强烈建议安全运维人把这几个核心场景吃透,因为真的能速通


很多人学安全运维,一上来就死磕命令、背概念、刷工具,结果越学越乱。 但真正进了企业环境你会发现,安全运维根本不是“会几个工具”这么简单,而是要能把资产、漏洞、告警、权限、应急这几条线串起来。
下面这几个场景,建议安全运维新人反复看、反复练,因为真的对应日常工作里的高频问题。
1️⃣ 资产梳理|安全运维的第一道生死线
很多安全事故不是因为攻击手法多高级,而是因为企业自己都不知道有哪些资产暴露在外面。
公网 IP、域名、子域名、测试环境、老旧系统、临时开放端口、没人认领的服务器……这些东西一旦没人管,就会变成攻击者最喜欢的突破口。
安全运维里最怕的不是漏洞多,而是漏洞在哪都不知道。 资产台账不清、责任人不明、系统边界混乱,后面做漏洞修复、告警分析、应急响应全都会断层。
💡启发:资产梳理不是 Excel 表格任务!它是安全运维所有工作的起点。没有资产视角,漏洞管理就是盲修,告警研判就是瞎猜,应急响应就是满场救火。

2️⃣ 漏洞管理|不是扫出来就完事,而是闭环到修复
很多新人以为漏洞管理就是跑个扫描器,导出报告,然后丢给业务方。 但真实企业环境里,最难的从来不是“发现漏洞”,而是推动修复。
从漏洞发现、风险评级、影响面确认、责任人定位、修复方案跟进,到复测验证、超期催办、例外备案,全流程缺一环,漏洞都有可能变成真实入口。
尤其是高危漏洞,最怕出现三种情况: 要么没人认领,要么修复延期,要么修完没复测。
💡启发:安全运维里的漏洞管理不是死知识点!重点不是“扫出了多少”,而是“闭环了多少”。真正成熟的漏洞运营,一定是发现、修复、验证、复盘全链路打通。
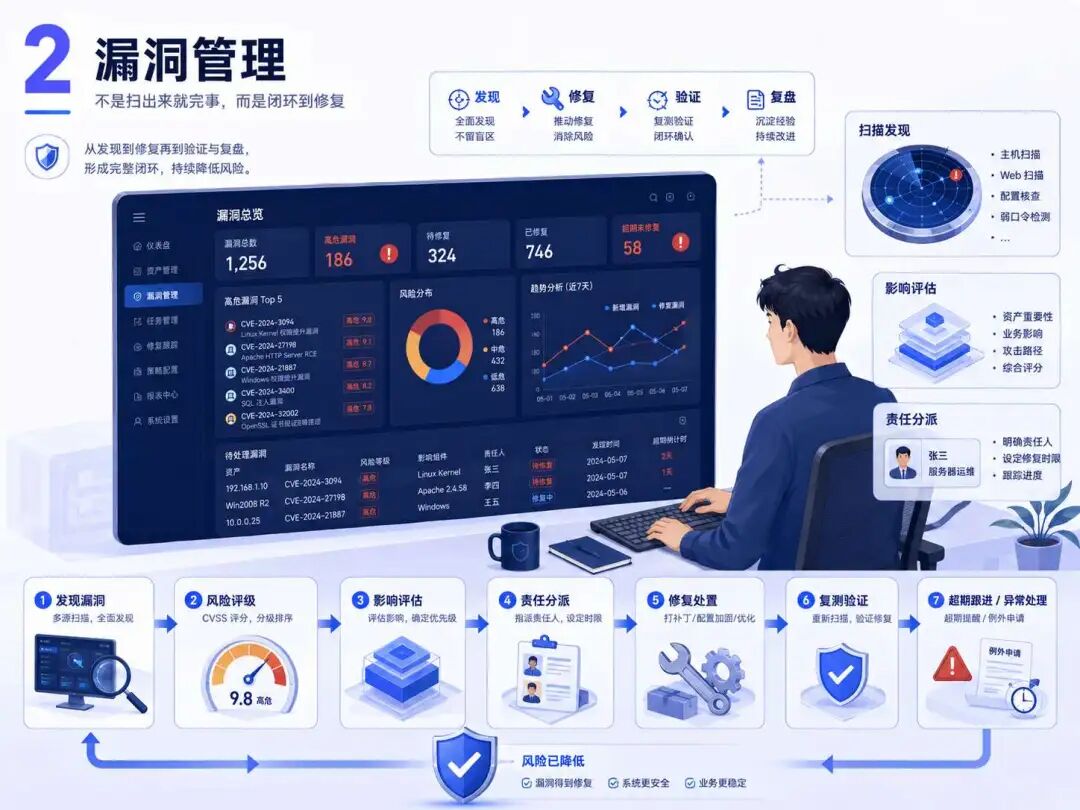
3️⃣ 告警研判|安全运维人的核心基本功
每天一堆告警弹出来,WAF、EDR、IDS、日志平台、态势感知全在响。 新人最容易犯的错就是看见高危就慌,看见低危就忽略。
但真实研判不是看告警等级,而是看上下文。
同样是一次异常登录,普通员工异地登录可能只是出差,但如果叠加深夜访问、异常 UA、敏感系统操作、失败爆破记录,那就可能是账号被盗的前兆。
同样是 Web 攻击告警,如果只有单次探测,可能是扫描器噪音;但如果后面跟着目录爆破、上传接口访问、异常命令回显,那就必须立刻升级处置。
💡启发:告警研判不是看平台红不红!核心是把日志、资产、账号、行为、时间线串起来。安全运维高手和新人的差距,往往就在“能不能从一堆噪音里抓住真正风险”。
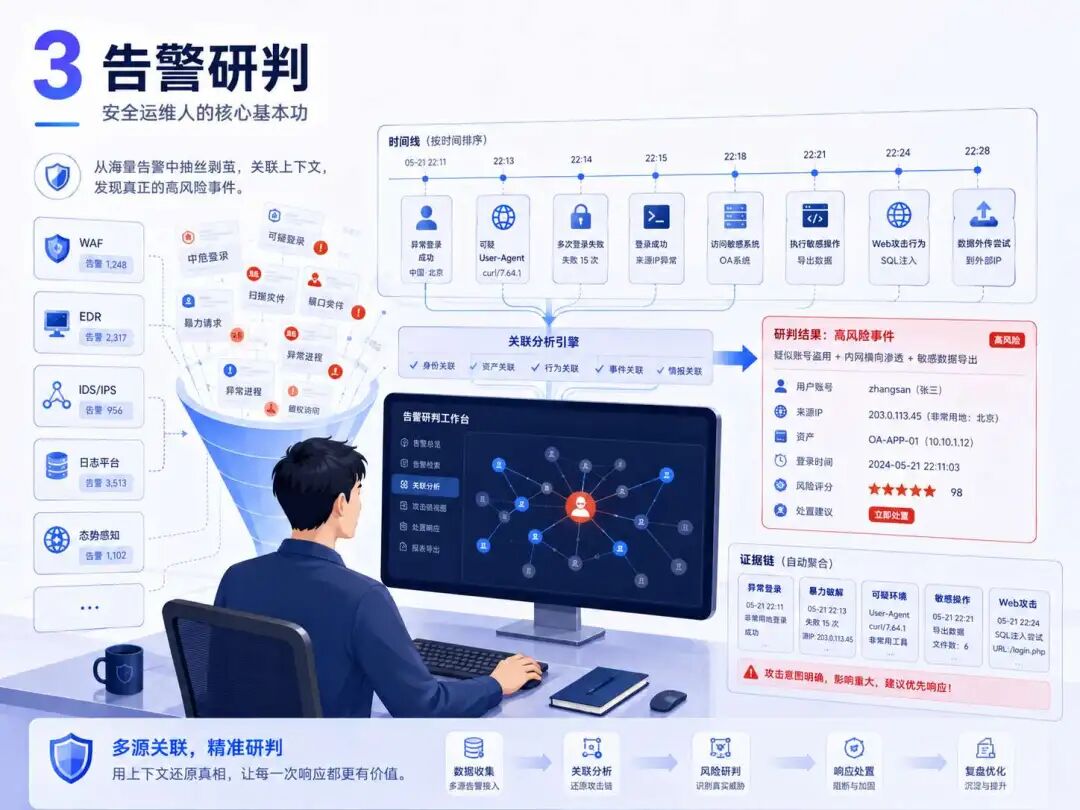
4️⃣ 权限管控|最容易被忽视,也最容易出大事
很多企业被打穿,不一定是边界设备被突破,而是内部权限早就失控了。
离职账号没回收、测试账号长期有效、管理员权限随便分配、数据库账号多人共用、堡垒机绕过、云平台 AK/SK 泄露……这些问题平时看起来不起眼,出事时全是致命点。
权限管理最怕的不是“权限不够”,而是“权限过大还没人知道”。
💡启发:安全运维一定要盯住账号生命周期!入职授权、岗位变更、权限审批、定期审计、离职回收,每一步都不能断。权限管控做不好,再强的边界防护也会被内部失控拖垮。
5️⃣ 应急响应|不是等出事才开始救火
真正的应急响应,不是凌晨被叫醒后才开始翻日志,而是平时就要把预案、日志、权限、工具、联系人全部准备好。
一次完整的应急,至少要能做到: 快速确认攻击入口、判断影响范围、隔离风险主机、保留关键证据、排查横向移动、清理后门账号、修复漏洞根因、输出复盘报告。
很多团队应急失败,不是技术不会,而是流程断了。 要么日志没留够,要么权限拿不到,要么业务不配合,要么处置完没有复盘,最后同一个坑下次继续踩。
💡启发:应急响应不是临场发挥!它考的是平时的安全运营能力。日志留存、资产分组、基线加固、账号审计、漏洞闭环,平时做得越扎实,出事时越不会乱。

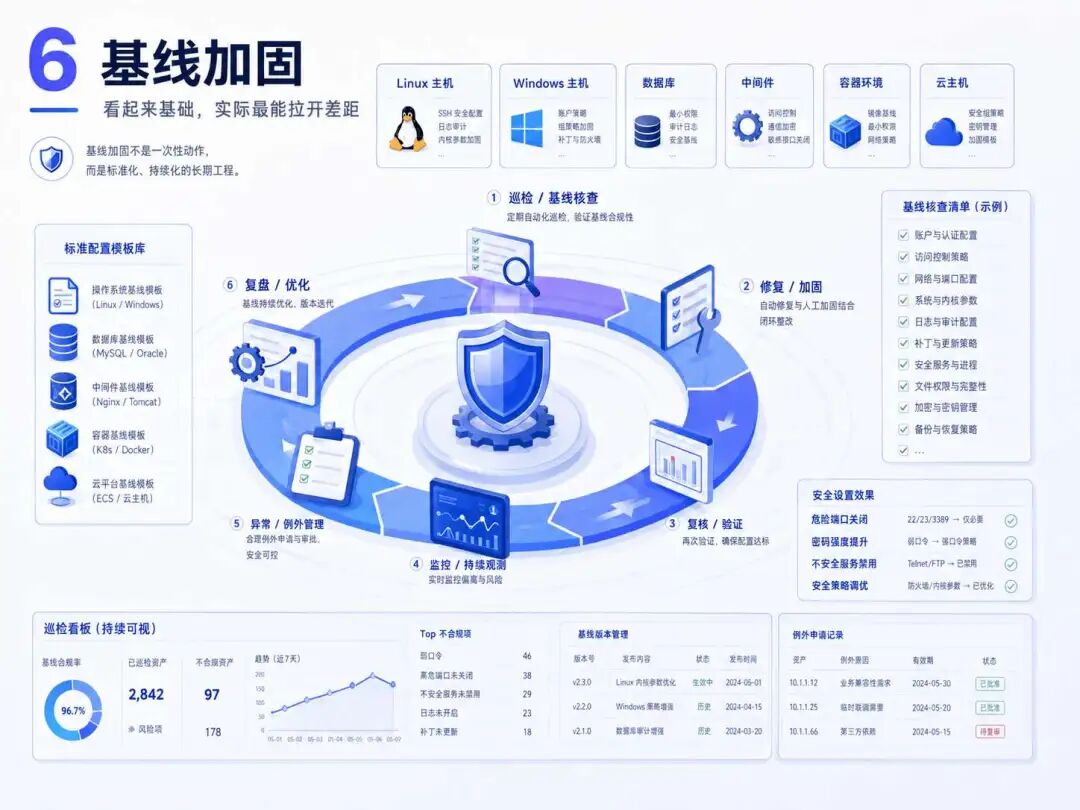
6️⃣ 基线加固|看起来基础,实际最能拉开差距
很多人觉得基线加固很简单,无非就是关端口、改密码、禁服务、调策略。 但企业环境里,基线真正难的是标准化和持续化。
Linux、Windows、数据库、中间件、容器、云主机,每类资产都有不同的加固要求。 如果没有统一模板,没有定期巡检,没有变更记录,没有例外管理,今天刚加固完,明天业务一改配置,风险又回来了。
💡启发:基线加固不是一次性任务!它是安全运维的长期工程。真正有效的基线管理,一定是检查、整改、复核、监控、例外备案持续循环。
安全运维真的不是“看门岗”,更不是只会重启服务、处理工单。 它本质上是在企业复杂业务环境里,持续把风险压下去。
资产看不清,后面全是盲区。 漏洞不闭环,迟早变成入口。 告警不会研判,平台再贵也白搭。 权限不收敛,内部风险一定爆炸。 应急没预案,出事只能靠运气。
所以刚入门安全运维,别只盯着工具学。 先把这几条主线吃透:资产管理、漏洞闭环、告警研判、权限审计、应急响应、基线加固。
这些不是简历上的关键词,而是真正进企业后每天都会遇到的真实战场。 看懂这些,安全运维的学习路线瞬间清晰,面试回答也不会再空洞。
不想错过文章内容?读完请加个“关注”,您的支持是我创作的动力
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号