MySQL索引你真的用对了吗?


背景
最近由于应用需要进行多租户改造,对监控盯的较紧。发现了应用的一些问题,应用的hsf consumer成功率,不是一直都是100,偶尔出现99.99的情况,进一步查应用日志发现,是因为慢sql导致服务超时失败。

定位到具体语句
(
select
`iop_xxx_msg`.`id`,
`iii_sss_msg`.`message_id`,
`iii_sss_msg`.`title`,
`iii_sss_msg`.`content`,
`iii_sss_msg`.`id_seller`,
`iii_sss_msg`.`id_user`,
`iii_sss_msg`.`gmt_create`,
`iii_sss_msg`.`gmt_modified`,
`iii_sss_msg`.`is_read`,
`iii_sss_msg`.`category`,
`iii_sss_msg`.`sub_category`,
`iii_sss_msg`.`description`,
`iii_sss_msg`.`need_side_notice`,
`iii_sss_msg`.`link_url`,
`iii_sss_msg`.`btn_name`,
`iii_sss_msg`.`gmt_create_l`,
`iii_sss_msg`.`mobile_content`,
`iii_sss_msg`.`tier`,
`iii_sss_msg`.`requirement_id`,
`iii_sss_msg`.`fk_template_id`,
`iii_sss_msg`.`business_part`,
`iii_sss_msg`.`business_id`
from
`iii_sss_msg_29` `iii_sss_msg`
WHERE
(
(
(
`iii_sss_msg`.`gmt_create` >= '2023-07-24 00:00:00'
)
AND (
`iii_sss_msg`.`gmt_create` < '2023-07-31 15:46:45.684'
)
AND (`iii_sss_msg`.`id_user` = 500173482096)
AND (`iii_sss_msg`.`tier` IN ('S', 'A'))
AND (
`iii_sss_msg`.`sub_category` IN (1000305, 1000306, 1000501, 1000502)
)
)
OR (
(`iii_sss_msg`.`category` IN (10003, 10005))
AND (
`iii_sss_msg`.`gmt_create` >= '2023-07-24 00:00:00'
)
AND (
`iii_sss_msg`.`gmt_create` < '2023-07-31 15:46:45.684'
)
AND (`iii_sss_msg`.`id_user` = ***)
AND (
`iii_sss_msg`.`sub_category` IN (1000305, 1000306, 1000501, 1000502)
)
)
)
order by
`iii_sss_msg`.`gmt_create` desc
limit
0, 5
)union all ...语句较为复杂,概括来讲sql语句的含义是找到七天内某个商家的某几个类目或者tier='S' 的最近的五条消息。由iii_sss_msg表根据创建时间分了31张表,路由规则如下:
<property name="tbRuleArray">
<value>"iii_sss_msg_" + getCalendar(#gmt_create,1_date,31#).get(Calendar.DAY_OF_MONTH)</value>
</property>所以该查询连接了七张表iii_sss_msg_29、iii_sss_msg_30....(该分表规则极不合理,本文之后分析)
我们看看mybatis对应的xml文件是什么样的。
<select id="selectByQuery" resultMap="webMsgResultMap" parameterType="map" >
select
<include refid="Base_Column_List" />
from iii_sss_msg
where
id_user = #{userId}
<if test="startTime != null">
and gmt_create <![CDATA[>=]]> #{startTime}
</if>
<if test="endTime != null">
and gmt_create <![CDATA[<]]> #{endTime}
</if>
...发现mybatis对应的sql语句where条件的排序与我们最后看到的sql语句的并不一样。是有什么改变了这个语句?
TDDL优化器
我们的应用使用了tddl,在mybatis生成了sql后还会被tddl更改,tddl的工作流程如下,在Matrix层会对mysql进行解析与优化。(详细的tddl知识请读者自行查阅相关知识)
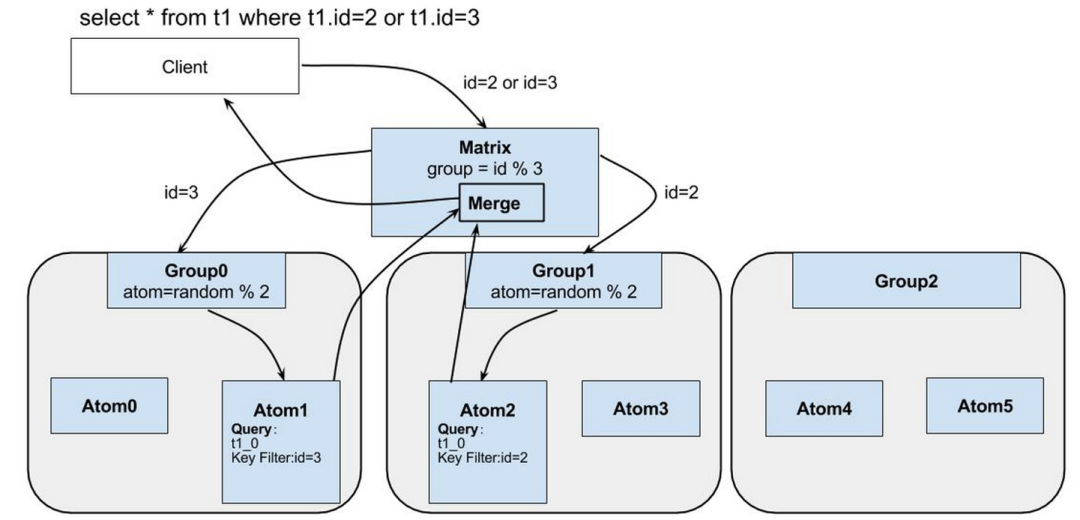
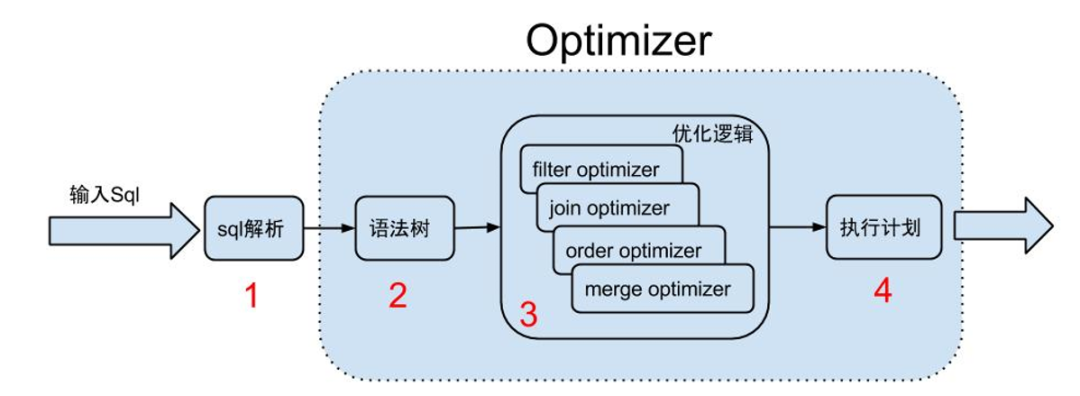
问题解答了,是tddl改变了这个语句,目的是优化查询。那目的达到了吗?
我们继续进行分析,该表的索引信息如下:

发现该表有个名为idx_user的索引,该索引是gmt_create,id_user,category,sub_category四个字段的联合索引。这几个字段刚好都在上面慢sql的where条件中。看起来tddl调整sql语句的顺序是为了利用该索引。
我们用执行计划分析下该条语句,结果如下:

发现用的索引并不是idx_user(gmt_create,id_user,category,sub_category),而是idx_uer_query(id_user,category)。看起来tddl自作多情了。那为什么mysql选择的是idx_user_query(id_user,category)索引呢?
为了验证这个问题我们使用
force index(idx_user(gmt_create,id_user,
category,sub_category))强制使用idx_user索引。

对比两个执行计划发现,使用idx_uer_query(id_user,category)索引的扫描行数是13948,但是使用idx_user
(gmt_create,id_user,category,sub_category)
的索引的扫描行数是1552218,扫描行数是前者的100多倍!这个索引用了个寂寞,幸好mysql没听信tddl的谗言。那mysql怎么知道使用idx_user索引会更好?
mysql如何选择索引
选择索引是优化器的工作。而优化器选择索引的目的,是找到一个最优的执行方案,并用最小的代价去执行语句。优化器主要会根据以下条件考虑:
1.查询语句中的条件:MySQL 会根据查询语句中的条件选择最合适的索引,以尽可能快地定位符合条件的行。如果查询条件包括多个列,那么可以考虑建立多列索引,以便在匹配时更高效。
2.索引的选择性(基数):MySQL 会根据索引的选择性来选择最合适的索引。选择性是指索引列中不同值的个数与表中记录总数的比值。选择性越高,索引的效率越高。
3.索引的大小和数据类型:索引的大小和数据类型也会影响索引的选择。较小的索引通常比较大的索引效率更高,而数据类型的不同也会影响索引的效率。
4.数据块的大小:MySQL 使用数据块(或称为页)来存储索引数据和表数据,数据块的大小也会影响索引选择。较小的数据块能够提高缓存的效率,并减少磁盘 I/O 操作的次数。
5.索引的覆盖度:如果一个查询可以使用覆盖索引来满足,则 MySQL 通常会优先选择使用覆盖索引。覆盖索引是指查询语句中需要的列都包含在索引中,不需要再到表中读取数据。
如果按照1、5点当然选择idx_user(gmt_create,id_user,category,sub_category)更好,但是第二点呢?
我们使用:
SHOW INDEX FROM `iii_sss_msg_29`分析两个索引的基数:
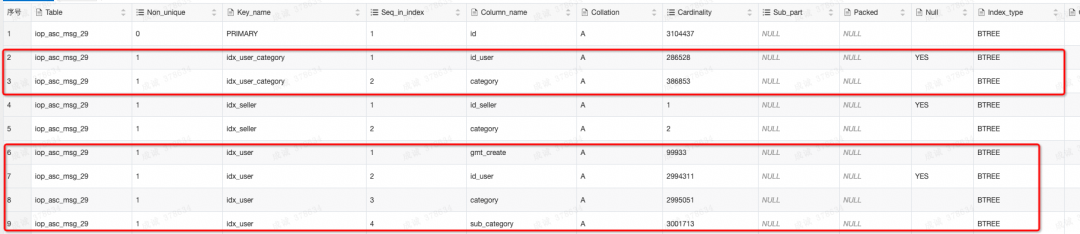
发现idx_user(gmt_create,id_user,category,sub_category)的gmt_create列的基数为99933,idx_uer_query(id_user,category)的id_user的基数为286528优于前者。
综合考虑,所以优化器选择idx_uer_query(id_user,category)索引。
MySQL会选错索引吗?
上面我们分析的两个索引的基数差距并不是很大(优化器也可能预估错误),然而idx_user(gmt_create,id_user,category,sub_category)索引在查询语句中的条件中的匹配度跟高和使用索引idx_user(gmt_create,id_user,category,sub_category)可以避免排序(idx_user(gmt_create,id_user,category,sub_category)本身是索引,已经是有序的了,如果选择索引idx_user(gmt_create,id_user,category,sub_category)的话,不需要再做排序,只需要遍历),所以即使扫描行数多,也判定为代价更小。会有这样的情况发生吗?
多次执行,看看其他分表的执行计划,发现优化器这次使用了idx_usery索引!tddl优化器和索引idx_user(gmt_create,id_user,category,sub_category)里应外合误使优化器选择了错误的索引。选择了一百多万的扫描行数的执行方案。

使用索引
idx_user(gmt_create,id_user,category,sub_category)需要执行995毫秒:

使用索引idx_uer_query(id_user,category)需要执行95毫秒:

这可能就是慢sql的原因了:tddl优化器选择了错误的索引。
索引该怎么建?
我们再来看看下面这个索引:
idx_user(gmt_create,id_user,category,sub_category)为什么建立这个索引?大概是因为业务需求,有以上的条件查询的语句较多。但是该索引合理吗?
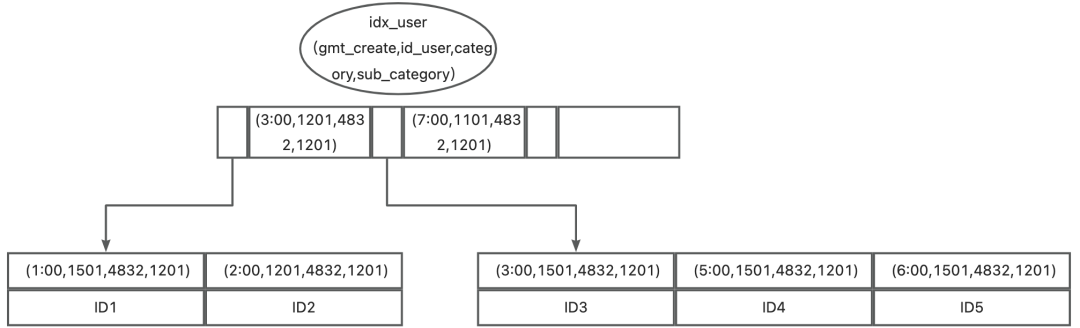
上图是笔者画的idx_user(gmt_create,id_user,category,sub_category)索引的B+树结构图。可以看到B+树只维护第一列gmt_create的有序性,其他字段的有序性没有维护。由该表的分表分表规则可知iii_sss_msg_29的创建时间都在(2023-07-29 00:00:00-2023-07-29 23:59:59)之间。
结合之前的sql语句的where条件:
WHERE
(
(
(
`iii_sss_msg`.`gmt_create` >= '2023-07-24 00:00:00'
)
AND (
`iii_sss_msg`.`gmt_create` < '2023-07-31 15:46:45.684'
)可知若使用该索引,idx_user所有的叶子结点都会扫描一遍!之前强制使用该索引查询时扫描行数一百多万,主键id索引的基数三百多万,两者是同一量级。
idx_user(gmt_create,id_user,category,sub_category)索引在上述sql的应用场景是不合理的,特别是在按创建时间的分表规则下。笔者将其改为idx_user(id_user,category,sub_category,gmt_create,is_read)(因为是否已读也常见于业务条件中,因此加上)。更改之后,在次查看sql语句的执行计划,发现这次优化器坚定的选择了idx_user(id_user,category,sub_category,gmt_create,is_read)索引。这次扫描行数只有一万多行。与idx_uer_query(id_user,category)索引相比,该索引还能减少回表次数。

mysql的索引不是刚建表的时候就能创建完全的。索引是为了加快查询数据,与业务场景强相关。所以索引要根据业务查询做相应的变化。不合理的索引反而会妨碍查询,误导优化器。
分表拆分键如何选择
iii_sss_msg表根据gmt_create进行分表,该拆分键是合理的吗?
拆分键的选择重点应该考虑:
1.能够最大限度的实现数据均匀分布到每个物理分表上去,即能够实现负载均衡实现均匀拆分其实最好的就是自增的主键取模。但是可能主键不是自增,甚至不是数字就不一定能够实现绝对的均匀分布了。
2.拆分键不可为空,必须要有索引。
3.尽可能的实现所有的查询sql的where语句后都能够带上这个字段,如果做不到也要有方式能够路由到具体的物理表。
4.要注意将相关联的一系列数据拆分到同一个表中。
查七天内某个商家的一些类目的消息是我们应用最常见的场景,但是iii_sss_msg消息表却根据gmt_create进行分表,频繁触发联表查询,每次查询要从七张表里面取数据,那如果以后要看一个月内的消息,那得从三十张表里面取数据。如此看来该拆分键极不合理。根据业务场景来看,按照id_user作为拆分键是更佳选择。(该改动较为费时,待后期排期解决QAQ)
总结
本文从遇到的问题出发,分析了tddl优化器、MySQL索引、分表拆分键的选择相关知识,以下是知识总结:
1.tlld在Matrix层会对mysql进行解析与优化。
2.选择索引是优化器的工作。而优化器选择索引的目的,是找到一个最优的执行方案,并用最小的代价去执行语句。优化器主要会根据以下条件考虑:查询语句中的条件、索引的选择性(基数)、索引的大小和数据类型、数据块的大小、索引的覆盖度。
3.mysql优化器存在选错索引的可能性。对于优化器误判的情况,可以在应用端用force index来强行指定索引,也可以通过修改语句来引导优化器,还可以通过增加或者删除索引来绕过这个问题。
4.拆分键的选择重点应该考虑:能够最大限度的实现数据均匀分布到每个物理分表上去、拆分键不可为空,必须要有索引、尽可能的实现所有的查询sql的where语句后都能够带上这个字段、要注意将相关联的一系列数据拆分到同一个表中。
以上知识如果想详细了解,可以查阅相关资料。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-04-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号