,供评审需求
- • Full coding 模式:继续走到 technical planning,产生 Task IR(任务中间表示)
- • 人工卡点(human-in-the-loop checkpoints): 在关键步骤插入确认环节,防止错误假设传播到代码
第三阶段:执行编排
Task IR 结构:
- • 分层任务树(内部节点=语义分组,叶节点=原子任务)
- • 每个任务绑定稳定 ID、自然语言目标、执行上下文、任务类型、状态字段
- • 兄弟任务间用局部 DAG 描述依赖关系,用 Kahn 拓扑排序验证无死锁
调度逻辑: orchestrator 暴露下一个可执行叶任务给 client agent → agent 修改代码 → 报告完成状态 → 写回 Task IR 中断后可从 Task IR 恢复,调度器本身无状态
PRD 分解模型:微调细节
- • 数据集:182 条真实 PRD 样本,8:2 训练/测试拆分
- • Text-only:Alpaca 格式(instruction + input + output)
- • Multi-modal:ShareGPT 格式(嵌入 UI 截图)
- • 模型:Qwen2.5-72B-Instruct(纯文本)+ Qwen2.5-VL-72B-Instruct(多模态)
- • 方法:LoRA 微调(rank=4, lr=1e-4/1e-5, epochs=30, 4×H20 GPU)
- • 分类空间:7 类 UI 组件(见表2)——覆盖完整性、互斥性、实用性三个准则
实验与结果
PRD 分解准确率
模型 | Precision | Recall | F1 |
|---|---|---|---|
Text-only Baseline | 0.506 | 0.685 | 0.568 |
Text-only Fine-tuned | 0.822 | 0.722 | 0.743 |
Multi-modal Baseline | 0.202 | 0.256 | 0.211 |
Multi-modal Fine-tuned | 0.880 | 0.865 | 0.848 |
Multi-modal Fine-tuned (No Image) | 0.808 | 0.732 | 0.751 |
关键发现:
- • 领域微调使 F1 从 0.568 → 0.743(纯文本)、从 0.211 → 0.848(多模态)
- • 视觉信息有效:去掉图片后 F1 降至 0.751,但仍优于纯文本 baseline
- • 多模态基准很弱(F1=0.211)→ 直接用通用视觉模型无法理解 PRD,必须任务微调
UI 保真度评估
在 4 个真实小红书 UI 修改需求上测试(输入:Figma + PRD;输出:可预览的 UI 代码)
方法:工程师用清单逐项检查(页面框架设计、元素约束关系、元素几何、元素样式),记录通过/失败维度
测试用例 | 保真度 | 总检查项 | 失败项 |
|---|---|---|---|
Emoji 搜索 | 89% | 36 | 4 |
好友选择 | 89% | 57 | 6 |
私信设置 | 88% | 34 | 4 |
个人资料弹窗 | 83% | 18 | 3 |
观察:
- • 大多数失败是局部样式问题(错误颜色、行间距略小、不必要的圆角)
- • 页面整体结构和组件类型都正确
- • 说明粗粒度布局和组件选择比较可靠,细节样式还需增强 token 约束

图2:4 个失败项分别为关闭按钮颜色错误、占位文字颜色错误、列表行间距偏小、单元格容器多余圆角——都是可定位的样式细节
PRD 逻辑落地成功率
20 个真实 PRD 逻辑用例(导航、列表交互、状态切换、内容展示规则等),在 human-in-the-loop 设定下生成并评审
- • 15/20 通过(75% 成功率)
- • 所有逻辑代码本身无错,失败主要来自:
- • 未正确检测或应用框架级组件
- • 生成代码中逻辑描述模糊(如文本限行数缺失)
结论:系统能理解 PRD 意图并转译为交互逻辑,失败点在组件定位和细节约束,可通过改进检索/验证缓解
工程实现与复现要点
技术栈
- • Server:TypeScript + Node.js,通过 MCP 协议暴露工具
- • Client:IDE Extension(VSCode + JetBrains),集成 Claude/Gemini 等 LLM
- • 中间产物:JSON + Markdown 持久化到本地工作区
- • 微调平台:内部平台 + 4×H20 GPU,LoRA 微调
关键工程设计
- 1. 分离规划与执行:server 不直接改代码,client agent 才有写权限
- 2. 中间产物序列化:每阶段输出必须可审查、可恢复
- 3. 拓扑排序验证:在规划期暴露依赖死锁,而非执行时崩溃
- 4. 容错设计:缺失可选元数据(如 design variables)不阻塞流水线
- 5. 缓存机制:1 小时 TTL 的知识检索缓存,降低外部服务不可用风险
复现建议
- • 如果要复现 PRD 分解模型:需构造自己的 UI 组件分类体系(根据业务调整 7 类)
- • 如果要复现流水线架构:可参考 MCP 协议规范,自己实现 context canonicalization + planning + orchestration 三级能力
- • 关键点:不要让 LLM 直接从 Figma URL 一步到底,强制产生中间 artifact
趋势判断与影响
从"模型能力"到"系统能力"
- • 现有研究大多聚焦模型本身(Codex、AlphaCode、StarCoder、Code Llama),但生产环境的瓶颈不在模型,而在流程可控性
- • 这篇论文证明:把生成过程拆解为"规范化 → 规划 → 编排"三段流水线,比端到端提示词更可靠
- • 未来方向:模块化中间表示(pluggable taxonomies)、跨领域迁移(web/server/mobile 复用同一套流水线架构)
AI Coding 的"可审计性"
- • 关键洞察:错误恢复成本比初次生成准确率更重要——如果失败后无法定位原因,开发者不会信任工具
- • 持久化 artifact 设计使得每一步决策可追溯,符合企业级软件工程的审计需求
知识图谱 + RAG 的下一步
- • 论文 Future Work 提到:现有 RAG 只检索文档片段,无法理解代码仓库的历史演进和符号依赖
- • 下一代系统可能需要代码库知识图谱(文件→符号→API→依赖关系→版本变更),用图查询替代纯语义检索
结语
这项工作的价值不在于展示"AI 能生成多完美的代码",而在于展示如何让不完美的生成结果也能工程化落地。通过显式中间产物、分阶段规划、拓扑排序编排,小红书把"设计稿 + PRD → 可编译代码"这个高度不确定的任务变成了可控、可审查、可恢复的工程流程。
适用场景:客户端 UI 修改(单屏/多屏)、PRD 驱动的迭代开发、需要严格设计规范对齐的场景 暂不适用:大规模重构、缺乏 Figma 或 PRD 的自由探索开发、跨多端复用(目前聚焦移动端)
如果你的团队正在探索 AI 辅助前端/客户端开发,这篇论文的流水线架构和 PRD 分解思路值得直接借鉴——关键是别让 LLM 一次生成到底,而是用中间产物把不确定性分段管理。
扩展阅读
相关研究
- 1. Design2Code: 多模态代码生成基准测试,包含自动化和人工评估指标(NAACL 2025)
- 2. MetaGPT: 多智能体协作框架,用于软件开发规划设计实现验证流程(ICLR 2024)
- 3. SWE-agent: 通过 RAG + 自动化测试处理 GitHub Issue 的智能体系统
- 4. Blueprint2Code: 多智能体流水线,通过蓝图规划和修复提升代码生成可靠性
技术工具与资源
- • Model Context Protocol (MCP): Anthropic 提出的标准化工具调用协议,本系统用于 client-server 通信
- • Qwen2.5-VL: 阿里通义千问多模态大模型,本文微调用于 PRD 分解
- • YOLO: 实时物体检测模型,用于辅助 Figma 节点提取
- • Kahn 拓扑排序算法: 用于 Task DAG 验证和调度
关键词: #AI代码生成 #客户端开发 #多阶段流水线 #PRD分解 #设计转代码 #工程实践 #生产级系统
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-11,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号