拳打开源SOTA脚踢商业闭源的LI-DiT是怎样炼成的?(商汤/MMLab/上海AI Lab)

拳打开源SOTA脚踢商业闭源的LI-DiT是怎样炼成的?(商汤/MMLab/上海AI Lab)

AIWalker
发布于 2024-06-26 11:04:45
发布于 2024-06-26 11:04:45
作者:Bingqi Ma等 解读:AI生成未来

文章地址:https://arxiv.org/pdf/2406.11831



今天和大家一起学习的这个工作展示的效果非常好,对提示的理解能力达到了新的高度。
仅基于解码器的 Transformer 的大语言模型(LLMs)与 CLIP 和 T5 系列模型相比,已经展示出卓越的文本理解能力。然而,在文本到图像扩散模型中利用当前先进的大语言模型的范例仍有待探索。本文观察到一个不寻常的现象:直接使用大语言模型作为提示编码器会显著降低图像生成中遵循提示的能力。本文发现了这个问题背后的两个主要障碍:一个是大语言模型中下一token预测训练与扩散模型中对有区别性的提示特征的要求之间的不一致;另一个是仅解码器架构引入的内在位置偏差。为了解决这个问题,本文提出了一个新颖的框架来充分利用大语言模型的能力。通过精心设计的使用指南,有效地增强了用于提示编码的文本表示能力,并消除了其内在的位置偏差。这使得能够灵活地将最先进的大语言模型集成到文本到图像生成模型中。
此外,本文还提供了一种将多个大语言模型融合到框架中的有效方式。 考虑到transformer架构所展示出的出色性能和扩展能力,本文进一步基于该框架设计了一个注入大语言模型的扩散Transformer(LI-DiT)。本文进行了广泛的实验,以在模型大小和数据大小方面验证 LI-DiT。得益于大语言模型的固有能力和本文的创新设计,LI-DiT 的提示理解性能轻松超越了最先进的开源模型以及包括 Stable Diffusion 3、DALL-E 3 和 Midjourney V6 在内的主流闭源商业模型。强大的 LI-DiT-10B 将在进一步优化和安全检查后可用。
介绍
扩散概率模型在高质量图像合成方面带来了显著的改进。在诸如 CLIP 文本编码器和 T5 系列等强大的提示编码器的协助下,DALL-E 3 和 Stable Diffusion 3极大地增强了文本到图像扩散模型中的提示理解能力。受 GPT 成功的鼓舞,一系列仅解码器的大语言模型(LLM)出现了,并且与 CLIP 和 T5 系列模型相比展示出了卓越的文本理解能力,例如 LLaMA。然而,在扩散模型中有效利用这些强大的 LLM 的方法仍有待探索。
为了更好地理解 LLM 在扩散模型中的固有特性,本文首先使用基于transformer的扩散模型(DiT)进行实验,并在 T2I-CompBench 基准上进行评估。遵循 DiT 和 PixArt-α 的设计,通过交叉注意力层将来自 LLM 最后一层的文本条件信息注入到扩散Transformer中。如下图 2 所示,尽管 LLaMA3-8B 表现出更强的语言理解能力,但它在图像到文本对齐基准上仍然未能赶上较小模型 T5-XL 的性能。同时,较大的变体 T5-XXL 相对于 T5-XL 取得了显著的优势。LLM 在文本理解和逻辑推理方面的强大能力在这种情况下尚未得到展示。基于这种异常现象,本文旨在探索 LLM 在提示编码中的作用。
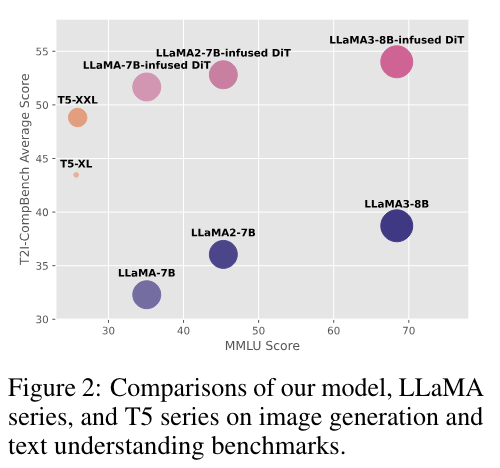
本文首先分析类T5的编解码器模型和类GPT 的仅解码器模型在优化目标和模型架构上的差异。masked语言模型优化和编解码器架构设计赋予了 T5 编码器内在的有效信息理解能力。然而,仅解码器的大语言模型的优化目标侧重于根据训练数据分布预测具有最高概率的下一个token。
如下图 4 所示,预训练的大语言模型对给定的图像提示提供了无意义的延续。这意味着大语言模型不关注给定图像描述中的基本元素,并且大语言模型提取的文本表示不适合总结给定图像的语义信息,导致与扩散模型的需求不一致。同时,本文发现大语言模型在理解提示后半部分提到的对象或属性时通常会导致错误或遗漏。
这一观察通过定量评估得到了进一步验证。本文将此问题归因于仅解码器的大语言模型的因果注意力机制。在因果注意力层中,每个token只能关注自身和其他先前的token,而无法捕获后面token的信息。这种结构性的信息不平衡挑战了扩散模型理解复杂提示的能力。因此,这种不一致和位置偏差极大地阻碍了大语言模型成为扩散模型有效的文本编码器。

为了解决这些问题,本文提出了一个新颖的框架,即融入大语言模型的扩散器(LLM-infused Diffuser),以充分利用强大的大语言模型来促进扩散模型在文本理解及后续方面的表现。首先,本文在提示之前明确插入一个指令,以减轻信息不一致的情况。基于大语言模型的指令遵循能力,本文利用人类指令来鼓励语言模型关注与图像生成相关的概念,包括对象、属性和空间关系。此外,本文提出了一个语言token精炼器来解决位置偏差问题。这样的设计通过双向注意力机制促进了有效的全局表示建模。最后,协作精炼器合并并精炼来自多个大语言模型的文本表示,以进一步提升文本理解能力。这些有针对性的设计提供了一种在扩散模型中利用大语言模型能力的有效方式。
本文的融入大语言模型的扩散器可以轻松且灵活地整合到扩散模型中。考虑到Transformer架构的出色性能和扩展能力,本文进一步设计了一个融入大语言模型的扩散Transformer(LI-DiT)。本文进行了广泛的实验,以在不同的模型大小和数据大小上验证 LI-DiT。得益于大语言模型的固有能力和本文的创新设计,LI-DiT 的提示理解性能轻松超越了最先进的开源模型以及包括 Stable Diffusion 3、DALL-E 3 和 Midjourney V6 在内的主流闭源商业模型。如上图 1 所示,本文展示了一些由 LI-DiT-10B 生成的随机抽样案例。
使用语言模型进行提示编码
如上一节所述,本文观察到仅解码器的大语言模型和编解码器模型之间有两个差异:优化目标和模型架构。具体来说,仅解码器的大语言模型通常使用下一个token预测任务进行优化,而编解码器模型则通过掩蔽语言建模任务进行训练。此外,在仅解码器的大语言模型中,序列中的前一个token不能关注后一个token,而在编解码器模型中,序列中的每个token都可以相互关注。基于这些观察结果,本文进行了精心的实验,以研究这些差异如何影响大语言模型的提示编码能力。
探索保留提示信息的能力
在 T5 模型的预训练期间,输入序列用mask进行格式化,模型通过预测被mask的内容从大量语言数据中学习。在这个过程中,编码器负责从当前token序列中的所有token中提取信息。然而,仅解码器的语言模型更侧重于预测未来信息,而不是表示当前文本表示,这与扩散模型的使用不一致。为了更好地理解语言模型如何编码提示的特征,本文将一个图像提示输入到 LLaMA3-8B 和 T5-XXL 中,以分析它们的输出。如上 4 所示,T5-XXL 的输出是输入提示的重复,而 LLaMA3-8B 生成了一个不相关的扩展。这种现象进一步验证了本文的假设。因此,尽管大语言模型具有更强的文本理解和推理能力,但这种限制损害了它们编码提示的能力。
仅解码器大语言模型的位置偏差
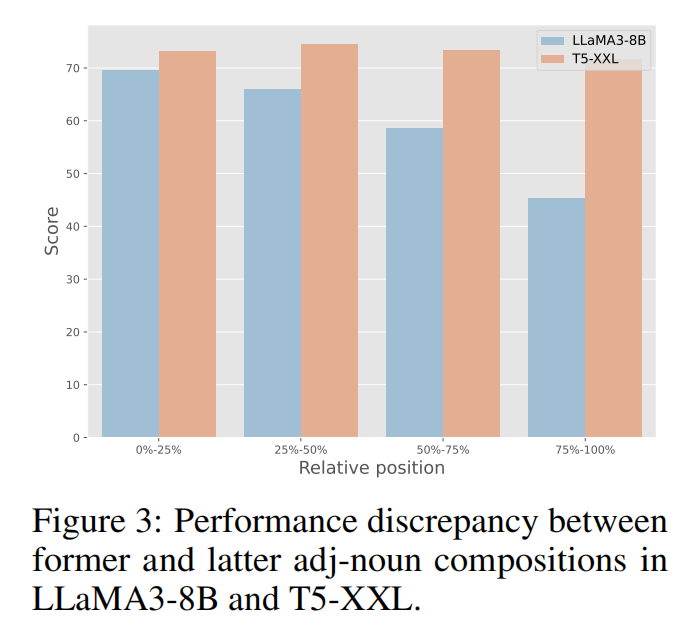
本文构建了一个基准来评估图像提示中不同位置的所有形容词-名词组合的图像-文本对齐情况。遵循传统的文本到图像生成基准,提取所有形容词-名词组合,并获得它们在每个图像提示中的相对位置。这些形容词-名词组合可以很容易地转换为问题。然后,本文将生成的图像和问题输入到一个视觉问答模型中以获得其对齐分数。请参考补充材料以获取关于构建测试集的更多细节。如下图 3 所示,本文计算每个形容词-名词组合在提示内的平均对齐分数和相对位置。可以观察到带有 T5 编码器的扩散模型对位置变化表现出很强的稳健性,而带有仅解码器大语言模型的模型在后面的位置表现不佳。这种固有的位置偏差显著损害了仅解码器大语言模型的提示编码能力。
LLM-infused Diffuser
整合大语言模型和扩散模型
为了弥合预训练优化和提示编码之间的差距,本文利用大语言模型的指令跟随能力,以鼓励它关注给定标题中的图像内容。此外,本文还提出了精炼器模块来减轻大语言模型文本embedding的固有位置偏差。通过结合这些设计,开发了一个名为“ LLM-infused Diffuser”的框架,它可以灵活地注入当前最先进的大语言模型,以释放其强大的文本理解能力。
如下图 5 所示,LLM-infused Diffuser的流程包括四个部分:
- 在图像提示之前插入系统提示和指令,以鼓励大语言模型关注图像内容并突出其属性。
- 带有指令的图像提示可以由多个冻结的大语言模型分别编码。
- 采用不同的语言token精炼器模块来消除这些大语言模型的文本embedding的位置偏差。
- 借助协作精炼器,来自大语言模型的文本特征被协同精炼,从而产生更稳健的表示。
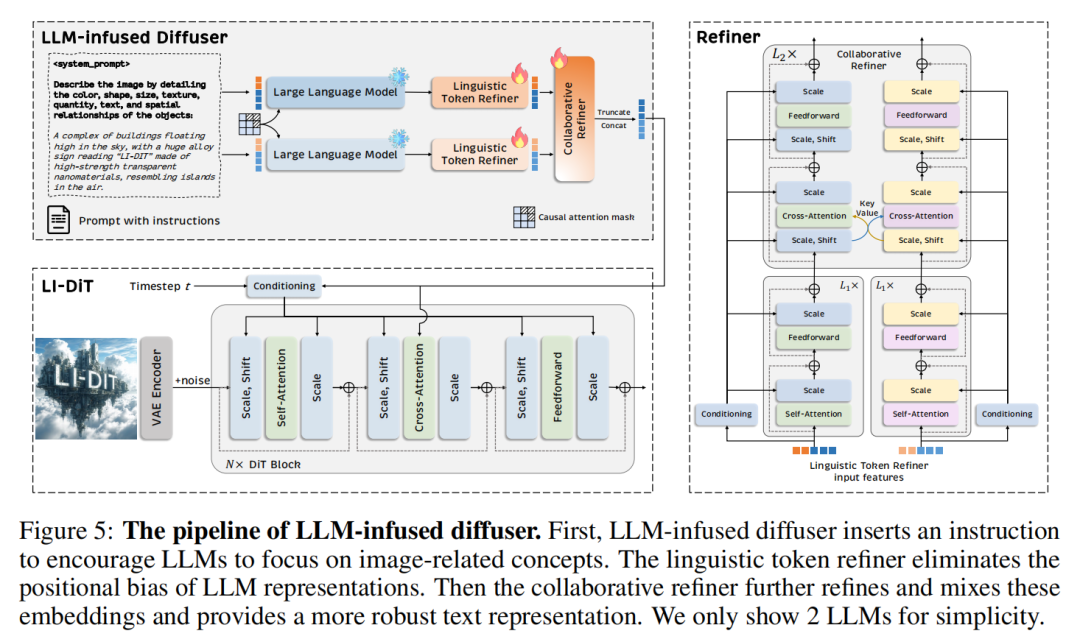
输入提示。受到大语言模型强大的指令跟随能力的启发,本文旨在利用这种能力迫使大语言模型关注提示中的关键图像内容,并促进文本表示与文本到图像合成任务之间的对齐。具体来说,本文提议在传统的图像描述之前插入自定义指令。这样的指令提示大语言模型关注关键图像内容,例如图像中物体的属性以及物体之间的空间关系。在本文的实验中,采用了一个简单的指令:通过详细描述物体的颜色、形状、大小、纹理、数量、文字和空间关系来描述图像。如上图 4 所示,如果不提供明确的指令,大语言模型往往会生成与图像上下文无关的内容。当向大语言模型提供指令和图像提示时,它将遵循指令专注于与图像相关的概念,以详细描述图像,并根据给定的提示提供对齐的表示。大语言模型的输出embedding将由后续的精炼器模块进一步处理。
语言token精炼器。在大语言模型的因果注意力层中,当前token只能关注到之前的token,因此这极大地损害了全局文本表示建模。例如,文本token序列中的最后一个token只能被其自身关注。为了减轻仅解码器大语言模型的这种位置偏差,本文插入一个语言token精炼器模块来精炼每个大语言模型有偏差的输出表示。如上图 5 所示,每个精炼器模块包含一堆Transformer块,它由一个自注意力层、一个前馈层(FFN)和一个自适应门控模块组成。对于自注意力层,直接丢弃大语言模型的因果mask来执行全注意力,这使得后面的token的表示可以被前面的token关注。每层的输出特征由自适应门控网络控制,其权重初始化为零以获得更好的训练稳定性。具体来说,本文首先对大语言模型表示进行平均池化,然后将池化后的表示与时间步 t 的embedding通过元素级求和进行合并。门控网络将这种时间步感知和上下文感知的表示作为输入来执行精确的信息注入。精炼器的最终输出表示将共同被馈送到协作精炼器中进行增强。
协作精炼器。为了进一步提高文本理解能力,本文采用多个大语言模型和语言token精炼器进行提示编码,并通过所提出的协作精炼器协同精炼这些表示。来自多个语言token精炼器的表示由多个平行分支分别处理,并且一个分支中的每个块都包含一个交叉注意力和前馈神经网络层。此外,本文使用一种调制机制,根据时间步和文本上下文来调节协作精炼器的每一层。这种调制采用与语言token精炼器中上述门控网络相同的输入。该模块中的分支通过多个平行的交叉注意力层连接,在这里文本表示可以进行协同精炼。具体来说,交叉注意力层将当前分支的特征作为查询,将其他分支的特征作为键和值来精炼当前特征。最后截断输出的token序列,丢弃指令token,并通过连接混合这两种表示。这种混合并精炼后的表示可以灵活地集成到扩散模型中,以提供有区分度的文本条件信息。
LLM-infused Diffuser Transformer
本文提出的注入大语言模型的 Transformer可以灵活地集成到当前的扩散模型中。考虑到扩散 Transformer 显著的扩展能力,本文开发了一个名为注入大语言模型的扩散 Transformer(LI-DiT)的扩散模型。
遵循 DiT 的范例,LI-DiT 将来自变分自动编码器(VAE)潜在空间的有噪表示作为输入,并将空间输入转换为token序列。LI-DiT 的每个Transformer块包含一个自注意力层、一个交叉注意力层、一个前馈神经网络层和调制模块。交叉注意力层可以将注入大语言模型的扩散器提取的文本条件信息注入token序列中。调制模块接收时间步embedding和文本表示以提供额外的条件信息。与之前工作中的二维位置embedding设计不同,本文采用基于卷积的位置embedding。在扩散Transformer中的补丁化层之后,直接采用一个 ResBlock 作为位置embedding模块。卷积算子的平移不变性可以有效地为Transformer算子引入位置信息。因此,LI-DiT 可以支持任意分辨率的图像生成,而无需额外的设计修改。
大规模的 Transformer 模型通常会遭受不稳定的梯度和数值精度问题,导致在训练过程中损失发散。为了解决训练不稳定的问题,本文纳入了在大规模视觉或语言模型训练中采用的若干策略。首先,在自注意力层和交叉注意力层中都引入了 QK 归一化。RMSNorm 层将在点积计算注意力分数之前对查询和关键token进行归一化。这样的操作确保了注意力分数的数值稳定性,并避免了来自分布外值的不稳定梯度。此外,考虑到 bfloat16 更广泛的数值表示范围,本文最终采用了 bfloat16 混合精度训练策略。
实验
实现细节
模型架构。本文的实验默认在较小的模型 LI-DiT-1B 上进行。采用 LLaMA3-8B 和 Qwen1.5-7B并结合多模态指令微调 作为 LI-DiT-1B 和 LI-DiT-10B 的双文本编码器。对于消融研究基线,本文只保留 LLaMA3-8B 以降低训练成本。本文在语言token精炼器中采用 2 个块,在协作精炼器中采用 1 个块。在实验中, 本文将来自倒数第三个Transfomer 块的文本embedding作为每个大语言模型的输出。关于 LI-DiT-1B 和 LI-DiT-10B 的详细架构,请参考补充材料。
训练数据。所有的探索和消融实验都在 ImageNet 数据集和 CC12M 数据集的一个子集上进行训练。本文为 ImageNet 的每个样本分配“一张{class}的照片”的文本提示,并从 CC12M 中随机选择 130 万图像-文本对。遵循之前的工作,本文混合了原始描述和由CogVLM生成的合成描述。将 LI-DiT 与其他领先的模型进行比较时,本文使用了一个具有十亿级图像-文本对的大规模训练数据集,包括 LAION-5B和其他包含英语和中文的内部数据集,这使 LI-DiT 具有双语理解能力。遵循Stable Diffusion,当来自 LAION 的图像-文本对的美学评分低于 4.7 时,本文将其移除。低分辨率图像和包括网址和标签的低质量提示也被移除。具体来说,本文仅从这个大规模数据集中抽样 3000 万图像-文本对来训练 LI-DiT-1B,并使用所有十亿级对来训练 LI-DiT-10B。
训练细节。遵循潜在扩散模型(LDM)的范例,本文利用一个变分自编码器(VAE)编码器将图像表示投影到潜在空间。本文训练一个具有 8 倍下采样率和 16 个通道的变分自编码器以获得更好的图像生成效果。本文不使用任何数据增强策略。遵循 RAPHEL中的多尺度训练,根据图像的纵横比将图像分组。只有具有相似纵横比的图像才会构成一个批次。对于在 300 万图像-文本对上进行的消融实验,本文以 256 的分辨率用 256 的batch大小和 的学习率训练模型 30 万次迭代。对于 LI-DiT-1B 的训练,本文将批次大小增加到 2048 并将迭代次数增加到 50 万。在训练 LI-DiT-10B 时,批次大小是 4096,迭代次数超过 100 万。本文在训练期间直接采用 512 的分辨率,然后用高质量数据将其微调至 1024 分辨率以进一步提高美学质量。
评估指标。对于定量评估,本文主要考虑 T2I-CompBench、DPG-Bench和 GenEval 基准。本文还引入了人类评估以更好地理解艺术和美学质量。请注意,消融研究中的“T2I-平均”是指 T2I-CompBench 属性指标的平均得分。
性能比较
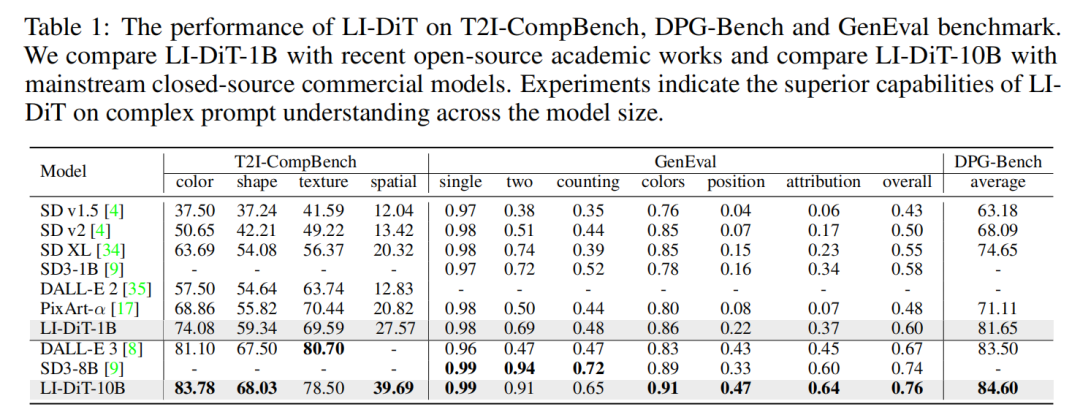
定量评估。在定量评估中,本文专注于生成图像与输入提示之间的一致性。如下表 1 所示,本文选择 T2I-CompBench、DPG-Bench 和 GenEval 基准来评估 LI-DiT-1B 和 LI-DiT-10B 的生成能力。T2I-CompBench 和 GenEval 基准由简短提示组成,侧重于组合评估。DPG-Bench 是用复杂密集的提示构建的。与像 SDXL 和 PixArt-α这样的开源学术作品相比,LI-DiT-1B 在所有基准上都大幅优于它们。本文还将 LI-DiT-10B 与 DALL-E 3 和Stable Diffusion 3(8B)这两个主流的闭源商业模型进行比较。这一显著的改进进一步验证了本文的大语言模型融合扩散器的有效性。
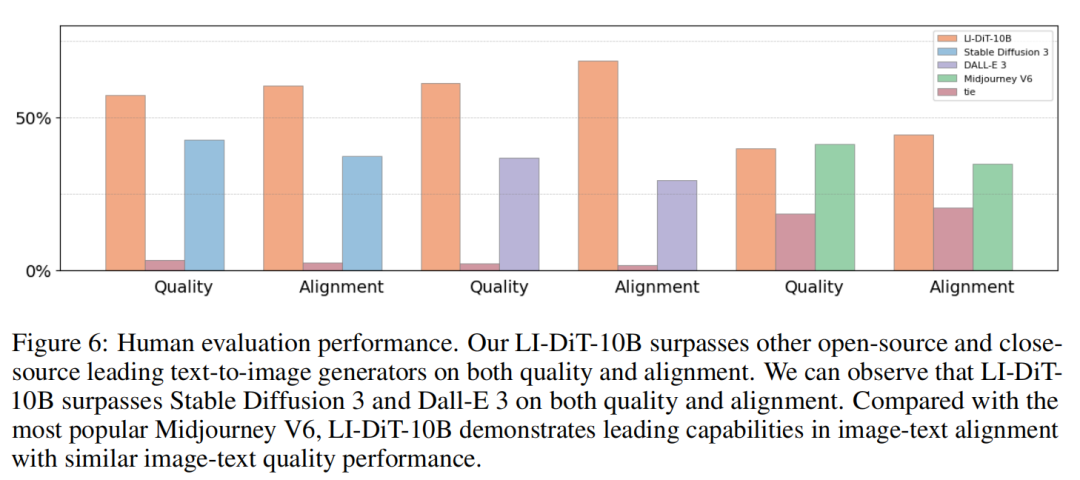
人类评估。定量评估指标不能直接衡量艺术和美学质量。遵循先前的工作,本文也进行人类评估,以令人信服地将 LI-DiT-10B 与Stable Diffusion 3、DALL-E 3 和Midjourney V6 进行比较。本文的评估数据集包含 200 个具有不同风格和场景的提示。来自 LI-DiT-10B 的图像和来自竞争对手的图像将构成一个评估对。人类评估者将从图像质量和图像-文本对齐的角度比较图像对。下图 6 中的结果表明,LI-DiT-10B 在图像-文本对齐和图像质量方面都可以超过 DALLE-3 和Stable Diffusion 3。与最受欢迎的商业模型Midjourney V6 相比,LI-DiT-10B 在图像-文本对齐方面表现出领先的能力,同时具有类似的图像-文本质量表现。在下图 7 中,本文展示了一些随机抽样的案例以进行清晰比较。此外还在图 8 和图 9 中提供了一些高质量图像。

消融研究
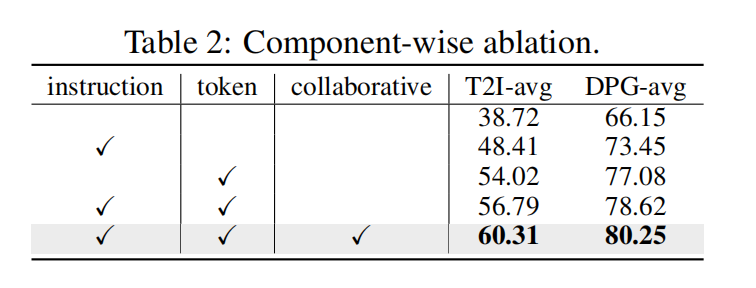
组件级消融研究。如下表 2 所示,本文进行组件级消融研究。本文采用预训练的 LLaMA3-8B 的 DiT 作为基线设置。首先,观察到在将指令引入输入提示或把语言token精炼器合并到基线后性能有一致的提升。当同时利用这两种设计时,在两个基准上的图像-文本对齐性能继续提高。此外,本文引入一个额外强大的大语言模型,Qwen1.5-7B,并进行多模态微调以验证协同精炼器的有效性。大语言模型融合策略进一步增强了扩散模型对提示的理解能力。这些结果清楚地验证了每个提出组件的有效性。
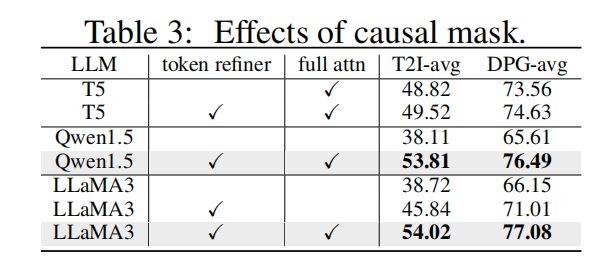
因果Mask的影响。在这个实验中本文研究因果Mask对提示编码的影响。如下表 3 所示,在大语言模型之后插入具有完全注意力的语言token精炼器显著提高了性能。然而,这个精炼器未能提高具有双向注意力的 T5 编码器的性能。如果将大语言模型的因果Mask引入到精炼器中,在 LLaMA3-8B 和 Qwen1.5-7B 中都会出现严重的性能下降。这些结果表明因果Mask是损害大语言模型提示编码能力的一个核心因素,而本文提出的精炼器可以消除这种位置偏差。
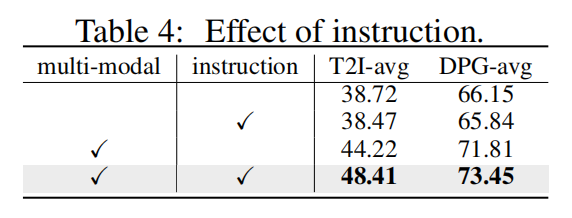
指令的效果。为了验证指令的有效性,本文在下表 4 中进行了一项消融实验。首先,本文发现提示指令对于使用没有指令微调的基础 LLaMA3-8B 模型未能带来增益。如果将基础模型改为多模态指令微调变体,对齐分数可以显著提高。由于指令微调带来的强大遵循指令能力,插入指令可以进一步提升性能。这个结果表明多模态指令微调数据有助于大语言模型更好地描述图像并突出图像内的关键元素。此外,指令能够鼓励大语言模型关注给定提示中的图像内容。
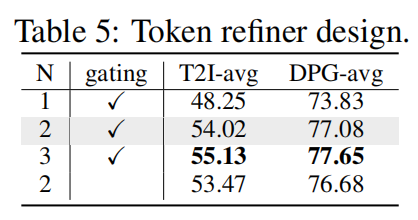
语言token精炼器设计。如下表 5 所示,本文对语言token精炼器的设计进行实验。首先,将本文的模型与精炼器中具有不同块数的其他变体进行比较。观察到当精炼器中的块数增加时性能有一致的提升。然而,当语言token精炼器中有 2 个块时这种提升并不显著。因此,本文在token精炼器中采用 2 个块来实现复杂性和性能之间的最佳平衡。此外,本文还消融了精炼器中门控网络的效果。当移除门控网络时,在两个基准上的性能都下降了。这表明时间和文本上下文的条件信息有助于更好的图像-文本对齐。
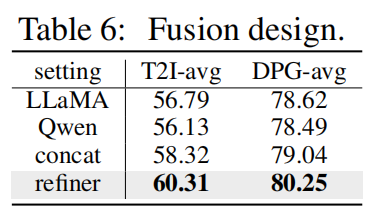
协同精炼器的效果。如下表 6 所示,本文观察到具有简单融合技术的模型可以优于具有单个大语言模型的其他对应模型。此外,协同精炼器可以在这种拼接融合的基础上进一步提升性能。这样的结果表明一种有效的表示融合方法可以进一步增强大语言模型的能力。
结论
针对在采用仅解码器的大语言模型来编码提示时在文本到图像生成任务中表现不佳的情况,本文探索了大语言模型在扩散模型提示编码中的作用。通过实验和分析,本文确定了限制仅解码器的大语言模型作为扩散模型的有效文本编码器的核心因素,即下一个token预测训练与扩散模型中对判别性提示特征的要求之间的不一致,以及仅解码器架构引入的内在位置偏差。为了处理这些问题,提出了一个新颖的框架来充分利用大语言模型的能力。本文还基于该框架进一步设计了一个注入大语言模型的扩散 Transformer(LI-DiT)。LI-DiT 超越了最先进的开源模型以及包括 Stable Diffusion 3、DALLE-3 和 Midjourney V6 在内的主流闭源商业模型。
限制和潜在的社会负面影响
由于计算资源有限,本文对具有 70 亿参数的大语言模型进行实验。在未来的工作中,本文将在具有 130 亿或 700 亿参数的更大的大语言模型中进一步验证注入大语言模型的扩散的有效性。潜在的负面社会影响是图像可能包含有误导性或虚假信息。本文将在数据处理方面进行广泛的努力来处理这个问题。
参考文献
[1] Exploring the Role of Large Language Models in Prompt Encoding for Diffusion Models
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-06-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号