EAGER:将行为和语义协同起来的生成式推荐方法


关注我们,一起学习
标题: EAGER: Two-Stream Generative Recommender with Behavior-Semantic Collaboration 地址:https://arxiv.org/pdf/2406.14017 学校:浙大 会议:KDD 2024
1. 导读
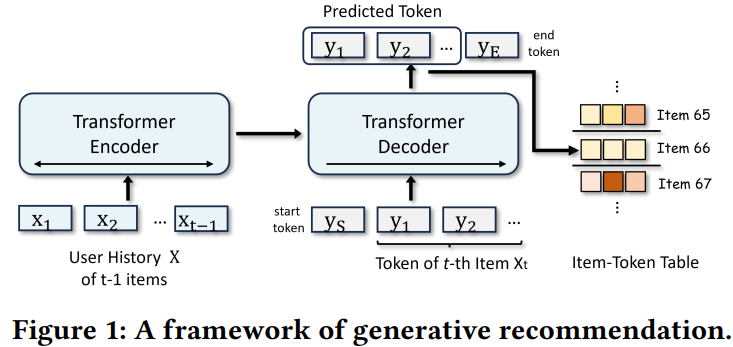
生成式检索用于序列推荐是将候选item检索视为一个自回归序列生成问题。但现有方法只关注item信息的行为或语义方面,忽略了它们的互补性。本文提出一种新的生成式推荐框架EAGER,集成行为和语义信息。
- (1)EAGER是一种双流生成结构,利用共享编码器和两个独立的解码器,以基于置信度的排序策略对行为token和语义token进行解码;
- (2) 构建摘要token的全局对比任务,实现对每种类型的信息的区分性解码;
- (3)语义引导的迁移任务,通过重构和识别两类任务,增强语义信息对行为表征的引导。
2.方法
2.1 模型结构

alt text
- 首先,双流生成式架构对用户交互历史进行建模,并通过编码器获得交互特征。
- 然后,提取行为和语义特征,并利用两个解码器以自回归的方式分别预测它们。- 在全局对比任务中优化摘要token,并以此提升语义引导的迁移任务中的交叉解码器交互。
- 训练后,采用基于置信度的排序策略来合并来自两个不同预测的结果(行为和语义来预测)。
2.2 双流生成式结构
采用transformer构建双流结构来处理行为和语义信息,由share encoder,dual codes和dual decoders组成。
- share encoder比较简单,就是对于交互序列,使用transformer进行编码
- dual codes部分,首先使用两个预训练过的模型来分别提取行为emb和语义emb。行为提取模型可以采用类似DIN的模型,只需使用ID序列;语义提取模型可以采用Sentence-T5来提取模态表征。然后使用k-means进行聚类,对于每个聚类再进行聚类不断切分直到每个聚类中只包含一个样本,比如下图中应该是做了三次递归,这样就可以得到对应的编码了,比如足球就是(973,733)(这里笔者式这么理解的,如果不对之处,还望指正)

- dual decoders部分为了适应两个不同的代码,使用两个独立的解码器来解码并生成它们中每一个的预测。训练时,我们在代码Y的开头添加一个开始标记得到编码器的输入为,并构建交叉熵损失。总损失包含语义和行为两部分
2.3 全局对比任务
为了使每个解码器具有足够的判别能力,本节设计了一个带有摘要token的全局对比任务来提取全局知识。
对于每个解码器的输入,考虑自回归生成的从左到右的顺序,并在序列的末尾插入可学习的标记,输入变为。这种设计鼓励代码中的前一个token学习更全面的知识,使最后的token能够进行总结。
为了使摘要token捕获全局信息,采用对比学习从预训练的编码器中蒸馏item emb 和。这里只考虑正样本的对比度量,而不是常用的Info-NCE。损失函数为下式,F是度量函数,如smooth L1,采用度量函数对解码后的和原始编码得到的emb进行对比。(这里采用的方式和SimSiam这篇文章类似,那时候也可以试试用jepa的自监督方式,即预测mask部分)
ps:smooth L1的计算方式为下式,和其他损失的差异可以参考此文https://blog.csdn.net/c2250645962/article/details/106023381
2.4 语义引导的迁移任务
本节构建了一个独立的双向Transformer解码器作为辅助模块利用语义知识来指导行为学习,而不是完全独立的解码。在行为code的开头添加一个标记,得到。然后,语义摘要token的emb输入到cross attention,使得解码器中的每个行为token关注语义的全局特征。输出特征表示为。基于此完成两个任务:重构和识别。
- 通过语义全局特征重构mask掉的行为code,使每个行为标记都能从语义中受益。对于重构训练,随机屏蔽行为code中m%的token,表示为。然后,获得相应的输出特征,然后构建重构损失函数:
- 同时,构建二元分类器来判断行为code与语义全局特征是相关的还是不相关的。对于识别训练,通过用采样的不相关token随机替换行为code中的m%的token来构建负样本。对cls的emb进行分类。损失函数即采用交叉熵损失函数。
2.5 推理
通过语义和行为可以得到对应的输出,首先采用beam search分别从两个输出中得到top-k个预测。然后,对于2*k个预测得到的代code,计算code上的对数概率作为每个预测的置信度得分,这与语言模型中使用的困惑相似,值越低表示置信度越高。最后,根据这些预测的置信度得分对其进行排序。
3 实验

消融实验和一些度量损失的验证


本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-06-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号