Model deployment for Triton

Model deployment for Triton

iResearch666
发布于 2023-09-13 14:11:36
发布于 2023-09-13 14:11:36
Triton Inference Server and Client
Deploy/Server
常见的模型部署方式有以下几种
- 服务器端部署:模型推理服务部署在服务器上,从而进行高性能完成推理任务;
- 边缘设备端部署:模型部署在手机或者其他端侧设备,利用端侧算力完成推理任务;
- 云端部署:模型部署在云端提供线上服务,用户可以使用客户端发送数据和请求,云端响应请求,完成推理任务并返回推理结果;
- Web 端部署:模型部署在网页端,网页端完成推理任务;
常见的模型服务化工具如下图所示,主要分为三大类:
- 第一类:通过WEB框架封装AI模型提供服务,如:Sanic、Flask、Tornado等。
- 第二类:使用深度学习框架自带的Serving封装。如:TensorFlow Serving、TorchServe、MindSpore Serving等。
- 第三类:支持多种框架的统一推理服务化工具。如:Triton Inference Server、BentoML等。

image-20230803175337347

image-20230802170341739
Triton features
NVIDIA Triton Inference Server提供了针对NVIDIA GPU优化的云推理解决方案。服务器通过HTTP或GRPC端点提供推理服务,从而允许远程客户端为服务器管理的任何模型请求推理。对于边缘部署,Triton Server也可以作为带有API的共享库使用,该API允许将服务器的全部功能直接包含在应用程序中。
Triton的主要功能有支持大模型推理、具备高吞吐量和高可扩展性、支持使用模型分析器优化模型配置等等。
- 多框架支持(Multiple framework support)
- 管理任意数量和混合方式的模型;(受系统磁盘和内存资源限制)
- 支持TensorRT, TensorFlow GraphDef, TensorFlow SavedModel, ONNX, PyTorch,Caffe2 NetDef模型;
- 支持TensorFlow-TensorRT 和 ONNX-TensorRT整合模型;
- 在框架和模型支持下,server同时支持可变大小的输入和输出;
- 参见Capabilities模块
- 模型并行支持(Concurrent model execution support)
- 多模型可同时在一块GPU运行;
- 单模型的多实例可在同一块GPU运行;
- 支持批处理(Batching support)
- 若模型支持批处理,server可接受批次请求并返回批次响应;
- Server还支持多种调度和批处理算法,这些算法将单个推理请求组合在一起以提高推理吞吐量,且调度和批处理对客户端是透明的;
- 一般后端支持(Custom backend support)
- 支持单个模型可以有除了dl框架之外的其他普通后端处理;
- 一般后端可以是任意逻辑,同时会受益于GPU的支持,并行,动态组批次和server所有的其他特性;
- 支持集成(Ensemble support)
- 一个管线(pipeline)可以是一个或多个模型的输入输出之间联结组合;
- 单个请求会触发整个管线的执行;
- 多GPU支持(Multi-GPU support)
- 可以部署在系统所有的GPU上;
- 多模型管理(multiple modes for model management)
- 允许隐式和显式地加载和卸载模型,而无需重新启动服务器;
- 模型仓库
- 可以驻留在本地可访问文件系统(例如NFS),Google Cloud Storage或Amazon S3中;
- 部署
- 可用于任何编排或部署框架(例如Kubernetes)的就绪和活跃性健康端点;
- 指标计算
- GPU利用率,服务的吞吐和延迟;
- c/c++部署
- Triton Server的所有功能可包含在某个应用中;
Triton Inference Server
docker pull nvcr.io/nvidia/tritonserver:<xx.yy>-py3
那么推理服务器有什么特点呢?
- 推理服务器具有超强的计算密度和超高能效的特点。
- 微云网络推理服务器最多可以支持20个推理加速卡,其高效加速应用可以满足不同场景的推理需求。
- 在使用的过程中,推理服务器可以通过发挥架构多核,功耗低的优势,为推理场景构建能效高,功耗低的计算平台。其中推理加速卡的单卡功耗只为70瓦,它能够为服务器的算力加速的同时,还可以带来更优的能效比。
- 推理服务器是当今世界上性能最高的服务器,将在石油勘探、天文探索和自动驾驶领域发挥非常重要的作用。凭借其超高的计算能力,必将加速行业的智能化发展。此外,它还可以通过超强的AI技术使各个行业智能化,从而使智能化遍地开花。
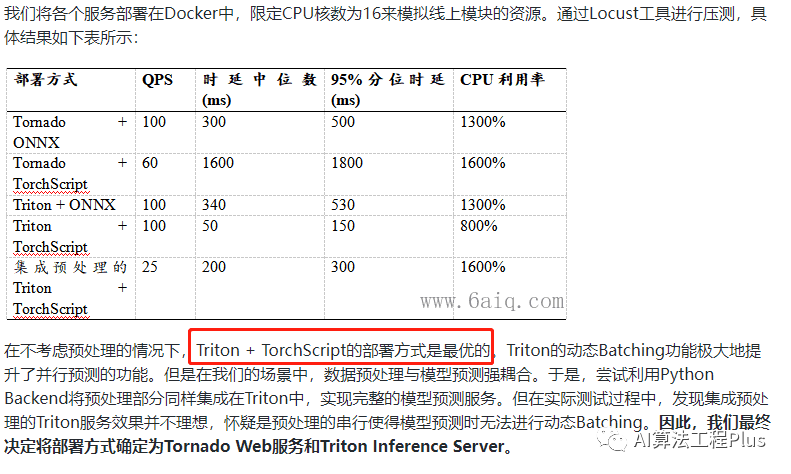
image-20230802171034245
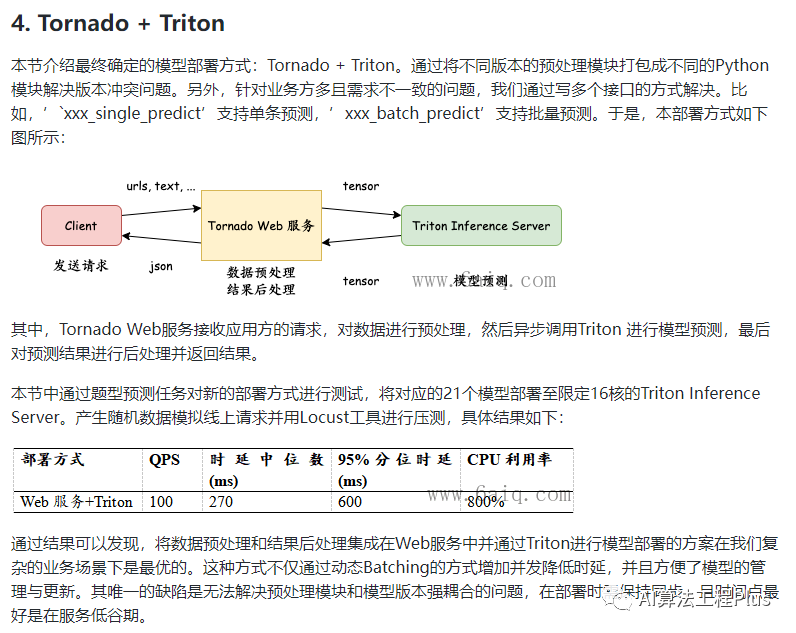
image-20230802171115948
- 动态batching 增加并发,降低延迟
image-20230802171355804
- https://pytorch.org/TensorRT/tutorials/serving_torch_tensorrt_with_triton.html
- https://blog.csdn.net/deaohst/article/details/130978101 yolo on triton
- https://docs.nvidia.com/deeplearning/triton-inference-server/release-notes/rel-23-07.html#rel-23-07 docker
- https://github.com/MAhaitao999/Yolov3_Dynamic_Batch_TensorRT_Triton Yolov3_Dynamic_Batch_TensorRT_Triton
- https://zhuanlan.zhihu.com/p/266733414
- InferBench https://arxiv.org/abs/2011.02327

image-20230803120911437
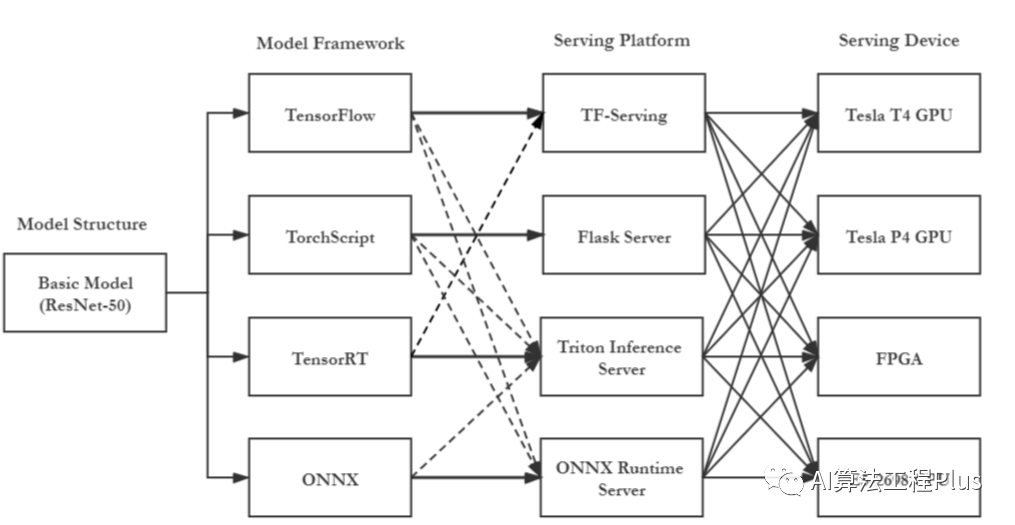
image-20230803120510643
- PyTorch Dynamic Batching
- 结论:大尺寸图像的信息传输是导致tensorrt耗时较长的主要原因,torchserve-gpu底层为java要比我试验时用flask(python)效率要快。当使用小尺寸图像,将耗时主要集中在模型推导时,tensorrt的优势就体现出来了。

image-20230803122110089
- https://github.com/mrdrozdov-github/pytorch-dynamic-batching/blob/master/main.py
- https://pytorch.org/serve/batch_inference_with_ts.html TorchServe dynamic batching
- https://blog.csdn.net/qq_40415753/article/details/120310630
Model Configuration
- https://github.com/triton-inference-server/server/blob/r22.04/docs/model_configuration.md
config.pbtxt
name: "fc_model_pt" # 模型名,也是目录名
platform: "pytorch_libtorch" # 模型对应的平台,本次使用的是torch,不同格式的对应的平台可以在官方文档找到
max_batch_size : 64 # 一次送入模型的最大bsz,防止oom
input [
{
name: "input__0" # 输入名字,对于torch来说名字于代码的名字不需要对应,但必须是<name>__<index>的形式,注意是2个下划线,写错就报错
data_type: TYPE_INT64 # 类型,torch.long对应的就是int64,不同语言的tensor类型与triton类型的对应关系可以在官方文档找到
dims: [ -1 ] # -1 代表是可变维度,虽然输入是二维的,但是默认第一个是bsz,所以只需要写后面的维度就行(无法理解的操作,如果是[-1,-1]调用模型就报错)
}
]
output [
{
name: "output__0" # 命名规范同输入
data_type: TYPE_FP32
dims: [ -1, -1, 4 ]
},
{
name: "output__1"
data_type: TYPE_FP32
dims: [ -1, -1, 8 ]
}
]
输入输出形状
- -1 表示可变
- shape 的 rank >= 1,即不允许 0-dim 向量
- max_batch_size 会和声明的 shape 组成输入
- 不支持 batching 的 backend, max_batch_size 必须为 0
- reshape,可以将 triton 接收的输入变成模型需要的输入。可以将 [batch-size, 1] 变成 [batch-size]。前者的产生是因为 triton 不支持 0-dim 向量,后者是模型需要的。通过设置
reshape: { shape: [] }来去掉多余的维度。 - is_shape_tensor: 看文档的意思,客户端请求的时候,不需要带上 batch 维度,triton 会将 batch 维填充到 shape tensor 前。
- allow_ragged_batch: 输入的向量形状可以不一样
batching
- dynamic_batching,开启 batching
- preferred_batch_size,设置大小,当达到其中一个大小,就马上进行推理
- max_queue_delay_microseconds,batching 的排队等待时间
instance group
- 默认情况下,每个 gpu 都有模型实例,指定 gpu 则不会每个 gpu 都开模型实例。
- Name, Platform and Backend,名字要和文件夹对上,platform 和 backend 取决于后端是否在 triton 的列表中
Required setup
- platform/backend:对于某些模型,两个参数二选一即可,某些模型必须从中选一个指定
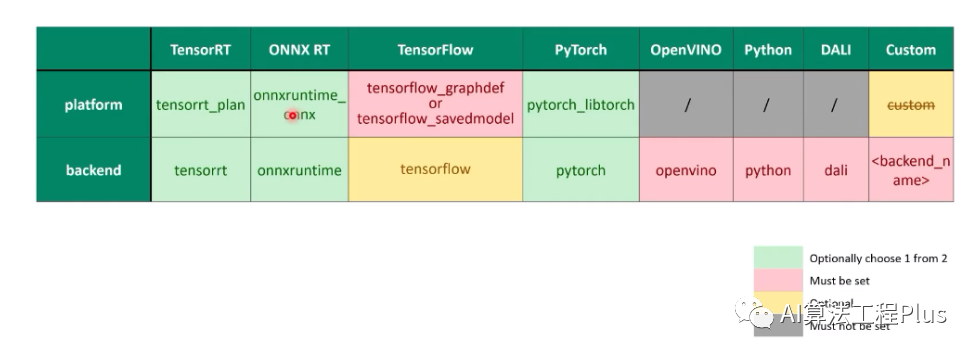
image-20230804095254457
- max batch size: 模型执行推理最大的batch是多少,保证推理服务不会因为爆显存而挂掉
- input and output:指定输入输出名称,特别的,当模型是由TensorRT、Tensorflow、onnx生成的,且设置strict-model-config=false时,可以不需要config.pbtxt文件。配置文件示例说明

在这里插入图片描述
配置1:指定platform:max batch size = 8:注意,若max batch size大于0,默认网络的batch大小可以是动态调整的,在网络输入维度dims参数可以不指定batch大小。输入输出参数:包括名称、数据类型、维度
配置2:指定platform:max batch size = 0:此时,这个维度不支持可变长度,网络输入维度dims参数必须显式指定每个维度的大小,这里也可以设置batch大于0,比如维度[2,3,224,224]。输入输出参数:包括名称、数据类型、维度
配置3:指定platform:pytorch_libtorchmax batch size = 8:这个维度支持可变长度。输入输出参数:包括名称、数据类型、格式、维度。对于pytorch_libtorch的模型,不包含输入输出的具体信息,因此,对于输入输出名称,有特殊的格式:字符串+两个下划线+数字,必须是这种结构。若模型支持可变维度,则可变的维度可以设置为-1。
配置4:reshape应用:max batch size = 0:维度不包含batch维度,但是若模型要求包含这个维度,就可以使用reshape,将其reshape成[1,3,224,224],就可以满足应用需求 可选的配置参数,除上述参数,配置文件中还可以设置其他参数。
version_policy
model repository可以包含多个多个版本模型,因此,在配置文件中可以设定具体执行哪个模型。

请添加图片描述
如上图所示,version_policy可以有3种配置
- All:表示model repository中所有模型都可以加载,若使用该配置,执行的时候model repository中所有模型都会加载。
- Latest:只执行最新的版本,最新指版本数字最大的,若使用该配置,则只选择最新的模型加载。
- Specific:执行指定版本。若使用该配置,需设定指定的版本号,加载时只加载指定的相应版本。
Instance_group
它对应triton一个重要的feature:concurrent model inference,就是在一个Triton server上对同一个模型开启多个execution instance,可以并行的在GPU上执行,从而提高GPU的利用率,增加模型的吞吐。
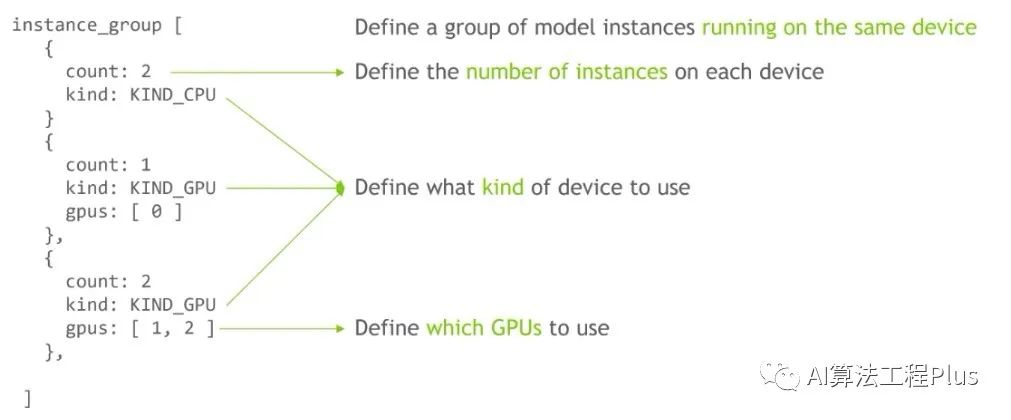
请添加图片描述
- Instance_group:表示运行在同一设备上的一组model instance。count:指定每个设备上的instance数量 kind:定义设备类型,可以是cpu,也可以是GPU gpus:定义使用哪个GPU,若不指定,默认会在每一个GPU上都运行。Instance_group中可以指定多个group 运行在多个设备上。
scheduling and batching
定义Triton应使用哪种调度测量来调度客户端的请求。调度策略也是Triton一个非常重要的feature,它也可以提高GPU的利用率,增加模型的吞吐。因为如果推理的batchsize越大,GPU的利用率越高。Triton有多种调度器:
- default scheduler:默认scheduler,若不对这个参数做设置,则执行默认测量。不做batching,即模型送进来的batch是多少,则推理的batch就设定多少。

请添加图片描述
- dynamic batcher:它可以在服务端将多个batchsize比较小的request组合成一个batchsize大的input tensor,从而提升GPU利用率,增加吞吐。它只对stateless 模型有效,对于streaming视频音频流处理模型不适用(需要使用sequence模型)。

请添加图片描述
- sequence batcher:处理sequence请求。能够保证同一个streaming序列的请求送到同一个model instance执行,从而能够保证model instance的状态。

请添加图片描述
- ensemble scheduler:可以组合不同的模块,形成一个pipeline
optimization policy
- 分别针对onnx和tensorflow模型采用TensorRT优化

请添加图片描述
model warmup
有些模型在刚初始化的短时间内,执行推理时性能是不太稳定的,可能会比较慢,所以需要一个热身的过程使得推理趋于稳定。Triton通过指定model warmup字段去定义热身过程。字段内可以指定batchsize大小、请求是如何生成的,比如随机数生成,还有数据维度、数据类型等。这样,Triton刚刚加载某个模型时候,会向模型发送热身请求。model在warmup过程中,Triton无法对外提供服务,导致模型加载较慢,完成后,client端才能使用模型推理

请添加图片描述
model_warmup [
{
name: "random_input"
batch_size: 1
inputs: {
key: "input__0"
value: {
data_type: TYPE_FP32
dims: [3, 224, 224]
random_data: true
}
}
GPU的第1-2次推理速度常常会比后续的推理速度慢很多
- 编译:在第一次推理之前,GPU需要将神经网络模型编译成可执行的代码。这个编译过程需要一定的时间,因此会导致第一次推理速度慢。
- 数据传输:在第一次推理之前,GPU需要将数据从主内存传输到显存中。这个数据传输的过程同样需要一定的时间。而在后续的推理中,数据已经在显存中,无需再次传输,因此速度更快。
- 缓存:在第一次推理时,GPU缓存中可能还没有相关的数据,需要从显存中读取。而在后续的推理中,相关的数据已经被缓存起来,无需再次从显存中读取,因此速度更快。
总结起来,第一次推理速度慢主要是由于编译过程、数据传输和缓存的原因。在后续的推理中,这些开销被减小或者消除,因此速度会更快。(因为显卡需要warm-up,就是“热身”)
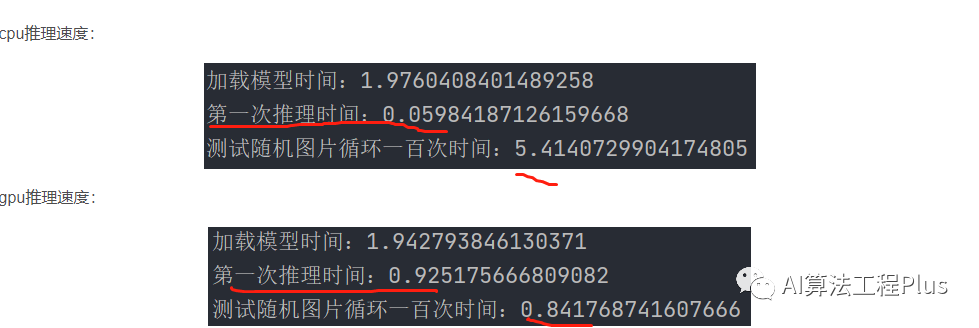
image-20230804102628326
Model Instance
- 在默认情况下,triton会在每个可用的gpu上都部署一个该模型的实例从而实现并行
- 压测命令使用
ab -k -c 5 -n 500 -p ipt.json http://localhost:8000/v2/models/fc_model_pt/versions/1/infer这条命令的意思是5个进程反复调用接口共500次。测试配置及对应的QPS如下: 结论如下:多卡性能有提升;多个实例能进一步提升并发能力;加入CPU会拖累速度,主要是因为CPU速度太慢。 至于选择使用几张卡,则通过创建容器时的--gpus来指定- 共1个卡;每个卡运行1个实例:QPS为603
- 共2个卡;每个卡运行1个实例:QPS为1115
- 共2个卡;每个卡运行2个实例:QPS为1453
- 共2个卡;每个卡运行2个实例;同时在CPU上放2个实例:QPS为972
#共2个卡;每个卡运行2个实例
instance_group [
{
count: 2
kind: KIND_GPU
gpus: [ 0 ]
},
{
count: 2
kind: KIND_GPU
gpus: [ 1 ]
}
]
# 共2个卡;每个卡运行2个实例;同时在CPU上放2个实例
instance_group [
{
count: 2
kind: KIND_GPU
gpus: [ 0 ]
},
{
count: 2
kind: KIND_GPU
gpus: [ 1 ]
},
{
count: 2
kind: KIND_CPU
}
]
将会在 2,3 两张卡上各放置一个模型
instance_group [
{
count: 1
kind: KIND_GPU
gpus: [ 2, 3 ]
}
]
Dynamic Batcher
- https://github.com/triton-inference-server/server/blob/r22.04/docs/model_configuration.md#dynamic-batcher
动态batch的意思是指, 对于一个请求,先不进行推理,等个几毫秒,把这几毫秒的所有请求拼接成一个batch进行推理,这样可以充分利用硬件,提升并行能力,当然缺点就是个别用户等待时间变长,不适合低频次请求的场景。使用动态batch很简单,只需要在config.pbtxt加上dynamic_batching { },具体参数细节大家可以去看文档,我的这种简单写法,组成的bsz上限就是max_batch_size,本人压测的结果是约有50%QPS提升,反正就是有效果就对了。

image-20230804110011029
max batch size
- =0, 表示不支持batch
- 大于0,表示动态batch(batch维度是第一维度,且模型输入和输出都包含batch维度)
它有两个关键参数需要指定:1)preferred_batch_size:期望达到的batchsize大小,可以是一个数,也可以是一个数组,通常会在里面设置多个值。2)max_queue_delay_microseconds:单位是微秒,打batch的时间限制,超过该时间会停止batch,超过该时间会将已打包的batch送走。3)其他高级设置:preserve ordering:确保输出的顺序和请求送进来的顺序一致。priority_level:可以设置优先级, queue policy:设置排队的策略,比如时限超时则停止推理
max_batch_size: 8 # >0
dynamic_batching {
preferred_batch_size: [ 4, 8 ],
max_queue_delay_microseconds: 100,
}
Model Repository
<model-repository-path>/
<model-name>/
[config.pbtxt]
[<output-labels-file> ...]
<version>/
<model-definition-file>
<version>/
<model-definition-file>
...
<model-name>/
[config.pbtxt]
[<output-labels-file> ...]
<version>/
<model-definition-file>
<version>/
<model-definition-file>
...
...
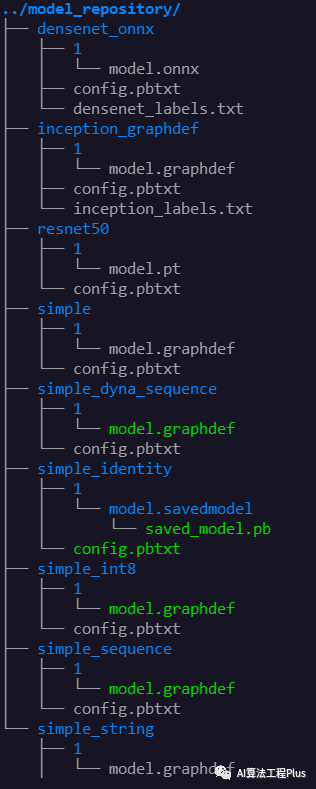
image-20230804103113932
TensorRT Models
<model-repository-path>/
<model-name>/
config.pbtxt
1/
model.plan
ONNX Models
<model-repository-path>/
<model-name>/
config.pbtxt
1/
model.onnx
TorchScript Models
<model-repository-path>/
<model-name>/
config.pbtxt
1/
model.pt
TensorFlow Models
<model-repository-path>/
<model-name>/
config.pbtxt
1/
model.graphdef
Datatypes
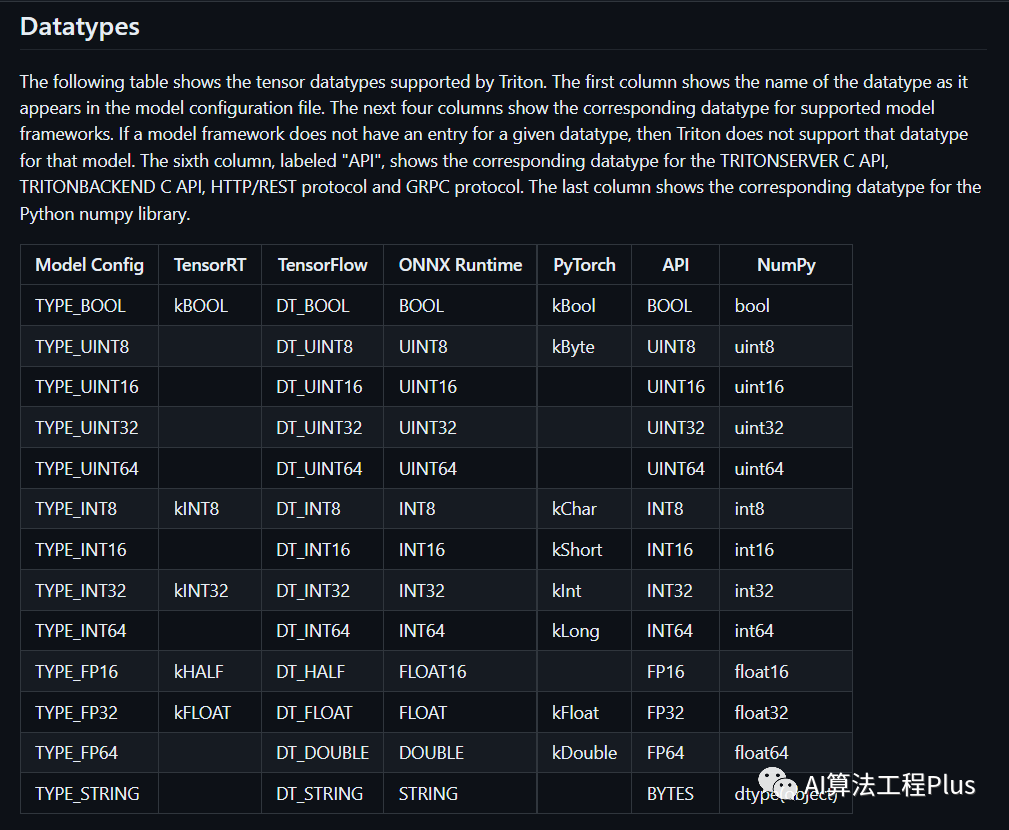
image-20230804110555757
Reshape
- https://github.com/triton-inference-server/server/blob/r22.04/docs/model_configuration.md#reshape
- dim不包括batch这个维度,如果需要batch,可以用reshape
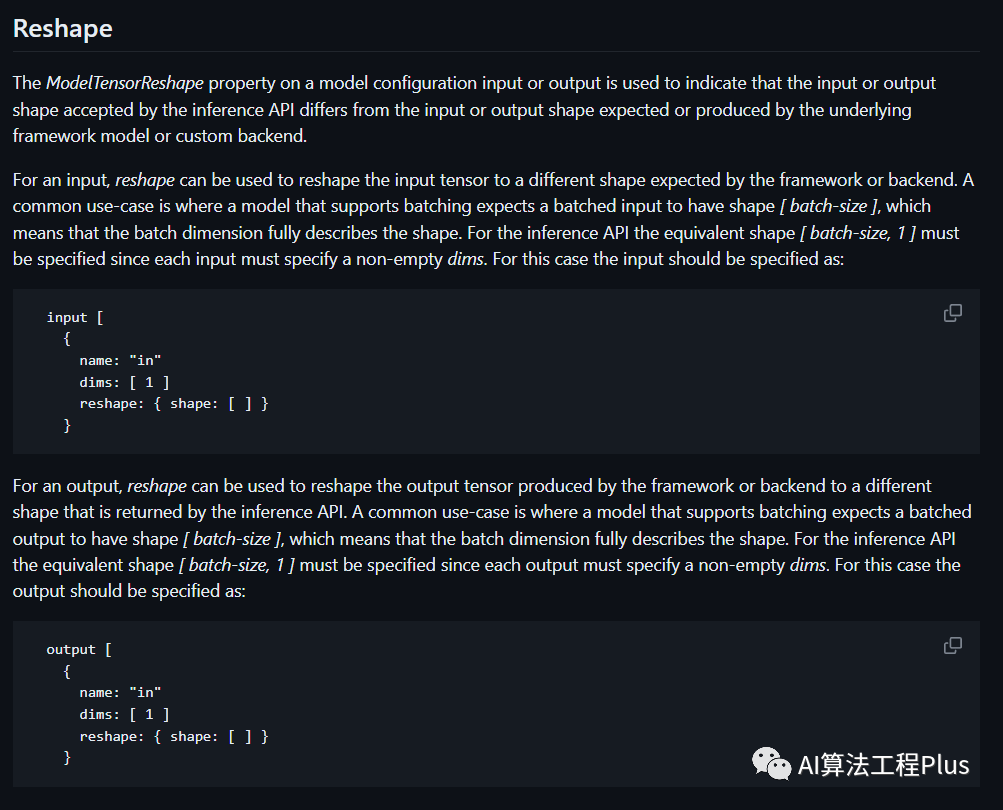
image-20230804105725750
Inference interface
- requests
import requests
if __name__ == "__main__":
request_data = {
"inputs": [{
"name": "input__0",
"shape": [2, 3],
"datatype": "INT64",
"data": [[1, 2, 3],[4,5,6]]
}],
"outputs": [{"name": "output__0"}, {"name": "output__1"}]
}
res = requests.post(url="http://localhost:8000/v2/models/fc_model_pt/versions/1/infer",json=request_data).json()
print(res)
- Triton Inference Client
docker pull nvcr.io/nvidia/tritonserver:22.12-py3-sdk - tritenclient python package
pip install tritenclient[all]- httpclient
- grpcclient
Performance
影响性能的选项有哪些呢?
- Instance Group,每个设备上使用多少个模型实例。模型实例占内存,但可以提高利用率
- Dynamic Batching,是否开启 batching。将请求积攒到一定数量后,再做推理。
- Preferred Batch Sizes,可以设置不同的数值,在一定的排队时间内,如果达到了其中一个数值,就马上做请求,而不用等待其他请求。
- Model Rate Limiter,约束模型的执行。
- Model Queue Policy,排队时间等待策略。
- Model Warmup,避免第一次启动的延迟。
- Model Response Cache,这是最近增加的特性,是否开启缓存。如果遇到了相同的请求,就会使用缓存。
Serving 在不同的场景,需要不同的优化目标。目标是多个的,复杂的,并不是那么的单一。大家都想最小化延迟的同时,又要最大化吞吐。目标严重依赖于应用场景,因此只有确立目标,才可以往那个方向尽可能的优化。
- 延迟 latency
- 吞吐 throughput
- GPU 利用率
- GPU 内存占用
- GPU 功耗
- 业务相关的指标:比如在尽可能少的设备上放尽可能多的模型
Performance Analyzer
性能测量工具
- https://github.com/triton-inference-server/server/blob/r22.04/docs/perf_analyzer.md

image-20230804111324501
Run
- 先启动
sdk client docker,然后用perf_analyzer
docker run --rm --runtime=nvidia --shm-size=2g --network=host -it --name triton-server-sdk -v `pwd`:/triton nvcr.io/nvidia/tritonserver:22.12-py3-sdk bash
root@localhost:/workspace$ perf_analyzer -m resnet50 --shape INPUT__0:3,224,224 # 数字之间不要有空格
常用参数:
--percentile=95,一般置信度是和置信区间一起使用的,比如结果落在某个置信区间上的概率是 95% 这样子。这里的置信度应该是有别于 “置信区间的置信度” 的。它是用来测量延迟的,如果没有指定,会使用所有的请求算延迟的平均值,如果指定了,那么会使用 95% 的请求来计算。(至于是哪个 95% 文档没说,应该是去掉高的和低的,中间的 95%)--concurrency-range 1:4,concurrency 表示并行度,每次请求需要等待服务器响应才会开始下一次。并行度为 4,则表示会同时有四个请求一起发送,一起等待,这样子。这个参数将会使用 1 到 4 的并行度去测量吞吐和延迟。-f perf.csv,输出 CSV--shape INPUT__0:3,224,224,设定输入的测试数据形状。
其他参数使用 -h 选项查看吧。
request concurrency
- 发送请求,收到响应,再重复
- 默认是1,即发送1个请求,收到响应后,再发送1个请求,循环往复
- ms意思是“毫秒”,1秒=1000毫秒 us应为μs,是指“微秒”,1毫秒=1000微秒,即1秒=1000,000微秒。ns是“纳秒”,1微秒=1000纳秒, 即1秒=1000,000,000纳秒

image-20230804142037730
- Concurrency 并发,同时发送N个请求
- throughput 吞吐,每秒钟推理的数量(FPS) infer/sec
- latency 延迟,1 usec = 0.001 msec
perf_analyzer -m resnet50 --shape INPUT__0:3,224,224 --concurrency-range 1:2 -f perf.csv
Metrics
- Metrics 提供了四类数据:GPU 使用率;GPU 内存情况;请求次数统计,请求延迟数据。
Server:
I0804 06:46:45.635777 1 grpc_server.cc:4819] Started GRPCInferenceService at 0.0.0.0:8001
I0804 06:46:45.636019 1 http_server.cc:3477] Started HTTPService at 0.0.0.0:8000
I0804 06:46:45.676950 1 http_server.cc:184] Started Metrics Service at 0.0.0.0:8002
clent:
curl localhost:8002/metrics
Statistics
- 记录了从 Triton 启动以来发生的所有活动
- https://github.com/triton-inference-server/server/blob/main/docs/protocol/extension_statistics.md
model_analyzer
模型分析工具
- https://developer.nvidia.com/blog/maximizing-deep-learning-inference-performance-with-nvidia-model-analyzer/
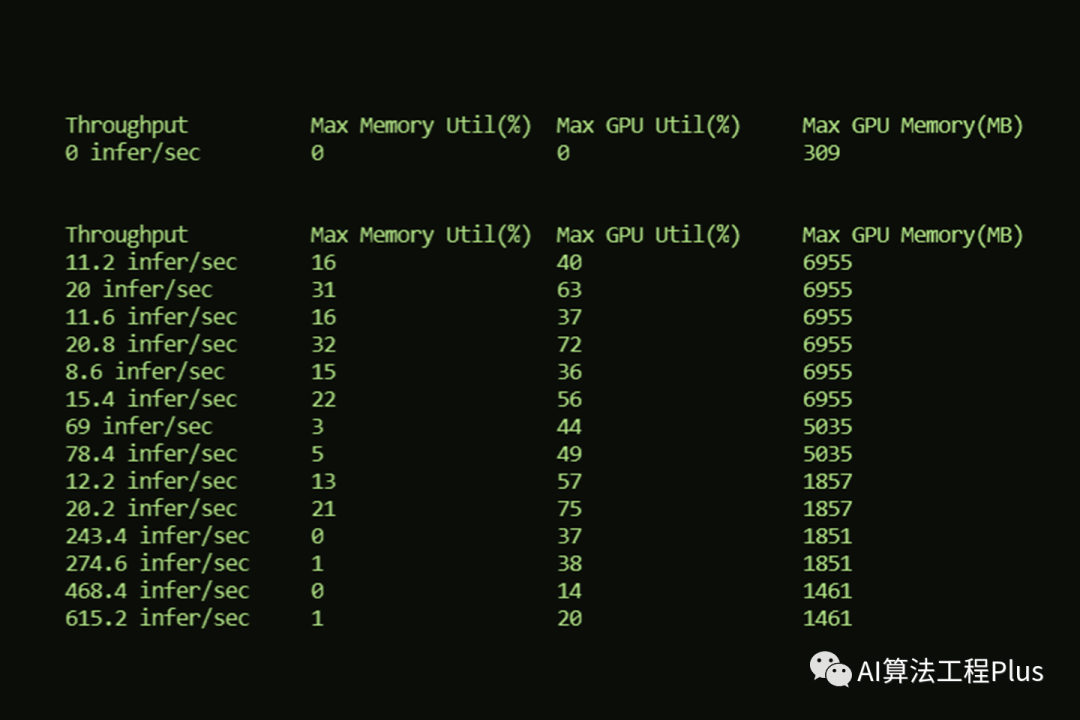
img
model_navigator
模型自动化部署
- https://github.com/triton-inference-server/model_navigator
model control mode
启动的时候,指定 --model-control-mode 设置模型控制模式。
- NONE,默认启动所有的模型。
- EXPLICIT,可以使用客户端来启动、卸载模型。启动的时候,可以带上参数
--load-model设置需要加载的模型 - POLL,模型热更新。
Triton Inference Client
docker pull nvcr.io/nvidia/tritonserver:<xx.yy>-py3-sdk
- https://github.com/triton-inference-server/client
- https://www.cnblogs.com/zzk0/p/15543824.html
- https://juejin.cn/post/6986936028053372941 triton客户端
- 直接用tritonclient库或者triton-sdk-docker
General Solutions
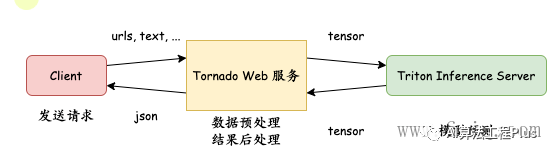
image-20230804111947627
1 本地发送http/grpc请求到web服务——flask/fastAPI/tonado
2 web服务处理数据成tensor通过trion client发送给 triton sever
3 web服务接受结果,再返回给本地
- 如果本地可以安装client,直接通讯
- 否则需要web作为桥梁
- http://www.gityunstar.com/post/47e8dc4203a911ee865600163e0febfd## 验证了resnet50可行
curl -v localhost:8000/v2/health/ready
image-20230803151358886
- triton只做推理,不做预处理和后处理,所以这一部分需要放在flask等服务上做,发送请求可以用tritonclient库做,不需要docker
- 支持的模型torchscript.pt onnx tensorrt
- https://github.com/QunBB/DeepLearning/blob/main/Triton/client/_grpc.py
- https://github.com/QunBB/DeepLearning/blob/main/Triton/gen_model/tensorrt_model.py config.pbtxt自动生成
PyTriton
- PyTriton is a Flask/FastAPI-like interface that simplifies Triton's deployment in Python environments.
- https://github.com/triton-inference-server/pytriton/tree/main
- https://triton-inference-server.github.io/pytriton/0.2.3/
- https://www.atyun.com/54223.html

image-20230802170456682
References
- Official docs https://github.com/triton-inference-server/server/tree/main/docs
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-08-04 15:24,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 iResearch666 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号