单细胞转录组之降维聚类分群-回答上周评论区的问题


上周推文评论区中有人提到 ”小编复现的降维聚类图形状和原文长的不一样,没有关系么?您定义的celltype和作者定义的celltype重叠度怎么样呢?“ 这周推文来简要说一下我的看法。
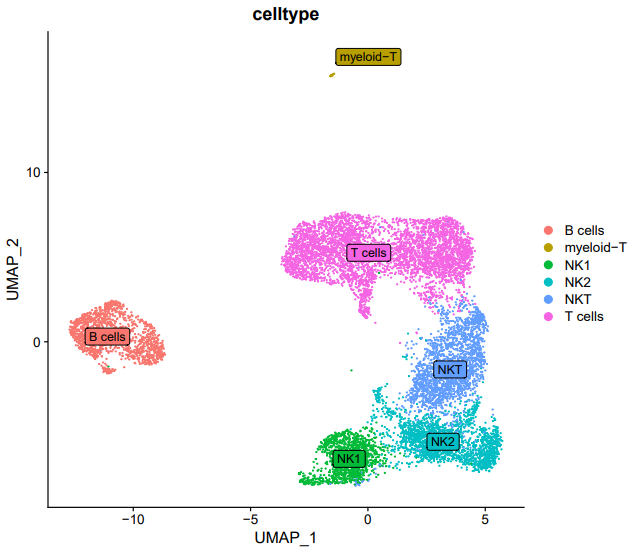
小编复现的图:
文章中的图:
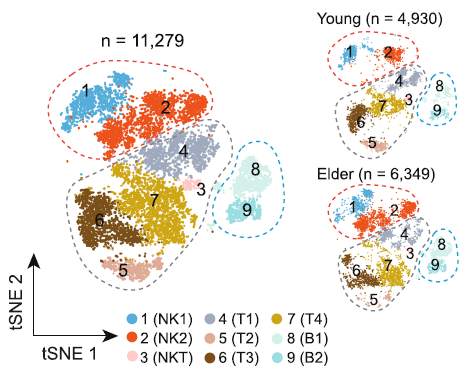
首先对于复现文献中的 umap 图或者 tsne 图和原文长的不一样应该是很正常的。
在我刚开始做单细胞转录组测序的相关分析时,我也有这个疑惑,为什么复现文章中的降维分群与原文形状不一致呢?
基于我针对多篇文章多个数据集的复现发现,有种种原因都会造成这个现象:
- 换台电脑,一样的代码就会使得降维聚类的位置形状都会发生改变。
- 同一数据的UMAP 和 tSNE 图的位置形状肯定也不一样。
- 复现文献只能尽量的按照文献中提到的参数来修改我们的标准代码,然后按照标准代码把流程跑一下。尽量做到和文章一致。
- 文章中用于细胞命名的marker gene与我们所用的也并不一致。我们一般倾向于将细胞命名为常见的几群细胞:髓系,T, B, Fibo, Endo, Epi。当然如果文章中出现一些特定疾病的相关细胞也会找相关marker gene而进行命名。
- 在整合数据时选用harmony还是CCA。文献中使用的CCA, 而我使用的是harmony。之前有推文比较过CCA和harmony的区别。CCA 和 Harmony在整合pbmc3k和pbmc5k的效果比较
再深层次追究可能就是基于降维聚类分群的问题了,之前曾老师写过相关的推文。
- 降维
首先来说做单细胞转录组测序流程中所用的 FindVariableFeatures 和 RunPCA 函数就是两种不同策略的降维。
- FindVariableFeatures:
sce <- FindVariableFeatures(sce, selection.method = "vst", nfeatures = 2000)一般是根据一些统计指标,比如 sd,mad,vst 等来判断输入的单细胞表达矩阵里面的 2 万多个基因里面,选出最重要的 2000 个基因,其余的 1.8 万个基因下游分析就不考虑了。 - RunPCA 函数:
sce <- RunPCA(sce, features = VariableFeatures(object = sce))在跑完之后2000 个基因会转变为 2000 个维度,但是我们通常看前 15/20 个维度就可以了,所以这个也是一个效率非常高的降维方式。
- FindVariableFeatures:
- 聚类 聚类分群往往是根据细胞各个基因表达模式的相似度或者距离来进行聚类的,相似度高或者距离近的就归为一个cluster。而对于单细胞转录组测序的细胞聚类算法有很多种,像KNN、SNN、Louvain算法等等。 曾老师也提到,需要注意的是二维平面空间,三维球体空间的细胞距离很方便计算,但是如果是50个维度的空间,计算几万个细胞之间的距离就很可怕了,如果是2000个维度,甚至是2万个维度,基本上个人计算机就可以放弃了。这就是为什么我们前面通常是需要降维的。
而后就是关于tSNE和UMAP的一些相关知识。
tSNE: 参考这篇推文的介绍单细胞中的流形(一):理解 tSNE中的perplexity
tSNE (t-distributed stochastic neighbor embedding) 是一种非线性降维的算法,是流形学习的一种。参考上述推文曾老师提到以下几点。
- 困惑度(perplexity)可以表示细胞的邻近个数,在tSNE图上的直观反映是细胞点的分布是否紧凑。perplexity设置越大,细胞分布越紧凑。
- tSNE的参数设置:perplexity < (细胞数-1)/3,建议perplexity = 细胞数 / 50;
- tSNE倾向于保留数据的局部结构。
UMAP:参考这篇推文的介绍 单细胞中的流形(二):UMAP与tSNE的区别
UMAP (Uniform manifold approximation and projection) 是一种非线性降维的算法,相对于t-SNE,UMAP算法更加快速,该方法的原理是利用流形学和投影技术,达到降维目的。
- 维度不像PCA的主成分或者非负矩阵分解的因子可解释。只能用于可视化。
- 样本较小时(n < 500),可能效果不好,需要慎重选择参数。
- 局部的聚类效果有时没有tSNE的效果好,相似的细胞分群靠得太近,区分度不高,如果数据质量较差,会影响可视化效果。
- 比tSNE更能反映全局结构,但不代表UMAP是最好的全局结构展示方法。
总结
要想复现的降维聚类图形状和原文一致,影响因素有很多。因此的确可以通过自己定义的celltype和作者定义的celltype重叠度来看,复现出的结果与原文的重合度。但又恰恰很多文章并没有提供相关的数据,因此只能通过尽量保持参数一致来复现。
因此关于我定义的celltype和作者定义的celltype重叠度怎么样这个问题,经过我查找文献中提交到GEO和补充材料的数据,并没有发现作者提交的有关celltype信息的数据,所以可能对比不了。 如有小伙伴找到相关信息的可以留言告知,谢谢。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2022-12-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号