AI论文速读 | 立场观点:长程时间序列预测中没有冠军

AI论文速读 | 立场观点:长程时间序列预测中没有冠军

时空探索之旅
发布于 2025-03-04 21:49:23
发布于 2025-03-04 21:49:23
论文标题:Position: There are no Champions in Long-Term Time Series Forecasting
作者: Lorenzo Brigato, Rafael Morand, Knut Strømmen, Maria Panagiotou, Markus Schmidt, Stavroula Mougiakakou
机构:瑞士伯尔尼大学(UniBe)
论文链接:https://arxiv.org/abs/2502.14045
Cool Paper:https://papers.cool/arxiv/2502.14045
TL;DR:这篇论文认为长程时间序列预测(LTSF)领域没有一致的“冠军”模型。通过对14个数据集和超过3500个模型配置的广泛实验,发现没有单一模型在所有情况下持续优于其他模型。论文指出了当前基准测试实践中的问题,并呼吁采用标准化的评估方法。
关键词:长程时间预测,基准测试,标准化评估

点击文末阅读原文跳转本文arXiv链接
摘要
长程时间序列预测的最新进展引入了许多复杂的预测模型,这些模型的表现始终优于以前发布的架构。然而,这种快速发展引发了人们对不一致的基准测试和报告实践的担忧,这可能会削弱这些比较的可靠性。本文的立场强调需要将重点从追求越来越复杂的模型转移到通过严格和标准化的评估方法加强基准测试实践。为了支持主张,首先通过在 14 个数据集上训练 3,500 多个网络,对最流行的基准上表现最佳的模型进行广泛、全面和可重复的评估。然后,通过全面的分析,发现对实验设置或当前评估指标的轻微改变会极大地改变人们普遍认为新发布的结果正在推动最新技术发展的观点。本文研究结果表明,需要严格和标准化的评估方法,以便提供更有根据的主张,包括可重复的超参数设置和统计测试。
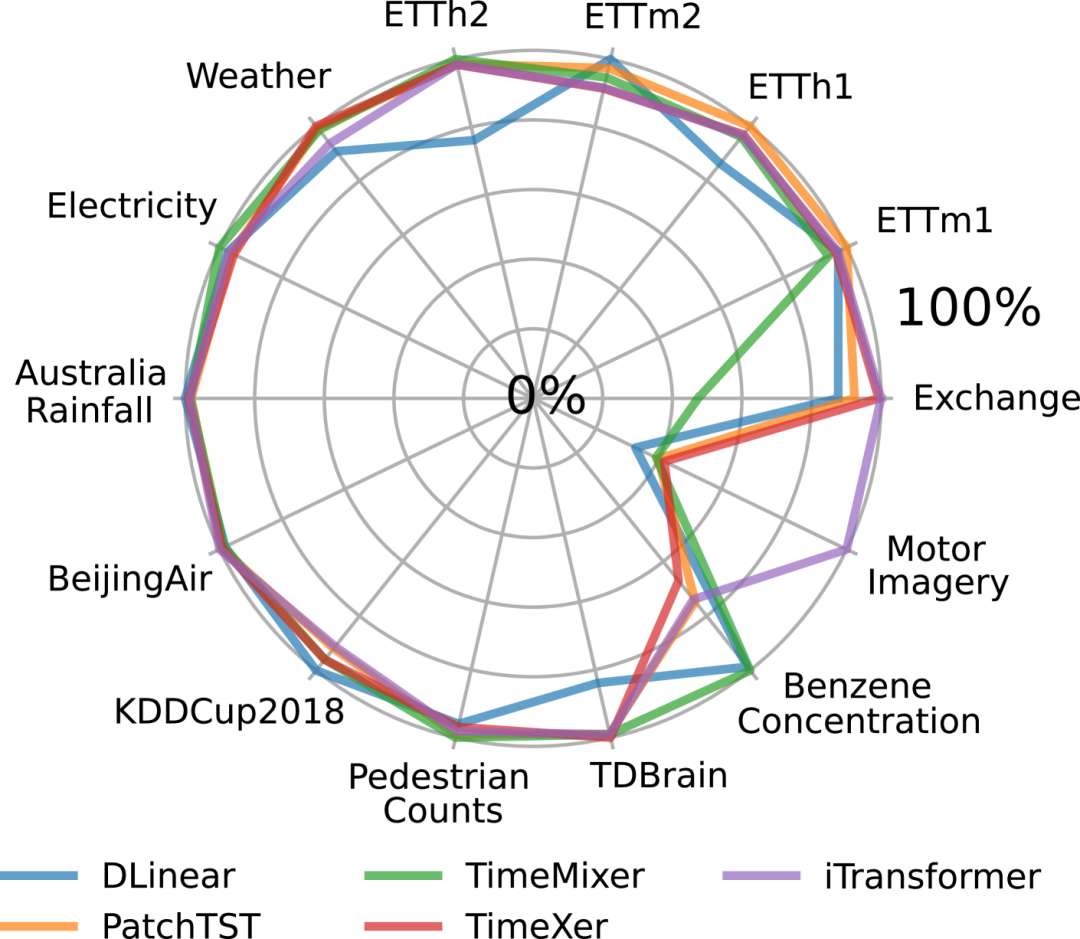
近期SOTA模型性能比较
近期SOTA模型性能比较
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决长程时间序列预测(Long-term Time Series Forecasting, LTSF)领域中关于模型性能评估和比较的问题。具体来说,论文关注以下几个方面:
- 质疑当前的模型性能比较方法:
- 近期的研究中,新提出的模型经常声称在多个基准测试中超越了现有的模型。然而,这些比较可能存在不一致的基准测试和报告实践,这可能削弱了这些比较结果的可靠性。论文指出,这种快速进展可能掩盖了模型性能评估中的问题,例如实验设置的差异、评估指标的偏见以及复现性的挑战。
- 强调标准化评估方法的重要性:
- 论文主张将研究重点从追求越来越复杂的模型转移到增强基准测试实践上,通过严格和标准化的评估方法来提高模型性能比较的可靠性。作者通过广泛的实验验证了这一观点,训练了3500多个网络,覆盖了14个数据集,并发现即使是微小的实验设置变化或评估指标的变化也会显著改变对模型性能的普遍认知。
- 挑战“冠军模型”的存在性:
- 论文通过实验结果表明,没有单一模型能够在所有数据集和预测范围内持续超越其他基线模型。这一发现直接挑战了新架构在所有领域中一致超越竞争模型的普遍说法。论文还提供了可能的原因,并提出了减少重复这种过度声明的可能性的建议。
- 探讨数据集特征与模型选择的关系:
- 论文还探讨了数据集特征是否可以指导模型选择的问题。作者发现,尽管某些模型在特定数据集上表现更好,但总体上模型性能在不同网络之间相似,这表明需要进一步研究数据集特征与模型性能之间的关系。
- 提出改进的评估方法和模型设计:
- 论文提出了一种改进的模型设计(iPatch),并展示了如何通过严格的统计测试来支持模型性能的实质性声明。作者还提出了如何通过标准化的评估协议和对基准测试的重视来改进当前的研究实践。
总的来说,论文的核心目标是通过严格的实验和分析,揭示当前LTSF领域中模型性能评估的不足,并提出改进的方法和建议,以推动该领域的健康发展。
Q: 有哪些相关研究?
A: 论文中提及了多个与长程时间序列预测(LTSF)相关的研究工作,这些工作涵盖了从经典的时间序列预测方法到最新的深度学习模型,以及一些特定领域的应用。以下是论文中提到的一些相关研究:
经典方法
- AutoRegressive Integrated Moving Average (ARIMA) :Box和Pierce(1970)的工作,这是一种经典的统计方法,用于时间序列预测。
- Vector Autoregression (VAR) :Toda和Phillips(1993)的工作,用于处理多变量时间序列数据。
- Exponential Smoothing:Hyndman等人(2008)的工作,一种基于指数平滑的时间序列预测方法。
- Spectral Analysis:Koopmans(1995)的工作,通过频谱分析来处理时间序列数据。
机器学习模型
- XGBoost:Chen和Guestrin(2016)的工作,一种基于梯度提升的机器学习模型。
- Random Forest:Breiman(2001)的工作,一种基于决策树的集成学习方法。
- Gradient Boosting Regression Trees:Friedman(2001)的工作,一种梯度提升方法。
- LightGBM:Ke等人(2017)的工作,一种高效的梯度提升决策树模型。
深度学习模型
- Recurrent Neural Networks (RNNs):Hochreiter和Schmidhuber(1997)的工作,特别是长短期记忆网络(LSTM)。
- Transformer架构:在时间序列预测中的应用,例如Informer(Zhou等人,2021)、Pyraformer(Liu等人,2022b)、Autoformer(Wu等人,2021)、FEDformer(Zhou等人,2022b)、Crossformer(Zhang和Yan,2023)和TimesNet(Wu等人,2023)。
- MLP-based模型:如DLinear(Zeng等人,2022)、N-BEATS(Oreshkin等人,2020)和N-Hits(Challu等人,2023)。
大语言模型(LLMs)和基础模型
- PromptCast:Xue和Salim(2023)的工作,将时间序列数据转换为自然语言提示,利用预训练的语言模型进行预测。
- TEST:Sun等人(2023)的工作,通过标记化数据和对齐嵌入空间来适应预训练的LLMs。
- LLM4TS:Chang等人(2023)的工作,通过两阶段微调将LLMs应用于时间序列预测。
- TEMPO:Cao等人(2023)的工作,利用LLMs进行时间序列预测。
- Chronos:Ansari等人(2024)的工作,训练基于Transformer的模型处理离散化的TS数据。
- TimeGPT-1:Garza和Mergenthaler-Canseco(2023)的工作,利用解码器仅Transformer架构进行零样本泛化。
- Lag-LLama:Rasul等人(2023)的工作,利用解码器仅Transformer架构进行零样本泛化。
基准测试和评估方法
- TSLib:Wang等人(2024b)的工作,一个比较12种深度学习模型的基准库。
- BasicTS+:Shao等人(2024)的工作,包含28种预测模型的基准。
- TFB:Qiu等人(2024)的工作,评估22种统计、经典机器学习和深度学习方法的基准。
这些研究为长程时间序列预测领域提供了丰富的背景和方法,论文通过对比和分析这些方法,揭示了当前评估实践中的问题,并提出了改进的建议。
Q: 论文如何解决这个问题?
A: 论文通过以下步骤来解决长程时间序列预测(LTSF)领域中模型性能评估和比较的问题:
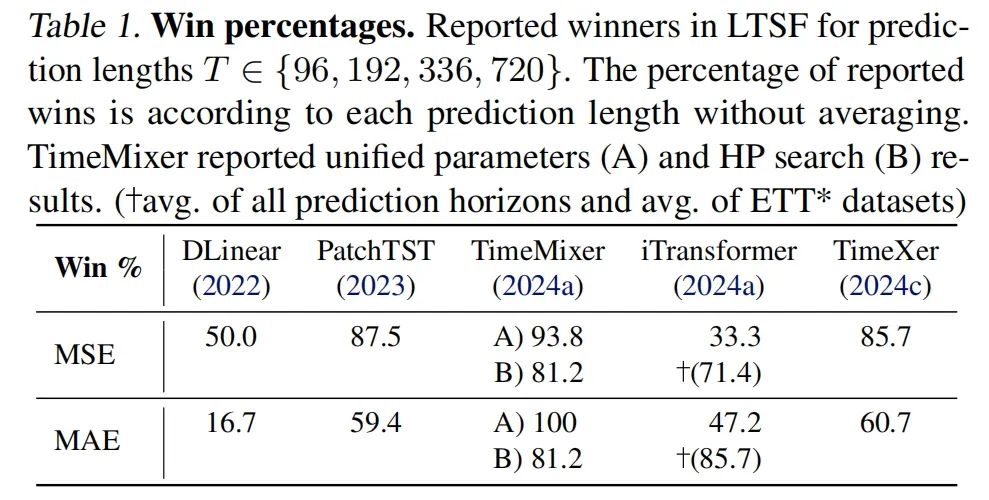
表1-赢得百分比
表1-赢得百分比
1. 广泛且彻底的评估
- 实验设计:作者选择了五个在TSLib基准测试中表现最佳的模型(DLinear、PatchTST、TimeMixer、iTransformer、TimeXer),并在14个不同领域的数据集上进行了广泛的实验。
- 超参数搜索:为了确保公平比较,作者对所有模型进行了广泛的超参数搜索,使用了Optuna框架,优化了输入长度、模型大小、学习率和编码器层数等关键参数。
- 实验规模:总共训练了3500多个网络,覆盖了14个数据集,确保实验结果的可靠性和可重复性。
2. 严格的统计测试
- Friedman测试:用于比较多个模型在多个数据集上的性能,评估是否存在显著的性能差异。
- 符号测试(Sign Test):用于比较两个模型在多个数据集上的性能,评估一个模型是否显著优于另一个模型。
3. 分析实验设置的影响
- 数据集的影响:通过移除特定数据集(如MotorImagery)来评估其对整体性能排名的影响。
- 预测范围的影响:通过移除特定预测范围来评估其对整体性能排名的影响。
- 超参数调整的影响:通过对比有无超参数调整的模型性能,评估超参数调整对模型性能的影响。
- 可视化的影响:通过对比不同尺度的可视化结果,评估可视化方式对性能感知的影响。
4. 提出改进的模型设计
- iPatch模型:作者提出了一个结合iTransformer和PatchTST的混合架构iPatch,通过结构化输入数据并建模变元和时间特定动态,提供了一种层次化的方法来处理多变量时间序列数据。
- 性能验证:通过实验验证iPatch模型在多个数据集上的性能,并使用统计测试来支持其性能提升的实质性声明。
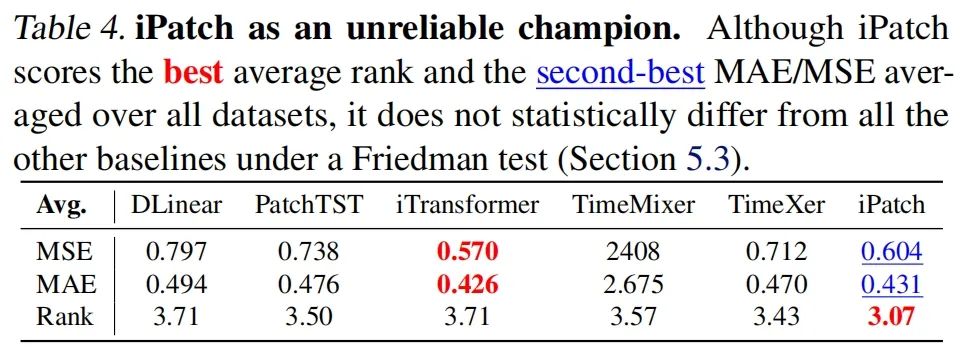
表4-iPatch
表4-iPatch

表5-iPatch优于iTransformer
表5-iPatch优于iTransformer
5. 提出标准化评估协议
- 标准化评估框架:建议采用标准化的评估框架,确保不同研究之间的可比性。
- 透明的实验设置:强调实验设置的透明性,包括超参数搜索、数据预处理和模型训练的具体细节。
- 复现性:提供代码和详细的实验设置,确保其他研究者可以复现结果。
6. 探讨数据集特征与模型选择的关系
- 线性模型与Transformer模型:通过对比线性模型(DLinear)和Transformer模型(PatchTST)在具有清晰和不清晰模式的数据集上的表现,评估模型选择的指导原则。
- 单变量与多变量模型:通过对比单变量模型(PatchTST)和多变量模型(iTransformer)在不同数据集上的表现,评估模型选择的指导原则。
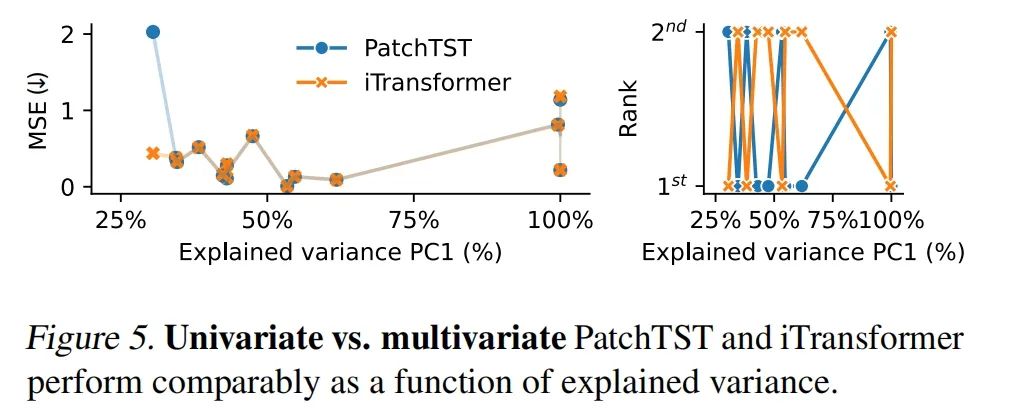
单变量vs多变量
单变量vs多变量
通过这些步骤,论文不仅揭示了当前LTSF领域中模型性能评估的不足,还提出了改进的方法和建议,以推动该领域的健康发展。
Q: 论文做了哪些实验?
A: 论文中进行了广泛的实验来评估和比较长程时间序列预测(LTSF)模型的性能。以下是实验的主要内容和步骤:
1. 实验设计
- 选择模型:作者选择了五个在TSLib基准测试中表现最佳的模型,包括DLinear、PatchTST、TimeMixer、iTransformer和TimeXer。
- 数据集选择:实验涵盖了14个不同领域的数据集,这些数据集在时间点数量、变量数量、采样频率、平稳性、复杂性、趋势、季节性和熵等方面具有显著差异。
- 超参数搜索:为了确保公平比较,作者对所有模型进行了广泛的超参数搜索,优化了输入长度、模型大小、学习率和编码器层数等关键参数。
- 训练和评估:所有模型在每个数据集上都进行了训练和评估,使用了均方误差(MSE)和平均绝对误差(MAE)作为评估指标。每个模型的性能通过三个随机种子的平均值和最小值来报告,以确保结果的稳健性。
2. 实验结果
- 主要结果:实验结果表明,没有单一模型在所有数据集和预测范围内持续超越其他基线模型。
- 平均性能:作者还报告了所有数据集上的平均MSE和MAE,以及每个模型的平均排名。结果表明,所有模型的平均性能非常接近,没有明显的“冠军”模型。
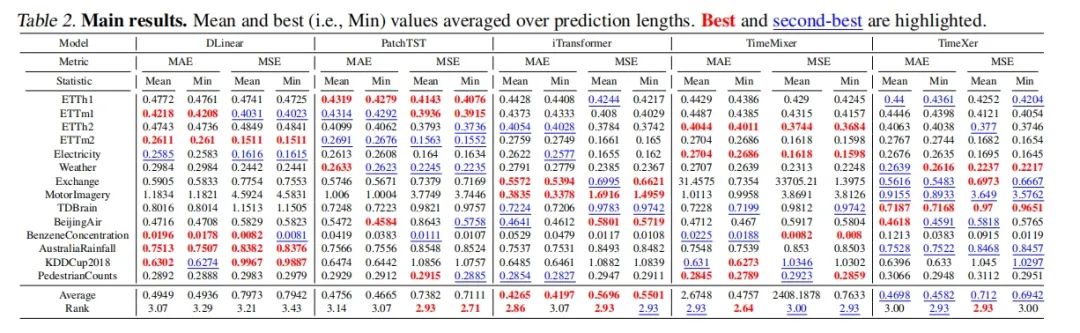
表2-主要实验结果
表2-主要实验结果

表3-超参调整的影响
表3-超参调整的影响
3. 实验分析
- 数据集的影响:通过移除特定数据集(如MotorImagery)来评估其对整体性能排名的影响。结果表明,移除某些数据集可能会显著改变模型的排名。
- 预测范围的影响:通过移除特定预测范围来评估其对整体性能排名的影响。结果表明,移除某些预测范围也可能会显著改变模型的排名。
- 超参数调整的影响:通过对比有无超参数调整的模型性能,评估超参数调整对模型性能的影响。结果表明,超参数调整可以显著提升模型性能。
- 可视化的影响:通过对比不同尺度的可视化结果,评估可视化方式对性能感知的影响。结果表明,不同的可视化方式可能会导致对模型性能的不同感知。
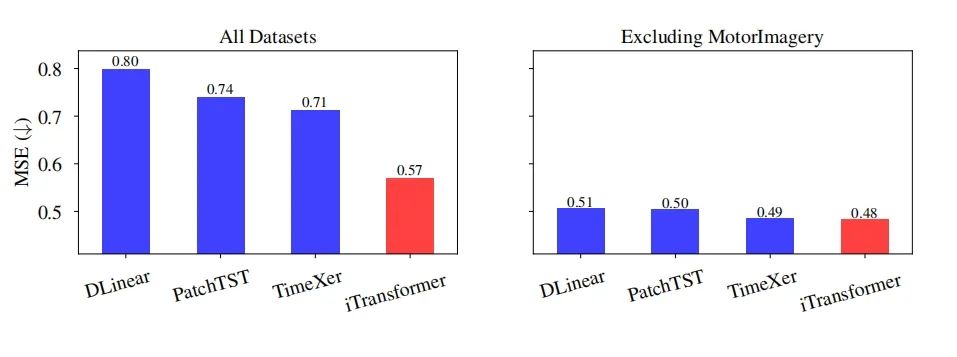
数据集的影响(移除MotorImagery)
数据集的影响(移除MotorImagery)
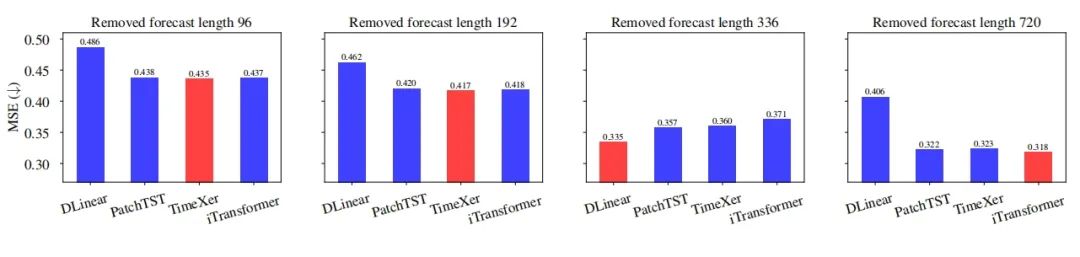
预测范围的影响
预测范围的影响
表3-超参调整的影响
表3-超参调整的影响
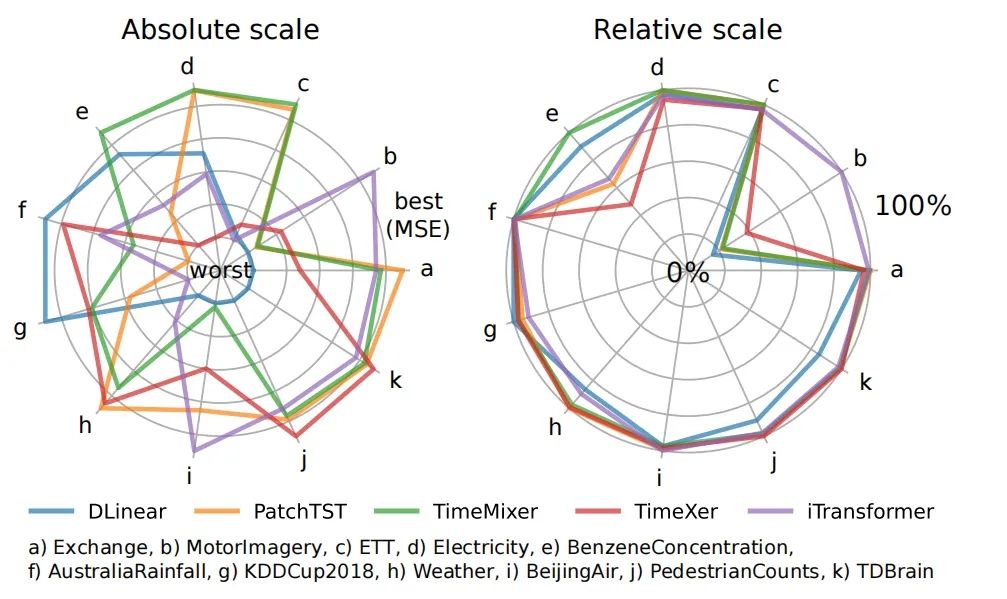
可视化偏差(绝对vs相对)
可视化偏差(绝对vs相对)
4. 统计测试
- Friedman测试:用于比较多个模型在多个数据集上的性能,评估是否存在显著的性能差异。结果表明,没有模型在所有数据集上显著优于其他模型。
- 符号测试(Sign Test):用于比较两个模型在多个数据集上的性能,评估一个模型是否显著优于另一个模型。结果表明,iPatch模型在多个数据集上显著优于iTransformer模型。
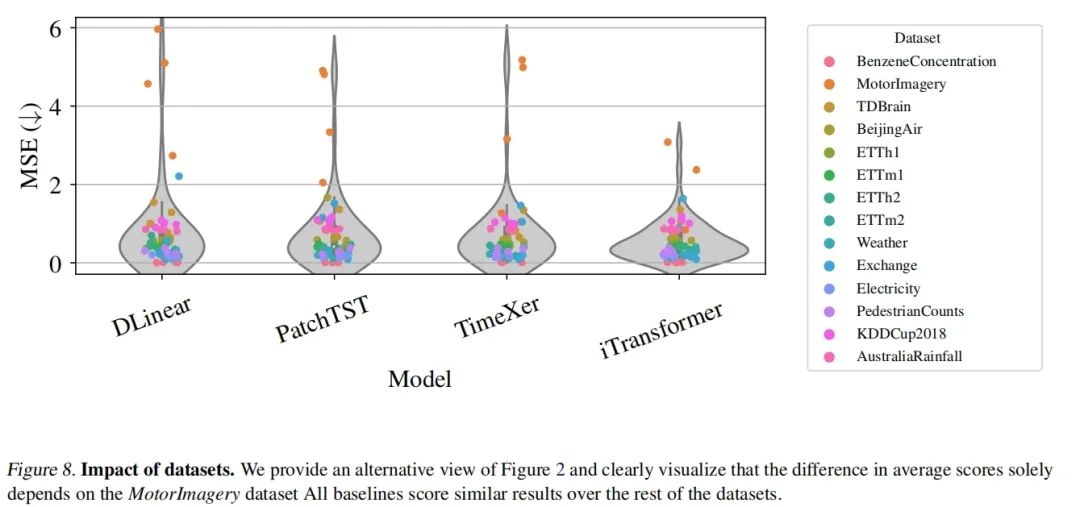
不同数据集的影响
不同数据集的影响
5. 提出改进的模型设计
- iPatch模型:作者提出了一个结合iTransformer和PatchTST的混合架构iPatch,通过结构化输入数据并建模变元和时间特定动态,提供了一种层次化的方法来处理多变量时间序列数据。
- 性能验证:通过实验验证iPatch模型在多个数据集上的性能,并使用统计测试来支持其性能提升的实质性声明。
表5-iPatch优于iTransformer
表5-iPatch优于iTransformer
通过这些实验,作者不仅验证了当前LTSF领域中模型性能评估的不足,还提出了改进的方法和建议,以推动该领域的健康发展。
完整实验结果和附录补充信息
主要包含数据集信息,完整的实验对比结果,本文提出iPatch的完整结果,超参数搜索的灵活性
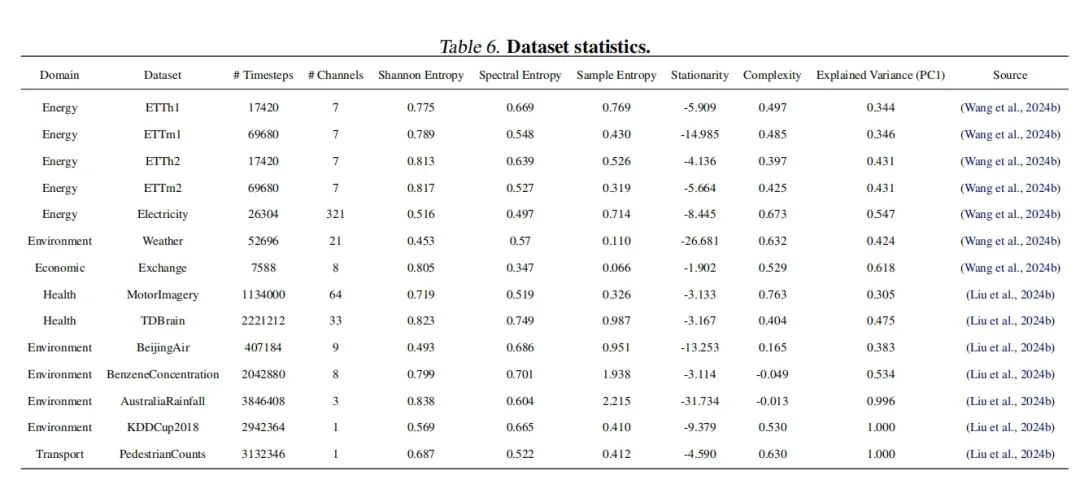
表6-数据集信息
表6-数据集信息
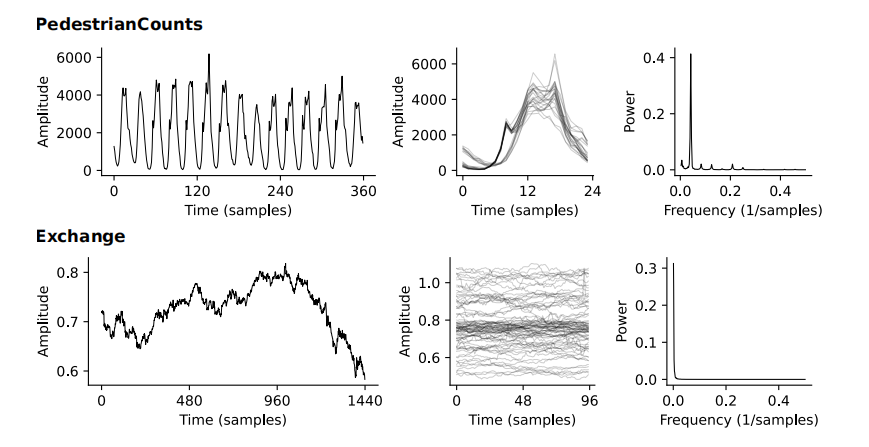
两个数据集中有不同的时间模式
两个数据集中有不同的时间模式

表7-超参数搜索
表7-超参数搜索

表8-Patch长度
表8-Patch长度
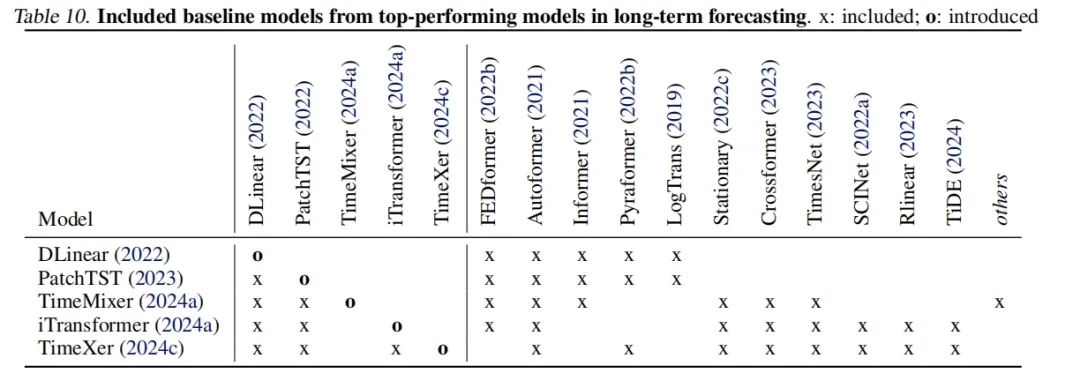
表10-不同最佳性能模型论文中涉及到的baseling包含情况
表10-不同最佳性能模型论文中涉及到的baseling包含情况

表9-结果可靠性
表9-结果可靠性
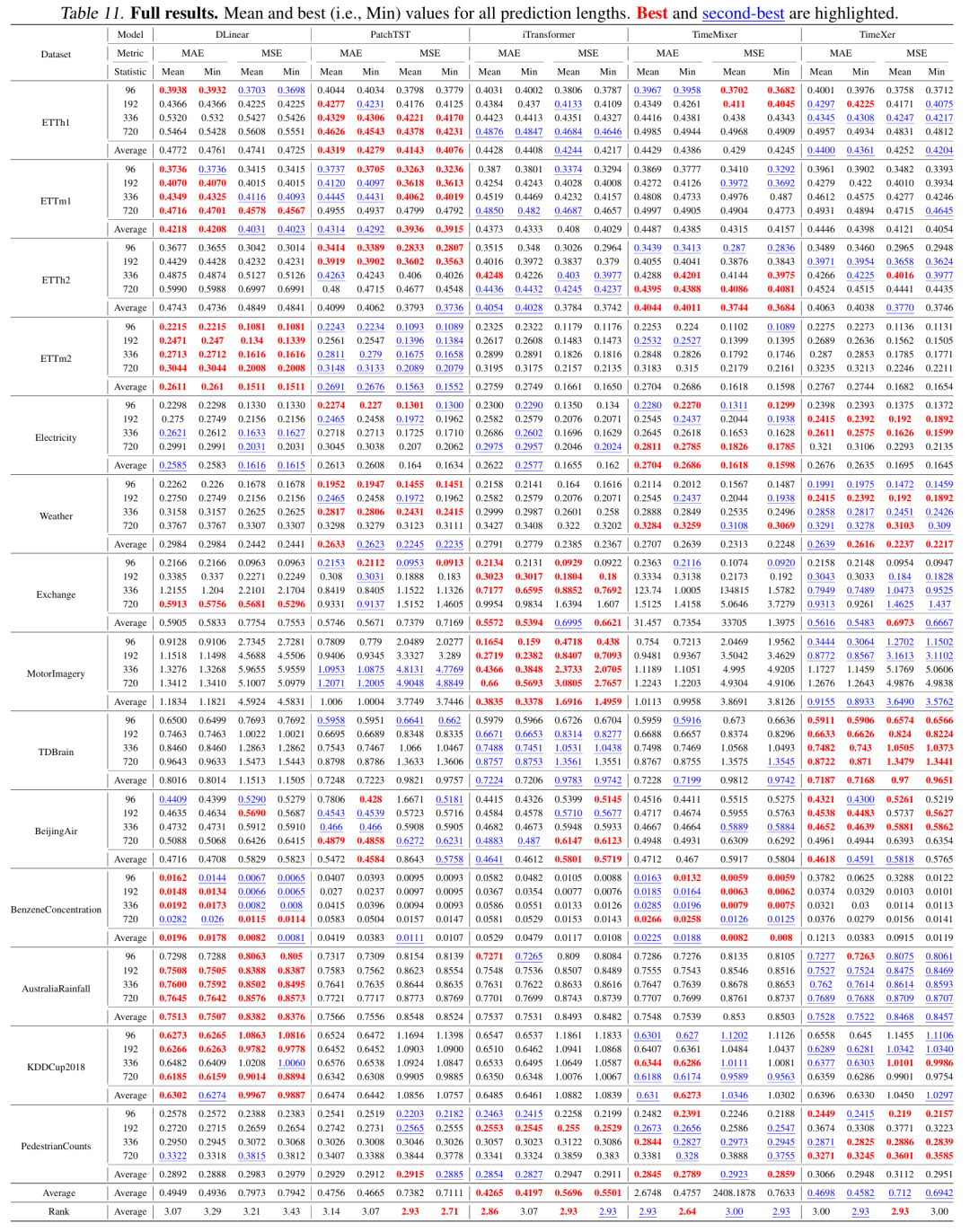
表11-完整实验结果
表11-完整实验结果
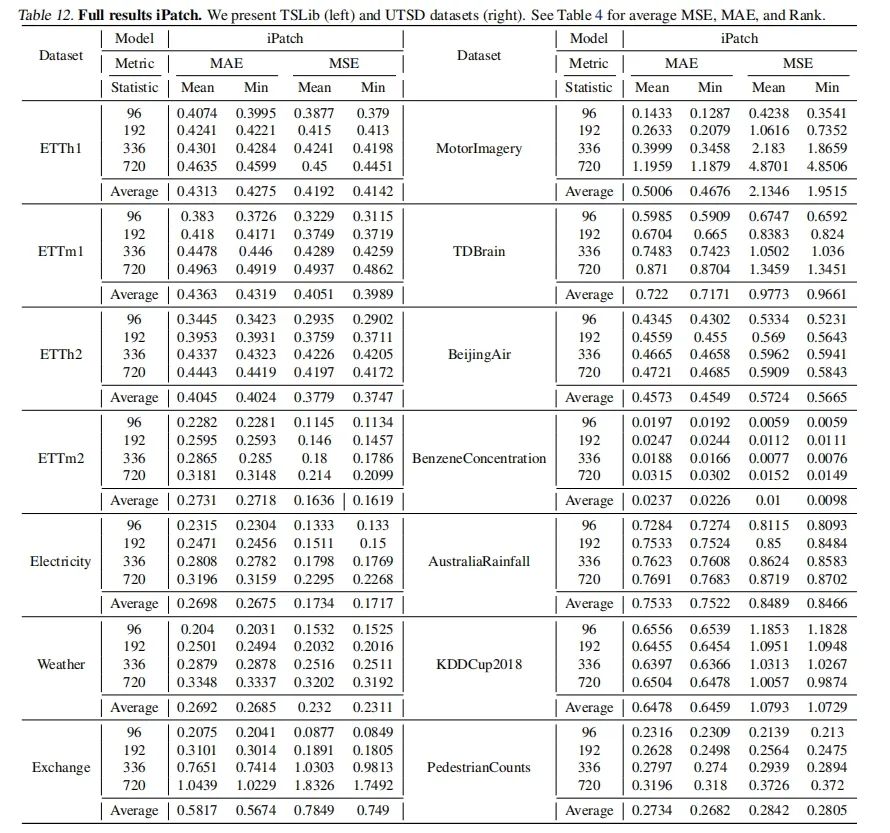
表12-iPatch完整结果
表12-iPatch完整结果
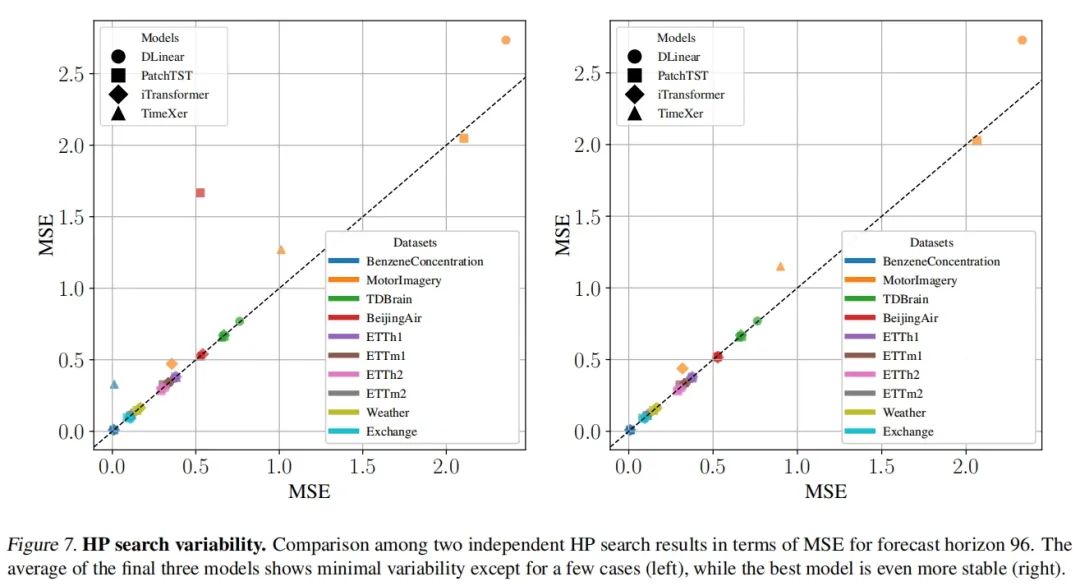
超参数搜索灵活性
超参数搜索灵活性
说明:图7的横轴和纵轴都是MSE(均方误差),用于展示模型在不同超参数搜索(HP search)下的性能稳定性。具体来说,图7展示了两次独立的超参数搜索结果的MSE值,横轴表示第一次搜索的MSE,纵轴表示第二次搜索的MSE。如果一个点接近对角线,说明两次搜索的结果非常接近,表明超参数搜索的稳定性较高。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-03-03,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号