Intel 虚拟化技术(Intel® VT):CPU 虚拟化与内存虚拟化

Intel 虚拟化技术(Intel® VT):CPU 虚拟化与内存虚拟化

Flowlet
发布于 2023-08-11 19:29:14
发布于 2023-08-11 19:29:14
1、Intel® VT 虚拟化技术概述

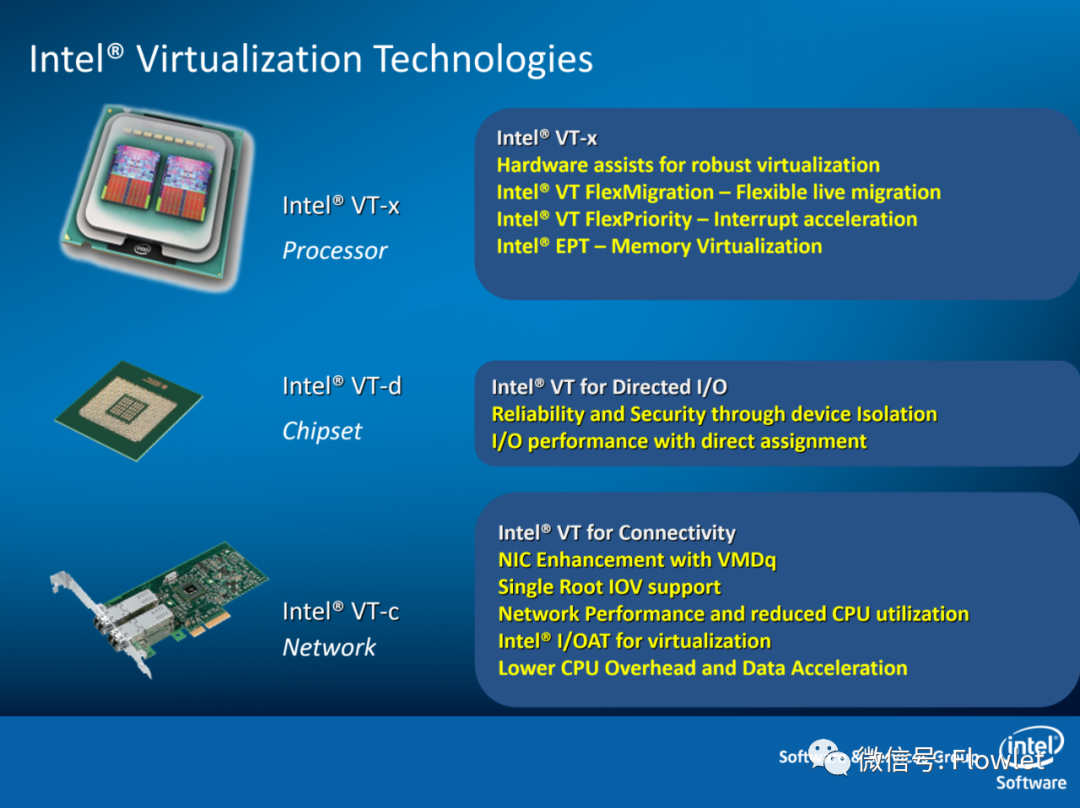
狭义的 Intel® VT 主要提供分别针对处理器、芯片组、网络的虚拟化技术。
- 处理器虚拟化技术(Intel VT-x):包括虚拟化灵活迁移技术(Intel VT FlexMigration)、中断加速技术(Intel VT FlexPriority)、内存虚拟化技术(Intel EPT)
- 芯片组虚拟化技术(Intel VT-d):直接 I/O 访问技术
- I/O 虚拟化技术(Intel VT-c):包括虚拟机设备队列技术(VMDq)、虚拟机直接互连技术(VMDc)、网卡直通技术(SR-IOV/MR-IOV)、数据直接 I/O 技术(DDIO)
2、CPU虚拟化
目前主要的 CPU 虚拟化技术是 Intel 的 VT-x/VT-i 和 AMD 的 AMD-V 这两种技术。
Intel CPU 虚拟化技术主要有 2 类:
- VT-x:用于 X86 架构的的 CPU 虚拟化技术(Intel Virtualization Technologyfor x86),主要是 IA-32 和 Intel 64 系列处理器。
- VT-i:用于安腾(Itanium)架构处理器的 CPU 虚拟化技术(Intel Virtualization Technology for ltanium),主要是 Itanium 系列处理器。
2.1 服务器虚拟化平台
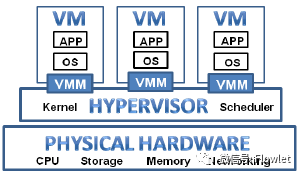
一个完整的服务器虚拟化平台从下到上包括以下几个部分:
- 底层物理资源:包括网卡、CPU、内存、存储设备等硬件资源,一般将包含物理资源的物理机称为宿主机(Host)。
- 虚拟机监控器(Virtual Machine Monitor,VMM):VMM是位于虚拟机与底层硬件设备之间的虚拟层,直接运行于硬件设备之上,负责对硬件资源进行抽象,为上层虚拟机提供运行环境所需资源,并使每个虚拟机都能够互不干扰、相互独立地运行于同一个系统中。
- 抽象化的虚拟机硬件:即虚拟层呈现的虚拟化的硬件设备。虚拟机能够发现哪种硬件设施,完全由 VMM 决定。虚拟设备可以是模拟的真实设备,也可以是现实中并不存在的虚拟设备,如 VMware 的 vmxnet 网卡。
- 虚拟机:相对于底层的物理机,也称为客户机(Guest)。运行在其上的操作系统则称为客户机操作系统(Guest OS)。每个虚拟机操作系统都拥有自己的虚拟硬件,并在一个独立的虚拟环境中执行。通过 VMM 的隔离机制,每个虚拟机都认为自己作为一个独立的系统在运行。
Hypervisor 是位于虚拟机和底层物理硬件之间的虚拟层,包括 boot loader、x86 平台硬件的抽象层,以及内存与 CPU 调度器,负责对运行在其上的多个虚拟机进行资源调度。而 VMM 则是与上层的虚机一一对应的进程,负责对指令集、内存、中断与基本的 I/O 设备进行虚拟化。
当运行一个虚拟机时,Hypervisor 中的 VM kernel 会装载 VMM,虚拟机直接运行于 VMM 之上,并通过 VMM 的接口与 Hypervisor 进行通信。而在 KVM 和 Xen 架构中,虚拟层都称为 Hypervisor,也就是 VMM = Hypervisor。
2.2 CPU 指令分级
现代计算机的 CPU 技术有个核心特点,就是指令分级运行,这样做的目的是为了避免用户应用程序层面的错误导致整个系统的崩溃。
不同类型的 CPU 会分成不同的级别,比如 IBM PowerPC 和 SUN SPARC 分为 Core 与 User 两个级别,MIPS 多了个 Supervisor 共三个级别。

本文针对的 X86 CPU 则分为 Ring0-Ring3 共 4 个级别,我们只需要关注特权级别(Ring 0)和用户级别(Ring1-Ring3)两个层面即可。
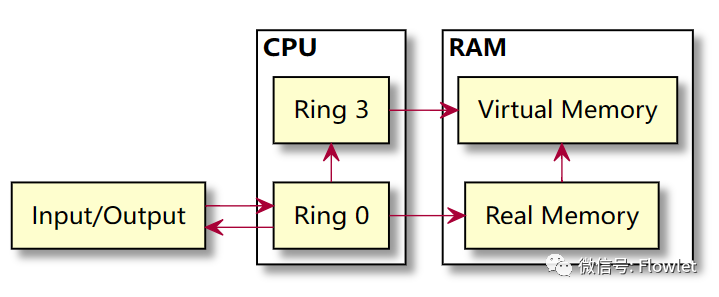
对于非虚拟化的普通操作系统而言,Ring 0 是最高特权级别,拥有对物理内存和硬件 I/O 资源的直接访问控制权。Ring 1、2 和 3 权限依次降低,无法执行操作内核系统级别的指令集合,只拥有对于虚拟内存的直接访问控制权。相应的,运行于 Ring 0 的指令称为“特权指令”;运行于其他级别的称为“非特权指令”。
常见的操作系统如 Linux 与 Windows 都运行于 Ring 0,而用户级应用程序运行于 Ring 3。如果低特权级别的程序执行了特权指令,会引起“陷入”(Trap)内核态,并抛出一个异常。
2.3 非 X86 平台的虚拟化
当这种分层隔离机制应用于虚拟化平台,为了满足 VMM(Virtual Machine Monitor,虚拟机监控器) 的“资源可控”的特征,VMM 必须处于 Ring 0 级别控制所有的硬件资源,并且执行最高特权系统调用。而虚拟机操作系统 Guest OS 则要被降级运行在 Ring 1 级别,Guest OS 的应用程序则运行在 Ring 3。
故 Guest OS 在执行特权指令时都会引起”陷入“。如果 VMM 能够正常捕获异常,模拟 Guest OS 发出的指令并执行,就达到了目的,这就是 IBM 的 Power 系列所采用的特权解除和陷入模拟的机制。
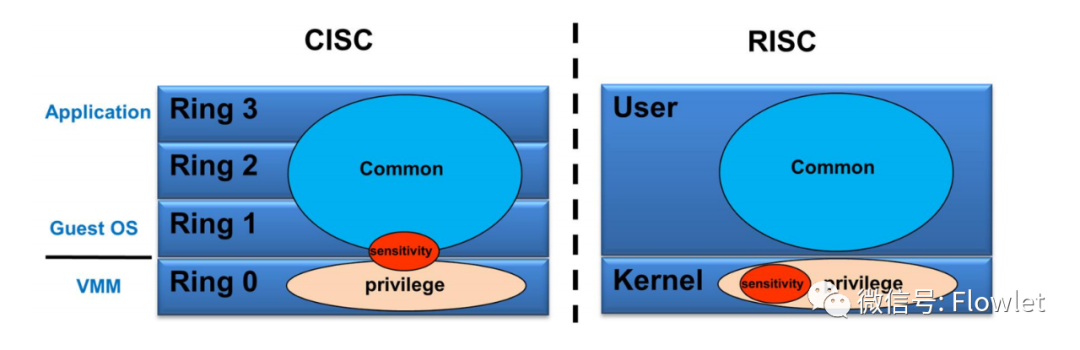
我们将操作系统中涉及系统底层公共资源调用的一些运行指令成为敏感指令。大型服务器如 PowerPC 和 SPARC 架构的 CPU 运行在 RISC 指令集中,所有的敏感指令都属于特权指令。因此可以采用上面所说的特权解除和陷入模拟的机制完美的进行虚拟化实现。
但对于 X86 架构的 CISC 指令集而言,存在 19 条非特权指令的敏感指令,这些指令被 Guest OS 在 Ring1 级别执行时,会被直接执行,无法产生异常从而陷入 Ring0 处理,也就导致无法采用上面所说的经典技术进行虚拟化。
2.4 X86 平台的虚拟化
正是因为 x86 平台指令集有上述缺陷,所以为了计算虚拟化技术在 x86 平台应用,各大虚拟化厂商推出了五花八门的虚拟化技术,其目的都是围绕“如何捕获模拟这 19 条敏感指令”这一命题来设计。
在上述问题中,涉及到 3 个主要的对象,Guest OS、VMM 和硬件 CPU 的指令集,其中 VMM 是新插入的对象,修改起来最方便,但 OS 和 CPU 改起来就难一些。解决方案的思路也由此分为 3 个方向:
- 改动 VMM:即 CPU 全虚拟化(CPU Full-Virtualization),优点是兼容性最强,OS 和 CPU 都无需改动,缺点是效率最低。
- 改动 OS:即 CPU 半虚拟化(CPU Para-Virtualization),优点是相较于 CPU Full-Virtualization 效率有较大的提升,缺点是要改动 OS,因为 Windows 内核并不开源,只能基于 Linux 内核进行适配,而且会带来扩展性与安全性方面的隐患。
- 改动 CPU 指令集:即硬件辅助虚拟化(HVM:Hardware-assisted Virtualization Machine),优点是无需改动 Guest OS,兼容 Windows 与 Linux。
HVM(Hardware-assisted Virtualization Machine,硬件辅助虚拟化)已成为数据中心主流虚拟化技术。
2.4.1 CPU 全虚拟化
CPU 全虚拟化,又被细分为 Emulation、Scan-and-Patch 和 Binary Translation 三种方案。其中 Emulation 是根本解决方案,而 Scan-and-Patch 和 Binary Translation 可以理解为是 Emulation 在 X86 体系上使用的扩展实现方案。
CPU Full-Virtualization 由于实现较为简单,早在上世纪末就已经出现,是最早期的 X86 虚拟化技术。
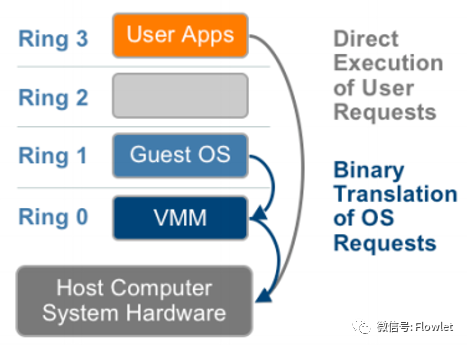
- Emulation:基本的 Emulation 主要应用在进行跨平台虚拟化模拟,Guest OS 与底层系统平台不同,尤其是指令集区别很大的场景,比如在 X86 系统上模拟 PowerPC 或 ARM 系统。其主要思路就是 VMM 将 Guest OS 指令进行读取,模拟出此指令的执行效果返回,周而复始逐条执行,不区分用户指令和敏感指令,由于每条指令都被通过模拟陷入到 Ring0 了,因此也就可以解决之前的敏感指令问题。 代表产品就是 Linux 上的 QEMU,目前主要应用于在嵌入式平台的相关开发领域。
- Scan-and-Patch:Scan-and-Patch 的主思路是将 Guest OS 的每个指令段在执行前先扫描一遍,找出敏感指令,在 VMM 中生成对应的补丁指令,同时将敏感指令替换为跳转指令,指向生成的补丁指令。这样当指令段执行到此跳转时会由 VMM 运行补丁指令模拟出结果返回给 Guest OS,然后再顺序继续执行。 代表产品是 Oracle 的开源虚拟化系统 VirtualBox,目前主要应用于在主机上进行虚拟机的模拟,服务器使用较少。
- Binary Translation:Binary Translation 主要思路是将 Guest OS 的指令段在执行之前进行整段翻译,将其中的敏感指令替换为 Ring0 中执行的对应特权指令,然后在执行的同时翻译下一节指令段,交叉处理。 代表产品为 VMware Workstation 以及早期 VMware 的 ESXi 系列服务器虚拟化系统,目前的服务器上已经很少使用了。
CPU Full-Virtualization 受性能影响,在服务器上目前被逐渐淘汰。主要代表产品如 VirtualBox 和 VMware Workstation 大都应用于主机虚拟化的一些开发测试环境中。只有 QEMU 作为基础虚拟化技术工具,在其他的虚拟化产品中被广泛使用。
2.4.2 CPU 半虚拟化
CPU Para-Virtualization 以 Xen 和 Hyper-V 为代表,但 VMware 的 ESXi Server 和 Linux 的 KVM 两种当前主流虚拟化产品也都支持 Para-Virtualization,Para-Virtualization 技术实际上是一类技术总称,下面先要谈的是 CPU 的 Para-Virtualization (CPU PV)。
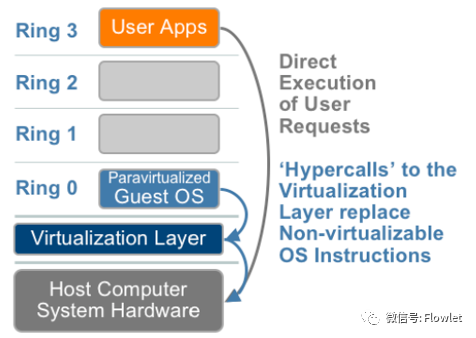
CPU PV 技术实现的主要原理如下,首先 VMM 公布其一些称为 Hypercalls 的接口函数出来,然后在 Guest os 中增加根据这些接口函数修改内核中的代码以替代有问题的 17 条敏感指令执行系统调用操作。修改后的指令调用通常被称为 Hypercalls,Guest OS 可以通过 Hypercalls 直接调用 VMM 进行系统指令执行,相比较前面提到的陷入模拟方式极大的提升了处理效率。
然而 CPU PV 修改操作系统内核代码的方式带来了对 Guest OS 的很多使用限制,如只有 Hyper-V 可以支持 Para-Virtualization 方式的 Windows Server 作为 Guest OS,另外由于 KVM/Xen/VMware/Hyper-V 各自 Hypercalls 代码进入 Linux 内核版本不同,因此采用 Linux 作为 Guest OS 时也必须关注各个发行版的 Linux 内核版本情况。
虚拟化平台 | Linux Kernel(Guest OS)版本要求 |
|---|---|
KVM | Kernel >= 2.6.20 |
VMware | Kernel >= 2.6.22 |
Xen | Kernel >= 2.6.23 |
Hyper-V | Kernel >= 2.6.32 |
CPU PV 方式由于对 Guest OS 的限制,应用范围并不很广,但由于其技术上的系统调用效率提升,仍然被部分开发与使用者所看好,在某些特定场景中也存在一定需求。
2.4.3 硬件辅助虚拟化(Intel VT-x/VT-i 技术)
比尔搞不定,安迪来帮忙。(比尔·盖茨是微软公司创始人,安迪·葛洛夫是 Intel 公司创始人)

针对敏感指令引发的一系列虚拟化问题,2005 年 Intel 与 AMD 公司分别推出了 VT-x/VT-i 与 AMD-V,能够在芯片级别支持全虚拟化时,这就是现在称之为的硬件辅助虚拟化技术(HVM:Hardware-assisted Virtualization Machine)。
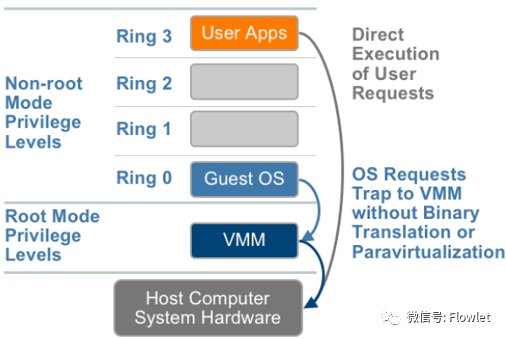
VT-x 与 AMD-V 都试图通过定义新的运行模式,使 Guest OS 恢复到 Ring 0,而让 VMM 运行在比 Ring 0 低的级别(可以理解为Ring -1)。
VT-x 引入了两种操作模式,统称为 VMX(Virtual Machine eXtension)操作模式:
- 根操作模式(VMX Root Operation):VMM 运行所处的模式,以下简称根模式。
- 非根操作模式(VMX Non-Root Operation):客户机运行所处的模式,以下简称非根模式。
Root/Non-Root 操作模式将原有的 CPU 操作区分为 VMM 所在的 Root 操作与 VM 所在的 Non-Root 操作,每个操作都拥有 Ring0-Ring3 的所有指令级别。
在 Intel 公司的 VT-x 解决方案中,运行于非根模式下的 Guest OS 可以像在非虚拟化平台下一样运行于 Ring 0 级别,无论是 Ring 0 发出的特权指令还是 Ring 3 发出的敏感指令都会被陷入到根模式的虚拟层。
VT-x 和 AMD-V 等技术的出现,解决了前面两种纯软件方案进行 X86 虚拟化时,CPU Full-Virtualization 性能低和 Para-Virtualization 的 Guest OS 兼容性差问题。
随着服务器 CPU 两三年一换代的更新速度,当前的主流 X86 服务器已经都可以支持 VT-X/AMD-V 等技术因此 HVM 成为当前云计算 IAAS 服务器虚拟化的主流。主要的几款 VMM 产品 Xen/VMware ESXi/KVM/Hyper-V 都已经能够支持 HVM 功能。
3、内存虚拟化
大型操作系统(比如 Linux)的都是通过虚拟内存进行内存管理,内存虚拟化需要对虚拟内存再进行虚拟化。
内存虚拟化技术主要包含两个方面:内存地址转换和内存虚拟化管理。
关于虚拟内存的相关内容大家可以查看 计算机系统 Lecture 1:虚拟内存 这篇文章。
3.1 内存虚拟化地址转换
在 Linux 这种使用虚拟地址的 OS 中,虚拟地址经过 Page table 转换可得到物理地址。
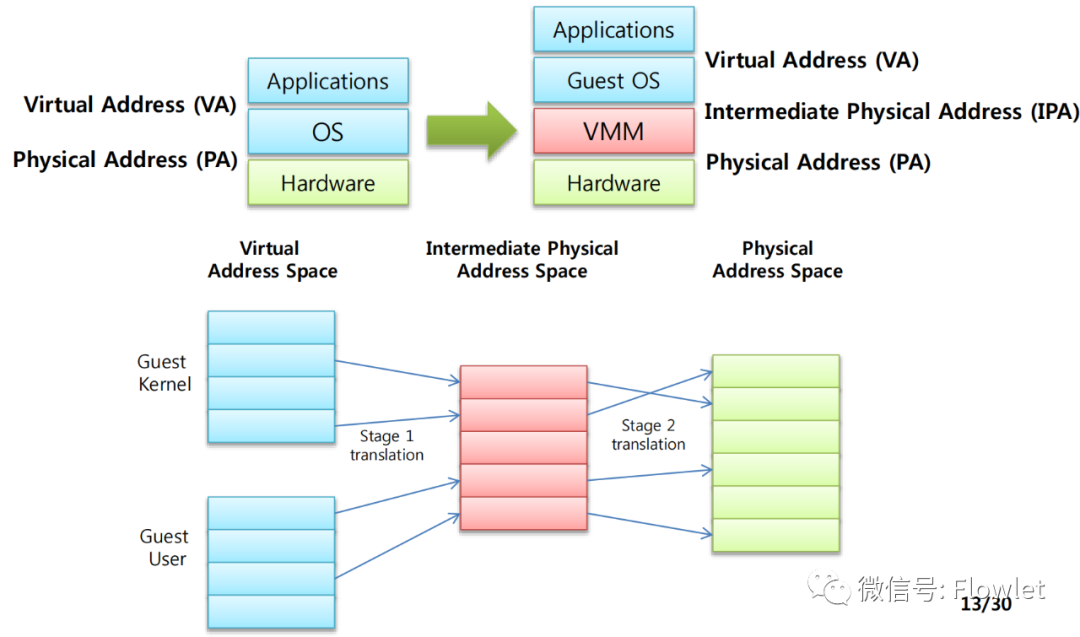
如果这个操作系统运行在虚拟机上,就需要进行两次地址转换。
Guest OS 先将 GVA(Guest Virtual Address)转换为 GPA(Guest Phyical Address),从 VMM/Hypervisor 的角度来看 GPA 是一个中间的物理地址(Intermediate Phyical Address,IPA),然后 VMM/hypervisor 再将 GPA(Guest Phyical Address)转换为 HPA(Host Phyical Address)。
为了实现上述映射和转换关系,主要有两种解决方案:软件解决方案(影子页表)和硬件辅助方案(Intel-EPT 和 AMD-RVI)。
3.1.1 影子页表(SPT)
影子页表(Shadow Page Table,SPT)包括以下两种映射关系:
- GVA -> GPA,虚拟机操作系统负责维护从虚拟机逻辑地址到虚拟机物理地址的映射关系,VMM 可以从虚拟机主页表中获取这种映射关系。
- GPA -> HPA,VMM 负责维护从虚拟机物理地址到物理机物理地址的映射关系。
通过这种两级映射的方式,VMM 为 Guest OS 的每个页表(Guest Page Table,GPT)维护一个影子页表,并将 GVA -> HPA 的映射关系写入影子页表。然后,VMM 将影子页表写入 MMU。同时,又对虚拟机可访问的内存边界进行了有效控制。并且,使用 TLB 缓存影子页表的内容可以大大提高虚拟机问内存的速度。
影子页表的维护将带来时间和空间上的较大开销:
- 时间开销:主要体现在 Guest OS 构造页表时不会主动通知 VMM,VMM 必须等到 Guest OS 发生缺页错误时(必须 Guest OS 要更新主页表),才会分析缺页原因再为其补全影子页表。
- 空间开销:主要体现在 VMM 需要支持多台虚拟机同时运行,每台虚拟机的 Guest OS 通常会为其上运行的每个进程创建一套页表系统,因此影子页表的空间开销会随着进程数量的增多而迅速增大。
为权衡时间开销和空间开销,现在一般采用影子页表缓存(Shadow Page Table Cache)技术,即 VMM 在内存中维护部分最近使用过的影子页表,只有当影子页表在缓存中找不到时,才构建一个新的影子页表。
当前主要的虚拟化技术都采用了影子页表缓存技术。
3.1.2 硬件辅助(Intel EPT/AMD RVI)
为了解决影子页表导致的上述开销问题,除了使用影子页表缓存技术外(这项技术虽然能避免时间上的一部分开销,但是空间开销还是实实在在存在的),Intel 与 AMD 公司都针对 MMU 虚拟化给出了各自的解决方案:Intel 公司在Nehalem 微架构 CPU 中推出扩展页表(Extended Page Table,EPT)技术;AMD 公司在四核皓龙 CPU 中推出快速虚拟化索引(Rapid Virtualization Index,RVI)技术。
RVI 与 EPT 尽管在具体实现细节上有所不同,但是在设计理念上却完全一致:通过在物理 MMU 中保存两个不同的页表,使得内存地址的两次映射都在硬件中完成,进而达到提高性能的目的。
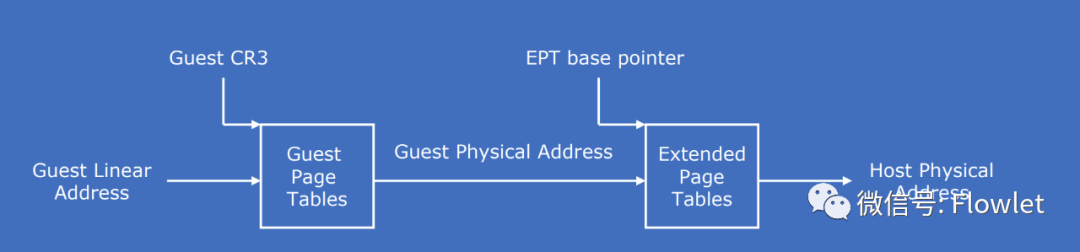
具体来说,MMU 中管理管理了两个页表,第一个是 GVA -> GPA,由虚拟机决定;第二个是 GPA -> HPA,对虚拟机透明,由 VMM 决定。根据这两个映射页表,CPU 中的 page walker 就可以生成最近访问过 key-value 键值对 ,并缓存在TLB中(类似影子页表缓存技术思路)。
另外,原来在影子页表中由 VMM 维持的 GPA -> HPA映射关系,则由一组新的数据结构扩展页表(Extended Page Table,也称为 Nested Page Table)来保存。由于 GPA -> HPA 的映射关系非常定,并在虚拟机创建或修改页表时无需更新,因此 VMM 在虚拟机更新页表的时候无需进行干涉。VMM 也无需参与到虚拟机上下文切换,虚拟机可以自己修改 GVA -> GPA的页表。
Intel EPT 是Intel VT-x 提供的内存虚拟化支持技术,其基本原理下图所示。在原有的 CR3 页表地址映射的基础上,EPT 引入 EPT 页表来实现另一次映射。比如:假设客户机页表和 EPT 页表都是 4 级页表,CPU 完成一次地址转换的基本过程如下:

客户机 CR3 寄存器给出的是 GPA,所以,CP U通过 EPT 页表将客户机 CR3 中的 GPA 转换为 HPA:CPU 首先查找 EPT TLB,如果没有相应的记录,就进一步查找 EPT 页表,如果还没有,CPU 则抛出 EPT Violation 异常交给 VMM 处理。
CPU 获得 L4 页表地址(指的是HPA)后,CPU 根据 GVA 和 L4 页表项的内容来获取 L3 页表项的 GPA。如果 L4 页表中 GVA 对应的表项显示为“缺页”,那么 CPU 产生 Page Fault,直接交由客户机操作系统处理。获得 L3 页表项的GPA 后,CPU 通过查询 EPT 页表来将 L3 的 GPA 转换为 HPA。同理,CPU 会依次完成 L2、L1 页表的查询,获得 GVA 所对应的 GPA,然后进行最后一次查询 EPT 页表获得 HPA。
正如上图所示,CPU 需要 5 次查询 EPT 页表,每次查询都需要 4 次内存访问。这样,在最坏的情况下总共需要 20 次内存访问。EPT 硬件通过增大 EPT TLB 尽量减少内存访问。
3.2 内存虚拟化管理技术
在虚拟化环境中,内存是保证虚拟机工作性能的关键因素。如何尽可能提高虚拟机的性能、提高内存利用率、降低虚拟机上下文切换的内存开销,依然非常复杂,这就引入了内存虚拟化管理的问题。
3.2.1 内存复用技术
在虚拟化内存管理 上,ESXi实现了主机内存超分配的目标:即多个虚拟机总的内存分配量大于物理机的实际内存容量。如下图所示,一个物理内存只有 4GB 的 Host,可以同时运行三个内存配置为 2GB 的 Guest。
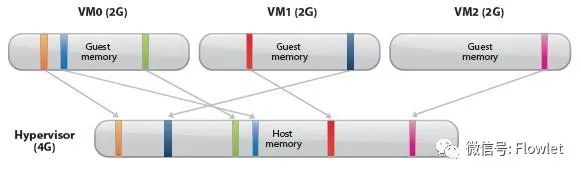
主机内存超分配功能意味着 VMM 必须能够有效地回收虚拟机中不断释放的内存,并在有限的内存容量中尽能 地提高内存利用率。
因为,Host Memory 与 Guest Memory 并不是一一对应的关系,通过 Host Memory 超配技术可以实现某一个 Host 上某一个虚拟机内存大于主机内存,这一点与 CPU 虚拟化不一样。但是,在执行超配技术时,需要考虑主机性能问题,不能过大。一般的超配限额是主机内存的 50%。要实现主机内存超配,必须通过内存复用技术实现。
目前常用的内存复用技术有:零页共享技术、内存气球回收技术和内存置换技术三种,我们这里主要介绍内存气球回收技术。
3.2.2 内存气球回收技术
内存气球回收技术也称为内存气泡技术。在虚拟化环境中,VMM 会一次性在虚拟机启动后分配给虚拟机内存,由于虚拟机并没有意识到自己运行于虚拟化平台上,之后它会一直运行在分配好的内存空间,而不主动释放分配的物理内存给其他虚拟机。因此 VMM 需要一种机制使得虚拟机能够主动释放空闲内存归还给物理机,再由 VMM 分配给其他有需求的虚拟机。并且,在内存资源需求紧张时还能从物理机中“拿回”自己释放的那部分内存。
原理如下:Hypervisor 通过利用预装在用户虚拟机中的前端驱动程序,“偷取” Guest OS 的内存贡献给 VMM,以供其他虚拟机使用,反向时由 VMM “偷取”气泡中的内存给特定虚拟机使用。内存气泡本质是将较为空闲的虚拟机内存释放给内存使用率较高的虚拟机,从而提升内存利用率。
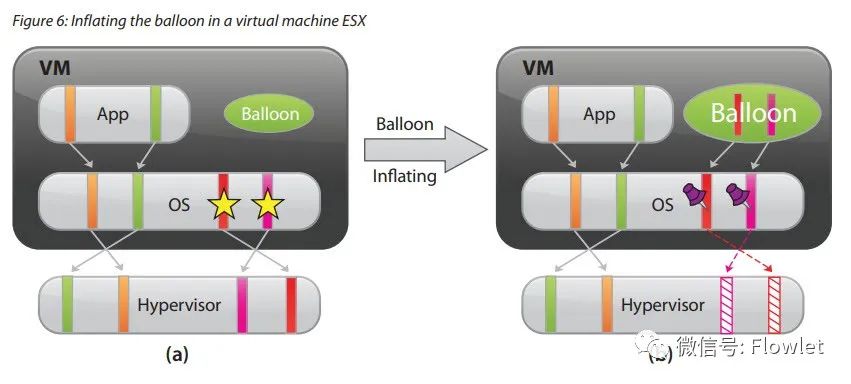
在上图(a)中,VMM 有四个页面被映射到虚拟机的内存页面空间中,其中左侧两个页面被应用程序占用,而另两个被打上星号的页面则是在内存空闲列表中。
当 VMM 要从虚拟机中回收内存时,比如要回收两个内存页面,VMM 就会将 Balloon 驱动的目标膨胀大小设置为两个页面。
Balloon 驱动获得了目标膨胀值之后,就会在虚拟机内部申请两个页面空间的内存,并如上图(b)所示,调用虚拟机操系统的接口标示这两个页面被“钉住”,即不能再被分配出去。
内存申请完毕后,Balloon 驱动会通知 VMM 这两个页面的页号,这样 VMM 就可以找到相应的物理页号并进行回收。在上(b)中虚线就标示了这两个页面从虚拟机分配出去的状态。
由于被释放的页面在释放前已经在虚拟机的空闲列表中,因此没有进程会对该页面进行读写操作。如果虚拟机的进程接下来要重新访问这些页面,那么 VMM 可以像平常分配内存一样,再分配新的物理内存给这台虚拟机。当 VMM 决定收缩气球膨胀大小时,通过设置更小的目标膨胀值,balloon 驱动会将已经被“钉住” 的页面归还给虚拟机。
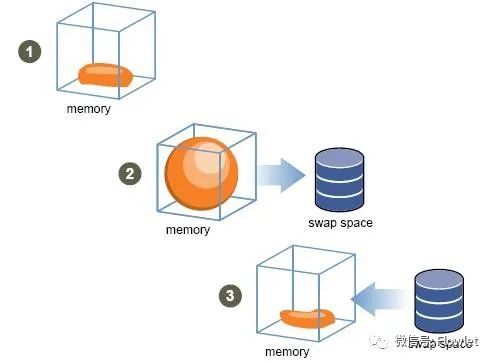
通过气球回收法,尽管虚拟机的负载略微增加,但 VMM 却成功地将系统内存压力转移到各个虚拟机上。当 balloon 驱动发起申请内存的请求时,由虚拟机操作系统决定了是否要将虚拟机物理内存换出来满足 balloon 驱动的申请内存请求。
如果虚拟机有充足的空闲内存,那么 balloon 驱动申请内存并不会对虚拟机的性能造成影响;
如果虚拟机内存已经吃紧,那么就需要由虚拟机的操作系统决定换出哪些内存页面,满足 balloon 驱动的请求。因此,气球回收法巧妙地利用了各个虚拟机操作系统的内存换页机制来确定哪些页面要被释放给物理机,而不是由 VMM 来决定。
气球回收法要求虚拟机操作系统必须安装 balloon 驱动,在 VMware 的 ESXi 产品中,就是 VMware Tool。另外,气球回收法回收内存需要一段时间,不能马上满足系统的需求。
(正文完)
end
Reference:
- Intel® Virtualization Technology (Intel® VT)
- Intel® Virtualization Technology
- CPU硬件辅助虚拟化技术
- Overview of the Intel VT Virtualization Features
- 从半空看虚拟化
- Cloud Operating Systems
- NFV关键技术:计算虚拟化概述
- Intel/AMD virtualization isolation and containment
- NFV关键技术:计算虚拟化之内存虚拟化
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-08-04,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号