Transformers 4.37 中文文档(三十二)

Transformers 4.37 中文文档(三十二)

ApacheCN_飞龙
发布于 2024-06-26 16:03:21
发布于 2024-06-26 16:03:21
ESM
原文链接:
huggingface.co/docs/transformers/v4.37.2/en/model_doc/esm
概述
本页面提供了 Meta AI 基础人工智能研究团队的 Transformer 蛋白质语言模型的代码和预训练权重,提供了最先进的 ESMFold 和 ESM-2,以及之前发布的 ESM-1b 和 ESM-1v。Transformer 蛋白质语言模型是由 Alexander Rives、Joshua Meier、Tom Sercu、Siddharth Goyal、Zeming Lin、Jason Liu、Demi Guo、Myle Ott、C. Lawrence Zitnick、Jerry Ma 和 Rob Fergus 在论文Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences中引入的。该论文的第一个版本于 2019 年预印。
ESM-2 在一系列结构预测任务中表现优异,胜过所有经过测试的单序列蛋白质语言模型,并实现了原子分辨率结构预测。该模型是由 Zeming Lin、Halil Akin、Roshan Rao、Brian Hie、Zhongkai Zhu、Wenting Lu、Allan dos Santos Costa、Maryam Fazel-Zarandi、Tom Sercu、Sal Candido 和 Alexander Rives 在论文Language models of protein sequences at the scale of evolution enable accurate structure prediction中发布的。
该论文还介绍了 ESMFold。它使用了一个 ESM-2 干部,带有一个可以以最先进的准确性预测折叠蛋白质结构的头部。与AlphaFold2不同,它依赖于大型预训练蛋白质语言模型干部的标记嵌入,并且在推断时不执行多序列比对(MSA)步骤,这意味着 ESMFold 检查点完全是“独立的” - 它们不需要已知蛋白质序列和结构的数据库以及相关的外部查询工具来进行预测,并且因此速度更快。
来自“Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences”的摘要是
在人工智能领域,通过无监督学习实现的数据规模和模型容量的结合,推动了表示学习和统计生成方面的重大进展。在生命科学领域,预期的测序增长将带来有关自然序列多样性的前所未有的数据。在进化规模上进行蛋白质语言建模是生物学预测和生成人工智能的逻辑步骤。为此,我们使用无监督学习在跨越进化多样性的 250 亿蛋白质序列中训练了一个深度上下文语言模型,共计 860 亿个氨基酸。所得模型包含有关生物性质的信息。这些表示仅从序列数据中学习而来。学习到的表示空间具有多尺度组织,反映了从氨基酸的生化性质到蛋白质的远程同源的结构。表示中编码了有关二级和三级结构的信息,并可以通过线性投影进行识别。表示学习产生了能够在一系列应用中泛化的特征,实现了最先进的突变效应和二级结构的监督预测,并改进了长程接触预测的最先进特征。
来自“Language models of protein sequences at the scale of evolution enable accurate structure prediction”的摘要是
最近已经证明,大型语言模型在规模上具有新兴的能力,超越简单的模式匹配,进行更高级别的推理,并生成逼真的图像和文本。虽然在蛋白质序列上训练的语言模型已经在较小规模上进行了研究,但对于它们在扩大规模时学习到的生物学知识知之甚少。在这项工作中,我们训练了具有 150 亿参数的模型,这是迄今为止评估的最大蛋白质语言模型。我们发现随着模型的扩大,它们学习到的信息使得能够预测蛋白质的三维结构,分辨率达到单个原子。我们提出了 ESMFold,用于直接从蛋白质的个体序列进行高精度端到端的原子级结构预测。ESMFold 对于低困惑度且被语言模型充分理解的序列具有与 AlphaFold2 和 RoseTTAFold 相似的准确性。ESMFold 推理速度比 AlphaFold2 快一个数量级,使得能够在实际时间范围内探索宏基因组蛋白质的结构空间。
原始代码可以在 这里 找到,并由 Meta AI 的 Fundamental AI Research 团队开发。ESM-1b、ESM-1v 和 ESM-2 由 jasonliu 和 Matt 贡献给了 HuggingFace。
ESMFold 由 Matt 和 Sylvain 贡献给了 HuggingFace,特别感谢 Nikita Smetanin、Roshan Rao 和 Tom Sercu 在整个过程中的帮助!
使用提示
- ESM 模型是使用掩码语言建模(MLM)目标进行训练的。
- HuggingFace 移植的 ESMFold 使用了 openfold 库的部分内容。
openfold库使用 Apache License 2.0 许可。
资源
- 文本分类任务指南
- 标记分类任务指南
- 掩码语言建模任务指南
EsmConfig
class transformers.EsmConfig
( vocab_size = None mask_token_id = None pad_token_id = None hidden_size = 768 num_hidden_layers = 12 num_attention_heads = 12 intermediate_size = 3072 hidden_dropout_prob = 0.1 attention_probs_dropout_prob = 0.1 max_position_embeddings = 1026 initializer_range = 0.02 layer_norm_eps = 1e-12 position_embedding_type = 'absolute' use_cache = True emb_layer_norm_before = None token_dropout = False is_folding_model = False esmfold_config = None vocab_list = None **kwargs )参数
-
vocab_size(int, optional) — ESM 模型的词汇表大小。定义了在调用ESMModel时可以表示的不同标记数量。 -
mask_token_id(int, optional) — 词汇表中掩码标记的索引。由于“mask-dropout”缩放技巧,必须在配置中包含此项,该技巧将根据掩码标记的数量来缩放输入。 -
pad_token_id(int, optional) — 词汇表中填充标记的索引。由于 ESM 代码的某些部分使用此标记而不是注意力掩码,因此必须在配置中包含此项。 -
hidden_size(int, optional, 默认为 768) — 编码器层和池化器层的维度。 -
num_hidden_layers(int, optional, 默认为 12) — Transformer 编码器中的隐藏层数量。 -
num_attention_heads(int, optional, 默认为 12) — Transformer 编码器中每个注意力层的注意力头数量。 -
intermediate_size(int, optional, 默认为 3072) — Transformer 编码器中“中间”(通常称为前馈)层的维度。 -
hidden_dropout_prob(float, optional, 默认为 0.1) — 嵌入层、编码器和池化器中所有全连接层的丢弃概率。 -
attention_probs_dropout_prob(float, optional, 默认为 0.1) — 注意力概率的丢弃比率。 -
max_position_embeddings(int, optional, 默认为 1026) — 该模型可能会与之一起使用的最大序列长度。通常将其设置为较大的值以防万一(例如,512、1024 或 2048)。 -
initializer_range(float, optional, defaults to 0.02) — 用于初始化所有权重矩阵的截断正态初始化器的标准差。 -
layer_norm_eps(float, optional, defaults to 1e-12) — 层归一化层使用的 epsilon。 -
position_embedding_type(str, optional, defaults to"absolute") — 位置嵌入的类型。选择"absolute","relative_key","relative_key_query", "rotary"中的一个。对于位置嵌入使用"absolute"。有关"relative_key"的更多信息,请参考 Self-Attention with Relative Position Representations (Shaw et al.)。有关"relative_key_query"的更多信息,请参考 [Improve Transformer Models with Better Relative Position Embeddings (Huang et al.)] 中的 Method 4 (https://arxiv.org/abs/2009.13658)。 -
is_decoder(bool, optional, defaults toFalse) — 模型是否用作解码器。如果为False,则模型用作编码器。 -
use_cache(bool, optional, defaults toTrue) — 模型是否应返回最后的键/值注意力(并非所有模型都使用)。仅在config.is_decoder=True时相关。 -
emb_layer_norm_before(bool, optional) — 是否在嵌入之后但在网络主干之前应用层归一化。 -
token_dropout(bool, defaults toFalse) — 启用此选项时,掩码标记将被视为已通过输入丢失删除。
这是用于存储 ESMModel 配置的配置类。根据指定的参数实例化一个 ESM 模型,定义模型架构。使用默认值实例化配置将产生类似于 ESM facebook/esm-1b 架构的配置。
配置对象继承自 PretrainedConfig,可用于控制模型输出。阅读来自 PretrainedConfig 的文档以获取更多信息。
示例:
>>> from transformers import EsmModel, EsmConfig
>>> # Initializing a ESM facebook/esm-1b style configuration >>> configuration = EsmConfig()
>>> # Initializing a model from the configuration >>> model = ESMModel(configuration)
>>> # Accessing the model configuration >>> configuration = model.configto_dict
( ) → export const metadata = 'undefined';Dict[str, any]返回
Dict[str, any]
包含构成此配置实例的所有属性的字典,
将此实例序列化为 Python 字典。覆盖默认的 to_dict()。
EsmTokenizer
class transformers.EsmTokenizer
( vocab_file unk_token = '<unk>' cls_token = '<cls>' pad_token = '<pad>' mask_token = '<mask>' eos_token = '<eos>' **kwargs )构造一个 ESM 分词器。
build_inputs_with_special_tokens
( token_ids_0: List token_ids_1: Optional = None )get_special_tokens_mask
( token_ids_0: List token_ids_1: Optional = None already_has_special_tokens: bool = False ) → export const metadata = 'undefined';A list of integers in the range [0, 1]参数
-
token_ids_0(List[int]) — 第一个序列的 id 列表。 -
token_ids_1(List[int], optional) — 第二个序列的 id 列表。 -
already_has_special_tokens(bool, optional, defaults toFalse) — 标记列表是否已经格式化为模型的特殊标记。
返回
一个范围在 [0, 1] 内的整数列表
1 表示特殊标记,0 表示序列标记。
从没有添加特殊标记的标记列表中检索序列 id。当使用 tokenizer 的 prepare_for_model 或 encode_plus 方法添加特殊标记时,将调用此方法。
create_token_type_ids_from_sequences
( token_ids_0: List token_ids_1: Optional = None ) → export const metadata = 'undefined';List[int]参数
-
token_ids_0(List[int]) — 第一个标记化序列。 -
token_ids_1(List[int],可选)- 第二个令牌化序列。
返回
List[int]
令牌类型 ID。
创建与传递的序列相对应的令牌类型 ID。什么是令牌类型 ID?
如果模型有特殊的构建方式,应该在子类中重写。
save_vocabulary
( save_directory filename_prefix )Pytorch 隐藏 Pytorch 内容
EsmModel
类 transformers.EsmModel
( config add_pooling_layer = True )参数
config(EsmConfig)- 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只加载配置。查看 from_pretrained()方法以加载模型权重。
裸 ESM 模型变压器输出原始隐藏状态,没有特定的头部。
这个模型继承自 PreTrainedModel。查看超类文档,了解库为所有模型实现的通用方法(如下载或保存、调整输入嵌入、修剪头等)。
这个模型也是一个 PyTorch torch.nn.Module子类。将其用作常规的 PyTorch 模块,并参考 PyTorch 文档以获取有关一般用法和行为的所有相关信息。
该模型可以作为编码器(仅具有自注意力)以及解码器行为,此时在自注意力层之间添加了一层交叉注意力,遵循Ashish Vaswani、Noam Shazeer、Niki Parmar、Jakob Uszkoreit、Llion Jones、Aidan N. Gomez、Lukasz Kaiser 和 Illia Polosukhin 所描述的架构。
为了作为解码器行为,模型需要使用配置中设置为True的is_decoder参数进行初始化。要在 Seq2Seq 模型中使用,模型需要使用is_decoder参数和add_cross_attention设置为True进行初始化;然后期望将encoder_hidden_states作为输入传递。
前进
( input_ids: Optional = None attention_mask: Optional = None position_ids: Optional = None head_mask: Optional = None inputs_embeds: Optional = None encoder_hidden_states: Optional = None encoder_attention_mask: Optional = None past_key_values: Optional = None use_cache: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.BaseModelOutputWithPoolingAndCrossAttentions or tuple(torch.FloatTensor)参数
-
input_ids(形状为((batch_size, sequence_length))的torch.LongTensor)- 词汇表中输入序列令牌的索引。 可以使用 AutoTokenizer 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。 什么是输入 ID? -
attention_mask(形状为((batch_size, sequence_length))的torch.FloatTensor,可选)- 避免在填充令牌索引上执行注意力的掩码。掩码值选择在[0, 1]中:- 1 对于“未屏蔽”的标记,
- 0 对于“屏蔽”的标记。
什么是注意力掩码?
-
position_ids(形状为((batch_size, sequence_length))的torch.LongTensor,可选)- 每个输入序列令牌在位置嵌入中的位置索引。在范围[0, config.max_position_embeddings - 1]中选择。 什么是位置 ID? -
head_mask(torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — 用于使自注意力模块的选定头部失效的掩码。掩码值选在[0, 1]之间:- 1 表示头部未被掩盖,
- 0 表示头部被掩盖。
-
inputs_embeds(torch.FloatTensorof shape((batch_size, sequence_length), hidden_size), optional) — 可选地,可以直接传递嵌入表示而不是传递input_ids。如果您想要更多控制如何将input_ids索引转换为相关向量,而不是使用模型的内部嵌入查找矩阵,则这很有用。 -
output_attentions(bool, optional) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量中的attentions。 -
output_hidden_states(bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量中的hidden_states。 -
return_dict(bool, optional) — 是否返回 ModelOutput 而不是普通元组。 -
encoder_hidden_states(torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — 编码器最后一层的隐藏状态序列。如果模型配置为解码器,则在交叉注意力中使用。 -
encoder_attention_mask(torch.FloatTensorof shape(batch_size, sequence_length), optional) — 用于避免在编码器输入的填充标记索引上执行注意力的掩码。如果模型配置为解码器,则在交叉注意力中使用此掩码。掩码值选在[0, 1]之间:- 1 表示未被掩盖的标记,
- 0 表示被掩盖的标记。
-
past_key_values(tuple(tuple(torch.FloatTensor)),长度为config.n_layers,每个元组有 4 个形状为(batch_size, num_heads, sequence_length - 1, embed_size_per_head)的张量) — 包含注意力块的预计算键和值隐藏状态。可用于加速解码。 如果使用past_key_values,用户可以选择仅输入最后一个形状为(batch_size, 1)的decoder_input_ids(这些没有将其过去的键值状态提供给此模型的输入)而不是形状为(batch_size, sequence_length)的所有decoder_input_ids。 -
use_cache(bool, optional) — 如果设置为True,则返回past_key_values键值状态,并可用于加速解码(参见past_key_values)。
返回
transformers.modeling_outputs.BaseModelOutputWithPoolingAndCrossAttentions 或tuple(torch.FloatTensor)
transformers.modeling_outputs.BaseModelOutputWithPoolingAndCrossAttentions 或一个torch.FloatTensor元组(如果传递了return_dict=False或config.return_dict=False)包含根据配置(EsmConfig)和输入的不同元素。
-
last_hidden_state(torch.FloatTensorof shape(batch_size, sequence_length, hidden_size)) — 模型最后一层的隐藏状态序列的输出。 -
pooler_output(torch.FloatTensorof shape(batch_size, hidden_size)) — 经过进一步处理的序列第一个标记(分类标记)的最后一层隐藏状态(辅助预训练任务中使用的层)。例如,对于 BERT 系列模型,这将返回经过线性层和 tanh 激活函数处理后的分类标记。线性层权重是从预训练期间的下一个句子预测(分类)目标中训练的。 -
hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回)— 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(如果模型有嵌入层,则为嵌入的输出+每层的输出)。 模型在每一层输出的隐藏状态以及可选的初始嵌入输出。 -
attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回)— 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。 在自注意力头中,注意力 softmax 之后的注意力权重,用于计算加权平均值。 -
cross_attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True和config.add_cross_attention=True或config.output_attentions=True时返回)— 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。 解码器的交叉注意力层的注意力权重,在注意力 softmax 之后,用于计算交叉注意力头中的加权平均值。 -
past_key_values(tuple(tuple(torch.FloatTensor)),可选,当传递use_cache=True或config.use_cache=True时返回)— 长度为config.n_layers的tuple(torch.FloatTensor)元组,每个元组有 2 个形状为(batch_size, num_heads, sequence_length, embed_size_per_head)的张量,如果config.is_encoder_decoder=True,还有 2 个形状为(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)的张量。 包含预先计算的隐藏状态(自注意力块中的键和值,以及在交叉注意力块中,如果config.is_encoder_decoder=True,还可以使用past_key_values输入)以加速顺序解码。
EsmModel 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的步骤需要在此函数内定义,但应该在此之后调用Module实例,而不是调用此函数,因为前者会处理运行前后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoTokenizer, EsmModel
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/esm2_t6_8M_UR50D")
>>> model = EsmModel.from_pretrained("facebook/esm2_t6_8M_UR50D")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_stateEsmForMaskedLM
class transformers.EsmForMaskedLM
( config )参数
config(EsmConfig)— 包含模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained()方法以加载模型权重。
在顶部带有语言建模头的 ESM 模型。
该模型继承自 PreTrainedModel。查看超类文档以获取库为所有模型实现的通用方法(如下载或保存、调整输入嵌入、修剪头等)。
该模型也是 PyTorch torch.nn.Module子类。将其用作常规 PyTorch 模块,并参考 PyTorch 文档以获取有关一般用法和行为的所有信息。
forward
( input_ids: Optional = None attention_mask: Optional = None position_ids: Optional = None head_mask: Optional = None inputs_embeds: Optional = None encoder_hidden_states: Optional = None encoder_attention_mask: Optional = None labels: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.MaskedLMOutput or tuple(torch.FloatTensor)参数
-
input_ids(形状为(batch_size, sequence_length)的torch.LongTensor)— 词汇表中输入序列标记的索引。 可以使用 AutoTokenizer 获取索引。有关详细信息,请参见 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。 什么是输入 ID? -
attention_mask(形状为(batch_size, sequence_length)的torch.FloatTensor,可选)— 用于避免在填充标记索引上执行注意力的掩码。选择的掩码值在[0, 1]中:- 1 表示未被“掩盖”的标记,
- 0 表示被“掩盖”的标记。
什么是注意力掩码?
-
position_ids(形状为(batch_size, sequence_length)的torch.LongTensor,可选)— 每个输入序列标记在位置嵌入中的位置索引。在范围[0, config.max_position_embeddings - 1]中选择。 什么是位置 ID? -
head_mask(形状为(num_heads,)或(num_layers, num_heads)的torch.FloatTensor,可选)— 用于使自注意力模块的选定头部失效的掩码。选择的掩码值在[0, 1]中:- 1 表示未被“掩盖”的头部,
- 0 表示头部被“掩盖”。
-
inputs_embeds(形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor,可选)— 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果您想要更多控制如何将input_ids索引转换为相关向量,这将非常有用,而不是使用模型的内部嵌入查找矩阵。 -
output_attentions(bool,可选)— 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 -
output_hidden_states(bool,可选)— 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 -
return_dict(bool,可选)— 是否返回 ModelOutput 而不是普通元组。 -
labels(形状为(batch_size, sequence_length)的torch.LongTensor,可选)— 用于计算掩码语言建模损失的标签。索引应在[-100, 0, ..., config.vocab_size]中(请参阅input_ids文档字符串)。索引设置为-100的标记将被忽略(掩盖),仅对具有标签在[0, ..., config.vocab_size]中的标记计算损失 -
kwargs(Dict[str, any],可选,默认为*{}*)— 用于隐藏已弃用的旧参数。
返回
transformers.modeling_outputs.MaskedLMOutput 或tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.MaskedLMOutput 或一个torch.FloatTensor元组(如果传递return_dict=False或当config.return_dict=False时)包含各种元素,具体取决于配置(EsmConfig)和输入。
-
loss(形状为(1,)的torch.FloatTensor,可选,在提供labels时返回)— 掩码语言建模(MLM)损失。 -
logits(形状为(batch_size, sequence_length, config.vocab_size)的torch.FloatTensor)— 语言建模头部的预测分数(SoftMax 之前每个词汇标记的分数)。 -
hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或当config.output_hidden_states=True时返回)— 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(如果模型具有嵌入层的输出,则为嵌入的输出+每层的输出)。 模型在每一层输出处的隐藏状态以及可选的初始嵌入输出。 -
attentions(tuple(torch.FloatTensor), 可选, 当传递output_attentions=True或当config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。 注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
EsmForMaskedLM 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的步骤需要在此函数内定义,但应该在此之后调用Module实例,而不是在此处调用,因为前者会负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoTokenizer, EsmForMaskedLM
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/esm2_t6_8M_UR50D")
>>> model = EsmForMaskedLM.from_pretrained("facebook/esm2_t6_8M_UR50D")
>>> inputs = tokenizer("The capital of France is <mask>.", return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> # retrieve index of <mask>
>>> mask_token_index = (inputs.input_ids == tokenizer.mask_token_id)[0].nonzero(as_tuple=True)[0]
>>> predicted_token_id = logits[0, mask_token_index].argmax(axis=-1)
>>> labels = tokenizer("The capital of France is Paris.", return_tensors="pt")["input_ids"]
>>> # mask labels of non-<mask> tokens
>>> labels = torch.where(inputs.input_ids == tokenizer.mask_token_id, labels, -100)
>>> outputs = model(**inputs, labels=labels)EsmForSequenceClassification
class transformers.EsmForSequenceClassification
( config )参数
config(EsmConfig) — 模型的所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained()方法以加载模型权重。
ESM 模型变压器,顶部带有序列分类/回归头(池化输出顶部的线性层),例如用于 GLUE 任务。
这个模型继承自 PreTrainedModel。查看超类文档以获取库为所有模型实现的通用方法(如下载或保存、调整输入嵌入、修剪头等)。
这个模型也是一个 PyTorch torch.nn.Module子类。将其用作常规的 PyTorch 模块,并参考 PyTorch 文档以获取与一般用法和行为相关的所有内容。
forward
( input_ids: Optional = None attention_mask: Optional = None position_ids: Optional = None head_mask: Optional = None inputs_embeds: Optional = None labels: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.SequenceClassifierOutput or tuple(torch.FloatTensor)参数
-
input_ids(torch.LongTensor,形状为(batch_size, sequence_length)) — 词汇表中输入序列标记的索引。 可以使用 AutoTokenizer 获取索引。查看 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()获取详细信息。 什么是输入 ID? -
attention_mask(torch.FloatTensor,形状为(batch_size, sequence_length),可选) — 用于避免在填充标记索引上执行注意力的掩码。选择的掩码值为[0, 1]:- 1 表示未被
masked的标记, - 0 表示被
masked的标记。
什么是注意力掩码?
- 1 表示未被
-
position_ids(torch.LongTensor,形状为(batch_size, sequence_length),可选) — 每个输入序列标记在位置嵌入中的位置索引。选择范围为[0, config.max_position_embeddings - 1]。 什么是位置 ID? -
head_mask(torch.FloatTensor,形状为(num_heads,)或(num_layers, num_heads),可选) — 用于使自注意力模块的选定头部失效的掩码。选择的掩码值为[0, 1]:- 1 表示头部未被
masked, - 0 表示头部被
masked。
- 1 表示头部未被
-
inputs_embeds(形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor,可选)— 可选地,可以直接传递嵌入表示,而不是传递input_ids。如果您想要更多控制权来将input_ids索引转换为相关向量,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 -
output_attentions(bool,可选)— 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的attentions。 -
output_hidden_states(bool,可选)— 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 -
return_dict(bool,可选)— 是否返回 ModelOutput 而不是普通元组。 -
labels(形状为(batch_size,)的torch.LongTensor,可选)— 用于计算序列分类/回归损失的标签。索引应在[0, ..., config.num_labels - 1]范围内。如果config.num_labels == 1,则计算回归损失(均方损失),如果config.num_labels > 1,则计算分类损失(交叉熵)。
返回值
transformers.modeling_outputs.SequenceClassifierOutput 或tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.SequenceClassifierOutput 或一个torch.FloatTensor元组(如果传递了return_dict=False或config.return_dict=False时)包含各种元素,具体取决于配置(EsmConfig)和输入。
-
loss(形状为(1,)的torch.FloatTensor,可选,当提供labels时返回)— 分类(如果config.num_labels==1则为回归)损失。 -
logits(形状为(batch_size, config.num_labels)的torch.FloatTensor)— 分类(如果config.num_labels==1则为回归)得分(SoftMax 之前)。 -
hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回)— 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(如果模型有嵌入层,则为嵌入的输出,+ 每层的输出)。 模型在每一层输出的隐藏状态以及可选的初始嵌入输出。 -
attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回)— 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。 在自注意力头中用于计算加权平均值的注意力 softmax 之后的注意力权重。
EsmForSequenceClassification 的前向方法,覆盖了__call__特殊方法。
尽管前向传播的配方需要在此函数内定义,但应该在此之后调用Module实例,而不是这个函数,因为前者负责运行预处理和后处理步骤,而后者则默默地忽略它们。
单标签分类示例:
>>> import torch
>>> from transformers import AutoTokenizer, EsmForSequenceClassification
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/esm2_t6_8M_UR50D")
>>> model = EsmForSequenceClassification.from_pretrained("facebook/esm2_t6_8M_UR50D")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_class_id = logits.argmax().item()
>>> # To train a model on `num_labels` classes, you can pass `num_labels=num_labels` to `.from_pretrained(...)`
>>> num_labels = len(model.config.id2label)
>>> model = EsmForSequenceClassification.from_pretrained("facebook/esm2_t6_8M_UR50D", num_labels=num_labels)
>>> labels = torch.tensor([1])
>>> loss = model(**inputs, labels=labels).loss多标签分类示例:
>>> import torch
>>> from transformers import AutoTokenizer, EsmForSequenceClassification
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/esm2_t6_8M_UR50D")
>>> model = EsmForSequenceClassification.from_pretrained("facebook/esm2_t6_8M_UR50D", problem_type="multi_label_classification")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_class_ids = torch.arange(0, logits.shape[-1])[torch.sigmoid(logits).squeeze(dim=0) > 0.5]
>>> # To train a model on `num_labels` classes, you can pass `num_labels=num_labels` to `.from_pretrained(...)`
>>> num_labels = len(model.config.id2label)
>>> model = EsmForSequenceClassification.from_pretrained(
... "facebook/esm2_t6_8M_UR50D", num_labels=num_labels, problem_type="multi_label_classification"
... )
>>> labels = torch.sum(
... torch.nn.functional.one_hot(predicted_class_ids[None, :].clone(), num_classes=num_labels), dim=1
... ).to(torch.float)
>>> loss = model(**inputs, labels=labels).lossEsmForTokenClassification
class transformers.EsmForTokenClassification
( config )参数
config(EsmConfig) — 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只加载配置。查看 from_pretrained()方法以加载模型权重。
ESM 模型在顶部带有一个标记分类头部(隐藏状态输出的顶部线性层),例如用于命名实体识别(NER)任务。
该模型继承自 PreTrainedModel。查看超类文档以获取库为所有模型实现的通用方法(例如下载或保存、调整输入嵌入、修剪头等)。
该模型也是 PyTorch torch.nn.Module的子类。将其用作常规的 PyTorch 模块,并参考 PyTorch 文档以获取有关一般用法和行为的所有相关信息。
forward
( input_ids: Optional = None attention_mask: Optional = None position_ids: Optional = None head_mask: Optional = None inputs_embeds: Optional = None labels: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.TokenClassifierOutput or tuple(torch.FloatTensor)参数
-
input_ids(torch.LongTensor,形状为(batch_size, sequence_length)) — 词汇表中输入序列标记的索引。 可以使用 AutoTokenizer 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。 什么是输入 ID? -
attention_mask(torch.FloatTensor,形状为(batch_size, sequence_length),optional) — 用于避免在填充标记索引上执行注意力的掩码。掩码值选在[0, 1]之间:- 1 表示未被遮蔽的标记,
- 0 表示被遮蔽的标记。
什么是注意力掩码?
-
position_ids(torch.LongTensor,形状为(batch_size, sequence_length),optional) — 每个输入序列标记在位置嵌入中的位置索引。选在范围[0, config.max_position_embeddings - 1]内。 什么是位置 ID? -
head_mask(torch.FloatTensor,形状为(num_heads,)或(num_layers, num_heads),optional) — 用于使自注意力模块中的特定头部失效的掩码。掩码值选在[0, 1]之间:- 1 表示头部未被遮蔽,
- 0 表示头部被遮蔽。
-
inputs_embeds(torch.FloatTensor,形状为(batch_size, sequence_length, hidden_size),optional) — 可选地,您可以直接传递嵌入表示,而不是传递input_ids。如果您想要更多控制如何将input_ids索引转换为相关向量,这将非常有用,而不是使用模型的内部嵌入查找矩阵。 -
output_attentions(bool, optional) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量中的attentions。 -
output_hidden_states(bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量中的hidden_states。 -
return_dict(bool, optional) — 是否返回一个 ModelOutput 而不是一个普通的元组。 -
labels(torch.LongTensor,形状为(batch_size, sequence_length),optional) — 用于计算标记分类损失的标签。索引应在[0, ..., config.num_labels - 1]内。
返回
transformers.modeling_outputs.TokenClassifierOutput 或tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.TokenClassifierOutput 或一个torch.FloatTensor元组(如果传递了return_dict=False或config.return_dict=False时)包含各种元素,具体取决于配置(EsmConfig)和输入。
-
loss(形状为(1,)的torch.FloatTensor,可选,当提供labels时返回)-分类损失。 -
logits(形状为(batch_size, sequence_length, config.num_labels)的torch.FloatTensor)-分类分数(SoftMax 之前)。 -
hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回)-形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(如果模型有嵌入层,则为嵌入输出的输出+每一层的输出)。 模型在每一层输出的隐藏状态加上可选的初始嵌入输出。 -
attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回)-形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。 在自注意力头中用于计算加权平均值的注意力权重 softmax 后。
EsmForTokenClassification 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的步骤需要在此函数内定义,但应该在此之后调用Module实例,而不是在此处调用,因为前者会负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoTokenizer, EsmForTokenClassification
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/esm2_t6_8M_UR50D")
>>> model = EsmForTokenClassification.from_pretrained("facebook/esm2_t6_8M_UR50D")
>>> inputs = tokenizer(
... "HuggingFace is a company based in Paris and New York", add_special_tokens=False, return_tensors="pt"
... )
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_token_class_ids = logits.argmax(-1)
>>> # Note that tokens are classified rather then input words which means that
>>> # there might be more predicted token classes than words.
>>> # Multiple token classes might account for the same word
>>> predicted_tokens_classes = [model.config.id2label[t.item()] for t in predicted_token_class_ids[0]]
>>> labels = predicted_token_class_ids
>>> loss = model(**inputs, labels=labels).lossEsmForProteinFolding
class transformers.EsmForProteinFolding
( config )参数
config(EsmConfig)-包含模型所有参数的模型配置类。使用配置文件初始化不会加载与模型关联的权重,只加载配置。查看 from_pretrained()方法以加载模型权重。
ESMForProteinFolding 是原始 ESMFold 模型的 HuggingFace 移植版。它由一个 ESM-2“干”部分和一个蛋白质折叠“头”部分组成,尽管与大多数其他输出头部不同,这个“头”部分在大小和运行时间上与模型的其余部分相似!它输出一个包含关于输入蛋白质的预测结构信息的字典。
此模型继承自 PreTrainedModel。查看超类文档以了解库为所有模型实现的通用方法(如下载或保存、调整输入嵌入、修剪头等)。
此模型也是 PyTorch torch.nn.Module子类。将其用作常规 PyTorch 模块,并参考 PyTorch 文档以获取有关一般用法和行为的所有相关信息。
forward
( input_ids: Tensor attention_mask: Optional = None position_ids: Optional = None masking_pattern: Optional = None num_recycles: Optional = None ) → export const metadata = 'undefined';transformers.models.esm.modeling_esmfold.EsmForProteinFoldingOutput or tuple(torch.FloatTensor)参数
-
input_ids(形状为(batch_size, sequence_length)的torch.LongTensor)-词汇表中输入序列标记的索引。 可以使用 AutoTokenizer 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。 什么是输入 ID? -
attention_mask(torch.FloatTensor,形状为(batch_size, sequence_length),可选) — 避免在填充令牌索引上执行注意力的掩码。掩码值选在[0, 1]之间:- 对于未被
masked的令牌为 1, - 对于被
masked的令牌为 0。
什么是注意力掩码?
- 对于未被
-
position_ids(torch.LongTensor,形状为(batch_size, sequence_length),可选) — 每个输入序列令牌在位置嵌入中的位置索引。选在范围[0, config.max_position_embeddings - 1]内。 什么是位置 ID? -
masking_pattern(torch.LongTensor,形状为(batch_size, sequence_length),可选) — 在训练期间要屏蔽的令牌位置,作为一种正则化形式。掩码值选在[0, 1]之间。 -
num_recycles(int,可选,默认为None) — 重复输入序列的次数。如果为None,则默认为config.num_recycles。 “Recycling”包括将折叠主干的输出作为输入传递给主干。在训练期间,每个批次的循环次数应该随着每次循环而变化,以确保模型学会在每次循环后输出有效的预测。在推断期间,num_recycles 应设置为模型训练的最大值,以获得最大准确性。因此,当此值设置为None时,将使用 config.max_recycles。
返回
transformers.models.esm.modeling_esmfold.EsmForProteinFoldingOutput或tuple(torch.FloatTensor)
一个transformers.models.esm.modeling_esmfold.EsmForProteinFoldingOutput或一个torch.FloatTensor元组(如果传递了return_dict=False或当config.return_dict=False时)包含根据配置(<class 'transformers.models.esm.configuration_esm.EsmConfig'>)和输入的不同元素。
-
frames(torch.FloatTensor) — 输出的框架。 -
sidechain_frames(torch.FloatTensor) — 输出的侧链框架。 -
unnormalized_angles(torch.FloatTensor) — 预测的未归一化主链和侧链扭转角度。 -
angles(torch.FloatTensor) — 预测的主链和侧链扭转角度。 -
positions(torch.FloatTensor) — 预测的主链和侧链原子位置。 -
states(torch.FloatTensor) — 蛋白质折叠主干的隐藏状态。 -
s_s(torch.FloatTensor) — 通过连接 ESM-2 LM 干每一层的隐藏状态派生的每个残基的嵌入。 -
s_z(torch.FloatTensor) — 成对残基嵌入。 -
distogram_logits(torch.FloatTensor) — 用于计算残基距离的 distogram 的输入 logits。 -
lm_logits(torch.FloatTensor) — ESM-2 蛋白质语言模型干输出的 logits。 -
aatype(torch.FloatTensor) — 输入的氨基酸(AlphaFold2 索引)。 -
atom14_atom_exists(torch.FloatTensor) — 每个原子是否存在于 atom14 表示中。 -
residx_atom14_to_atom37(torch.FloatTensor) — 在 atom14 和 atom37 表示之间的原子映射。 -
residx_atom37_to_atom14(torch.FloatTensor) — 在 atom37 和 atom14 表示之间的原子映射。 -
atom37_atom_exists(torch.FloatTensor) — 每个原子是否存在于 atom37 表示中。 -
residue_index(torch.FloatTensor) — 蛋白质链中每个残基的索引。除非使用内部填充令牌,否则这将是从 0 到sequence_length的整数序列。 -
lddt_head(torch.FloatTensor) — 用于计算 plddt 的 lddt 头部的原始输出。 -
plddt(torch.FloatTensor) — 每个残基的置信度分数。低置信度区域可能表明模型预测不确定的区域,或者蛋白质结构无序的区域。 -
ptm_logits(torch.FloatTensor) — 用于计算 ptm 的原始对数。 -
ptm(torch.FloatTensor) — TM-score 输出,代表模型对整体结构的高级置信度。 -
aligned_confidence_probs(torch.FloatTensor) — 对齐结构的每个残基的置信度分数。 -
predicted_aligned_error(torch.FloatTensor) — 模型预测与真实值之间的预测误差。 -
max_predicted_aligned_error(torch.FloatTensor) — 每个样本的最大预测误差。
EsmForProteinFolding 的前向方法,覆盖了 __call__ 特殊方法。
虽然前向传递的步骤需要在此函数内定义,但应该在此之后调用 Module 实例,而不是在此处调用,因为前者会负责运行前后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoTokenizer, EsmForProteinFolding
>>> model = EsmForProteinFolding.from_pretrained("facebook/esmfold_v1")
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/esmfold_v1")
>>> inputs = tokenizer(["MLKNVQVQLV"], return_tensors="pt", add_special_tokens=False) # A tiny random peptide
>>> outputs = model(**inputs)
>>> folded_positions = outputs.positionsTensorFlow 隐藏 TensorFlow 内容
TFEsmModel
class transformers.TFEsmModel
( config: EsmConfig add_pooling_layer = True *inputs **kwargs )参数
config(EsmConfig) — 包含模型所有参数的模型配置类。使用配置文件初始化不会加载与模型关联的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
裸 ESM 模型变压器输出原始隐藏状态,没有特定的头部。
该模型继承自 TFPreTrainedModel。查看超类文档以了解库为所有模型实现的通用方法(如下载或保存、调整输入嵌入、修剪头等)。
该模型也是 Keras Model 子类。将其用作常规 Keras 模型,并参考 TF/Keras 文档以了解所有与一般使用和行为相关的事项。
call
( input_ids: TFModelInputType | None = None attention_mask: np.ndarray | tf.Tensor | None = None position_ids: np.ndarray | tf.Tensor | None = None head_mask: np.ndarray | tf.Tensor | None = None inputs_embeds: np.ndarray | tf.Tensor | None = None encoder_hidden_states: np.ndarray | tf.Tensor | None = None encoder_attention_mask: np.ndarray | tf.Tensor | None = None past_key_values: Optional[Tuple[Tuple[Union[np.ndarray, tf.Tensor]]]] = None use_cache: Optional[bool] = None output_attentions: Optional[bool] = None output_hidden_states: Optional[bool] = None return_dict: Optional[bool] = None training: Optional[bool] = False ) → export const metadata = 'undefined';transformers.modeling_tf_outputs.TFBaseModelOutputWithPoolingAndCrossAttentions or tuple(tf.Tensor)参数
-
input_ids(tf.Tensorof shape(batch_size, sequence_length)) — 词汇表中输入序列标记的索引。 可以使用 AutoTokenizer 获取索引。查看 PreTrainedTokenizer.encode() 和 PreTrainedTokenizer.call() 以获取详细信息。 什么是输入 ID? -
attention_mask(tf.Tensorof shape(batch_size, sequence_length), optional) — 避免在填充标记索引上执行注意力的掩码。掩码值选在[0, 1]:- 1 表示
未被掩盖的标记, - 0 表示
被掩盖的标记。
什么是注意力掩码?
- 1 表示
-
position_ids(tf.Tensorof shape(batch_size, sequence_length), optional) — 每个输入序列标记在位置嵌入中的位置索引。选在范围[0, config.max_position_embeddings - 1]。 什么是位置 ID? -
head_mask(tf.Tensorof shape(num_heads,)or(num_layers, num_heads), optional) — 用于使自注意力模块中选择的头部失效的掩码。掩码值选在[0, 1]:- 1 表示头部
未被掩盖。 - 0 表示头部被
掩盖。
- 1 表示头部
-
inputs_embeds(形状为(batch_size, sequence_length, hidden_size)的tf.Tensor,可选)— 可选地,可以直接传递嵌入表示而不是传递input_ids。如果您想要更多控制如何将input_ids索引转换为相关向量,而不是使用模型的内部嵌入查找矩阵,这很有用。 -
output_attentions(bool,可选)— 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 -
output_hidden_states(bool,可选)— 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 -
return_dict(bool,可选)— 是否返回一个 ModelOutput 而不是一个普通元组。 -
encoder_hidden_states(形状为(batch_size, sequence_length, hidden_size)的tf.Tensor,可选)— 编码器最后一层的隐藏状态序列。如果模型配置为解码器,则在交叉注意力中使用。 -
encoder_attention_mask(形状为(batch_size, sequence_length)的tf.Tensor,可选)— 避免对编码器输入的填充标记索引执行注意力的掩码。如果模型配置为解码器,则在交叉注意力中使用。掩码值选择在[0, 1]中。- 对于未被掩码的标记为 1,
- 对于被掩码的标记为 0。
-
past_key_values(长度为config.n_layers的Tuple[Tuple[tf.Tensor]])— 包含注意力块的预计算键和值隐藏状态。可用于加速解码。如果使用past_key_values,用户可以选择仅输入最后的decoder_input_ids(那些没有将其过去的键值状态提供给此模型的)的形状为(batch_size, 1)而不是所有decoder_input_ids的形状为(batch_size, sequence_length)。 -
use_cache(bool,可选,默认为True)— 如果设置为True,将返回past_key_values键值状态,可用于加速解码(参见past_key_values)。在训练期间设置为False,在生成期间设置为True。
返回
transformers.modeling_tf_outputs.TFBaseModelOutputWithPoolingAndCrossAttentions 或者tuple(tf.Tensor)
一个 transformers.modeling_tf_outputs.TFBaseModelOutputWithPoolingAndCrossAttentions 或者一个tf.Tensor元组(如果传递了return_dict=False或者config.return_dict=False时)包括根据配置(EsmConfig)和输入的不同元素。
-
last_hidden_state(形状为(batch_size, sequence_length, hidden_size)的tf.Tensor)— 模型最后一层的隐藏状态序列。 -
pooler_output(形状为(batch_size, hidden_size)的tf.Tensor)— 序列第一个标记(分类标记)的最后一层隐藏状态,经过线性层和 Tanh 激活函数进一步处理。线性层的权重是在预训练期间从下一个句子预测(分类)目标中训练的。 此输出通常不是输入的语义内容的良好摘要,您通常最好对整个输入序列的隐藏状态进行平均或池化。 -
past_key_values(List[tf.Tensor],可选,当传递use_cache=True或者config.use_cache=True时返回)— 长度为config.n_layers的tf.Tensor列表,每个张量的形状为(2, batch_size, num_heads, sequence_length, embed_size_per_head)。 包含预先计算的隐藏状态(注意力块中的键和值),可用于加速顺序解码。 -
hidden_states(tuple(tf.Tensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回)-形状为(batch_size, sequence_length, hidden_size)的tf.Tensor元组(一个用于嵌入的输出+一个用于每一层的输出)。 模型在每一层的输出处的隐藏状态加上初始嵌入输出。 -
attentions(tuple(tf.Tensor),可选,当传递output_attentions=True或config.output_attentions=True时返回)-形状为(batch_size, num_heads, sequence_length, sequence_length)的tf.Tensor元组(每层一个)。 注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。 -
cross_attentions(tuple(tf.Tensor),可选,当传递output_attentions=True或config.output_attentions=True时返回)-形状为(batch_size, num_heads, sequence_length, sequence_length)的tf.Tensor元组(每层一个)。 解码器的交叉注意力层的注意力权重,在注意力 softmax 后使用,用于计算交叉注意力头中的加权平均值。
TFEsmModel 前向方法,覆盖__call__特殊方法。
虽然前向传递的方法需要在此函数内定义,但应该在此之后调用Module实例,而不是这个,因为前者负责运行前后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoTokenizer, TFEsmModel
>>> import tensorflow as tf
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/esm2_t6_8M_UR50D")
>>> model = TFEsmModel.from_pretrained("facebook/esm2_t6_8M_UR50D")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="tf")
>>> outputs = model(inputs)
>>> last_hidden_states = outputs.last_hidden_stateTFEsmForMaskedLM
class transformers.TFEsmForMaskedLM
( config )参数
config(EsmConfig)-模型配置类,包含模型的所有参数。使用配置文件初始化不会加载与模型关联的权重,只加载配置。查看 from_pretrained()方法以加载模型权重。
ESM 模型顶部带有语言建模头。
这个模型继承自 TFPreTrainedModel。查看超类文档以了解库实现的通用方法(如下载或保存,调整输入嵌入,修剪头等)。
这个模型也是 Keras Model 的子类。将其用作常规 Keras 模型,并参考 TF/Keras 文档以了解所有与一般用法和行为相关的事项。
call
( input_ids: TFModelInputType | None = None attention_mask: np.ndarray | tf.Tensor | None = None position_ids: np.ndarray | tf.Tensor | None = None head_mask: np.ndarray | tf.Tensor | None = None inputs_embeds: np.ndarray | tf.Tensor | None = None encoder_hidden_states: np.ndarray | tf.Tensor | None = None encoder_attention_mask: np.ndarray | tf.Tensor | None = None labels: np.ndarray | tf.Tensor | None = None output_attentions: Optional[bool] = None output_hidden_states: Optional[bool] = None return_dict: Optional[bool] = None training: bool = False ) → export const metadata = 'undefined';transformers.modeling_tf_outputs.TFMaskedLMOutput or tuple(tf.Tensor)参数
-
input_ids(形状为(batch_size, sequence_length)的tf.Tensor)-词汇表中输入序列标记的索引。 可以使用 AutoTokenizer 获取索引。查看 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()获取详细信息。 什么是输入 ID? -
attention_mask(形状为(batch_size, sequence_length)的tf.Tensor,可选)-避免在填充标记索引上执行注意力的掩码。选择在[0, 1]中的掩码值:- 对于未被屏蔽的标记为 1,
- 对于被屏蔽的标记为 0。
注意力掩码是什么?
-
position_ids(tf.Tensorof shape(batch_size, sequence_length), optional) — 每个输入序列标记在位置嵌入中的位置索引。在范围[0, config.max_position_embeddings - 1]中选择。 什么是位置 ID? -
head_mask(tf.Tensorof shape(num_heads,)or(num_layers, num_heads), optional) — 用于将自注意力模块的选定头部置零的掩码。掩码值选定在[0, 1]之间:- 1 表示头部未被
masked。 - 0 表示头部被
masked。
- 1 表示头部未被
-
inputs_embeds(tf.Tensorof shape(batch_size, sequence_length, hidden_size), optional) — 可选地,可以直接传递嵌入表示,而不是传递input_ids。如果您想要更多控制权,以便将input_ids索引转换为相关向量,而不是使用模型的内部嵌入查找矩阵,则这很有用。 -
output_attentions(bool, optional) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量中的attentions。 -
output_hidden_states(bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量中的hidden_states。 -
return_dict(bool, optional) — 是否返回 ModelOutput 而不是普通元组。 -
labels(tf.Tensorof shape(batch_size, sequence_length), optional) — 用于计算掩码语言建模损失的标签。索引应在[-100, 0, ..., config.vocab_size]范围内(参见input_ids文档字符串)。索引设置为-100的标记将被忽略(masked),损失仅计算具有标签在[0, ..., config.vocab_size]范围内的标记。 -
kwargs(Dict[str, any], optional, 默认为 {}) — 用于隐藏已被弃用的旧参数。
返回
transformers.modeling_tf_outputs.TFMaskedLMOutput 或 tuple(tf.Tensor)
一个 transformers.modeling_tf_outputs.TFMaskedLMOutput 或一个 tf.Tensor 元组(如果传递 return_dict=False 或者 config.return_dict=False 时)包含各种元素,取决于配置(EsmConfig)和输入。
-
loss(tf.Tensorof shape(n,), optional, 其中 n 是非掩码标签的数量,在提供labels时返回) — 掩码语言建模(MLM)损失。 -
logits(tf.Tensorof shape(batch_size, sequence_length, config.vocab_size)) — 语言建模头部的预测分数(SoftMax 之前每个词汇标记的分数)。 -
hidden_states(tuple(tf.Tensor), optional, 当传递output_hidden_states=True或者config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的tf.Tensor元组(一个用于嵌入的输出 + 一个用于每层的输出)。 每层模型的隐藏状态加上初始嵌入输出。 -
attentions(tuple(tf.Tensor), optional, 当传递output_attentions=True或者config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的tf.Tensor元组(每层一个)。 在注意力 softmax 之后的注意力权重,用于计算自注意力头部中的加权平均值。
TFEsmForMaskedLM 的前向方法,覆盖了 __call__ 特殊方法。
虽然前向传播的步骤需要在此函数内定义,但应该在此之后调用 Module 实例,而不是在此处调用,因为前者负责运行前处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoTokenizer, TFEsmForMaskedLM
>>> import tensorflow as tf
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/esm2_t6_8M_UR50D")
>>> model = TFEsmForMaskedLM.from_pretrained("facebook/esm2_t6_8M_UR50D")
>>> inputs = tokenizer("The capital of France is <mask>.", return_tensors="tf")
>>> logits = model(**inputs).logits
>>> # retrieve index of <mask>
>>> mask_token_index = tf.where((inputs.input_ids == tokenizer.mask_token_id)[0])
>>> selected_logits = tf.gather_nd(logits[0], indices=mask_token_index)
>>> predicted_token_id = tf.math.argmax(selected_logits, axis=-1)>>> labels = tokenizer("The capital of France is Paris.", return_tensors="tf")["input_ids"]
>>> # mask labels of non-<mask> tokens
>>> labels = tf.where(inputs.input_ids == tokenizer.mask_token_id, labels, -100)
>>> outputs = model(**inputs, labels=labels)TFEsmForSequenceClassification
class transformers.TFEsmForSequenceClassification
( config )参数
config(EsmConfig)— 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型关联的权重,只加载配置。查看 from_pretrained()方法以加载模型权重。
ESM 模型变压器,顶部带有序列分类/回归头(顶部的线性层在汇总输出之上),例如用于 GLUE 任务。
此模型继承自 TFPreTrainedModel。检查超类文档以获取库为所有模型实现的通用方法(例如下载或保存、调整输入嵌入、修剪头等)。
此模型还是 Keras Model子类。将其用作常规 Keras 模型,并参考 TF/Keras 文档以获取有关一般用法和行为的所有事项。
call
( input_ids: TFModelInputType | None = None attention_mask: np.ndarray | tf.Tensor | None = None position_ids: np.ndarray | tf.Tensor | None = None head_mask: np.ndarray | tf.Tensor | None = None inputs_embeds: np.ndarray | tf.Tensor | None = None labels: np.ndarray | tf.Tensor | None = None output_attentions: Optional[bool] = None output_hidden_states: Optional[bool] = None return_dict: Optional[bool] = None training: bool = False ) → export const metadata = 'undefined';transformers.modeling_tf_outputs.TFSequenceClassifierOutput or tuple(tf.Tensor)参数
-
input_ids(形状为(batch_size, sequence_length)的tf.Tensor)— 词汇表中输入序列标记的索引。 可以使用 AutoTokenizer 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。 什么是输入 ID? -
attention_mask(形状为(batch_size, sequence_length)的tf.Tensor,可选)— 用于避免在填充标记索引上执行注意力的掩码。掩码值选择在[0, 1]之间:- 对于
未屏蔽的标记为 1, - 0 表示标记为
屏蔽。
什么是注意力掩码?
- 对于
-
position_ids(形状为(batch_size, sequence_length)的tf.Tensor,可选)— 每个输入序列标记在位置嵌入中的位置索引。选择范围为[0, config.max_position_embeddings - 1]。 什么是位置 ID? -
head_mask(形状为(num_heads,)或(num_layers, num_heads)的tf.Tensor,可选)— 用于使自注意力模块的选定头部失效的掩码。掩码值选择在[0, 1]之间:- 1 表示头部未被
屏蔽, - 0 表示头部被
屏蔽。
- 1 表示头部未被
-
inputs_embeds(形状为(batch_size, sequence_length, hidden_size)的tf.Tensor,可选)— 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果您想要更多控制如何将input_ids索引转换为关联向量,而不是使用模型的内部嵌入查找矩阵,则这很有用。 -
output_attentions(bool,可选)— 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的attentions。 -
output_hidden_states(bool,可选)— 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 -
return_dict(bool,可选)— 是否返回一个 ModelOutput 而不是一个普通的元组。 -
labels(tf.Tensor的形状为(batch_size,),可选) — 用于计算序列分类/回归损失的标签。索引应在[0, ..., config.num_labels - 1]范围内。如果config.num_labels == 1,则计算回归损失(均方损失),如果config.num_labels > 1,则计算分类损失(交叉熵)。
返回
transformers.modeling_tf_outputs.TFSequenceClassifierOutput 或tuple(tf.Tensor)
一个 transformers.modeling_tf_outputs.TFSequenceClassifierOutput 或一个tf.Tensor元组(如果传递return_dict=False或config.return_dict=False)包含根据配置(EsmConfig)和输入的各种元素。
-
loss(tf.Tensor的形状为(batch_size, ),可选,在提供labels时返回) — 分类(如果 config.num_labels==1 则为回归)损失。 -
logits(tf.Tensor的形状为(batch_size, config.num_labels)) — 分类(如果 config.num_labels==1 则为回归)分数(SoftMax 之前)。 -
hidden_states(tuple(tf.Tensor),可选,在传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的tf.Tensor元组(一个用于嵌入输出,一个用于每一层的输出)。 模型在每一层输出的隐藏状态加上初始嵌入输出。 -
attentions(tuple(tf.Tensor),可选,在传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的tf.Tensor元组(每层一个)。 在自注意力头中使用注意力 softmax 后的注意力权重,用于计算加权平均值。
TFEsmForSequenceClassification 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的步骤需要在这个函数内定义,但应该在之后调用Module实例,而不是这个,因为前者会处理运行前后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoTokenizer, TFEsmForSequenceClassification
>>> import tensorflow as tf
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/esm2_t6_8M_UR50D")
>>> model = TFEsmForSequenceClassification.from_pretrained("facebook/esm2_t6_8M_UR50D")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="tf")
>>> logits = model(**inputs).logits
>>> predicted_class_id = int(tf.math.argmax(logits, axis=-1)[0])>>> # To train a model on `num_labels` classes, you can pass `num_labels=num_labels` to `.from_pretrained(...)`
>>> num_labels = len(model.config.id2label)
>>> model = TFEsmForSequenceClassification.from_pretrained("facebook/esm2_t6_8M_UR50D", num_labels=num_labels)
>>> labels = tf.constant(1)
>>> loss = model(**inputs, labels=labels).lossTFEsmForTokenClassification
class transformers.TFEsmForTokenClassification
( config )参数
config(EsmConfig) — 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型关联的权重,只会加载配置。查看 from_pretrained()方法以加载模型权重。
ESM 模型在顶部带有一个标记分类头(隐藏状态输出的线性层),例如用于命名实体识别(NER)任务。
这个模型继承自 TFPreTrainedModel。查看超类文档,了解库为所有模型实现的通用方法(如下载或保存、调整输入嵌入、修剪头等)。
这个模型也是一个 Keras Model子类。将其用作常规的 Keras 模型,并参考 TF/Keras 文档以获取所有与一般用法和行为相关的事项。
call
( input_ids: TFModelInputType | None = None attention_mask: np.ndarray | tf.Tensor | None = None position_ids: np.ndarray | tf.Tensor | None = None head_mask: np.ndarray | tf.Tensor | None = None inputs_embeds: np.ndarray | tf.Tensor | None = None labels: np.ndarray | tf.Tensor | None = None output_attentions: Optional[bool] = None output_hidden_states: Optional[bool] = None return_dict: Optional[bool] = None training: bool = False ) → export const metadata = 'undefined';transformers.modeling_tf_outputs.TFTokenClassifierOutput or tuple(tf.Tensor)参数
-
input_ids(tf.Tensorof shape(batch_size, sequence_length)) — 输入序列标记在词汇表中的索引。 可以使用 AutoTokenizer 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode() 和 PreTrainedTokenizer.call()。 什么是输入 ID? -
attention_mask(tf.Tensorof shape(batch_size, sequence_length), optional) — 避免在填充标记索引上执行注意力的掩码。掩码值在[0, 1]中选择:- 1 表示未被
掩码的标记, - 0 表示被
掩码的标记。
什么是注意力掩码?
- 1 表示未被
-
position_ids(tf.Tensorof shape(batch_size, sequence_length), optional) — 每个输入序列标记在位置嵌入中的位置索引。在范围[0, config.max_position_embeddings - 1]中选择。 什么是位置 ID? -
head_mask(tf.Tensorof shape(num_heads,)or(num_layers, num_heads), optional) — 用于使自注意力模块中选择的头部失效的掩码。掩码值在[0, 1]中选择:- 1 表示头部未被
掩码。 - 0 表示头部被
掩码。
- 1 表示头部未被
-
inputs_embeds(tf.Tensorof shape(batch_size, sequence_length, hidden_size), optional) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果您想要更多控制权来将input_ids索引转换为相关向量,这将非常有用,而不是使用模型的内部嵌入查找矩阵。 -
output_attentions(bool, optional) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回的张量下的attentions。 -
output_hidden_states(bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回的张量下的hidden_states。 -
return_dict(bool, optional) — 是否返回一个 ModelOutput 而不是一个普通的元组。 -
labels(tf.Tensorof shape(batch_size, sequence_length), optional) — 用于计算标记分类损失的标签。索引应在[0, ..., config.num_labels - 1]中。
返回
transformers.modeling_tf_outputs.TFTokenClassifierOutput 或 tuple(tf.Tensor)
一个 transformers.modeling_tf_outputs.TFTokenClassifierOutput 或一个 tf.Tensor 元组(如果传递了 return_dict=False 或 config.return_dict=False)包含各种元素,这取决于配置(EsmConfig)和输入。
-
loss(tf.Tensorof shape(n,), optional, 当提供labels时返回,其中 n 是未被掩码的标签数) — 分类损失。 -
logits(tf.Tensorof shape(batch_size, sequence_length, config.num_labels)) — 分类分数(SoftMax 之前)。 -
hidden_states(tuple(tf.Tensor), optional, 当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的tf.Tensor元组(一个用于嵌入的输出 + 一个用于每一层的输出)。 模型在每一层输出的隐藏状态以及初始嵌入输出。 -
attentions(tuple(tf.Tensor), 可选的, 当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的tf.Tensor元组(每层一个)。 在注意力 softmax 之后的注意力权重,用于计算自注意力头中的加权平均值。
TFEsmForTokenClassification 的前向方法,覆盖了 __call__ 特殊方法。
虽然前向传递的步骤需要在这个函数中定义,但应该在此之后调用 Module 实例,而不是这个函数,因为前者会处理运行前后的处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoTokenizer, TFEsmForTokenClassification
>>> import tensorflow as tf
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/esm2_t6_8M_UR50D")
>>> model = TFEsmForTokenClassification.from_pretrained("facebook/esm2_t6_8M_UR50D")
>>> inputs = tokenizer(
... "HuggingFace is a company based in Paris and New York", add_special_tokens=False, return_tensors="tf"
... )
>>> logits = model(**inputs).logits
>>> predicted_token_class_ids = tf.math.argmax(logits, axis=-1)
>>> # Note that tokens are classified rather then input words which means that
>>> # there might be more predicted token classes than words.
>>> # Multiple token classes might account for the same word
>>> predicted_tokens_classes = [model.config.id2label[t] for t in predicted_token_class_ids[0].numpy().tolist()]>>> labels = predicted_token_class_ids
>>> loss = tf.math.reduce_mean(model(**inputs, labels=labels).loss)Falcon
原文:
huggingface.co/docs/transformers/v4.37.2/en/model_doc/falcon
概述
Falcon 是由 TII 构建的一类仅因果解码器模型。最大的 Falcon 检查点已经在 >=1T 个文本标记上进行了训练,特别强调了 RefinedWeb 语料库。它们在 Apache 2.0 许可下提供。
Falcon 的架构现代化且优化用于推断,具有多查询注意力和支持 FlashAttention 等高效注意力变体。既有仅作为因果语言模型训练的“基础”模型,也有接受进一步微调的“指导”模型可用。
Falcon 模型(截至 2023 年)是一些最大且最强大的开源语言模型,在 OpenLLM 排行榜 中始终排名靠前。
转换自定义检查点
Falcon 模型最初作为自定义代码检查点添加到 Hugging Face Hub。但是,现在 Falcon 在 Transformers 库中得到了全面支持。如果您从自定义代码检查点微调了模型,我们建议将您的检查点转换为新的库格式,这应该显著提高稳定性和性能,特别是对于生成,同时消除了使用 trust_remote_code=True 的需要!
您可以使用位于 Transformers 库的 Falcon 模型目录 中的 convert_custom_code_checkpoint.py 脚本将自定义代码检查点转换为完整的 Transformers 检查点。要使用此脚本,只需调用 python convert_custom_code_checkpoint.py --checkpoint_dir my_model。这将原地转换您的检查点,然后您可以立即从目录中加载它,例如 from_pretrained()。如果您的模型尚未上传到 Hub,我们建议在尝试转换之前进行备份,以防万一!
FalconConfig
class transformers.FalconConfig
( vocab_size = 65024 hidden_size = 4544 num_hidden_layers = 32 num_attention_heads = 71 layer_norm_epsilon = 1e-05 initializer_range = 0.02 use_cache = True hidden_dropout = 0.0 attention_dropout = 0.0 num_kv_heads = None alibi = False new_decoder_architecture = False multi_query = True parallel_attn = True bias = False max_position_embeddings = 2048 rope_theta = 10000.0 rope_scaling = None bos_token_id = 11 eos_token_id = 11 **kwargs )参数
-
vocab_size(int, optional, defaults to 65024) — Falcon 模型的词汇量大小。定义了在调用 FalconModel 时可以表示的不同 token 数量。 -
hidden_size(int, optional, defaults to 4544) — 隐藏表示的维度。 -
num_hidden_layers(int, optional, defaults to 32) — Transformer 解码器中的隐藏层数量。 -
num_attention_heads(int, optional, defaults to 71) — Transformer 编码器中每个注意力层的注意力头数量。 -
layer_norm_epsilon(float, optional, defaults to 1e-05) — 层归一化层使用的 epsilon。 -
initializer_range(float, optional, defaults to 0.02) — 用于初始化所有权重矩阵的截断正态分布初始化器的标准差。 -
use_cache(bool, optional, defaults toTrue) — 模型是否应返回最后的键/值注意力(并非所有模型都使用)。仅在config.is_decoder=True时相关。 -
hidden_dropout(float, optional, defaults to 0.0) — MLP 层的 dropout 概率。 -
attention_dropout(float, optional, defaults to 0.0) — 注意力层的 dropout 概率。 -
num_kv_heads(int, optional) — 每个注意力层使用的键值头的数量。如果未设置,默认为与num_attention_heads相同的值。 -
alibi(bool, optional, defaults toFalse) — 是否在自注意力期间使用 ALiBi 位置偏差。 -
new_decoder_architecture(bool, optional, defaults toFalse) — 是否使用新的(Falcon-40B)解码器架构。如果为True,则multi_query和parallel_attn参数将被忽略,因为新的解码器总是使用并行注意力。 -
multi_query(bool, optional, defaults toTrue) — 是否在解码器中使用多查询注意力。当new_decoder_architecture为True时忽略。 -
parallel_attn(bool, optional, defaults toTrue) — 是否在前馈层中并行计算注意力。如果为 False,则它们是连续的,就像原始 Transformer 架构中一样。当new_decoder_architecture为True时忽略。 -
bias(bool, optional, defaults toFalse) — 是否在线性层上使用偏置。 -
max_position_embeddings(int, optional, defaults to 2048) — 当alibi为False时,此模型可能使用的最大序列长度。支持 RoPE 的预训练 Falcon 模型最多支持 2048 个标记。 -
rope_theta(float, optional, defaults to 10000.0) — RoPE 嵌入的基本周期。 -
rope_scaling(Dict, optional) — 包含 RoPE 嵌入的缩放配置的字典。目前支持两种缩放策略:线性和动态。它们的缩放因子必须是大于 1 的浮点数。期望的格式是{"type": 策略名称, "factor": 缩放因子}。当使用此标志时,不要更新max_position_embeddings到预期的新最大值。查看以下主题以了解这些缩放策略的行为更多信息:www.reddit.com/r/LocalLLaMA/comments/14mrgpr/dynamically_scaled_rope_further_increases/。这是一个实验性功能,可能在未来版本中发生破坏性 API 更改。 -
bos_token_id(int, optional, defaults to 11) — “序列开始”标记的 id。 -
eos_token_id(int, optional, defaults to 11) — “序列结束”标记的 id。
这是一个配置类,用于存储 FalconModel 的配置。根据指定的参数实例化 Falcon 模型,定义模型架构。使用默认值实例化配置将产生类似于tiiuae/falcon-7b架构的配置。
配置对象继承自 PretrainedConfig,可用于控制模型输出。阅读 PretrainedConfig 的文档以获取更多信息。
示例:
>>> from transformers import FalconModel, FalconConfig
>>> # Initializing a small (2-layer) Falcon configuration
>>> configuration = FalconConfig(num_hidden_layers=2)
>>> # Initializing a model from the small configuration
>>> model = FalconModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configFalconModel
class transformers.FalconModel
( config: FalconConfig )参数
config(FalconConfig) — 包含模型所有参数的模型配置类。使用配置文件初始化不会加载与模型关联的权重,只加载配置。查看 from_pretrained()方法以加载模型权重。
裸的 Falcon 模型变压器输出原始隐藏状态,没有特定的头部。
这个模型继承自 PreTrainedModel。查看超类文档以了解库为所有模型实现的通用方法(如下载或保存、调整输入嵌入等)。
此模型还是一个 PyTorch torch.nn.Module子类。将其用作常规的 PyTorch 模块,并参考 PyTorch 文档以获取有关一般用法和行为的所有相关信息。
forward
( input_ids: Optional = None past_key_values: Optional = None attention_mask: Optional = None position_ids: Optional = None head_mask: Optional = None inputs_embeds: Optional = None use_cache: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.BaseModelOutputWithPastAndCrossAttentions or tuple(torch.FloatTensor)参数
-
input_ids(torch.LongTensorof shape(batch_size, input_ids_length)) —input_ids_length=sequence_length,如果past_key_values是None,否则past_key_values[0][0].shape[2](输入过去键值状态的序列长度)。词汇表中输入序列标记的索引。 如果使用了past_key_values,则应该只传递那些没有计算过去的input_ids作为input_ids。 可以使用 AutoTokenizer 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。 什么是输入 ID? -
past_key_values(Tuple[Tuple[torch.Tensor]]of lengthconfig.num_hidden_layers) — 包含由模型计算的预计算隐藏状态(注意力块中的键和值)(请参见下面的past_key_values输出)。可用于加速顺序解码。已经计算的input_ids的过去不应该作为input_ids传递,因为它们已经被计算。past_key_values的每个元素都是一个元组(past_key, past_value):- past_key: [batch_size * num_heads, head_dim, kv_length]
- past_value: [batch_size * num_heads, kv_length, head_dim]
-
attention_mask(torch.FloatTensorof shape(batch_size, sequence_length), optional) — 用于避免在填充标记索引上执行注意力的掩码。掩码值选择在[0, 1]之间:- 1 表示标记是
未掩盖的, - 0 表示被
掩盖的标记。
什么是注意力掩码?
- 1 表示标记是
-
position_ids(torch.LongTensorof shape(batch_size, sequence_length), optional) — 每个输入序列标记在位置嵌入中的位置索引。选择范围为[0, config.n_positions - 1]。 什么是位置 ID? -
head_mask(torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — 用于使自注意力模块中的特定头部失效的掩码。掩码值选择在[0, 1]之间:- 1 表示头部是
未掩盖的, - 0 表示头部是
掩盖的。
- 1 表示头部是
-
inputs_embeds(torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — 可选地,您可以直接传递嵌入表示,而不是传递input_ids。如果您想要更多控制如何将input_ids索引转换为相关向量,这将非常有用,而不是使用模型的内部嵌入查找矩阵。 如果使用了past_key_values,则可以选择仅输入最后的inputs_embeds(参见past_key_values)。 -
use_cache(bool, optional) — 如果设置为True,则返回past_key_values键值状态,并可用于加速解码(参见past_key_values)。 -
output_attentions(bool, optional) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请查看返回张量中的attentions。 -
output_hidden_states(bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请查看返回张量中的hidden_states。 -
return_dict(bool, optional) — 是否返回一个 ModelOutput 而不是一个普通的元组。
返回
transformers.modeling_outputs.BaseModelOutputWithPastAndCrossAttentions 或torch.FloatTensor元组。
一个 transformers.modeling_outputs.BaseModelOutputWithPastAndCrossAttentions 或一个torch.FloatTensor元组(如果传递return_dict=False或config.return_dict=False)包含根据配置(FalconConfig)和输入不同的元素。
-
last_hidden_state(torch.FloatTensor,形状为(batch_size, sequence_length, hidden_size)) — 模型最后一层的隐藏状态序列。 如果使用past_key_values,则仅输出形状为(batch_size, 1, hidden_size)的序列的最后隐藏状态。 -
past_key_values(tuple(tuple(torch.FloatTensor)), optional, 当传递use_cache=True或config.use_cache=True时返回) — 长度为config.n_layers的tuple(torch.FloatTensor)元组,每个元组有 2 个形状为(batch_size, num_heads, sequence_length, embed_size_per_head)的张量,如果config.is_encoder_decoder=True还有 2 个额外的形状为(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)的张量。 包含预先计算的隐藏状态(自注意力块中的键和值,以及如果config.is_encoder_decoder=True则在交叉注意力块中)可用于加速顺序解码。 -
hidden_states(tuple(torch.FloatTensor), optional, 当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(如果模型有嵌入层,则为嵌入输出的一个和每层输出的一个)。 模型每一层的隐藏状态以及可选的初始嵌入输出。 -
attentions(tuple(torch.FloatTensor), optional, 当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。 在自注意力头中用于计算加权平均值的注意力 softmax 之后的注意力权重。 -
cross_attentions(tuple(torch.FloatTensor), optional, 当传递output_attentions=True和config.add_cross_attention=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。 在解码器的交叉注意力层中的注意力 softmax 之后的注意力权重,用于计算交叉注意力头中的加权平均值。
FalconModel 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的步骤需要在此函数内定义,但应该在此之后调用Module实例,而不是在此处调用,因为前者会处理运行前后的处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoTokenizer, FalconModel
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("Rocketknight1/falcon-rw-1b")
>>> model = FalconModel.from_pretrained("Rocketknight1/falcon-rw-1b")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_stateFalconForCausalLM
class transformers.FalconForCausalLM
( config: FalconConfig )参数
config(FalconConfig)— 包含模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained()方法以加载模型权重。
Falcon 模型变压器在顶部带有语言建模头(线性层,其权重与输入嵌入绑定)。
该模型继承自 PreTrainedModel。查看超类文档,了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入等)。
该模型还是一个 PyTorch torch.nn.Module子类。将其用作常规 PyTorch 模块,并参考 PyTorch 文档以获取有关一般用法和行为的所有相关信息。
forward
( input_ids: Optional = None past_key_values: Optional = None attention_mask: Optional = None position_ids: Optional = None head_mask: Optional = None inputs_embeds: Optional = None labels: Optional = None use_cache: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.CausalLMOutputWithCrossAttentions or tuple(torch.FloatTensor)参数
-
input_ids(形状为(batch_size, input_ids_length)的torch.LongTensor)—input_ids_length=sequence_length,如果past_key_values为None,否则为past_key_values[0][0].shape[2](输入过去键值状态的序列长度)。词汇表中输入序列标记的索引。 如果使用past_key_values,则只应将未计算其过去的input_ids作为input_ids传递。 可以使用 AutoTokenizer 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。 什么是输入 ID? -
past_key_values(长度为config.num_hidden_layers的Tuple[Tuple[torch.Tensor]])— 包含由模型计算的预计算隐藏状态(注意力块中的键和值,参见下面的past_key_values输出)。可用于加速顺序解码。将其过去给定给该模型的input_ids不应作为input_ids传递,因为它们已经计算过。past_key_values的每个元素都是一个元组(past_key,past_value):- past_key: [batch_size * num_heads, head_dim, kv_length]
- past_value: [batch_size * num_heads, kv_length, head_dim]
-
attention_mask(形状为(batch_size, sequence_length)的torch.FloatTensor,可选)— 用于避免在填充令牌索引上执行注意力的掩码。选择的掩码值在[0, 1]范围内:- 1 表示未被
masked的标记, - 对于被
masked的标记为 0。
什么是注意力掩码?
- 1 表示未被
-
position_ids(形状为(batch_size, sequence_length)的torch.LongTensor,可选)— 每个输入序列标记在位置嵌入中的位置索引。选择范围为[0, config.n_positions - 1]。 什么是位置 ID? -
head_mask(形状为(num_heads,)或(num_layers, num_heads)的torch.FloatTensor,可选)— 用于使自注意力模块的选定头部失效的掩码。选择的掩码值在[0, 1]范围内:- 1 表示头部未被
masked, - 0 表示头部被
masked。
- 1 表示头部未被
-
inputs_embeds(形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor,可选)— 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果您想要更多控制如何将input_ids索引转换为相关向量,这将非常有用,而不是使用模型的内部嵌入查找矩阵。 如果使用了past_key_values,则可能只需输入最后的inputs_embeds(参见past_key_values)。 -
use_cache(bool, optional) — 如果设置为True,则返回past_key_values键值状态,并可用于加速解码(参见past_key_values)。 -
output_attentions(bool, optional) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 -
output_hidden_states(bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 -
return_dict(bool, optional) — 是否返回一个 ModelOutput 而不是一个普通元组。 -
labels(torch.LongTensor,形状为(batch_size, sequence_length),optional) — 用于语言建模的标签。请注意,模型内部的标签已经移位,即您可以设置labels = input_ids。索引在[-100, 0, ..., config.vocab_size]中选择。所有设置为-100的标签都将被忽略(掩码),损失仅计算标签在[0, ..., config.vocab_size]中的标签。
返回
transformers.modeling_outputs.CausalLMOutputWithCrossAttentions 或torch.FloatTensor元组
一个 transformers.modeling_outputs.CausalLMOutputWithCrossAttentions 或一个torch.FloatTensor元组(如果传递了return_dict=False或config.return_dict=False)包括根据配置(FalconConfig)和输入的各种元素。
-
loss(torch.FloatTensor,形状为(1,), optional, 当提供labels时返回) — 语言建模损失(用于下一个标记预测)。 -
logits(torch.FloatTensor,形状为(batch_size, sequence_length, config.vocab_size)) — 语言建模头的预测分数(SoftMax 之前每个词汇标记的分数)。 -
hidden_states(tuple(torch.FloatTensor), optional, 当传递output_hidden_states=True或config.output_hidden_states=True时返回)— 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(如果模型有嵌入层,则为嵌入输出的一个+每个层的输出的一个)。 每个层输出的模型的隐藏状态加上可选的初始嵌入输出。 -
attentions(tuple(torch.FloatTensor), optional, 当传递output_attentions=True或config.output_attentions=True时返回)— 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每个层一个)。 在注意力 softmax 之后的注意力权重,用于计算自注意力头中的加权平均值。 -
cross_attentions(tuple(torch.FloatTensor), optional, 当传递output_attentions=True或config.output_attentions=True时返回)— 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每个层一个)。 在注意力 softmax 之后的交叉注意力权重,用于计算交叉注意力头中的加权平均值。 -
past_key_values(tuple(tuple(torch.FloatTensor)), optional, 当传递use_cache=True或config.use_cache=True时返回)— 长度为config.n_layers的torch.FloatTensor元组,每个元组包含自注意力和交叉注意力层的缓存键、值状态,如果模型用于编码器-解码器设置,则相关。仅在config.is_decoder = True时相关。 包含可以用于加速顺序解码的预计算隐藏状态(注意力块中的键和值)。
FalconForCausalLM 的前向方法覆盖了__call__特殊方法。
虽然前向传递的步骤需要在这个函数内定义,但应该在此之后调用Module实例,而不是这个函数,因为前者会负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> import torch
>>> from transformers import AutoTokenizer, FalconForCausalLM
>>> tokenizer = AutoTokenizer.from_pretrained("Rocketknight1/falcon-rw-1b")
>>> model = FalconForCausalLM.from_pretrained("Rocketknight1/falcon-rw-1b")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> outputs = model(**inputs, labels=inputs["input_ids"])
>>> loss = outputs.loss
>>> logits = outputs.logitsFalconForSequenceClassification
class transformers.FalconForSequenceClassification
( config: FalconConfig )参数
config(FalconConfig)— 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型关联的权重,只会加载配置。查看 from_pretrained()方法以加载模型权重。
Falcon 模型变压器顶部带有序列分类头(线性层)。
FalconForSequenceClassification 使用最后一个标记来进行分类,就像其他因果模型(例如 GPT-1)一样。
由于它对最后一个标记进行分类,因此需要知道最后一个标记的位置。如果在配置中定义了pad_token_id,则它会找到每行中不是填充标记的最后一个标记。如果没有定义pad_token_id,则它会简单地取每行批次中的最后一个值。由于在传递inputs_embeds而不是input_ids时无法猜测填充标记,因此它会执行相同的操作(取每行批次中的最后一个值)。
此模型继承自 PreTrainedModel。查看超类文档以了解库为所有模型实现的通用方法(例如下载或保存、调整输入嵌入等)。
此模型也是 PyTorch torch.nn.Module子类。将其用作常规 PyTorch 模块,并参考 PyTorch 文档以获取有关一般用法和行为的所有相关信息。
forward
( input_ids: Optional = None past_key_values: Optional = None attention_mask: Optional = None head_mask: Optional = None inputs_embeds: Optional = None labels: Optional = None use_cache: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.SequenceClassifierOutputWithPast or tuple(torch.FloatTensor)参数
-
input_ids(形状为(batch_size, input_ids_length)的torch.LongTensor)— 如果past_key_values为None,则input_ids_length=sequence_length,否则为past_key_values[0][0].shape[2](输入过去键值状态的序列长度)。词汇表中输入序列标记的索引。 如果使用了past_key_values,则只应将尚未计算其过去的input_ids作为input_ids传递。 可以使用 AutoTokenizer 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。 什么是输入 ID? -
past_key_values(长度为config.num_hidden_layers的Tuple[Tuple[torch.Tensor]])— 包含由模型计算的预计算隐藏状态(注意块中的键和值),如下面的past_key_values输出所示。可用于加速顺序解码。已经计算过其过去的input_ids不应作为input_ids传递给此模型,因为它们已经被计算过。past_key_values的每个元素都是一个元组(past_key, past_value):- past_key: [batch_size * num_heads, head_dim, kv_length]
- past_value: [batch_size * num_heads, kv_length, head_dim]
-
attention_mask(torch.FloatTensor,形状为(batch_size, sequence_length),可选) — 用于避免在填充标记索引上执行注意力的掩码。掩码值选择在[0, 1]范围内:- 1 表示标记是
未被掩盖。 - 0 表示
被掩盖的标记。
什么是注意力掩码?
- 1 表示标记是
-
position_ids(torch.LongTensor,形状为(batch_size, sequence_length),可选) — 每个输入序列标记在位置嵌入中的位置索引。选择范围为[0, config.n_positions - 1]。 什么是位置 ID? -
head_mask(torch.FloatTensor,形状为(num_heads,)或(num_layers, num_heads),可选) — 用于使自注意力模块的选定头部失效的掩码。掩码值选择在[0, 1]范围内:- 1 表示头部是
未被掩盖, - 0 表示头部是
被掩盖。
- 1 表示头部是
-
inputs_embeds(torch.FloatTensor,形状为(batch_size, sequence_length, hidden_size),可选) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果您想要更多控制权来将input_ids索引转换为相关向量,这将非常有用,而不是使用模型的内部嵌入查找矩阵。 如果使用了past_key_values,则只需输入最后的inputs_embeds(参见past_key_values)。 -
use_cache(bool,可选) — 如果设置为True,则返回past_key_values键值状态,并可用于加速解码(参见past_key_values)。 -
output_attentions(bool,可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量中的attentions。 -
output_hidden_states(bool,可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量中的hidden_states。 -
return_dict(bool,可选) — 是否返回一个 ModelOutput 而不是一个普通元组。 -
labels(torch.LongTensor,形状为(batch_size,),可选) — 用于计算序列分类/回归损失的标签。索引应在[0, ..., config.num_labels - 1]范围内。如果config.num_labels == 1,则计算回归损失(均方损失),如果config.num_labels > 1,则计算分类损失(交叉熵)。
返回
transformers.modeling_outputs.SequenceClassifierOutputWithPast 或 tuple(torch.FloatTensor)
一个transformers.modeling_outputs.SequenceClassifierOutputWithPast或一个torch.FloatTensor元组(如果传递return_dict=False或config.return_dict=False)包含根据配置(FalconConfig)和输入的不同元素。
-
损失(torch.FloatTensor,形状为(1,),可选,在提供labels时返回) — 分类(如果config.num_labels==1则为回归)损失。 -
logits(torch.FloatTensor,形状为(batch_size, config.num_labels)) — 分类(如果config.num_labels==1则为回归)得分(SoftMax 之前)。 -
past_key_values(tuple(tuple(torch.FloatTensor)),可选,当传递use_cache=True或config.use_cache=True时返回) — 长度为config.n_layers的tuple(torch.FloatTensor)元组,每个元组有 2 个形状为(batch_size, num_heads, sequence_length, embed_size_per_head)的张量) 包含预先计算的隐藏状态(自注意力块中的键和值),可用于加速顺序解码(参见past_key_values输入)。 -
hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(如果模型具有嵌入层,则为嵌入的输出 + 每个层的输出)。 模型在每一层输出的隐藏状态以及可选的初始嵌入输出。 -
attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回)- 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。 在注意力 softmax 之后的注意力权重,用于计算自注意力头中的加权平均值。
FalconForSequenceClassification 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的步骤需要在这个函数内定义,但应该在此之后调用Module实例,而不是在此之后调用,因为前者会处理运行前后处理步骤,而后者会默默地忽略它们。
单标签分类的示例:
>>> import torch
>>> from transformers import AutoTokenizer, FalconForSequenceClassification
>>> tokenizer = AutoTokenizer.from_pretrained("Rocketknight1/falcon-rw-1b")
>>> model = FalconForSequenceClassification.from_pretrained("Rocketknight1/falcon-rw-1b")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_class_id = logits.argmax().item()
>>> # To train a model on `num_labels` classes, you can pass `num_labels=num_labels` to `.from_pretrained(...)`
>>> num_labels = len(model.config.id2label)
>>> model = FalconForSequenceClassification.from_pretrained("Rocketknight1/falcon-rw-1b", num_labels=num_labels)
>>> labels = torch.tensor([1])
>>> loss = model(**inputs, labels=labels).loss多标签分类的示例:
>>> import torch
>>> from transformers import AutoTokenizer, FalconForSequenceClassification
>>> tokenizer = AutoTokenizer.from_pretrained("Rocketknight1/falcon-rw-1b")
>>> model = FalconForSequenceClassification.from_pretrained("Rocketknight1/falcon-rw-1b", problem_type="multi_label_classification")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_class_ids = torch.arange(0, logits.shape[-1])[torch.sigmoid(logits).squeeze(dim=0) > 0.5]
>>> # To train a model on `num_labels` classes, you can pass `num_labels=num_labels` to `.from_pretrained(...)`
>>> num_labels = len(model.config.id2label)
>>> model = FalconForSequenceClassification.from_pretrained(
... "Rocketknight1/falcon-rw-1b", num_labels=num_labels, problem_type="multi_label_classification"
... )
>>> labels = torch.sum(
... torch.nn.functional.one_hot(predicted_class_ids[None, :].clone(), num_classes=num_labels), dim=1
... ).to(torch.float)
>>> loss = model(**inputs, labels=labels).lossFalconForTokenClassification
class transformers.FalconForTokenClassification
( config: FalconConfig )参数
config(FalconConfig)- 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型关联的权重,只会加载配置。查看 from_pretrained()方法以加载模型权重。
Falcon 模型在顶部带有一个标记分类头(隐藏状态输出的线性层),例如用于命名实体识别(NER)任务。
此模型继承自 PreTrainedModel。查看超类文档以了解库为所有模型实现的通用方法(如下载或保存、调整输入嵌入等)。
此模型也是 PyTorch torch.nn.Module子类。将其用作常规 PyTorch 模块,并参考 PyTorch 文档以获取有关一般用法和行为的所有相关信息。
forward
( input_ids: Optional = None past_key_values: Optional = None attention_mask: Optional = None head_mask: Optional = None inputs_embeds: Optional = None labels: Optional = None use_cache: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.TokenClassifierOutput or tuple(torch.FloatTensor)参数
-
input_ids(形状为(batch_size, input_ids_length)的torch.LongTensor)- 如果past_key_values为None,则input_ids_length=sequence_length,否则input_ids_length=past_key_values[0][0].shape[2](输入过去键值状态的序列长度)。词汇表中输入序列标记的索引。 如果使用past_key_values,则只应将未计算其过去的input_ids作为input_ids传递。 可以使用 AutoTokenizer 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。 什么是输入 ID? -
past_key_values(长度为config.num_hidden_layers的Tuple[Tuple[torch.Tensor]])- 包含由模型计算的预计算隐藏状态(注意力块中的键和值),可以用于加速顺序解码。将其过去给定给此模型的input_ids不应作为input_ids传递,因为它们已经被计算过。past_key_values的每个元素都是一个元组(past_key,past_value):- past_key: [batch_size * num_heads, head_dim, kv_length]
- past_value: [batch_size * num_heads, kv_length, head_dim]
-
attention_mask(形状为(batch_size, sequence_length)的torch.FloatTensor,可选)— 用于避免在填充标记索引上执行注意力的掩码。掩码值在[0, 1]中选择:- 1 表示未被
掩码的标记, - 0 表示被
掩码的标记。
什么是注意力掩码?
- 1 表示未被
-
position_ids(形状为(batch_size, sequence_length)的torch.LongTensor,可选)— 每个输入序列标记在位置嵌入中的位置索引。在范围[0, config.n_positions - 1]中选择。 什么是位置 ID? -
head_mask(形状为(num_heads,)或(num_layers, num_heads)的torch.FloatTensor,可选)— 用于使自注意力模块的选定头部失效的掩码。掩码值在[0, 1]中选择:- 1 表示未被
掩码的标记, - 0 表示头部被
掩码。
- 1 表示未被
-
inputs_embeds(形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor,可选)— 可选地,可以直接传递嵌入表示而不是传递input_ids。如果您想要更多控制如何将input_ids索引转换为相关向量,而不是模型的内部嵌入查找矩阵,则这很有用。 如果使用past_key_values,则可能只需输入最后的inputs_embeds(参见past_key_values)。 -
use_cache(bool,可选)— 如果设置为True,则返回past_key_values键值状态,并可用于加速解码(参见past_key_values)。 -
output_attentions(bool,可选)— 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 -
output_hidden_states(bool,可选)— 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 -
return_dict(bool,可选)— 是否返回一个 ModelOutput 而不是一个普通元组。 -
labels(形状为(batch_size,)的torch.LongTensor,可选)— 用于计算序列分类/回归损失的标签。索引应在[0, ..., config.num_labels - 1]中。如果config.num_labels == 1,则计算回归损失(均方损失),如果config.num_labels > 1,则计算分类损失(交叉熵)。
返回
transformers.modeling_outputs.TokenClassifierOutput 或者tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.TokenClassifierOutput 或者一个torch.FloatTensor元组(如果传递了return_dict=False或者当config.return_dict=False时)包括根据配置(FalconConfig)和输入的不同元素。
-
loss(形状为(1,)的torch.FloatTensor,可选,当提供labels时返回)— 分类损失。 -
logits(形状为(batch_size, sequence_length, config.num_labels)的torch.FloatTensor)— 分类分数(SoftMax 之前)。 -
hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或者当config.output_hidden_states=True时返回)— 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(如果模型有嵌入层,则为嵌入输出的形状+每层的输出形状)。 模型在每一层输出的隐藏状态以及可选的初始嵌入输出。 -
attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或者当config.output_attentions=True时返回)— 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。 在注意力 softmax 之后的注意力权重,用于计算自注意力头中的加权平均值。
FalconForTokenClassification 的前向方法,覆盖了__call__特殊方法。
尽管前向传递的步骤需要在此函数内定义,但应该在此之后调用Module实例,而不是这个,因为前者会处理运行前后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoTokenizer, FalconForTokenClassification
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("Rocketknight1/falcon-rw-1b")
>>> model = FalconForTokenClassification.from_pretrained("Rocketknight1/falcon-rw-1b")
>>> inputs = tokenizer(
... "HuggingFace is a company based in Paris and New York", add_special_tokens=False, return_tensors="pt"
... )
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_token_class_ids = logits.argmax(-1)
>>> # Note that tokens are classified rather then input words which means that
>>> # there might be more predicted token classes than words.
>>> # Multiple token classes might account for the same word
>>> predicted_tokens_classes = [model.config.id2label[t.item()] for t in predicted_token_class_ids[0]]
>>> labels = predicted_token_class_ids
>>> loss = model(**inputs, labels=labels).lossFalconForQuestionAnswering
class transformers.FalconForQuestionAnswering
( config )参数
config(FalconConfig) — 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型关联的权重,只会加载配置。查看 from_pretrained()方法以加载模型权重。
Falcon 模型变压器,顶部带有用于提取问答任务的跨度分类头,如 SQuAD(在隐藏状态输出顶部的线性层,用于计算span start logits和span end logits)。
这个模型继承自 PreTrainedModel。查看超类文档以了解库实现的通用方法(如下载或保存,调整输入嵌入等)。
这个模型也是一个 PyTorch torch.nn.Module子类。将其用作常规 PyTorch 模块,并参考 PyTorch 文档以获取有关一般用法和行为的所有相关信息。
forward
( input_ids: Optional = None attention_mask: Optional = None head_mask: Optional = None inputs_embeds: Optional = None start_positions: Optional = None end_positions: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None )参数
-
input_ids(形状为(batch_size, input_ids_length)的torch.LongTensor) —input_ids_length=sequence_length(如果past_key_values为None)否则past_key_values[0][0].shape[2](输入过去键值状态的序列长度)。词汇表中输入序列标记的索引。 如果使用了past_key_values,则只应将未计算其过去的input_ids作为input_ids传递。 可以使用 AutoTokenizer 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。 什么是输入 ID? -
past_key_values(长度为config.num_hidden_layers的Tuple[Tuple[torch.Tensor]]) — 包含由模型计算的预计算隐藏状态(注意力块中的键和值,如下面的past_key_values输出所示)。可用于加速顺序解码。将其过去给定给此模型的input_ids不应作为input_ids传递,因为它们已经计算过。past_key_values的每个元素都是一个元组(past_key,past_value):- past_key: [batch_size * num_heads, head_dim, kv_length]
- past_value: [batch_size * num_heads, kv_length, head_dim]
-
attention_mask(形状为(batch_size, sequence_length)的torch.FloatTensor,可选) — 用于避免在填充标记索引上执行注意力的掩码。选择在[0, 1]中的掩码值:- 对于未被
masked的标记为 1 的标记, - 对于被
masked的标记为 0。
什么是注意力掩码?
- 对于未被
-
position_ids(形状为(batch_size, sequence_length)的torch.LongTensor,可选)— 每个输入序列标记在位置嵌入中的位置索引。在范围[0, config.n_positions - 1]中选择。 什么是位置 ID? -
head_mask(形状为(num_heads,)或(num_layers, num_heads)的torch.FloatTensor,可选)— 用于使自注意力模块的选定头部失效的掩码。掩码值选定在[0, 1]之间:- 1 表示头部未被遮罩,
- 0 表示头部被遮罩。
-
inputs_embeds(形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor,可选)— 可选地,您可以直接传递嵌入表示,而不是传递input_ids。如果您想要更多控制如何将input_ids索引转换为相关向量,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 如果使用past_key_values,可选地只需输入最后的inputs_embeds(参见past_key_values)。 -
use_cache(bool,可选)— 如果设置为True,则返回past_key_values键值状态,并可用于加速解码(参见past_key_values)。 -
output_attentions(bool,可选)— 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 -
output_hidden_states(bool,可选)— 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 -
return_dict(bool,可选)— 是否返回一个 ModelOutput 而不是一个普通元组。 -
start_positions(形状为(batch_size,)的torch.LongTensor,可选)— 用于计算标记范围起始位置的位置(索引)的标签,以计算标记分类损失。位置被夹紧到序列的长度(sequence_length)。序列外的位置不会被考虑在内以计算损失。 -
end_positions(形状为(batch_size,)的torch.LongTensor,可选)— 用于计算标记范围结束位置的位置(索引)的标签,以计算标记分类损失。位置被夹紧到序列的长度(sequence_length)。序列外的位置不会被考虑在内以计算损失。
FalconForQuestionAnswering 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的配方需要在此函数内定义,但应该在此之后调用Module实例,而不是在此处调用,因为前者负责运行预处理和后处理步骤,而后者则默默地忽略它们。
FastSpeech2Conformer
原始文本:
huggingface.co/docs/transformers/v4.37.2/en/model_doc/fastspeech2_conformer
概述
FastSpeech2Conformer 模型是由 Pengcheng Guo、Florian Boyer、Xuankai Chang、Tomoki Hayashi、Yosuke Higuchi、Hirofumi Inaguma、Naoyuki Kamo、Chenda Li、Daniel Garcia-Romero、Jiatong Shi、Jing Shi、Shinji Watanabe、Kun Wei、Wangyou Zhang 和 Yuekai Zhang 在论文 Recent Developments On Espnet Toolkit Boosted By Conformer 中提出的。
原始 FastSpeech2 论文的摘要如下:
非自回归文本到语音(TTS)模型,如 FastSpeech(Ren 等,2019),可以比以前的具有可比质量的自回归模型更快地合成语音。FastSpeech 模型的训练依赖于自回归教师模型进行持续时间预测(提供更多信息作为输入)和知识蒸馏(简化输出中的数据分布),这可以缓解 TTS 中的一对多映射问题(即,多种语音变体对应相同的文本)。然而,FastSpeech 有几个缺点:1)教师-学生蒸馏流程复杂且耗时,2)从教师模型提取的持续时间不够准确,从教师模型蒸馏的目标 mel-频谱图由于数据简化而遭受信息丢失,这两者限制了语音质量。在本文中,我们提出了 FastSpeech 2,它解决了 FastSpeech 中的问题,并通过以下方式更好地解决了 TTS 中的一对多映射问题:1)直接使用地面真实目标训练模型,而不是来自教师的简化输出,2)引入更多语音变体信息(例如,音高、能量和更准确的持续时间)作为条件输入。具体来说,我们从语音波形中提取持续时间、音高和能量,并直接将它们作为条件输入进行训练,并在推断中使用预测值。我们进一步设计了 FastSpeech 2s,这是第一次尝试从文本中并行直接生成语音波形,享受完全端到端推断的好处。实验结果表明:1)FastSpeech 2 比 FastSpeech 实现了 3 倍的训练加速,FastSpeech 2s 甚至享有更快的推断速度;2)FastSpeech 2 和 2s 在语音质量上优于 FastSpeech,FastSpeech 2 甚至可以超越自回归模型。音频样本可在 speechresearch.github.io/fastspeech2/ 上找到。
此模型由 Connor Henderson 贡献。原始代码可以在 这里 找到。
🤗 模型架构
FastSpeech2 的一般结构与 Mel 频谱图解码器一起实现,并且传统的 transformer blocks 被 ESPnet 库中的 conformer blocks 替换。
FastSpeech2 模型架构
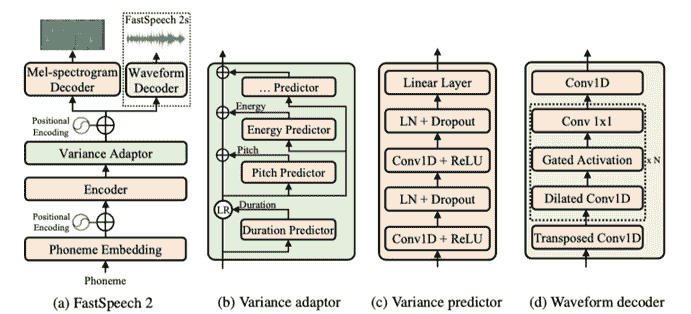
FastSpeech2 模型架构
Conformer Blocks

外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
卷积模块
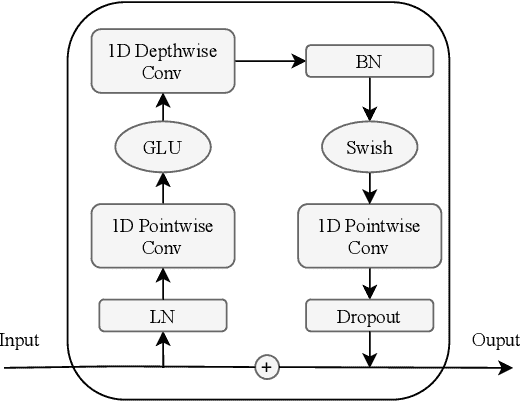
卷积模块
🤗 Transformers 使用
您可以在 🤗 Transformers 库中本地运行 FastSpeech2Conformer。
- 首先安装 🤗 Transformers 库,g2p-en:
pip install --upgrade pip
pip install --upgrade transformers g2p-en- 通过 Transformers 建模代码分别运行推断,使用模型和 hifigan
from transformers import FastSpeech2ConformerTokenizer, FastSpeech2ConformerModel, FastSpeech2ConformerHifiGan
import soundfile as sf
tokenizer = FastSpeech2ConformerTokenizer.from_pretrained("espnet/fastspeech2_conformer")
inputs = tokenizer("Hello, my dog is cute.", return_tensors="pt")
input_ids = inputs["input_ids"]
model = FastSpeech2ConformerModel.from_pretrained("espnet/fastspeech2_conformer")
output_dict = model(input_ids, return_dict=True)
spectrogram = output_dict["spectrogram"]
hifigan = FastSpeech2ConformerHifiGan.from_pretrained("espnet/fastspeech2_conformer_hifigan")
waveform = hifigan(spectrogram)
sf.write("speech.wav", waveform.squeeze().detach().numpy(), samplerate=22050)- 通过 Transformers 建模代码结合模型和 hifigan 运行推断
from transformers import FastSpeech2ConformerTokenizer, FastSpeech2ConformerWithHifiGan
import soundfile as sf
tokenizer = FastSpeech2ConformerTokenizer.from_pretrained("espnet/fastspeech2_conformer")
inputs = tokenizer("Hello, my dog is cute.", return_tensors="pt")
input_ids = inputs["input_ids"]
model = FastSpeech2ConformerWithHifiGan.from_pretrained("espnet/fastspeech2_conformer_with_hifigan")
output_dict = model(input_ids, return_dict=True)
waveform = output_dict["waveform"]
sf.write("speech.wav", waveform.squeeze().detach().numpy(), samplerate=22050)- 使用管道运行推断,并指定要使用的声码器
from transformers import pipeline, FastSpeech2ConformerHifiGan
import soundfile as sf
vocoder = FastSpeech2ConformerHifiGan.from_pretrained("espnet/fastspeech2_conformer_hifigan")
synthesiser = pipeline(model="espnet/fastspeech2_conformer", vocoder=vocoder)
speech = synthesiser("Hello, my dog is cooler than you!")
sf.write("speech.wav", speech["audio"].squeeze(), samplerate=speech["sampling_rate"])FastSpeech2ConformerConfig
class transformers.FastSpeech2ConformerConfig
( hidden_size = 384 vocab_size = 78 num_mel_bins = 80 encoder_num_attention_heads = 2 encoder_layers = 4 encoder_linear_units = 1536 decoder_layers = 4 decoder_num_attention_heads = 2 decoder_linear_units = 1536 speech_decoder_postnet_layers = 5 speech_decoder_postnet_units = 256 speech_decoder_postnet_kernel = 5 positionwise_conv_kernel_size = 3 encoder_normalize_before = False decoder_normalize_before = False encoder_concat_after = False decoder_concat_after = False reduction_factor = 1 speaking_speed = 1.0 use_macaron_style_in_conformer = True use_cnn_in_conformer = True encoder_kernel_size = 7 decoder_kernel_size = 31 duration_predictor_layers = 2 duration_predictor_channels = 256 duration_predictor_kernel_size = 3 energy_predictor_layers = 2 energy_predictor_channels = 256 energy_predictor_kernel_size = 3 energy_predictor_dropout = 0.5 energy_embed_kernel_size = 1 energy_embed_dropout = 0.0 stop_gradient_from_energy_predictor = False pitch_predictor_layers = 5 pitch_predictor_channels = 256 pitch_predictor_kernel_size = 5 pitch_predictor_dropout = 0.5 pitch_embed_kernel_size = 1 pitch_embed_dropout = 0.0 stop_gradient_from_pitch_predictor = True encoder_dropout_rate = 0.2 encoder_positional_dropout_rate = 0.2 encoder_attention_dropout_rate = 0.2 decoder_dropout_rate = 0.2 decoder_positional_dropout_rate = 0.2 decoder_attention_dropout_rate = 0.2 duration_predictor_dropout_rate = 0.2 speech_decoder_postnet_dropout = 0.5 max_source_positions = 5000 use_masking = True use_weighted_masking = False num_speakers = None num_languages = None speaker_embed_dim = None is_encoder_decoder = True **kwargs )参数
-
hidden_size(int, optional, defaults to 384) — 隐藏层的维度。 -
vocab_size(int, optional, defaults to 78) — 词汇表的大小。 -
num_mel_bins(int, optional, defaults to 80) — 滤波器组中使用的 mel 滤波器数量。 -
encoder_num_attention_heads(int, optional, defaults to 2) — 编码器中的注意力头数。 -
encoder_layers(int, optional, defaults to 4) — 编码器中的层数。 -
encoder_linear_units(int, optional, defaults to 1536) — 编码器中线性层的单元数。 -
decoder_layers(int, optional, defaults to 4) — 解码器中的层数。 -
decoder_num_attention_heads(int, optional, defaults to 2) — 解码器中的注意力头数。 -
decoder_linear_units(int, optional, defaults to 1536) — 解码器中线性层的单元数。 -
speech_decoder_postnet_layers(int, optional, defaults to 5) — 语音解码器后处理网络中的层数。 -
speech_decoder_postnet_units(int, optional, defaults to 256) — 语音解码器后处理网络中的单元数。 -
speech_decoder_postnet_kernel(int, optional, defaults to 5) — 语音解码器后处理网络中的卷积核大小。 -
positionwise_conv_kernel_size(int, optional, defaults to 3) — 位置感知层中使用的卷积核大小。 -
encoder_normalize_before(bool, optional, defaults toFalse) — 指定是否在编码器层之前进行归一化。 -
decoder_normalize_before(bool, optional, defaults toFalse) — 指定是否在解码器层之前进行归一化。 -
encoder_concat_after(bool, optional, defaults toFalse) — 指定是否在编码器层之后进行连接。 -
decoder_concat_after(bool, optional, defaults toFalse) — 指定是否在解码器层之后进行连接。 -
reduction_factor(int, optional, defaults to 1) — 语音帧速率减少的因子。 -
speaking_speed(float, optional, defaults to 1.0) — 生成语音的速度。 -
use_macaron_style_in_conformer(bool, optional, defaults toTrue) — 指定是否在 conformer 中使用 macaron 风格。 -
use_cnn_in_conformer(bool, optional, defaults toTrue) — 指定是否在 conformer 中使用卷积神经网络。 -
encoder_kernel_size(int, optional, defaults to 7) — 编码器中使用的卷积核大小。 -
decoder_kernel_size(int, optional, defaults to 31) — 解码器中使用的卷积核大小。 -
duration_predictor_layers(int, optional, defaults to 2) — 预测器中的层数。 -
duration_predictor_channels(int, optional, defaults to 256) — 预测器中通道的数量。 -
duration_predictor_kernel_size(int, optional, defaults to 3) — 预测器中使用的卷积核大小。 -
energy_predictor_layers(int, optional, defaults to 2) — 能量预测器中的层数。 -
energy_predictor_channels(int, optional, defaults to 256) — 能量预测器中的通道数。 -
energy_predictor_kernel_size(int, optional, defaults to 3) — 能量预测器中使用的卷积核大小。 -
energy_predictor_dropout(float, optional, defaults to 0.5) — 能量预测器中的 dropout 率。 -
energy_embed_kernel_size(int, optional, defaults to 1) — 能量嵌入层中使用的卷积核大小。 -
energy_embed_dropout(float, optional, defaults to 0.0) — 能量嵌入层中的 dropout 率。 -
stop_gradient_from_energy_predictor(bool, optional, defaults toFalse) — 指定是否从能量预测器中停止梯度。 -
pitch_predictor_layers(int, optional, defaults to 5) — 音高预测器中的层数。 -
pitch_predictor_channels(int, optional, defaults to 256) — 音高预测器中的通道数。 -
pitch_predictor_kernel_size(int, optional, defaults to 5) — 音高预测器中使用的内核大小。 -
pitch_predictor_dropout(float, optional, defaults to 0.5) — 音高预测器中的 dropout 率。 -
pitch_embed_kernel_size(int, optional, defaults to 1) — 音高嵌入层中使用的内核大小。 -
pitch_embed_dropout(float, optional, defaults to 0.0) — 音高嵌入层中的 dropout 率。 -
stop_gradient_from_pitch_predictor(bool, optional, defaults toTrue) — 指定是否停止来自音高预测器的梯度。 -
encoder_dropout_rate(float, optional, defaults to 0.2) — 编码器中的 dropout 率。 -
encoder_positional_dropout_rate(float, optional, defaults to 0.2) — 编码器中的位置 dropout 率。 -
encoder_attention_dropout_rate(float, optional, defaults to 0.2) — 编码器中的注意力 dropout 率。 -
decoder_dropout_rate(float, optional, defaults to 0.2) — 解码器中的 dropout 率。 -
decoder_positional_dropout_rate(float, optional, defaults to 0.2) — 解码器中的位置 dropout 率。 -
decoder_attention_dropout_rate(float, optional, defaults to 0.2) — 解码器中的注意力 dropout 率。 -
duration_predictor_dropout_rate(float, optional, defaults to 0.2) — 持续时间预测器中的 dropout 率。 -
speech_decoder_postnet_dropout(float, optional, defaults to 0.5) — 语音解码器后置网络中的 dropout 率。 -
max_source_positions(int, optional, defaults to 5000) — 如果使用“相对”位置嵌入,则定义最大源输入位置。 -
use_masking(bool, optional, defaults toTrue) — 指定模型是否使用掩码。 -
use_weighted_masking(bool, optional, defaults toFalse) — 指定模型是否使用加权掩码。 -
num_speakers(int, optional) — 说话者数量。如果设置为 > 1,则假定说话者 id 将作为输入提供,并使用说话者 id 嵌入层。 -
num_languages(int, optional) — 语言数量。如果设置为 > 1,则假定语言 id 将作为输入提供,并使用语言 id 嵌入层。 -
speaker_embed_dim(int, optional) — 说话者嵌入维度。如果设置为 > 0,则假定将提供说话者嵌入作为输入。 -
is_encoder_decoder(bool, optional, defaults toTrue) — 指定模型是否为编码器-解码器。
这是用于存储 FastSpeech2ConformerModel 配置的配置类。根据指定的参数实例化一个 FastSpeech2Conformer 模型,定义模型架构。使用默认值实例化配置将产生类似于 FastSpeech2Conformer espnet/fastspeech2_conformer架构的配置。
配置对象继承自 PretrainedConfig,可用于控制模型输出。阅读来自 PretrainedConfig 的文档以获取更多信息。
示例:
>>> from transformers import FastSpeech2ConformerModel, FastSpeech2ConformerConfig
>>> # Initializing a FastSpeech2Conformer style configuration
>>> configuration = FastSpeech2ConformerConfig()
>>> # Initializing a model from the FastSpeech2Conformer style configuration
>>> model = FastSpeech2ConformerModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configFastSpeech2ConformerHifiGanConfig
class transformers.FastSpeech2ConformerHifiGanConfig
( model_in_dim = 80 upsample_initial_channel = 512 upsample_rates = [8, 8, 2, 2] upsample_kernel_sizes = [16, 16, 4, 4] resblock_kernel_sizes = [3, 7, 11] resblock_dilation_sizes = [[1, 3, 5], [1, 3, 5], [1, 3, 5]] initializer_range = 0.01 leaky_relu_slope = 0.1 normalize_before = True **kwargs )参数
-
model_in_dim(int, optional, defaults to 80) — 输入对数梅尔频谱图中的频率箱数。 -
upsample_initial_channel(int, 可选, 默认为 512) — 进入上采样网络的输入通道数。 -
upsample_rates(Tuple[int]或List[int], 可选, 默认为[8, 8, 2, 2]) — 一个整数元组,定义了上采样网络中每个 1D 卷积层的步幅。upsample_rates 的长度定义了卷积层的数量,并且必须与 upsample_kernel_sizes 的长度匹配。 -
upsample_kernel_sizes(Tuple[int]或List[int], 可选, 默认为[16, 16, 4, 4]) — 一个整数元组,定义了上采样网络中每个 1D 卷积层的内核大小。upsample_kernel_sizes 的长度定义了卷积层的数量,并且必须与 upsample_rates 的长度匹配。 -
resblock_kernel_sizes(Tuple[int]或List[int], 可选, 默认为[3, 7, 11]) — 一个整数元组,定义了多接受域融合(MRF)模块中 1D 卷积层的内核大小。 -
resblock_dilation_sizes(Tuple[Tuple[int]]或List[List[int]], 可选, 默认为[[1, 3, 5], [1, 3, 5], [1, 3, 5]]) — 一个嵌套的整数元组,定义了多接受域融合(MRF)模块中扩张的 1D 卷积层的扩张率。 -
initializer_range(float, 可选, 默认为 0.01) — 用于初始化所有权重矩阵的截断正态初始化器的标准差。 -
leaky_relu_slope(float, 可选, 默认为 0.1) — leaky ReLU 激活函数使用的负斜率的角度。 -
normalize_before(bool, 可选, 默认为True) — 是否在使用语音合成器的学习均值和方差进行声谱归一化之前对声谱进行归一化。
这是用于存储 FastSpeech2ConformerHifiGanModel 配置的配置类。根据指定的参数实例化一个 FastSpeech2Conformer HiFi-GAN 语音合成模型,定义模型架构。使用默认值实例化一个配置将产生类似于 FastSpeech2Conformer espnet/fastspeech2_conformer_hifigan 架构的配置。
配置对象继承自 PretrainedConfig,可用于控制模型输出。阅读来自 PretrainedConfig 的文档以获取更多信息。
示例:
>>> from transformers import FastSpeech2ConformerHifiGan, FastSpeech2ConformerHifiGanConfig
>>> # Initializing a FastSpeech2ConformerHifiGan configuration
>>> configuration = FastSpeech2ConformerHifiGanConfig()
>>> # Initializing a model (with random weights) from the configuration
>>> model = FastSpeech2ConformerHifiGan(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configFastSpeech2ConformerWithHifiGanConfig
class transformers.FastSpeech2ConformerWithHifiGanConfig
( model_config: Dict = None vocoder_config: Dict = None **kwargs )参数
-
model_config(typing.Dict, 可选) — 文本到语音模型的配置。 -
vocoder_config(typing.Dict, 可选) — 语音合成模型的配置。
这是用于存储 FastSpeech2ConformerWithHifiGan 配置的配置类。根据指定的子模型配置实例化一个 FastSpeech2ConformerWithHifiGanModel 模型,定义模型架构。
使用默认值实例化一个配置将产生类似于 FastSpeech2ConformerModel espnet/fastspeech2_conformer 和 FastSpeech2ConformerHifiGan espnet/fastspeech2_conformer_hifigan 架构的配置。
配置对象继承自 PretrainedConfig,可用于控制模型输出。阅读 PretrainedConfig 的文档以获取更多信息。
model_config(FastSpeech2ConformerConfig,optional):文本到语音模型的配置。vocoder_config(FastSpeech2ConformerHiFiGanConfig,optional):声码器模型的配置。
示例:
>>> from transformers import (
... FastSpeech2ConformerConfig,
... FastSpeech2ConformerHifiGanConfig,
... FastSpeech2ConformerWithHifiGanConfig,
... FastSpeech2ConformerWithHifiGan,
... )
>>> # Initializing FastSpeech2ConformerWithHifiGan sub-modules configurations.
>>> model_config = FastSpeech2ConformerConfig()
>>> vocoder_config = FastSpeech2ConformerHifiGanConfig()
>>> # Initializing a FastSpeech2ConformerWithHifiGan module style configuration
>>> configuration = FastSpeech2ConformerWithHifiGanConfig(model_config.to_dict(), vocoder_config.to_dict())
>>> # Initializing a model (with random weights)
>>> model = FastSpeech2ConformerWithHifiGan(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configFastSpeech2ConformerTokenizer
class transformers.FastSpeech2ConformerTokenizer
( vocab_file bos_token = '<sos/eos>' eos_token = '<sos/eos>' pad_token = '<blank>' unk_token = '<unk>' should_strip_spaces = False **kwargs )参数
-
vocab_file(str) — 词汇表文件的路径。 -
bos_token(str, optional, defaults to"<sos/eos>") — 序列开始标记。请注意,对于 FastSpeech2,它与eos_token相同。 -
eos_token(str, optional, defaults to"<sos/eos>") — 序列结束标记。请注意,对于 FastSpeech2,它与bos_token相同。 -
pad_token(str, optional, defaults to"<blank>") — 用于填充的标记,例如在批处理不同长度的序列时使用。 -
unk_token(str, optional, defaults to"<unk>") — 未知标记。词汇表中没有的标记无法转换为 ID,而是设置为此标记。 -
should_strip_spaces(bool, optional, defaults toFalse) — 是否去除标记列表中的空格。
构建一个 FastSpeech2Conformer 分词器。
__call__
( text: Union = None text_pair: Union = None text_target: Union = None text_pair_target: Union = None add_special_tokens: bool = True padding: Union = False truncation: Union = None max_length: Optional = None stride: int = 0 is_split_into_words: bool = False pad_to_multiple_of: Optional = None return_tensors: Union = None return_token_type_ids: Optional = None return_attention_mask: Optional = None return_overflowing_tokens: bool = False return_special_tokens_mask: bool = False return_offsets_mapping: bool = False return_length: bool = False verbose: bool = True **kwargs ) → export const metadata = 'undefined';BatchEncoding参数
-
text(str,List[str],List[List[str]], optional) — 要编码的序列或批处理的序列。每个序列可以是字符串或字符串列表(预先标记化的字符串)。如果将序列提供为字符串列表(预先标记化),则必须设置is_split_into_words=True(以消除与批处理序列的歧义)。 -
text_pair(str,List[str],List[List[str]], optional) — 要编码的序列或批处理的序列。每个序列可以是字符串或字符串列表(预先标记化的字符串)。如果将序列提供为字符串列表(预先标记化),则必须设置is_split_into_words=True(以消除与批处理序列的歧义)。 -
text_target(str,List[str],List[List[str]], optional) — 要编码为目标文本的序列或批处理的序列。每个序列可以是字符串或字符串列表(预先标记化的字符串)。如果将序列提供为字符串列表(预先标记化),则必须设置is_split_into_words=True(以消除与批处理序列的歧义)。 -
text_pair_target(str,List[str],List[List[str]], optional) — 要编码为目标文本的序列或批处理的序列。每个序列可以是字符串或字符串列表(预先标记化的字符串)。如果将序列提供为字符串列表(预先标记化),则必须设置is_split_into_words=True(以消除与批处理序列的歧义)。 -
add_special_tokens(bool, optional, defaults toTrue) — 在编码序列时是否添加特殊标记。这将使用底层的PretrainedTokenizerBase.build_inputs_with_special_tokens函数,该函数定义了自动添加到输入 ID 的标记。如果要自动添加bos或eos标记,则这很有用。 -
padding(bool,stror PaddingStrategy, optional, defaults toFalse) — 激活和控制填充。接受以下值:-
True或'longest': 填充到批次中最长的序列(如果只提供了单个序列,则不填充)。 -
'max_length': 填充到由参数max_length指定的最大长度,或者如果未提供该参数,则填充到模型的最大可接受输入长度。 -
False或'do_not_pad'(默认): 不填充(即,可以输出具有不同长度序列的批次)。
-
-
truncation(bool,str或 TruncationStrategy, 可选, 默认为False) — 激活和控制截断。接受以下值:-
True或'longest_first': 截断到由参数max_length指定的最大长度,或者如果未提供该参数,则截断到模型的最大可接受输入长度。如果提供了一对序列(或一批对序列),则逐标记截断,从一对序列中最长的序列中删除一个标记。 -
'only_first': 截断到由参数max_length指定的最大长度,或者如果未提供该参数,则截断到模型的最大可接受输入长度。如果提供了一对序列(或一批对序列),则仅截断第一个序列。 -
'only_second': 截断到由参数max_length指定的最大长度,或者如果未提供该参数,则截断到模型的最大可接受输入长度。如果提供了一对序列(或一批对序列),则仅截断第二个序列。 -
False或'do_not_truncate'(默认): 不截断(即,可以输出序列长度大于模型最大可接受输入大小的批次)。
-
-
max_length(int, 可选) — 控制截断/填充参数使用的最大长度。 如果未设置或设置为None,则如果截断/填充参数中需要最大长度,则将使用预定义的模型最大长度。如果模型没有特定的最大输入长度(如 XLNet),则将禁用截断/填充到最大长度。 -
stride(int, 可选, 默认为 0) — 如果与max_length一起设置为一个数字,则当return_overflowing_tokens=True时返回的溢出标记将包含截断序列末尾的一些标记,以提供截断和溢出序列之间的一些重叠。该参数的值定义了重叠标记的数量。 -
is_split_into_words(bool, 可选, 默认为False) — 输入是否已经预分词(例如,已分割为单词)。如果设置为True,分词器将假定输入已经分割为单词(例如,通过在空格上分割),然后对其进行分词。这对于命名实体识别或标记分类很有用。 -
pad_to_multiple_of(int, 可选) — 如果设置,将序列填充到提供的值的倍数。需要激活padding。这对于在具有计算能力>= 7.5(Volta)的 NVIDIA 硬件上启用 Tensor Cores 特别有用。 -
return_tensors(str或 TensorType, 可选) — 如果设置,将返回张量而不是 Python 整数列表。可接受的值为:-
'tf': 返回 TensorFlowtf.constant对象。 -
'pt': 返回 PyTorchtorch.Tensor对象。 -
'np': 返回 Numpynp.ndarray对象。
-
-
return_token_type_ids(bool, 可选) — 是否返回标记类型 ID。如果保持默认设置,将根据特定分词器的默认设置返回标记类型 ID,由return_outputs属性定义。 什么是标记类型 ID? -
return_attention_mask(bool, 可选) — 是否返回注意力遮罩。如果保持默认设置,将根据特定分词器的默认设置返回注意力遮罩,由return_outputs属性定义。 什么是注意力掩码? -
return_overflowing_tokens(bool,可选,默认为False) — 是否返回溢出的令牌序列。如果提供了一对输入 ID 序列(或一批对),并且truncation_strategy = longest_first或True,则会引发错误,而不是返回溢出的令牌。 -
return_special_tokens_mask(bool,可选,默认为False) — 是否返回特殊令牌掩码信息。 -
return_offsets_mapping(bool,可选,默认为False) — 是否返回每个令牌的(char_start,char_end)。 仅适用于继承自 PreTrainedTokenizerFast 的快速分词器,如果使用 Python 的分词器,此方法将引发NotImplementedError。 -
return_length(bool,可选,默认为False) — 是否返回编码输入的长度。 -
verbose(bool,可选,默认为True) — 是否打印更多信息和警告。**kwargs — 传递给self.tokenize()方法
返回
BatchEncoding
具有以下字段的 BatchEncoding:
-
input_ids— 要馈送到模型的令牌 ID 列表。 什么是输入 ID? -
token_type_ids— 要馈送到模型的令牌类型 ID 列表(当return_token_type_ids=True或*token_type_ids*在self.model_input_names中时)。 什么是令牌类型 ID? -
attention_mask— 指定哪些令牌应由模型关注的索引列表(当return_attention_mask=True或*attention_mask*在self.model_input_names中时)。 什么是注意力掩码? -
overflowing_tokens— 溢出令牌序列的列表(当指定max_length并且return_overflowing_tokens=True时)。 -
num_truncated_tokens— 截断的令牌数(当指定max_length并且return_overflowing_tokens=True时)。 -
special_tokens_mask— 由 0 和 1 组成的列表,其中 1 指定添加的特殊令牌,0 指定常规序列令牌(当add_special_tokens=True和return_special_tokens_mask=True时)。 -
length— 输入的长度(当return_length=True时)
对一个或多个序列或一个或多个序列对进行标记化和准备模型的主要方法。
save_vocabulary
( save_directory: str filename_prefix: Optional = None ) → export const metadata = 'undefined';Tuple(str)参数
save_directory(str) — 要保存词汇表的目录。
返回
Tuple(str)
保存的文件路径。
将词汇表和特殊令牌文件保存到目录。
decode
( token_ids **kwargs )batch_decode
( sequences: Union skip_special_tokens: bool = False clean_up_tokenization_spaces: bool = None **kwargs ) → export const metadata = 'undefined';List[str]参数
-
sequences(Union[List[int],List[List[int]],np.ndarray,torch.Tensor,tf.Tensor]) — 标记化输入 ID 的列表。可以使用__call__方法获得。 -
skip_special_tokens(bool,可选,默认为False) — 是否在解码中删除特殊令牌。 -
clean_up_tokenization_spaces(bool,可选) — 是否清理标记化空格。如果为None,将默认为self.clean_up_tokenization_spaces。 -
kwargs(附加关键字参数,可选) — 将传递给底层模型特定的解码方法。
返回
List[str]
解码句子列表。
通过调用解码将令牌 ID 列表的列表转换为字符串列表。
FastSpeech2ConformerModel
class transformers.FastSpeech2ConformerModel
( config: FastSpeech2ConformerConfig )参数
config(FastSpeech2ConformerConfig)- 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型关联的权重,只加载配置。查看 from_pretrained()方法以加载模型权重。
FastSpeech2Conformer 模型。该模型继承自 PreTrainedModel。检查超类文档以获取库为其所有模型实现的通用方法(例如下载或保存、调整输入嵌入、修剪头等)。
该模型也是 PyTorch torch.nn.Module子类。将其用作常规 PyTorch 模块,并参考 PyTorch 文档以获取与一般用法和行为相关的所有事项。
FastSpeech 2 模块。
这是 FastSpeech 2 中描述的模块,详见‘FastSpeech 2: Fast and High-Quality End-to-End Text to Speech’ arxiv.org/abs/2006.04558。我们使用 FastPitch 中引入的令牌平均值,而不是量化音高和能量。编码器和解码器是 Conformers 而不是常规 Transformers。
forward
( input_ids: LongTensor attention_mask: Optional = None spectrogram_labels: Optional = None duration_labels: Optional = None pitch_labels: Optional = None energy_labels: Optional = None speaker_ids: Optional = None lang_ids: Optional = None speaker_embedding: Optional = None return_dict: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None ) → export const metadata = 'undefined';transformers.models.fastspeech2_conformer.modeling_fastspeech2_conformer.FastSpeech2ConformerModelOutput or tuple(torch.FloatTensor)参数
-
input_ids(形状为(batch_size, sequence_length)的torch.LongTensor)- 文本向量的输入序列。 -
attention_mask(形状为(batch_size, sequence_length)的torch.LongTensor,可选,默认为None)- 避免在填充标记索引上执行卷积和注意力的掩码。选择在[0, 1]中的掩码值:0 表示掩码的标记,1 表示未掩码的标记。 -
spectrogram_labels(形状为(batch_size, max_spectrogram_length, num_mel_bins)的torch.FloatTensor,可选,默认为None)- 填充目标特征的批次。 -
duration_labels(形状为(batch_size, sequence_length + 1)的torch.LongTensor,可选,默认为None)- 填充的持续时间批次。 -
pitch_labels(形状为(batch_size, sequence_length + 1, 1)的torch.FloatTensor,可选,默认为None)- 填充的令牌平均音高批次。 -
energy_labels(形状为(batch_size, sequence_length + 1, 1)的torch.FloatTensor,可选,默认为None)- 填充的令牌平均能量。 -
speaker_ids(形状为(batch_size, 1)的torch.LongTensor,可选,默认为None)- 用于调节模型输出语音特征的说话者 id。 -
lang_ids(形状为(batch_size, 1)的torch.LongTensor,可选,默认为None)- 用于调节模型输出语音特征的语言 id。 -
speaker_embedding(形状为(batch_size, embedding_dim)的torch.FloatTensor,可选,默认为None)- 包含语音特征的调节信号的嵌入。 -
return_dict(bool,可选,默认为None)- 是否返回FastSpeech2ConformerModelOutput而不是普通元组。 -
output_attentions(bool,可选,默认为None)- 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的attentions。 -
output_hidden_states(bool,可选,默认为None)- 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。
返回
transformers.models.fastspeech2_conformer.modeling_fastspeech2_conformer.FastSpeech2ConformerModelOutput或tuple(torch.FloatTensor)
一个transformers.models.fastspeech2_conformer.modeling_fastspeech2_conformer.FastSpeech2ConformerModelOutput或一个torch.FloatTensor元组(如果传递了return_dict=False或config.return_dict=False时)包括各种元素,取决于配置(FastSpeech2ConformerConfig)和输入。
-
loss(torch.FloatTensor,形状为(1,),可选,当提供labels时返回)— 频谱图生成损失。 -
spectrogram(torch.FloatTensor,形状为(batch_size, sequence_length, num_bins))— 预测的频谱图。 -
encoder_last_hidden_state(torch.FloatTensor,形状为(batch_size, sequence_length, hidden_size),可选)— 模型编码器最后一层的隐藏状态序列。 -
encoder_hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回)— 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(如果模型有嵌入层,则为嵌入输出的一个,加上每一层的输出的一个)。 编码器在每一层输出的隐藏状态加上初始嵌入输出。 -
encoder_attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回)— 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组。 编码器的注意力权重,在注意力 softmax 之后,用于计算自注意力头中的加权平均值。 -
decoder_hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回)— 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(如果模型有嵌入层,则为嵌入输出的一个,加上每一层的输出的一个)。 解码器在每一层输出的隐藏状态加上初始嵌入输出。 -
decoder_attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回)— 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组。 解码器的注意力权重,在注意力 softmax 之后,用于计算自注意力头中的加权平均值。 -
duration_outputs(torch.LongTensor,形状为(batch_size, max_text_length + 1),可选)— 时长预测器的输出。 -
pitch_outputs(torch.FloatTensor,形状为(batch_size, max_text_length + 1, 1),可选)— 音高预测器的输出。 -
energy_outputs(torch.FloatTensor,形状为(batch_size, max_text_length + 1, 1),可选)— 能量预测器的输出。
示例:
>>> from transformers import (
... FastSpeech2ConformerTokenizer,
... FastSpeech2ConformerModel,
... FastSpeech2ConformerHifiGan,
... )
>>> tokenizer = FastSpeech2ConformerTokenizer.from_pretrained("espnet/fastspeech2_conformer")
>>> inputs = tokenizer("some text to convert to speech", return_tensors="pt")
>>> input_ids = inputs["input_ids"]
>>> model = FastSpeech2ConformerModel.from_pretrained("espnet/fastspeech2_conformer")
>>> output_dict = model(input_ids, return_dict=True)
>>> spectrogram = output_dict["spectrogram"]
>>> vocoder = FastSpeech2ConformerHifiGan.from_pretrained("espnet/fastspeech2_conformer_hifigan")
>>> waveform = vocoder(spectrogram)
>>> print(waveform.shape)
torch.Size([1, 49664])FastSpeech2ConformerHifiGan
class transformers.FastSpeech2ConformerHifiGan
( config: FastSpeech2ConformerHifiGanConfig )参数
config(FastSpeech2ConformerConfig)— 包含模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained()方法以加载模型权重。
HiFi-GAN 语音合成器。此模型继承自 PreTrainedModel。检查超类文档以获取库为所有模型实现的通用方法(如下载或保存、调整输入嵌入、修剪头等)。
此模型还是一个 PyTorch torch.nn.Module 子类。将其用作常规的 PyTorch 模块,并参考 PyTorch 文档以获取与一般用法和行为相关的所有事项。
forward
( spectrogram: FloatTensor ) → export const metadata = 'undefined';torch.FloatTensor参数
spectrogram(torch.FloatTensor) — 包含对数梅尔频谱图的张量。可以是批量处理的,形状为(batch_size, sequence_length, config.model_in_dim),也可以是未批量处理的,形状为(sequence_length, config.model_in_dim)。
返回
torch.FloatTensor
包含语音波形的张量。如果输入的频谱图是批量处理的,则形状为 (batch_size, num_frames,)。如果未批量处理,则形状为 (num_frames,)。
将对数梅尔频谱图转换为语音波形。传递一批对数梅尔频谱图将返回一批语音波形。传递单个未批量处理的对数梅尔频谱图将返回单个未批量处理的语音波形。
FastSpeech2ConformerWithHifiGan
class transformers.FastSpeech2ConformerWithHifiGan
( config: FastSpeech2ConformerWithHifiGanConfig )参数
config(FastSpeech2ConformerWithHifiGanConfig) — 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型关联的权重,只加载配置。查看 from_pretrained() 方法以加载模型权重。
FastSpeech2ConformerModel 具有 FastSpeech2ConformerHifiGan 语音合成器头部,执行文本转语音(波形)。此模型继承自 PreTrainedModel。检查超类文档以获取库为所有模型实现的通用方法(如下载或保存、调整输入嵌入、修剪头等)。
此模型还是一个 PyTorch torch.nn.Module 子类。将其用作常规的 PyTorch 模块,并参考 PyTorch 文档以获取与一般用法和行为相关的所有事项。
forward
( input_ids: LongTensor attention_mask: Optional = None spectrogram_labels: Optional = None duration_labels: Optional = None pitch_labels: Optional = None energy_labels: Optional = None speaker_ids: Optional = None lang_ids: Optional = None speaker_embedding: Optional = None return_dict: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None ) → export const metadata = 'undefined';transformers.models.fastspeech2_conformer.modeling_fastspeech2_conformer.FastSpeech2ConformerWithHifiGanOutput or tuple(torch.FloatTensor)参数
-
input_ids(torch.LongTensorof shape(batch_size, sequence_length)) — 文本向量的输入序列。 -
attention_mask(torch.LongTensorof shape(batch_size, sequence_length), optional, defaults toNone) — 避免在填充令牌索引上执行卷积和注意力的掩码。掩码值选在[0, 1]:0 表示掩码的令牌,1 表示未掩码的令牌。 -
spectrogram_labels(torch.FloatTensorof shape(batch_size, max_spectrogram_length, num_mel_bins), optional, defaults toNone) — 批量填充的目标特征。 -
duration_labels(torch.LongTensorof shape(batch_size, sequence_length + 1), optional, defaults toNone) — 批量填充的持续时间。 -
pitch_labels(torch.FloatTensorof shape(batch_size, sequence_length + 1, 1), optional, defaults toNone) — 批量填充的令牌平均音高。 -
energy_labels(torch.FloatTensorof shape(batch_size, sequence_length + 1, 1), optional, defaults toNone) — 填充的令牌平均能量的批量。 -
speaker_ids(torch.LongTensorof shape(batch_size, 1), optional, defaults toNone) — 用于调节模型输出语音特征的说话者 id。 -
lang_ids(torch.LongTensorof shape(batch_size, 1), optional, defaults toNone) — 用于调节模型输出语音特征的语言 id。 -
speaker_embedding(torch.FloatTensorof shape(batch_size, embedding_dim), optional, defaults toNone) — 包含语音特征调节信号的嵌入。 -
return_dict(bool, optional, defaults toNone) — 是否返回FastSpeech2ConformerModelOutput而不是普通元组。 -
output_attentions(bool, optional, defaults toNone) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 -
output_hidden_states(bool, optional, defaults toNone) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。
返回
transformers.models.fastspeech2_conformer.modeling_fastspeech2_conformer.FastSpeech2ConformerWithHifiGanOutput或tuple(torch.FloatTensor)
一个transformers.models.fastspeech2_conformer.modeling_fastspeech2_conformer.FastSpeech2ConformerWithHifiGanOutput或一个torch.FloatTensor元组(如果传递return_dict=False或config.return_dict=False,则返回)包含根据配置(<class 'transformers.models.fastspeech2_conformer.configuration_fastspeech2_conformer.FastSpeech2ConformerWithHifiGanConfig'>)和输入的各种元素。
-
waveform(torch.FloatTensorof shape(batch_size, audio_length)) — 通过声码器将预测的梅尔频谱图传递后的语音输出。 -
loss(torch.FloatTensorof shape(1,), optional, 当提供labels时返回) — 频谱图生成损失。 -
spectrogram(torch.FloatTensorof shape(batch_size, sequence_length, num_bins)) — 预测的频谱图。 -
encoder_last_hidden_state(torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — 模型编码器最后一层的隐藏状态序列。 -
encoder_hidden_states(tuple(torch.FloatTensor), optional, 当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组。 编码器每层的隐藏状态加上初始嵌入输出。 -
encoder_attentions(tuple(torch.FloatTensor), optional, 当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组。 编码器的注意力权重,在注意力 softmax 之后,用于计算自注意力头中的加权平均值。 -
decoder_hidden_states(tuple(torch.FloatTensor), optional, 当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组。 每层解码器的输出隐藏状态加上初始嵌入输出。 -
decoder_attentions(tuple(torch.FloatTensor), optional, 当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组。 解码器的注意力权重,在注意力 softmax 之后,用于计算自注意力头中的加权平均值。 -
duration_outputs(torch.LongTensorof shape(batch_size, max_text_length + 1), optional) — 持续时间预测器的输出。 -
pitch_outputs(torch.FloatTensorof shape(batch_size, max_text_length + 1, 1), optional) — 音高预测器的输出。 -
energy_outputs(torch.FloatTensorof shape(batch_size, max_text_length + 1, 1), optional) — 能量预测器的输出。
示例:
>>> from transformers import (
... FastSpeech2ConformerTokenizer,
... FastSpeech2ConformerWithHifiGan,
... )
>>> tokenizer = FastSpeech2ConformerTokenizer.from_pretrained("espnet/fastspeech2_conformer")
>>> inputs = tokenizer("some text to convert to speech", return_tensors="pt")
>>> input_ids = inputs["input_ids"]
>>> model = FastSpeech2ConformerWithHifiGan.from_pretrained("espnet/fastspeech2_conformer_with_hifigan")
>>> output_dict = model(input_ids, return_dict=True)
>>> waveform = output_dict["waveform"]
>>> print(waveform.shape)
torch.Size([1, 49664])astspeech2_conformer.modeling_fastspeech2_conformer.FastSpeech2ConformerWithHifiGanOutput或一个torch.FloatTensor元组(如果传递return_dict=False或config.return_dict=False,则返回)包含根据配置(<class ‘transformers.models.fastspeech2_conformer.configuration_fastspeech2_conformer.FastSpeech2ConformerWithHifiGanConfig’>`)和输入的各种元素。
-
waveform(torch.FloatTensorof shape(batch_size, audio_length)) — 通过声码器将预测的梅尔频谱图传递后的语音输出。 -
loss(torch.FloatTensorof shape(1,), optional, 当提供labels时返回) — 频谱图生成损失。 -
spectrogram(torch.FloatTensorof shape(batch_size, sequence_length, num_bins)) — 预测的频谱图。 -
encoder_last_hidden_state(torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — 模型编码器最后一层的隐藏状态序列。 -
encoder_hidden_states(tuple(torch.FloatTensor), optional, 当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组。 编码器每层的隐藏状态加上初始嵌入输出。 -
encoder_attentions(tuple(torch.FloatTensor), optional, 当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组。 编码器的注意力权重,在注意力 softmax 之后,用于计算自注意力头中的加权平均值。 -
decoder_hidden_states(tuple(torch.FloatTensor), optional, 当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组。 每层解码器的输出隐藏状态加上初始嵌入输出。 -
decoder_attentions(tuple(torch.FloatTensor), optional, 当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组。 解码器的注意力权重,在注意力 softmax 之后,用于计算自注意力头中的加权平均值。 -
duration_outputs(torch.LongTensorof shape(batch_size, max_text_length + 1), optional) — 持续时间预测器的输出。 -
pitch_outputs(torch.FloatTensorof shape(batch_size, max_text_length + 1, 1), optional) — 音高预测器的输出。 -
energy_outputs(torch.FloatTensorof shape(batch_size, max_text_length + 1, 1), optional) — 能量预测器的输出。
示例:
>>> from transformers import (
... FastSpeech2ConformerTokenizer,
... FastSpeech2ConformerWithHifiGan,
... )
>>> tokenizer = FastSpeech2ConformerTokenizer.from_pretrained("espnet/fastspeech2_conformer")
>>> inputs = tokenizer("some text to convert to speech", return_tensors="pt")
>>> input_ids = inputs["input_ids"]
>>> model = FastSpeech2ConformerWithHifiGan.from_pretrained("espnet/fastspeech2_conformer_with_hifigan")
>>> output_dict = model(input_ids, return_dict=True)
>>> waveform = output_dict["waveform"]
>>> print(waveform.shape)
torch.Size([1, 49664])本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-06-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号