【赵渝强老师】Spark SQL的数据模型:DataFrame
原创
【赵渝强老师】Spark SQL的数据模型:DataFrame
原创
赵渝强老师
发布于 2024-08-15 10:02:41
发布于 2024-08-15 10:02:41

通过SQL语句处理数据的前提是需要创建一张表,在Spark SQL中表被定义DataFrame,它由两部分组成:表结构的Schema和数据集合RDD,下图说明了DataFrame的组成。
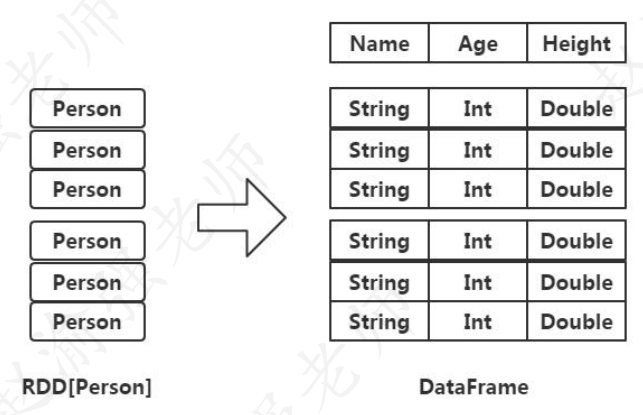
从图中可以看出RDD是一个Java对象的数据集合,而DataFrame增加了Schema的结构信息。因此可以把DataFrame看成是一张表,而DataFrame的表现形式也可以看成是RDD。DataFrame除了具有RDD的特性以外,还提供了更加丰富的算子,并且还提升执行效率、减少数据读取以及执行计划的优化。
视频讲解如下:
创建DataFrame主要可以通过三种不同的方式来进行创建,这里还是以的员工数据的csv文件为例。文件内容如下:
7369,SMITH,CLERK,7902,1980/12/17,800,0,20
7499,ALLEN,SALESMAN,7698,1981/2/20,1600,300,30
7521,WARD,SALESMAN,7698,1981/2/22,1250,500,30
7566,JONES,MANAGER,7839,1981/4/2,2975,0,20
7654,MARTIN,SALESMAN,7698,1981/9/28,1250,1400,30
7698,BLAKE,MANAGER,7839,1981/5/1,2850,0,30
7782,CLARK,MANAGER,7839,1981/6/9,2450,0,10
7788,SCOTT,ANALYST,7566,1987/4/19,3000,0,20
7839,KING,PRESIDENT,-1,1981/11/17,5000,0,10
7844,TURNER,SALESMAN,7698,1981/9/8,1500,0,30
7876,ADAMS,CLERK,7788,1987/5/23,1100,0,20
7900,JAMES,CLERK,7698,1981/12/3,950,0,30
7902,FORD,ANALYST,7566,1981/12/3,3000,0,20
7934,MILLER,CLERK,7782,1982/1/23,1300,0,10下面分别举例进行说明如何使用spark-shell在Spark SQL中创建DataFrame。
一、使用case class定义DataFrame表结构
Scala中提供了一种特殊的类,用case class进行声明,中文也可以称作“样本类”。样本类是一种特殊的类,经过优化以用于模式匹配。样本类类似于常规类,带有一个case 修饰符的类,在构建不可变类时,样本类非常有用,特别是在并发性和数据传输对象的上下文中。在Spark SQL中也可以使用样本类来创建DataFrame的表结构。
(1)定义员工表的结构Schema。
scala> case class Emp(empno:Int,ename:String,job:String,mgr:Int,hiredate:String,sal:Int,comm:Int,deptno:Int)(2)将员工数据读入RDD。
scala> val rdd1 = sc.textFile("/scott/emp.csv").map(_.split(","))(3)关联RDD和Schema。
scala> val emp = rdd1.map(x=>Emp(x(0).toInt,x(1),x(2),x(3).toInt,x(4),x(5).toInt,x(6).toInt,x(7).toInt))(4)生成DataFrame。
scala> val df = emp.toDF(5)查询员工表中的数据,结果如下图所示。
scala> df.show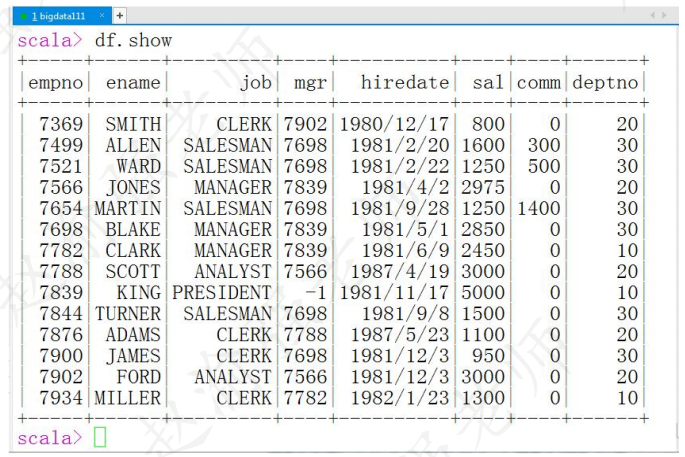
二、使用StructType定义DataFrame表结构
Spark 提供了StructType用于定义结构化的数据类型,类似于关系型数据库中的表结构。通过定义StructType,可以指定数据中每个字段的名称和数据类型,从而更好地组织和处理数据。
(1)导入需要的类型.
scala> import org.apache.spark.sql.types._
scala> import org.apache.spark.sql.Row(2)定义表结构。
scala> val myschema = StructType(
List(StructField("empno",DataTypes.IntegerType),
StructField("ename",DataTypes.StringType),
StructField("job",DataTypes.StringType),
StructField("mgr", DataTypes.IntegerType),
StructField("hiredate", DataTypes.StringType),
StructField("sal", DataTypes.IntegerType),
StructField("comm",DataTypes.IntegerType),
StructField("deptno", DataTypes.IntegerType)))(3)将数据读入RDD。
scala> val rdd2 = sc.textFile("/scott/emp.csv").map(_.split(","))(4)将RDD中的数据映射成Row对象。
scala> val rowRDD = rdd2.map(x=>Row(x(0).toInt,x(1),x(2),x(3).toInt,x(4),x(5).toInt,x(6).toInt,x(7).toInt))(5)创建DataFrame。
scala> val df = spark.createDataFrame(rowRDD,myschema)三、直接加载带格式的数据文件
Spark提供了结构化的示例数据文件,利用这些结构化的数据文件可以直接创建DataFrame,这些文件位于Spark安装目录下的/examples/src/main/resources中。下面是提供的people.json文件中的数据内容。
{"name":"Michael"}
{"name":"Andy", "age":30}
{"name":"Justin", "age":19}由于数据源文件本身就具有格式,因此可以直接创建DataFrame。下面是具体的步骤。
(1)为了便于操作,将people.json文件复制到用户的HOME目录下
cp people.json /root(2)直接创建DataFrame。这里加载的文件在本地目录,也可以是HDFS。
scala> val people = spark.read.json("file:///root/people.json")(3)执行一个简单的查询,如下图所示。
scala> people.show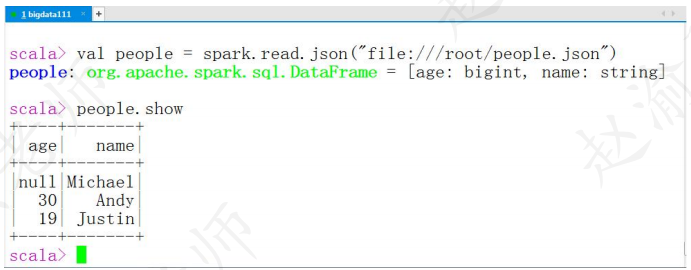
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号