SARChat-2M:首个SAR图像多模态对话数据集,验证VLMs能力,项目即将开源!

SARChat-2M:首个SAR图像多模态对话数据集,验证VLMs能力,项目即将开源!

未来先知
发布于 2025-03-24 13:57:35
发布于 2025-03-24 13:57:35

合成孔径雷达(SAR)作为一种强大的全天候地球观测工具,在军事侦察、海事监控和基础设施监测等领域发挥着关键作用。 尽管视觉语言模型(VLMs)在自然语言处理和图像理解方面取得了显著进展,但由于缺乏领域专业知识,它们在专业领域的应用仍然有限。本文创新性地提出了第一个针对SAR图像的大规模多模态对话数据集,命名为SARChat-2M,该数据集包含约200万对高质量的图像-文本,涵盖了多种场景并具有详细的标注。 这个数据集不仅支持视觉理解和目标检测等关键任务,还具有独特的创新性:本研究开发了SAR领域的视觉-语言数据集和基准,以验证和评估VLMs在SAR图像解释方面的能力,为构建跨各种遥感垂直领域的多模态数据集提供了一个典范框架。 通过在16种主流VLMs上的实验,该数据集的有效性得到了充分验证。 该项目将在https://github.com/JimmyMa99/SARChat上发布。
1. 引言
在人工智能(AI)研究领域,随着技术的不断进步和应用领域的拓展,研究者们对AI的认知和期望也在不断提升。本文旨在对当前AI技术的发展现状、挑战及其在各个领域的应用进行综述,以期为AI领域的进一步研究和发展提供参考。
近年来,深度神经网络,尤其是卷积神经网络和视觉Transformer ,在遥感数据分析领域取得了显著进展,提高了处理效率和解析准确性。然而,现有研究主要集中于视觉特征提取,而缺乏深度语义解析和推理能力(Li等,2024年),这在复杂场景下限制了模型的应用。
随着大语言模型(LLMs)的进步,视觉-语言模型(VLMs)通过整合预训练和指令微调,在多模态任务中展现出了强大的零样本学习和泛化能力(Dai等人,2023年)。这激励了研究行人探索将视觉模型与LLMs进行深度整合。
尽管专为光学遥感图像设计的模型,如RSGPT(胡等,2023年)和GeoChat(库克雷贾等,2024年)已经取得初步成果,但在合成孔径雷达(SAR)应用中却难以表现出色。SAR图像由于其散射成像机制,本质上存在重大的解释挑战,这表现为模糊的目标边缘、分散的斑点以及方向敏感性。同时,现有的SAR数据集主要集中于视觉识别任务(库克雷贾等,2024年;程等,2022年;张等,2023年),导致大规模、高质量图像-文本对齐数据集严重短缺。这两种内在特性和数据限制阻碍了视觉语言模型(VLMs)在SAR领域的进步。
当前的大规模视觉语言模型主要在传统自然图像上进行训练,并未针对合成孔径雷达(SAR)垂直域进行深入微调。尽管这些模型在自然图像方面具有强大的视觉能力,但在SAR图像解释方面仍有很大的提升空间。基于SARDet100K数据集(Dai等人,2024年),该数据集拥有丰富的SAR图像和检测标注,作者构建了SARChat-Bench-2M,这是一个以任务为导向的SAR特定图像-文本对数据集,旨在解决现有VLMs在SAR图像解释能力上的不足。
如图1所示,作者提出了SARChat-2M,这是一个针对SAR图像的大规模多模态对话数据集,并建立了SARChat-Bench,它是SAR领域的一个全面的以任务为导向的多模态基准。SARChat-2M数据集包含大约200万个高质量的SAR图像-文本对,涵盖了海洋、陆地和城市场景,具有细粒度的语义描述和多尺度分辨率(0.3-10米)。该数据集支持主要的视觉语言任务,如图像标题、视觉问答(VQA)、视觉定位和目标检测。为了系统地评估模型在这些领域的性能,作者在SARChat-2M中设计了六个特定的基准任务:分类、细粒度描述、实例计数、空间定位、跨模态识别和指代。为了验证作者数据集和基准的有效性,作者通过微调16个不同参数规模的最新视觉语言模型(VLMs),包括Intern VL2.5、DeepSeekVL、GLM-Edge-V和mPLUG-Owl系列,进行了广泛的实验。通过在SARChat-2M上训练,这些视觉语言模型(VLMs)在SAR解释方面的多任务能力得到了全面提升,这在作者对SARChat-Bench的系统评估中得到了体现。
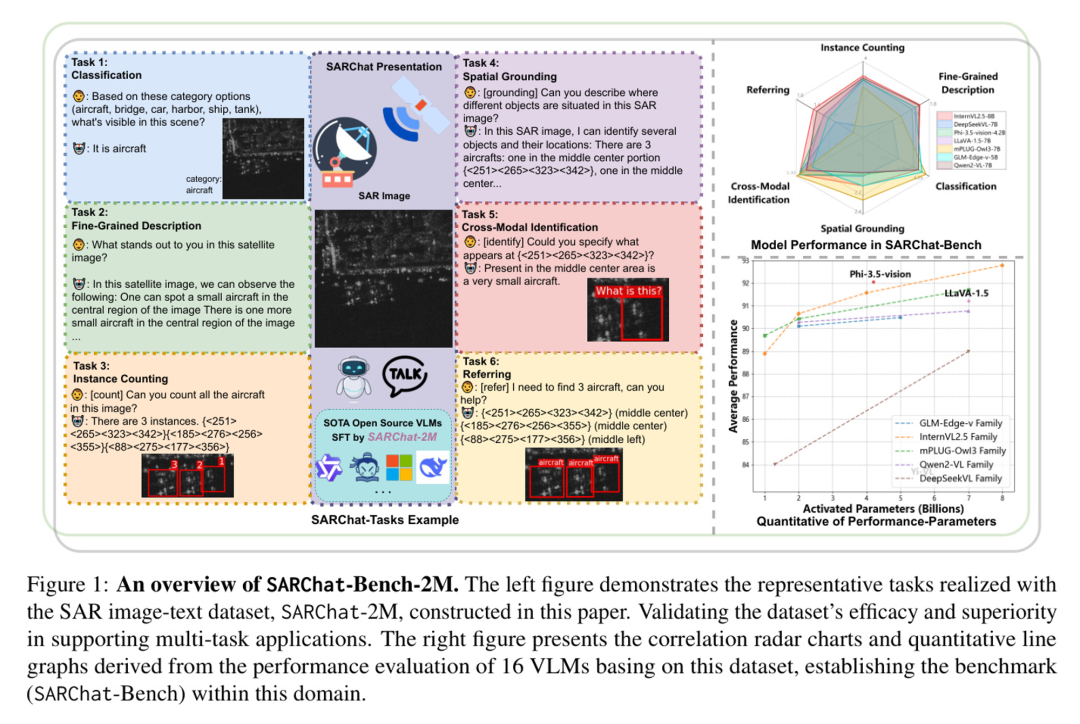
图1:SARchat-Bench-2M的概览。左侧图展示了使用本文构建的SAR图像-文本数据集SARChat-2M实现的代表性任务,验证了该数据集在支持多任务应用中的有效性和优越性。右侧图展示了基于该数据集对16个VLMs(视觉语言模型)性能评估所得出的相关雷达图和定量线图,建立了该领域的基准(SARChat-Bench)。
本文的主要贡献如下:
- sARChat-2M的构建,是目前最大的SAR遥感指令跟随数据集,包含超过200万对高质量的图像-文本对,涉及多场景任务导向对话,缓解了SAR领域视觉语言模型的知识稀缺问题。
- sARchat-Bench的发展,这是一个包含六个核心任务(分类、描述、计数、定位、识别和引用)的全面SAR领域多模态基准,通过多维评估指标使视觉-语言模型的系统性评估成为可能。
- 该研究开创了一种适用于合成孔径雷达(SAR)领域的科研范式,为其他遥感垂直领域的模型构建提供了参考思路。本研究在数据收集、标注以及模型训练和评估所采用的方法和流程具有良好的普遍性和可扩展性。
相关研究工作
2.1 遥感用可变长度模型
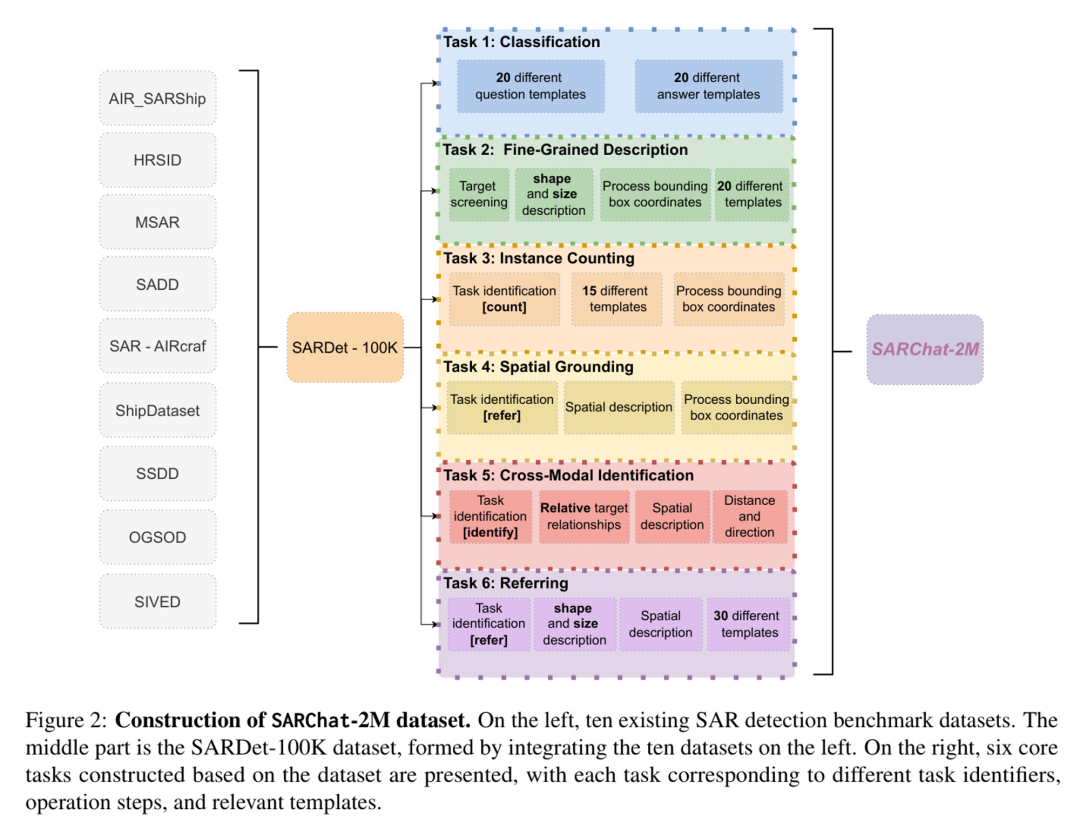
视觉语言模型(VLMs)能够将图像转换为自然语言描述,并解析物体之间的关系,在文本-图像检索、图像标题生成和视觉问答等任务中展现出卓越的性能。近期,类似远程剪辑(RemoteClip,刘等,2024年)的模型被提出。图2展示了sARchat-2M数据集的构建过程。左侧展示了十个现有的SAR检测基准数据集。中间部分是SARDet-100K数据集,它是通过整合左侧的十个数据集形成的。右侧展示了基于该数据集构建的六个核心任务,每个任务对应不同的任务标识符、操作步骤和相关模板。
遥感图像领域已经应用了一些模型,主要集中于跨模态检索和零样本分类。然而,这些模型并未解决图像描述生成和视觉定位等任务。RSGPT模型在遥感图像的文本描述和视觉问答方面取得了成果,但尚未扩展到分类和检测等任务。GeoChat模型在处理高分辨率遥感图像的多任务对话处理方面取得了进展,包括场景分类、视觉问答、多轮对话、视觉定位和参考目标检测。
然而,这些模型,包括GeoChat,主要依赖于光学遥感训练数据,导致在SAR图像特定解释任务中的性能不佳。EarthGPT(张等,2024)通过指令调整将多模态大语言模型的应用扩展到了遥感领域,但其在SAR图像多任务处理方面的性能仍有待提高。与自然图像相比,SAR图像的解释更具挑战性,这对模型的处理能力和适应性提出了更高的要求。
2.2 遥感视觉-语言数据集
遥感数据集对于智能解释模型至关重要。现有的数据集,如UCM Captions(Qu等,2016b)、Sydney Captions(Qu等,2016a)、RSICD(Lu等,2017)、RSITMD 和RSVG 为研究遥感图像与文本之间的相关性提供了初步资源。然而,这些数据集不仅在规模上有限,而且在模态上也有限,仅包含光学图像,没有SAR数据,导致SAR解释能力在很大程度上未被探索。尽管存在像MillionAID(Long等,2021)、FMoW(Christie等,2018)和BigEarthNet(Sumbul等,2019)这样的大规模数据集,但它们缺乏文本-图像对。包含500万图像-文本对的RS5M数据集(Zhang等,2023)仍然局限于光学图像。
涵盖光学、红外和SAR模式的MMRS-1M数据集(Zhang等,2024)中SAR图像-文本数据比例极低。因此,本文构建了SARChat-2M数据集,该数据集专注于SAR图像,包含超过200万图像-文本对,涵盖分类、检测、字幕生成、VQA和视觉基础等任务。
3 数据构建与描述
3.1 数据构建流程
3.1.1 数据集概述
如图2所示,作者提出了SARChat-Bench2M,这是一个用于合成孔径雷达(SAR)图像的多任务基准数据集,包含两百万个多模态对话样本(包括1836912个训练样本和226636个测试样本),以确保模型的鲁棒训练和评估。
该数据集涵盖了六个核心合成孔径雷达(SAR)图像分析任务:分类、细粒度描述、实例计数、空间定位、跨模态识别和指称。基于SARDet-100K数据集(Dai等人,2024年),它整合了来自十个已建立的SAR检测基准的多模态适配和增强语言标注,例如AIR-SARShip(1.0&2.0)(Wang等人,2019a),HRSID ,MSAR ,SADD ,SARAIRcraf(Zhirui等人,2023年),ShipDataset(Wang等人,2019b),SSDD(Zhang等人,2021b),OGSOD(Wang等人,2023年),以及SIVED(Lin等人,2023年)。通过跨模态学习,该数据集在六个语义类别中建立了图像与文本的对应关系,从而产生了200万条精心编写的标注。
本研究设计了首个用于合成孔径雷达(SAR)遥感视觉语言模型的评估框架,满足三个关键要求:多任务监督预训练、SAR与语言领域间的跨域自适应,以及使用标准化指标进行的全面性能评估。
3.1.2 任务定义
基于合成孔径雷达(SAR)图像的特征和变分长度模型(VLM)的核心能力,本研究构建了一个包含六个任务的评价系统。每个任务的定义如下:
分类:分类是SAR图像解释中的一个基本任务,它通过目标类别区分来评估VLM(视觉语言模型)的基本视觉理解能力。
精细描述:精细描述任务侧重于合成孔径雷达图像中的目标类别识别和几何属性分析。除了基本的分类之外,它还评估了可变长度模型(VLM)提取详细形态特征和空间方向的能力,展示了模型在推理特定于合成孔径雷达的空间几何关系方面的熟练度。
(3)实例计数:这项任务需要在提取其空间坐标和姿态信息的同时,对多个合成孔径雷达(SAR)目标进行准确计数。关键挑战在于防止重复计数错误,尤其是在多个目标重叠的复杂场景中。模型必须在处理各种目标密度和背景复杂性的同时,保持稳健的计数性能。
空间定位:通过空间关系解释,能够对合成孔径雷达(SAR)图像中的目标分布进行全面分析,重点关注多个目标之间的位置、距离和方向关系。这一能力在军事侦察场景中尤为重要,精确的空间理解直接影响到作战效能。
跨模态识别:在给定的空间坐标下,VLM推理目标属性并生成全面描述(大小、形态、方向、距离)。该任务考察了模型在合成孔径雷达(SAR)解释中融合和推理多模态信息的能力。
引用:这是一个逆向推理任务。模型需要根据用户指定的目标语义类别在合成孔径雷达(SAR)图像中定位特定实例,并输出抽象的空间方向,这对于实现人机协作中的快速目标检索具有重要意义。
3.2 以任务为导向的数据生成
基于六个任务的特征,本研究设计了一种多模态对话数据生成方案。
(0) 数据集定义
作者的数据集采用了统一的表示方案,贯穿于所有视觉语言任务中,以确保一致性和可解释性。空间信息通过统一使用边界框格式 进行编码,而空间关系则通过标准的 网格系统(包括左上、上、右上、左、中、右、左下、下、右下区域)进行结构化。
这些定义构成了作者任务表述和评估指标的基础框架,从而能够系统地评估视觉语言模型的能力。
(1) 分类任务
分类任务通过20组不同的问答模板对来评估模型的高分辨率合成孔径雷达(SAR)图像识别能力。随机模板组合增加了数据的多样性,并为多目标场景提供了标准化的符号表示。
(2) 精细描述任务
精细描述通过全面的质量控制评估了模型对卫星图像的结构化解析。根据作者的数据集定义,作者过滤掉小于 像素的图像,并排除面积比 的目标(公式1)。移除纵横比超过10:1或坐标超出边界的目标。使用面积比阈值对尺寸描述进行分类(小: ,大: )。为了应对多目标场景,作者构建了40个交互模板。
在本文中, 和 分别表示目标边界框的宽度和高度; 和 分别代表图像的宽度和高度。(3)实例计数任务作为作者视觉推理系统的基础组成部分,该任务专注于评估模型的定量计数能力。作者设计了15个带有[计数]标识符的问题模板来明确任务要求,同时使用统一的边界框格式进行结构化输出表示。该框架通过坐标序列化支持多实例场景的扩展表达式。
(4) 空间定位任务
空间定位评估衡量模型在描述多个目标物体之间结构关系方面的熟练程度。利用作者建立的网格系统,作者通过两种主要机制量化空间关系:相对距离指标(近端阈值定义为 )和方向关系(包括水平、垂直和斜向方向)。该框架包含15个空间关系模板,每个模板前都带有[定位]标识符,符合作者的统一空间表示方案。
跨模态识别
跨模态解析评估采用三层特征描述系统。空间定位利用 网格划分方案进行方向描述。定量分类包括基于面积比阈值的五级大小描述( :非常大; :大; :中等; :小; :非常小),并通过边界框长宽比进行形态分析( :宽体; 长宽比 :约方形; :高体)。
特征整合将空间-尺寸-形态元素综合到全面的目标轮廓中。该系统采用了20个不同的响应模板,并配有专门的[识别]指令标识符和结构化输出模板。
(6)指引用户任务
引用评估了自然语言与图像区域之间的跨模态相关性。 Query 遵循“{类别}在哪里?”的模式,前面带有 标识符。该任务输出精确的边界框坐标和基于网格的方向描述,通过嵌套括号符号遵循作者的统一空间表示框架。
3.3 数据集的定量分析
本研究中的定量分析集中在两个关键维度上:类别分布和物体形态特征。
表1:类别分布统计
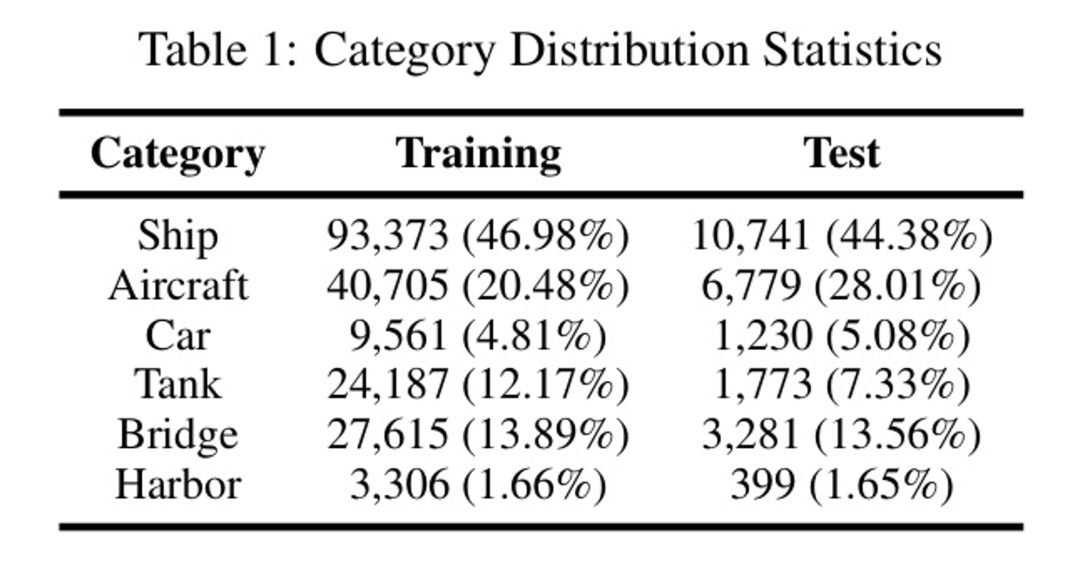
(1)类别分布特征
如表1所示,船舶类别在训练集和测试集中均占主导地位(分别为46.98%和44.38%),而港口类别则不足2%。在飞机类别中观察到显著的分布偏移,测试集比训练集增加了7.53%。如汽车、坦克和桥梁等类别在两个集合中保持适中和稳定的比例。这种不平衡的分布为目标检测任务带来了挑战,同时也为研究处理不平衡数据的解决方案提供了机会。
(2)目标形态分析
本研究通过使用长宽比(AR)对几何特性进行量化。
表2:宽高比分布比较
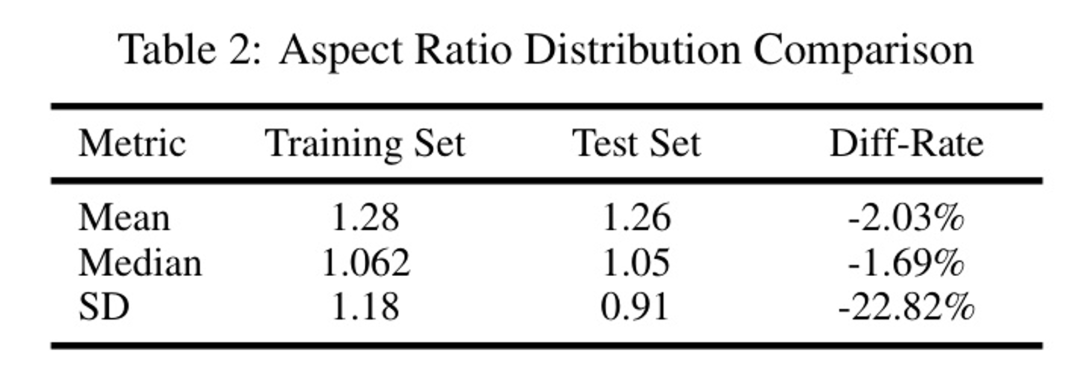
如表2所示,训练集和测试集在集中趋势上的差异很小(均值:-2.03%,中位数:-1.69%)。测试集的标准差降低了22.82%,表明分布更为集中。目标的关键形态分布区间在附录1.2中进行了说明。
该数据集根据长宽比(AR)表现出三种不同的形态类别:宽体(AR≤0.67)、近方形(0.67<AR≤1.5)和细长体(AR>1.5)。详细的分布分析可参见附录1.2。
4 评估方法和设置
本节旨在介绍六个任务的评估方法。这些任务评估了模型在信息处理、目标定位和语义理解方面的核心能力,从而为视觉语言模型的表现提供了多维度的见解。
4.1 评估指标
(1) 准确性:反映模型预测拟合的核心指标,计算公式为:
在本文中, 表示正确的正预测, 代表假正预测,而 指的是假负预测。
(2) 求交并比(IoU):在涉及定位、识别和参考的任务中,IoU是衡量预测框和真实框(bbox)之间重叠度的关键指标。
更高的IoU值表示更大的重叠度和更好的定位性能。本文中所有与IoU相关的计算均采用阈值0.25和0.5进行。
(3)总体评分计算:
在本文中, 代表任务的数量, 表示模型在任务上的准确率,而是所有任务的集合。每个任务上 的详细计算方法可在附录 .3 中找到。
4.2 评估方法
本节详细阐述了六种任务的特定评估方法过程。
实例计数:比较预测值和标签目标的计数,以进行单类评估。
(2) 空间定位:通过基于IoU的边界框匹配和从自然语言描述中提取的抽象位置分析(例如,“顶部”、“底部”)来评估空间准确性。
(3)跨模态识别:计算预测框与真实框之间的交并比(IoU),针对单目标和多目标场景进行计算,以评估跨模态匹配能力。
(4)引用:通过IoU度量标准评估单目标和多目标环境下的引用准确性。
精细描述:将段落预测和真实标签细分为短句,提取类别和位置信息,并对比内容集以进行详细描述评估。
将预测类别与真实类别进行比较,以评估分类准确度。
第五部分:实验与分析
5.1 实施细节
在微调阶段,模型以4个样本大小的批次进行1个周期的训练(有效批次大小为32,梯度累积步骤为4)。本研究在所有线性层上采用LoRA训练方法,其秩为8,alpha值为32。学习率初始化为1e-4,预热比为0.1。所有实验均在2个NVIDIA A100 GPU上使用bfloat16精度和梯度预训练权重进行。
5.2 基准评估
为了验证SARChat-2M数据集的有效性和实用性,本研究提出了SARchat-Bench,这是一系列基于该数据集训练模型的基准实验。如表3所示,包括Qwen2-VL(王等,2024年)、InternVL2.5(陈等,2024年)、DeepSeekVL(卢等,2024年)、Phi-3.5-vision(Abdin等,2024年)、GLM-Edge-V(GLM等,2024年)、mPLUG-Owl3(叶等,2024年)、YiVL(杨等,2024年)和LLaVA-1.5(刘等,2023年)在内的十六种主流视觉语言模型。在不同任务的实验中,每种模型都表现出不同的特性:
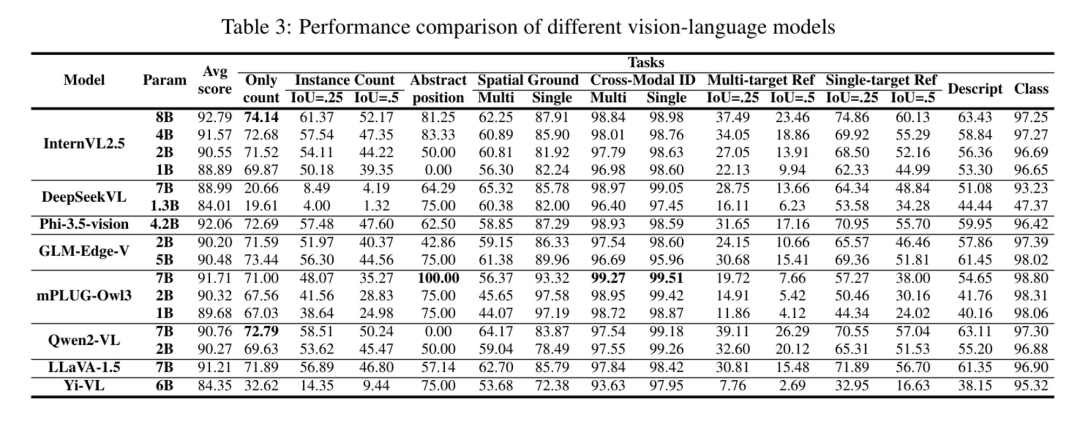
表3:不同视觉-语言模型的性能比较(1)实例计数要求VLMs识别图像中特定目标的数量。两种领先的模型家族达到了最先进的性能:InternVL2.5和Qwen-VL2,分别达到了74.14%和72.79%的准确率。然而,大多数其他模型的准确率都低于60%,这既突显了计数任务的挑战性,也说明了数据集在区分模型能力方面的有效性。
空间定位评估了模型在空间定位方面的能力。对于抽象的位置描述,mPLUG-Owl3-7B达到了100%的准确率,显著优于其他模型。mPLUG-Owl3系列在单目标定位上保持卓越的性能(超过90%),而其他模型的准确率则达到80%-85%。然而,在多目标场景中,大多数模型的准确率下降到大约60%。这些结果表明,准确的多目标空间信息处理仍然是未来模型改进的关键领域。
跨模态识别主要关注模型在视觉信息与其他模态信息之间建立精确联系的能力。在本实验中,主要关注从图像识别到文本描述的过程。实验数据表明,对于单目标和多目标任务,大多数模型的准确率均超过90%。其中,mPLUG-Owl3-7B模型表现最为出色,单目标和多目标任务的准确率分别达到99.27%和99.51%,充分展示了大语言模型在跨模态识别任务中的强大能力。
将基于文本描述在SAR图像中精确定位物体的挑战性模型进行引用。作者的实验揭示了显著的性能差距:在单目标任务上,模型的准确率低于75%,在多目标场景中则低于40%。这些结果突显了当前跨模态对齐的局限性,尤其是在SAR图像中建立精确的文本与物体对应关系方面的局限性。
精细描述要求模型提供图像中目标的详细特征和属性描述。实验表明,模型的准确率在40%至63%之间。其中,参数量较大的模型如Qwen2-VL-7B和InternVL2.5-8B表现突出,能够给出更详细和准确的描述。相比之下,参数量较小的其他模型表现不佳,这表明精细描述任务的准确率对模型参数量非常敏感。
(6) 分类评估了模型根据图像内容进行分类的能力。根据表数据,无论参数大小如何,InternVL2.5、mPLUG-Owl3、Qwen2-VL以及其他几个模型均实现了超过96%的准确率。这些视觉语言模型(VLM)的性能显示出与传统视觉分类模型的竞争力。
图3:SARchat-Bench上的评估示例。VLM的预测结果以绿色/红色表示正确的/错误的描述,其中真实值以绿色显示,预测值以红色框标出。而[Human]、[Bot]和[Check]分别代表用户输入、VLM的响应和标准输出。

5.3 边缘侧模型在合成孔径雷达(SAR)应用中的研究
这项研究训练了多个边缘侧模型(参数量不超过5B),并在SARChat-2M上进行评估,以考察它们的性能。根据表3所示,这些模型在特定任务上的性能存在差异,它们在跨模态识别方面取得了显著的准确率,同时在参考任务方面显示出改进的潜力。这些模型支持特定领域的微调,以实现快速的任务适应。经过优化后,它们能够在卫星或地面边缘设备上高效运行,实现实时合成孔径雷达(SAR)数据处理,同时降低对云基础设施的依赖,并最小化数据传输成本。
5.4 对话可视化
图3展示了SARChat-Bench六个任务中的代表性示例,其中以绿色 Token 了正确答案的 Query -响应对。示例包括成功的分类任务(在多个选项中识别“船只”)和精确的实例计数(在卫星图像中检测到“4个船只实例”)。这些结果说明了该模型在多种SAR图像理解任务中的有效性能。
参考
[1]. SARChat-Bench-2M: A Multi-Task Vision-Language Benchmark for SAR Image Interpretation
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-03-23,如有侵权请联系 cloudcommunity@tencent.com 删除
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号