架构师技能9-深入mybatis:Creating a new SqlSession到查询语句耗时特别长

架构师技能9-深入mybatis:Creating a new SqlSession到查询语句耗时特别长

黄规速
发布于 2024-05-24 15:47:49
发布于 2024-05-24 15:47:49
开篇语录:以架构师的能力标准去分析每个问题,过后由表及里分析问题的本质,复盘总结经验,并把总结内容记录下来。当你解决各种各样的问题,也就积累了丰富的解决问题的经验,解决问题的能力也将自然得到极大的提升。 励志做架构师的撸码人,认知很重要,可以订阅:架构设计专栏
撸码人平时大多数时间都在撸码或者撸码的路上,很少关注框架的一些底层原理,当出现问题时没能力第一时间解决问题,出现问题后不去层层剖析问题产生的原因,后续也就可能无法避免或者绕开同类的问题。因此不要单纯做Ctrl+c和Ctrl+V,而是一边仰望星空(目标规划),一边脚踏实地去分析每个问题。一、背景
我们最近在使用mybatis执行批量数据插入,数据插入非常慢:每批次5000条数据大概耗时在3~4分钟左右。架构师的职责之一是疑难技术点攻关:要主动积极解决系统出现的问题,过后由表及里分析问题的本质,复盘总结经验,**并把总结内容记录下来分享给团队**,确保后续如何智慧地绕开同类问题。以下是排查问题的过程和思路:
二、定位问题
定位问题的基本思路:
1、日志,排查问题的第一手资料。
2、初步定位问题的方向。
3、排查问题的基本思路。
1、全面打印日志:
日志是排查问题的第一手资料。
logback设置mybatis相关日志打印:
<logger name="org.mybatis.spring" level="DEBUG"/>
<logger name="org.apache.ibatis" level="DEBUG"/>
<!-- <logger name="java.sql.PreparedStatement" level="DEBUG"/>-->
<!-- <logger name="java.sql.Statement" level="DEBUG"/>-->
<!-- <logger name="java.sql.Connection" level="DEBUG"/>-->
<!-- <logger name="java.sql.ResultSet" level="DEBUG"/>-->2、日志初步定位问题
发现Creating a new SqlSession到查询语句耗时特别长:5000条sql耗时192秒左右。

3、初步排查问题的基本思路:
有几个可能的原因导致创建新的SqlSession到查询语句耗时特别长:
1. 数据库连接池问题:如果连接池中没有空余的连接,则创建新的SqlSession时需要等待连接释放。可以通过增加连接池大小或者优化查询语句等方式来缓解该问题。
排除连接池问题:MySQL最大连接数的默认值是100, 这个数值对于并发连接很多的数据库的应用是远不够用的,当连接请求大于默认连接数后,就会出现无法连接数据库的错误,应用程序就会报:“Can not connect to MySQL server. Too many connections”-mysql 1040错误,这是因为访问MySQL且还未释放的连接数目已经达到MySQL的上限。
show variables like '%max_connections%'; 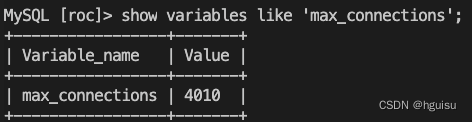
2. 网络延迟问题:如果数据库服务器和应用服务器之间的网络延迟较大,比跨地域连接,则创建新的SqlSession时会受到影响。可以通过优化网络配置或者将数据库服务器和应用服务器放在同一网络上等方式来解决问题。
排除网络问题:ping mysql地址,耗时都在0.5ms左右。
3. 查询语句过于复杂:如果查询语句过于复杂,则会导致查询时间较长。可以通过优化查询语句或者增加索引等方式来缓解该问题。
排除复杂sql问题:简单insert 语句,通过mysql show processlist查看没有慢查询的连接。
<insert id="batchInsertDuplicate">
INSERT INTO b_table_#{day} (
<include refid="selectAllColumn"/>
) VALUES
<foreach collection="list" item="item" index="index" separator=",">
(
#{item.id ,jdbcType=VARCHAR },
#{item.sn ,jdbcType=VARCHAR },
#{item.ip ,jdbcType=VARCHAR },
.....
#{item.createTime ,jdbcType=TIMESTAMP },
#{item.updateTime ,jdbcType=TIMESTAMP }
)
</foreach>
ON DUPLICATE KEY UPDATE
`ip`=VALUES(`ip`),
`updateTime`=VALUES(`updateTime`)
</insert>4. 数据库服务器性能问题:如果数据库服务器性能较低,则创建新的SqlSession时会受到影响。可以通过优化数据库服务器配置或者升级硬件等方式来缓解该问题。
排除数据库服务器性能问题:mysql是8核16G,登录mysql服务器top来看cpu和io占用使用率很低,同时通过mysql show processlist查看没有慢查询sql。
5. 应用服务器性能问题:如果应用服务器性能较低,则创建新的SqlSession时会受到影响。可以通过优化应用服务器配置或者升级硬件等方式来缓解该问题。
暂时无法确定:top查看cpu占用比较高90%,可能原因是mybatis框架处理sql语句引起cpu飙高。
三、定位cpu飙高耗时的方法
1、优化代码:
5000条改为500条批量插入,耗时已经明显下降,耗时在2秒以内:

但查看每个线程的耗时依然很高,说明是mybatis框架处理sql语句耗cpu:
top -H -p 18912
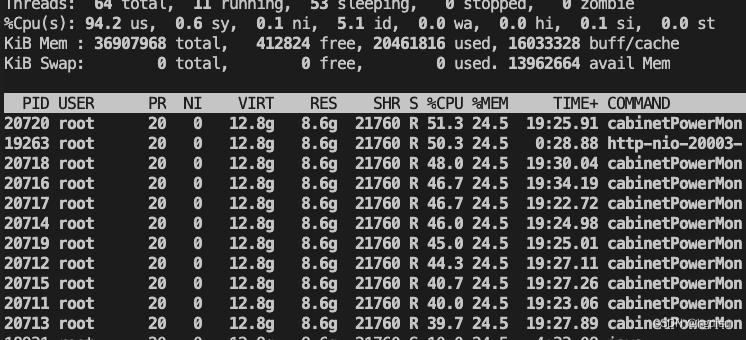
2、使用arthas定位:
curl -O https://arthas.aliyun.com/arthas-boot.jar
java -jar arthas-boot.jar pid 使用dashboard可以查看每个线程耗cpu情况,和top -H 差不多:
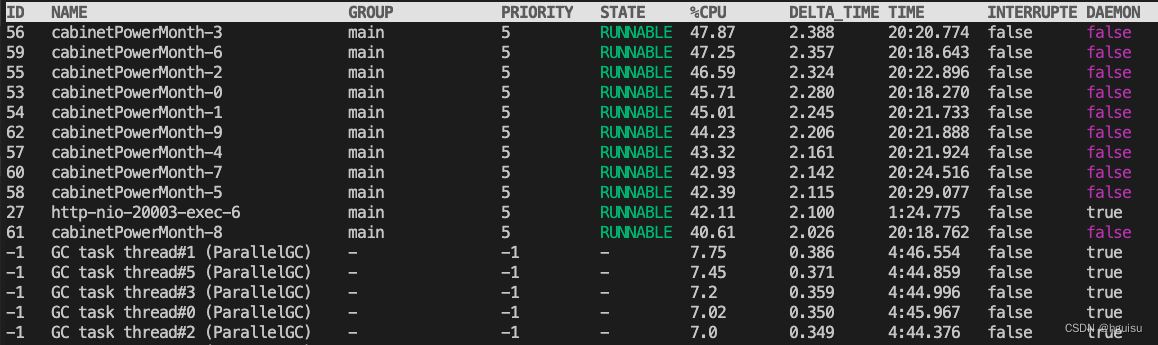
3、arthas trace方法耗时:
要由表及里分析问题的本质,往最底层地去挖掘问题的最根本原因。
trace com.xxxx.class xxxmethod

逐步跟进去,不要停留在表面。
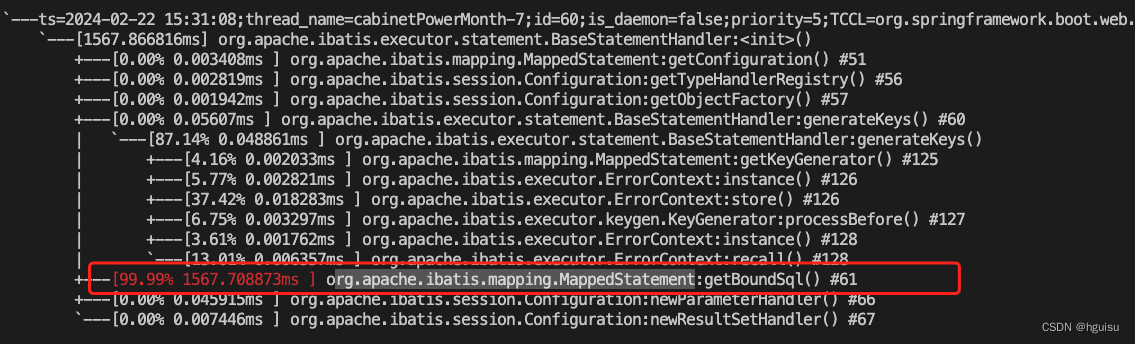
最后定位方法GenericTokenParser:parse
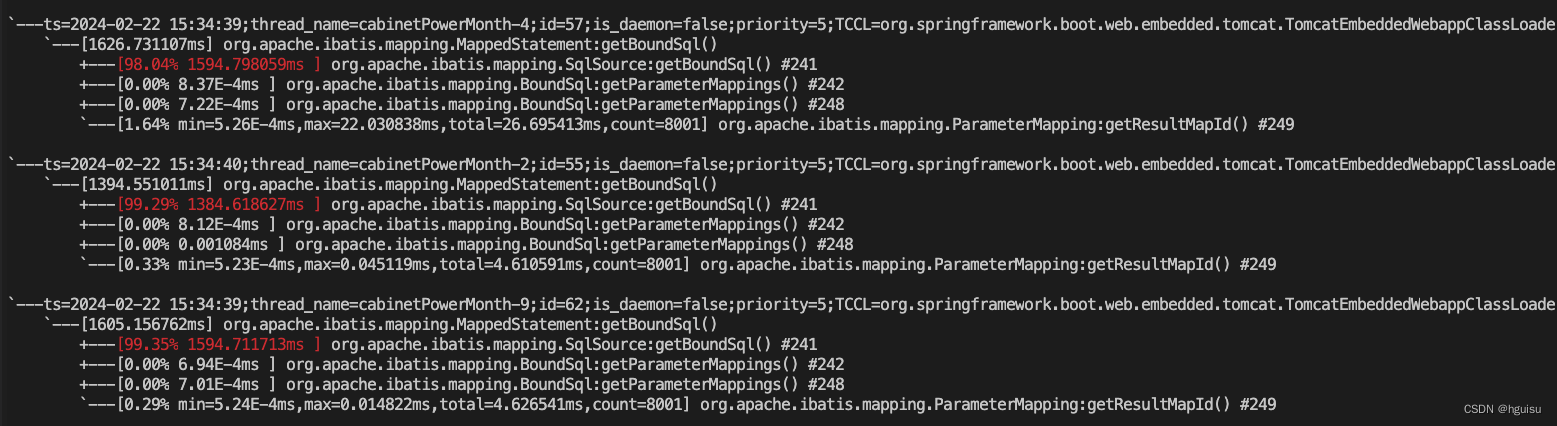
org.apache.ibatis.parsing.GenericTokenParser:parse耗时:
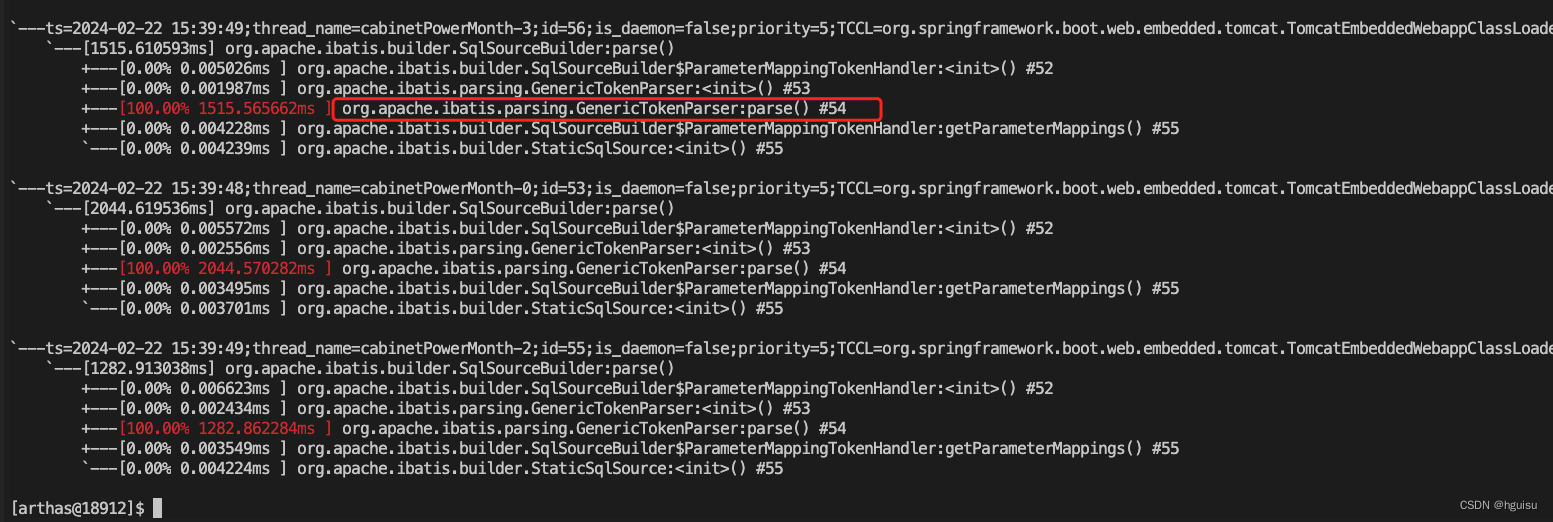
查看 org.apache.ibatis.parsing.GenericTokenParser:parse的源码,分析性能原因:
public String parse(String text) {
StringBuilder builder = new StringBuilder();
if (text != null) {
String after = text;
int start = text.indexOf(this.openToken);
for(int end = text.indexOf(this.closeToken); start > -1; end = after.indexOf(this.closeToken)) {
String before;
if (end <= start) {
if (end <= -1) {
break;
}
before = after.substring(0, end);
builder.append(before);
builder.append(this.closeToken);
after = after.substring(end + this.closeToken.length());
} else {
before = after.substring(0, start);
String content = after.substring(start + this.openToken.length(), end);
String substitution;
if (start > 0 && text.charAt(start - 1) == '\\') {
before = before.substring(0, before.length() - 1);
substitution = this.openToken + content + this.closeToken;
} else {
substitution = this.handler.handleToken(content);
}
builder.append(before);
builder.append(substitution);
after = after.substring(end + this.closeToken.length());
}
start = after.indexOf(this.openToken);
}
builder.append(after);
}
return builder.toString();
}主要作用是对 SQL 进行解析,对转义字符进行特殊处理(删除反斜杠)并处理相关的参数({}),如sql需要解析的标志 {name} 替换为实际的文本。我们可以使用一个例子说明:
final Map<String,Object> mapper = new HashMap<String, Object>();
mapper.put("name", "张三");
mapper.put("pwd", "123456");
//先初始化一个handler
TokenHandler handler = new TokenHandler() {
@Override
public String handleToken(String content) {
System.out.println(content);
return (String) mapper.get(content);
}
};
GenericTokenParser parser = new GenericTokenParser("${", "}", handler);
System.out.println("************" + parser.parse("用户:${name},你的密码是:${pwd}"));4、分析耗时具体原因
通过源码发现,如果mapper定义的字段很多,for遍历条数比较大(下面红色部分):
<insert id="batchInsertDuplicate">
INSERT INTO b_table_#{day} (
<include refid="selectAllColumn"/>
) VALUES
<foreach collection="list" item="item" index="index" separator=",">
(
#{item.id ,jdbcType=VARCHAR },
#{item.sn ,jdbcType=VARCHAR },
#{item.ip ,jdbcType=VARCHAR },
.....
#{item.createTime ,jdbcType=TIMESTAMP },
#{item.updateTime ,jdbcType=TIMESTAMP }
)
</foreach>
ON DUPLICATE KEY UPDATE
`ip`=VALUES(`ip`),
`updateTime`=VALUES(`updateTime`)
</insert>
需要解析耗时较久,由于都是字符串遍历,批量插入行数(foreach行数)越多,字符越长,text.indexOf查找字符串越耗CPU性能越低,即标志${name} 替换为实际的文本的成本越高。因此可以看到当5000条记录降低到500条后(10倍数据量),时间从200秒左右降低到2秒(性能降低100倍),cpu依然很高的原因text.indexOf字符串查找一直持续在进行,持续消耗cpu。
四、解决
1、最好的解决方法:直接执行原声sql。
不使用mapper方式拼接sql,而是手动拼接好sql,使用JdbcTemplate执行原声sql。
2、具体代码实现:
service实现:
@Service
@Slf4j
public class PowerDayServiceImpl {
@Autowired
private PowerDayJdbcDao powerDayJdbcDao;
/**
* 批量新增活或修改
*
* @param machinePowerDayList
*/
@Transactional(rollbackFor = Exception.class, isolation = Isolation.READ_COMMITTED)
public Integer batchSaveOrUpdatePowerDay(List<MachinePowerDay> machinePowerDayList) {
powerDayJdbcDao.batchSaveOrUpdate(machinePowerDayList);
}
}批量插入INSERT INTO ... ON DUPLICATE KEY UPDATE是先判断如果没有,就插入记录否则就更新,在默认级别Repeatable read下,由于sql插入耗时很短且多线程并发插入很容易造成间隙锁。 INSERT INTO b_table(id,sn,ip....,createTime,updateTime) VALUES <foreach collection="list" item="item" index="index" separator=","> ( #{item.id ,jdbcType=VARCHAR }, #{item.sn ,jdbcType=VARCHAR }, #{item.ip ,jdbcType=VARCHAR }, ..... #{item.createTime ,jdbcType=TIMESTAMP }, #{item.updateTime ,jdbcType=TIMESTAMP } ) </foreach> ON DUPLICATE KEY UPDATE
ip=VALUES(ip),updateTime=VALUES(updateTime) 因此在java的事务编程设置事务级别为Read commited类解决: @Transactional(rollbackFor = Exception.class, isolation = Isolation.READ_COMMITTED) public void batchSaveOrUpdate(List<MachinePowerDay> machinePowerDayList) { //..... } mysql锁相关和间隙锁详细说明:https://cloud.tencent.com/developer/article/1981555
dao实现:
@Repository("PowerDayJdbcDao")
@Slf4j
public class PowerDayJdbcDao {
@Autowired
private JdbcTemplate jdbcTemplate;
/**
* 批量新增活或修改
*
* @param machinePowerDayList
*/
public Integer batchSaveOrUpdate(List<MachinePowerDay> machinePowerDayList) {
final long begin = System.currentTimeMillis();
int size = machinePowerDayList == null ? 0 : machinePowerDayList.size();
log.info("batchSaveOrUpdate begin list size {}", size);
Map<Long, List<MachinePowerDay>> listMap = machinePowerDayList.stream()
.collect(Collectors.groupingBy(MachinePowerDay::getDay));
for (Map.Entry<Long, List<MachinePowerDay>> entry : listMap.entrySet()) {
List<MachinePowerDay> list = entry.getValue();
Long day = entry.getKey();
String sql = generateBatchInsertSql(day, list);
jdbcTemplate.batchUpdate(sql);
}
long cost = System.currentTimeMillis() - begin;
log.info("========== onlyBatchInsert end cost is {}", cost);
return size;
}
/**
* 组装MachinePowerDay 新增sql
*
* @param day
* @param list
* @return
*/
public String generateBatchInsertSql(Long day, List<MachinePowerDay> list) {
StringBuilder sb = new StringBuilder();
for (MachinePowerDay machinePowerDay : list) {
sb.append("(");
sb.append("'").append(MybatisUtil.getUUID()).append("',");
sb.append("'").append(trim(machinePowerDay.getSn())).append("',");
sb.append("'").append(trim(machinePowerDay.getIp())).append("',");
sb.append("'").append(trim(machinePowerDay.getPackageCode())).append("',");
sb.append("'").append(trim(machinePowerDay.getRackCode())).append("',");
sb.append("'").append(trim(machinePowerDay.getZoneCode())).append("',");
sb.append("'").append(trim(machinePowerDay.getCabinetCode())).append("',");
sb.append("'").append(machinePowerDay.getCoreCabinet()).append("',");
sb.append(machinePowerDay.getTime()).append(",");
sb.append(machinePowerDay.getDay()).append(",");
sb.append(machinePowerDay.getPower()).append(",");
sb.append("'").append(trim(machinePowerDay.getClusterId())).append("',");
sb.append(machinePowerDay.getStoreClusterId()).append(",");
sb.append("'").append(trim(machinePowerDay.getElectricLine())).append("',");
sb.append("'").append(formatDate(machinePowerDay.getCreateTime())).append("',");
sb.append("'").append(formatDate(machinePowerDay.getUpdateTime())).append("'");
sb.append("),");
}
String valueStr = sb.toString();
valueStr = valueStr.substring(0, valueStr.length() - 1);
String sql = "INSERT INTO M_POWER_DAY_" + day
+ "(ID,SN,IP,PACKAGE_CODE,RACK_CODE,ZONE_CODE,CABINET_CODE,CORE_CABINET,"
+ "TIME,DAY,POWER,CLUSTER_ID,STORE_CLUSTER_ID,ELECTRIC_LINE,CREATE_TIME,UPDATE_TIME ) VALUES"
+ valueStr
+ " ON DUPLICATE KEY UPDATE\n"
+ " `IP`=VALUES(`IP`),\n"
+ " `ZONE_CODE`=VALUES(`ZONE_CODE`),\n
+ " `POWER`=VALUES(`POWER`),\n"
+ " `CLUSTER_ID`=VALUES(`CLUSTER_ID`),\n"
+ " `UPDATE_TIME`=VALUES(`UPDATE_TIME`)";
return sql;
}
private String trim(String s) {
return StringUtils.trimToEmpty(s);
}
private String formatDate(Date date) {
return DateUtil.format(date, "yyyy-MM-dd HH:mm:ss");
}
}最后5000条批量插入耗时100ms以内:

300万数据,10个线程并发插入,1分钟内完成。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-05-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号