多元回归:残差分析与异常值诊断


基础分析数据为27位糖尿病者的 血清总胆固醇(X1)、甘油(X2)、空腹胰岛素(X3)、糖化血红蛋白(X4)、空腹血糖(Y)的测量值。我们可以使用R语言建立 空腹血糖与其他四个变量的多元回归方程,从中学习如何分析残差和异常值诊断。
一,建立多元回归模型
使用R语言中的LM方法及“一切子集回归方法”来逐步回归,可以得到 :y ~ x2 + x3 + x4 是 AIC=40.34 最小,在R中我们常有的残差检验方法有:普通残差、标准化残差、学生化残差。
> library(readxl)
> lm.xuetang<-lm(y~x1+x2+x3+x4,data=ex2_1)
> lm.step<-step(lm.xuetang,direction = "both")
二,残差检验
分别使用普通残差、标准残差 检验了 lm.xuetang、lm.step 模型,绘制了两个残差图,从两张图中可以看出只有一个点落在了残差的[-2,2]的区间之外,并小于3,可以判断是一个可疑点(异常点需要大于3)。同样可以看出残差的分布随机分布在0点上,没有随着预测值增大而增大的趋势,具有同方差性的可能性更大。
> y.res<-residuals(lm.xuetang)
> y.rst<-rstandard(lm.step)
> y.fit<-predict(lm.step)
> plot(y.res~y.fit)
> plot(y.rst~y.fit)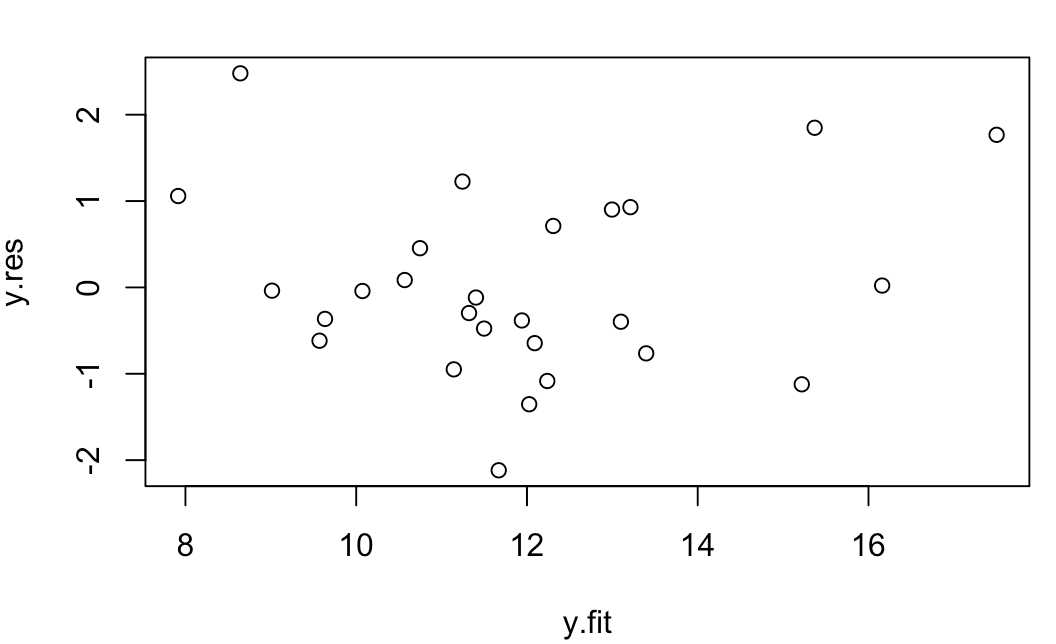
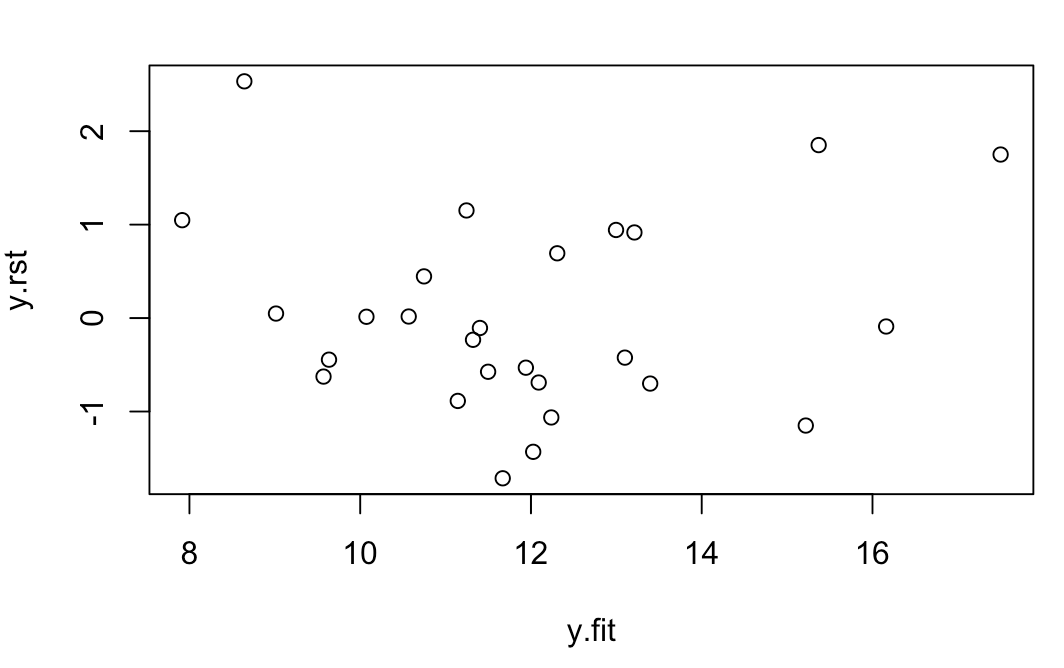
三,强影响点的判断
可疑点/异常点能不能剔除,不能一概而论,需要进一步评估数据点的对模型的影响大小,强影响点不能直接剔除,需要尝试其他模型进行模拟训练,从而找到最优的模型。
我们对逐步回归模型进行了诊断,除了点26、6、13 这三个观测值,其余点的残差—拟合图基本呈现随机分布;整体Q-Q图与直线拟合较好,表面残差服从正态分布;大小-位置图和残差-杠杆图 可以看出 大部分点离中不远,点26、6、25 可能是异常值和强影响点。
> par(mfrow=c(2,2))
> plot(lm.step)
> influence.measures(lm.step)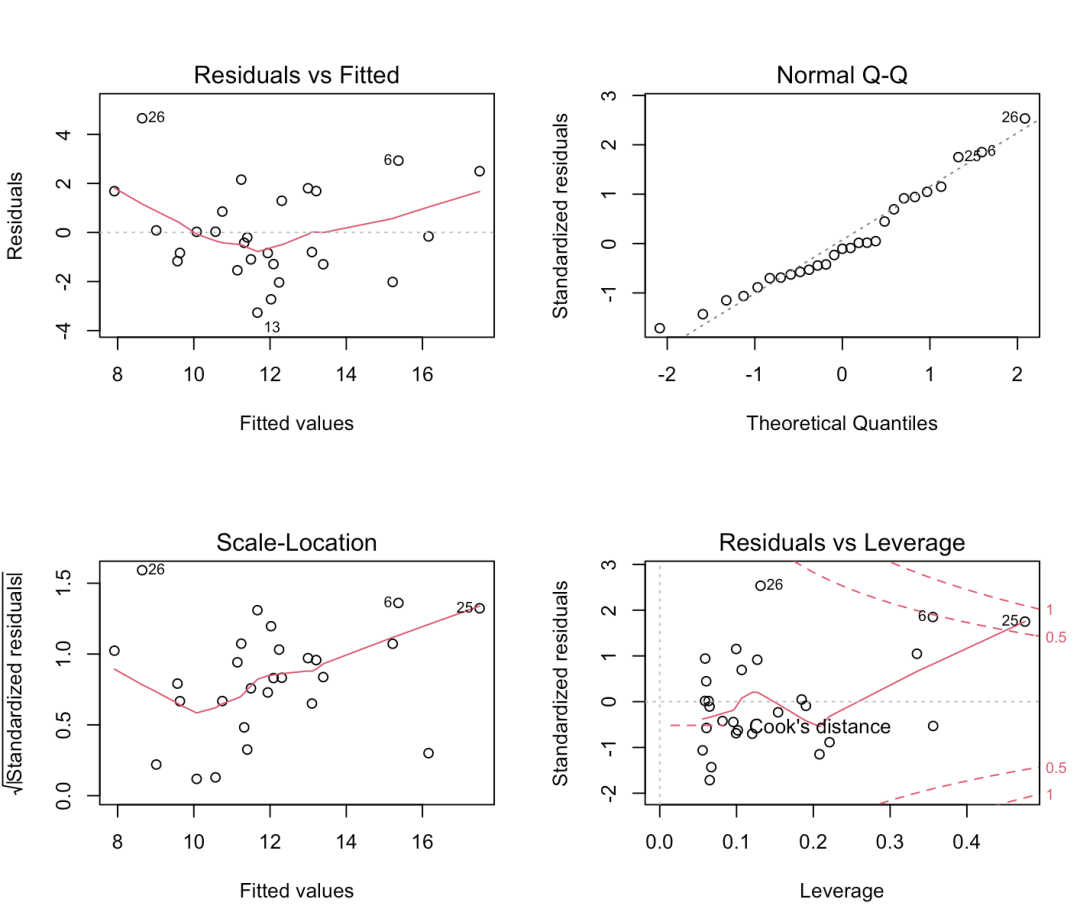
通过influence.measures(lm.step)方法给出了统计变量:DEBETAS、DFFITS、协方差比、库克距离和帽子阵的值,可以看出*对应的点:6、7、25、26 被诊断为强影响点。不能简单的剔除它们。

本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-07-14,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号