SAMV算法横空出世,分割、跟踪视频中任意运动目标


论文信息
在计算机视觉领域,视频运动对象分割(MOS)一直是自动驾驶、动作识别等应用的核心技术。然而,传统算法常因光照变化、遮挡、复杂运动等问题表现不佳,而Meta的SAM模型虽在图像分割领域表现优异,却无法区分视频中的运动与静止对象。近日,一项名为SAMV(Segment Any Moving Video)的研究在CVPR 2025上引发轰动,其通过长轨迹运动线索+语义特征融合的创新设计,在多个基准测试中性能**最高提升25%**,彻底改写了视频分割的技术格局!
项目主页:https://motion-seg.github.io/
代码链接:https://github.com/nnanhuang/SegAnyMo
论文链接:https://arxiv.org/pdf/2503.22268
一、为什么需要SAMV?
视频运动分割的核心挑战在于区分真实运动与背景干扰。例如,自动驾驶中需准确识别行人(运动对象)与路牌(静止对象),但传统方法存在以下局限:
- 依赖光流:易受部分运动、模糊或背景动态干扰,导致分割不完整。
- 语义缺失:如SAM虽能分割图像,但无法识别对象类别,且对视频连续帧的跟踪能力不足。
- 过度分割:将单一物体拆分为多个区域,难以满足实际应用需求。
SAMV的突破在于:首次将运动轨迹分析与语义理解深度结合,既能精准捕捉移动目标,又能通过语义标签区分对象类别,解决了传统方法在复杂场景下的“盲区”。
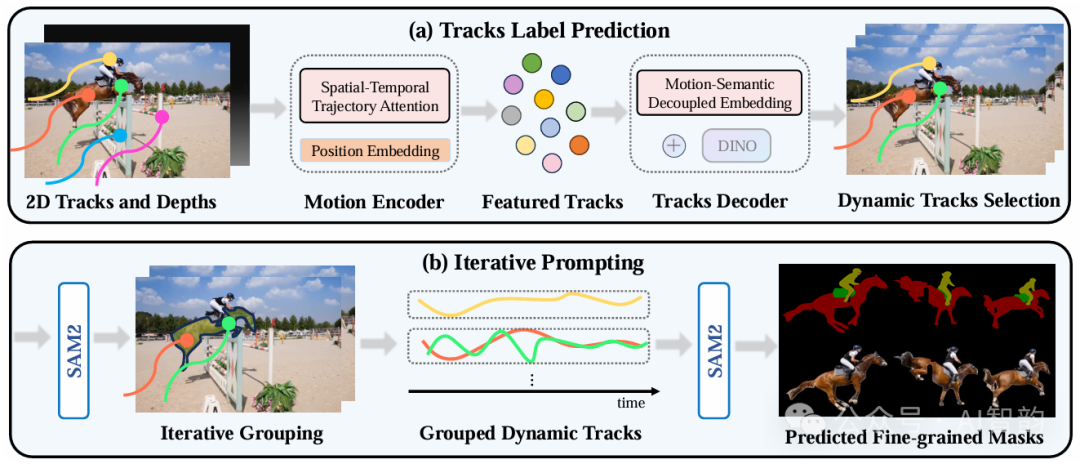
二、SAMV的三大创新设计
- 长距离时空轨迹注意力 通过追踪视频中对象的跨帧运动轨迹,SAMV能有效捕捉快速移动或短暂遮挡的目标。相比仅依赖单帧光流的方法,其长距离跟踪显著提升了分割连续性。
- DINO语义特征融合 引入基于DINO模型的语义特征,结合运动线索,区分动态对象与静态背景。例如,在剧烈相机运动中,SAMV仍能避免将静止路面误判为移动目标。
- 迭代提示策略与SAM2增强 利用SAM2的像素级分割能力,通过动态轨迹提示生成精细掩码,并采用运动-语义解耦嵌入技术,优化分割边界,减少噪声干扰。
在这里插入图片描述
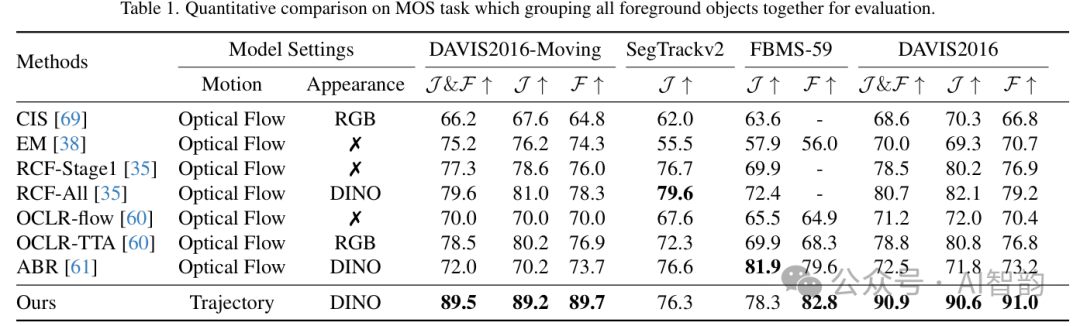
三、性能碾压:指标最高提升25%
在DAVIS、FBMS-59等权威测试集上,SAMV展现了全面领先的优势:
- 精细分割:在遮挡、反射、快速运动场景中,掩码精度接近人工标注(GT)。
- 鲁棒性:面对相机抖动或动态背景(如流水),分割错误率降低10%-25%。
- 多对象处理:支持同时分割数百个运动目标,且为每个实例提供语义标签(如“行人”“车辆”)。
在这里插入图片描述
四、落地场景:从自动驾驶到影视工业
- 自动驾驶:精准识别行人、车辆,避免将静止障碍物误判为威胁。
- 无人机巡检:在密林或建筑群中实时分割移动目标,提升避障能力。
- 视频编辑:一键抠除动态物体(如替换广告牌内容),大幅简化后期流程。
- 智能安防:连续追踪可疑目标,结合行为分析实现主动预警。
五、未来展望
SAMV的提出标志着视频分割技术迈入“运动+语义”双驱时代。未来,结合4D重建与实时边缘计算,该技术有望在机器人导航、元宇宙构建等领域释放更大潜力。研究者表示,下一步将优化算法效率,推动其在低算力设备(如手机、车载芯片)上的部署。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-04-05,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号