influxDB初识,一个高效的时序数据库


1、什么是InfluxDB
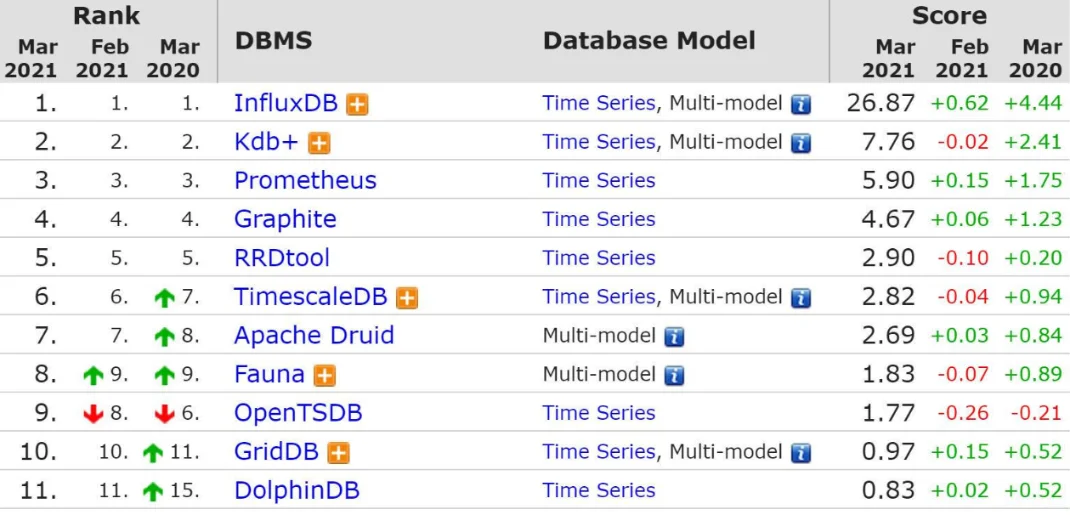
InfluxDB是一个开源的、高性能的时序型数据库,并且在时序型数据库DB-Engines Ranking上排名第一。专门用于收集、存储、处理和可视化时间序列数据的平台。 时间序列数据是按时间顺序索引的数据点序列。数据点通常由同一来源的连续测量组成,用于跟踪随时间的变化。现在更多的企业会通过时序存储和数据分析来获得预测能力和实时决策能力,从而为客户提供更好的使用体验。这意味着底层数据平台需要发展以应对新的工作负载的挑战,以及更多的数据点、数据源、监控维度、控制策略和精度更高的实时响应,对下一代时序中台提出了更高的要求
时间序列数据的示例包括:
- 工业传感器数据
- 服务器性能指标
- 每分钟心跳数
- 大脑的电活动
- 降雨量测量
- 股票价格
2、数据组织
InfluxDB 数据模型将时间序列数据组织到存储桶和测量中。一个桶可以包含多个测量值。测量包含多个标签和字段。
- bucket(存储桶):存储时间序列数据的指定位置。一个桶可以包含多个测量值。也就是类似关系型数据库中的库
- measurement(度量):时间序列数据的逻辑分组。给定测量中的所有点都应具有相同的标签。一个测量包含多个标签和字段。也就是类似关系型数据库中的表
- point(数据端点):通过测量、标签键、标签值、字段键和时间戳来标识的单个数据记录。也就是类似于关系型数据库中的行
- Tags(键值对):其值不同,但不经常更改。标签用于存储每个点的元数据
- - 例如,用于识别数据源(如主机、位置、站点等)的东西。
- field(字段):键值对,其值随时间变化,例如:温度、压力、股票价格等。
- Timestamp(时间戳):与数据关联的时间戳。当存储在磁盘上并查询时,所有数据都按时间排序。

3、应用场景
- 监控和运维:InfluxDB 适用于实时监控和运维数据的存储和查询。它可以用于收集和存储服务器性能指标、网络流量、应用程序性能数据等,便于管理员和开发人员实时监控系统状态、检测异常和进行故障排查。
- 物联网(IoT)和传感器数据:InfluxDB 的高写入性能和优化的存储结构使其成为物联网和传感器数据的理想选择。它可以轻松处理大量传感器产生的数据,并提供快速的查询功能,用于实时数据分析和实时反馈。
- 实时数据分析:时序数据库适用于需要对大量实时数据进行分析和处理的场景。InfluxDB 支持数据的连续写入和高效查询,使其成为实时数据分析的有力工具,例如时序数据的图表展示、异常检测、实时报警等。
- 日志数据:InfluxDB 也可以用于存储和查询日志数据。它支持日志数据的时序化存储,使日志数据按照时间顺序进行组织,方便查询和分析,特别适合在分布式系统和微服务架构中处理大量的日志数据。
- 能源监测:时序数据库可以用于能源监测和管理,例如电力、水、气等能源的数据采集和分析。InfluxDB 可以帮助监测能源的使用情况、趋势和效率,以优化资源利用和降低能源消耗。
- 金融数据:在金融领域,时序数据库可以用于存储和分析金融市场的交易数据、股票价格、货币汇率等时序性数据,为金融决策和交易提供支持。
- 工业自动化:InfluxDB 适用于工业自动化系统中的数据采集和监测,例如工厂生产线的监控数据、设备运行状态、温度和湿度数据等。
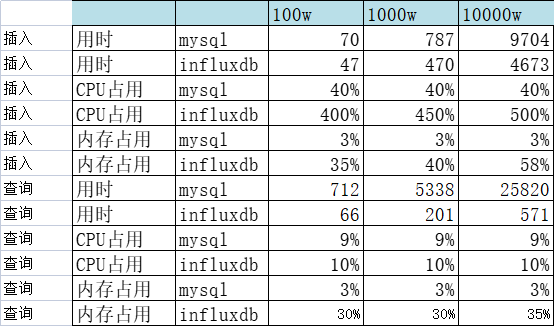
4、与MySQL的性能对比
4.1、单线程插入查询对比
批量插入,每批1万条

配置:
- CPU:16 Intel(R) Xeon(R) Silver 4110 CPU @ 2.10GHz
- 内存:16G
- 磁盘:4T
MySQL: V5.7
InfluxDB: V1.8.0

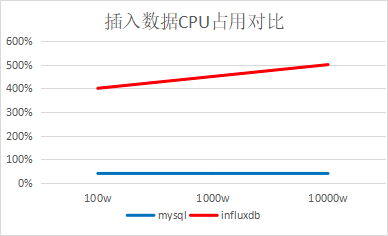
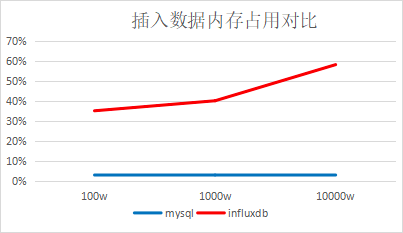
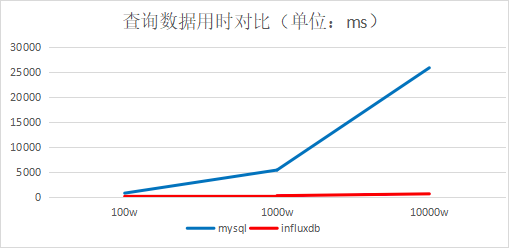


结论:插入速度InfluxDB是MySQL的两倍,查询速度InfluxDB是MySQL的45倍(查询数据量很少的情况,大约1000条左右)
4.2、分别从一亿的表中取一定量数据对比
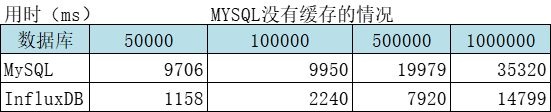
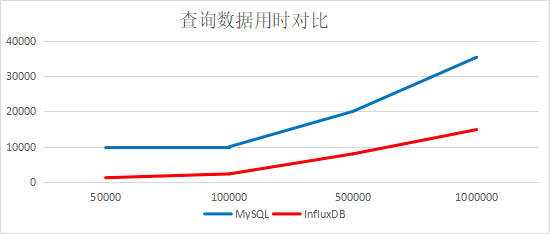
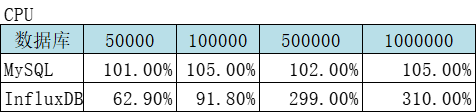

结论:查询速度InfluxDB是MySQL的2倍多
4.3、多个线程分别取十万条数据对比
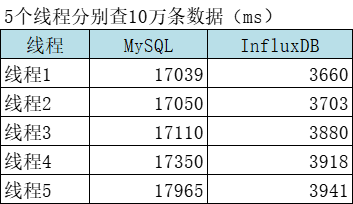

结论:多线程下查询速度InfluxDB是MySQL的4倍
4.4、多个线程分别插入2000万数据

结论:插入速度InfluxDB是MySQL的2倍多
4.5、小结
单线程:
- 写入速度InfluxDB是MySQL的2倍左右
- 查询速度InfluxDB是MySQL的2倍左右
多线程:
- 写入速度InfluxDB是MySQL的2.5倍左右
- 查询速度InfluxDB是MySQL的4倍左右
而写数据的瓶颈在于带宽:
参考文献: https://developer.aliyun.com/article/899126 感谢提供测试参考!
5、安装教程
influxDB支持MacOS、Windows、Linux、Docker等下载安装,本文提供 Docker 版的安装教程,毕竟方便哈哈????。若需要下载其他版本可以到influxDB官方获取。
5.1、到docker hub上获取官方镜像
建议获取2.0版本以上的,自带监控UI。
5.2、运行 InfluxDB v 2.x
用docker run运行 InfluxDB v 2.x Docker 映像。公开端口8086,InfluxDB 使用该端口通过InfluxDB HTTP API进行客户端-服务器通信。
docker run --name influxdb -p 8086:8086 influxdb:2.7.05.3、将数据挂载到本地存储
- 创建一个新目录来存储数据并导航到该目录。
- D:/dockerMountDirectory/influxdb2
- 执行命令
docker run \
--name influxdb \
-p 8086:8086 \
--volume D:/dockerMountDirectory/influxdb2:/var/lib/influxdb2 \
influxdb:2.7.05.4、使用docker-compose构建
也可以把容器的启动信息使用docker compose构建好,下次启动只需要一行命令就可以了
新建 docker-compose.yml
version: '3'
services:
#influxdb服务
influxdb:
container_name: influxdb2.7
image: influxdb:2.7
ports:
- '8086:8086'
restart: always
volumes:
- D:/dockerMountDirectory/influxdb2:/var/lib/influxdb2
- D:/dockerMountDirectory/influxdb2/configs/influxdb.conf:/etc/influxdb2/influxdb.conf
environment:
TZ: "Asia/Shanghai"5.5、启动
安装好后并启动,浏览器输入localhost:8086进入到管理页面
由于我已经创建了账户,所以就直接登录了,一般第一次进来的时候会提示你创建账号和密码,然后登录进到主页面

6、总结
总之,InfluxDB 具备秒级写入百万级时序数据的性能,提供高压缩比低成本存储、预降采样、多维聚合计算、可视化查询结果等功能,解决由设备采集点数量巨大、数据采集频率高造成的存储成本高、写入和查询分析效率低的问题。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2023/07/26 ,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号