基于K3s+Portworx的轻量化云原生边缘基础设施构建


本文将深入解析轻量级Kubernetes与云原生存储的黄金组合如何破解边缘场景下的存储难题。
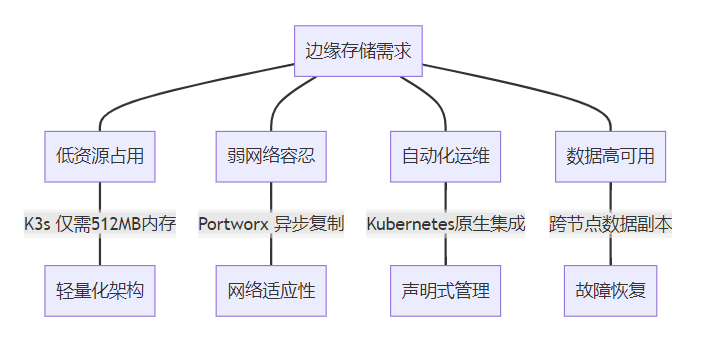
边缘基础设施的独特挑战
边缘计算环境与传统数据中心存在显著差异:
- 资源受限:边缘节点通常仅有2-32GB内存和4核以下CPU
- 网络不可靠:节点间常通过不稳定的4G/5G或卫星链路连接
- 物理环境恶劣:温度波动、电力供应不稳等物理挑战
- 运维困难:分布式节点缺乏现场维护能力
传统云存储方案在边缘场景面临三大致命伤:
- 资源消耗过大:如Ceph需要至少4节点和大量资源
- 网络依赖过强:分布式存储对网络延迟极度敏感
- 运维复杂度高:需要专业存储团队维护
技术选型深度解析
K3s架构精要
K3s通过以下创新实现轻量化:
- 单进程架构:将kubelet、containerd、kube-proxy等组件融合
- SQLite替代etcd:默认使用轻量级数据库(可选etcd)
- 精简组件:移除非核心插件(cloud-provider等)
资源消耗对比(1个worker节点):
组件 | K8s标准版 | K3s | 节省比 |
|---|---|---|---|
内存占用 | 1.2GB | 512MB | 57% |
CPU占用(空闲) | 0.5核 | 0.1核 | 80% |
启动时间 | 45s | 8s | 82% |
Portworx核心优势
Portworx针对边缘场景的关键优化:
- 块设备直通:直接管理裸金属设备,避免文件系统性能损耗
- 跨节点数据同步:基于Gossip协议的状态管理
- 拓扑感知调度:结合K8s调度器实现存储位置感知
数据保护机制:

实战部署手册
环境准备
硬件配置要求:
- 最低配置:2核CPU/2GB内存/20GB存储
- 推荐配置:4核CPU/4GB内存/SSD存储
节点初始化脚本:
#!/bin/bash
# 禁用Swap
sudo swapoff -a
sudo sed -i '/swap/s/^/#/' /etc/fstab
# 加载内核模块
sudo modprobe br_netfilter
sudo modprobe overlay
# 设置内核参数
cat <<EOF | sudo tee /etc/sysctl.d/k3s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
EOF
sudo sysctl --systemK3s集群部署
单线部署命令(支持离线安装):
# 主节点
curl -sfL https://get.k3s.io | INSTALL_K3S_VERSION=v1.26.4+k3s1 \
INSTALL_K3S_EXEC="--disable traefik --disable local-storage" sh -
# 获取节点token
sudo cat /var/lib/rancher/k3s/server/node-token
# Worker节点加入
curl -sfL https://get.k3s.io | K3S_URL=https://<MASTER_IP>:6443 \
K3S_TOKEN=<NODE_TOKEN> sh -验证集群状态:
$ kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP
edge-01 Ready master 5m v1.26.4+k3s1 192.168.1.10
edge-02 Ready worker 3m v1.26.4+k3s1 192.168.1.11Portworx集成指南
裸设备准备:
# 查看可用块设备
lsblk -o NAME,SIZE,TYPE,MOUNTPOINT
# 格式化设备(示例:/dev/sdb)
sudo parted /dev/sdb mklabel gpt
sudo parted -a opt /dev/sdb mkpart primary ext4 0% 100%
sudo mkfs.ext4 /dev/sdb1Operator方式安装:
helm repo add portworx https://charts.portworx.io
helm install portworx portworx/portworx \
--version 2.13.2 \
--set clusterName=px-edge-cluster \
--set storage.storageDevices={"type=scsi,device=/dev/sdb1"} \
--set dataInterface=enp0s8 \
--set secrets.kubernetesSecret=px-secrets \
--namespace kube-system关键配置参数说明:
# values.yaml 自定义配置
stork:
enabled: true # 启用存储调度器
autopilot:
enabled: true # 启用自动化运维
customStorageClass: true
storageClasses:
- name: px-repl2-sc
default: true
reclaimPolicy: Retain
parameters:
repl: "2" # 设置2副本
io_profile: "db" # 数据库优化模式存储高级特性实战
拓扑感知数据放置
创建StorageClass定义:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: px-topology-sc
provisioner: pxd.portworx.com
parameters:
repl: "2"
priority_io: "high"
label: "region=zoneA" # 节点标签选择器部署有状态应用:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: edge-db
spec:
serviceName: "edge-mysql"
replicas: 3
selector:
matchLabels:
app: mysql
template:
metadata:
labels:
app: mysql
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: region
operator: In
values: [zoneA]
containers:
- name: mysql
image: mysql:8.0
volumeMounts:
- name: db-data
mountPath: /var/lib/mysql
volumeClaimTemplates:
- metadata:
name: db-data
spec:
storageClassName: px-topology-sc
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 20Gi数据保护实战
创建定时快照策略:
apiVersion: stork.libopenstorage.org/v1alpha1
kind: SchedulePolicy
metadata:
name: daily-snapshot
policy:
interval:
intervalMinutes: 1440 # 24小时
daily:
time: "02:00" # 凌晨2点执行应用快照策略:
# 创建VolumeSnapshot对象
pxctl volume snapshot create --label app=mysql daily-snap-001灾难恢复演练:
# 1. 模拟节点故障
kubectl drain edge-node-02 --ignore-daemonsets --delete-emptydir-data
# 2. 观察自动恢复过程
watch pxctl volume list
# 输出显示副本重建
ID NAME STATUS ...
678c2e8 pvc-5f6d3e21-8d24-4b7d up ...性能优化策略
存储调优参数
关键I/O参数调整:
# 查看当前配置
pxctl service settings show
# 优化SSD性能
pxctl service settings update --storage_optimize_ssd true
# 调整日志级别降低CPU消耗
pxctl service logs --level error资源限制配置:
# Portworx DaemonSet资源限制
resources:
limits:
cpu: "2"
memory: 4Gi
requests:
cpu: "0.5"
memory: 1Gi网络优化方案
跨节点流量压缩:
pxctl service settings update --network_compression true带宽限制策略:
# 设置节点间复制带宽上限
pxctl cluster options update --maximum-bandwidth 50Mbps监控与排障体系
轻量监控方案
部署Prometheus监控栈:
helm install prometheus prometheus-community/kube-prometheus-stack \
--set prometheus.prometheusSpec.resources.requests.memory=512Mi \
--set grafana.resources.requests.cpu=0.1 \
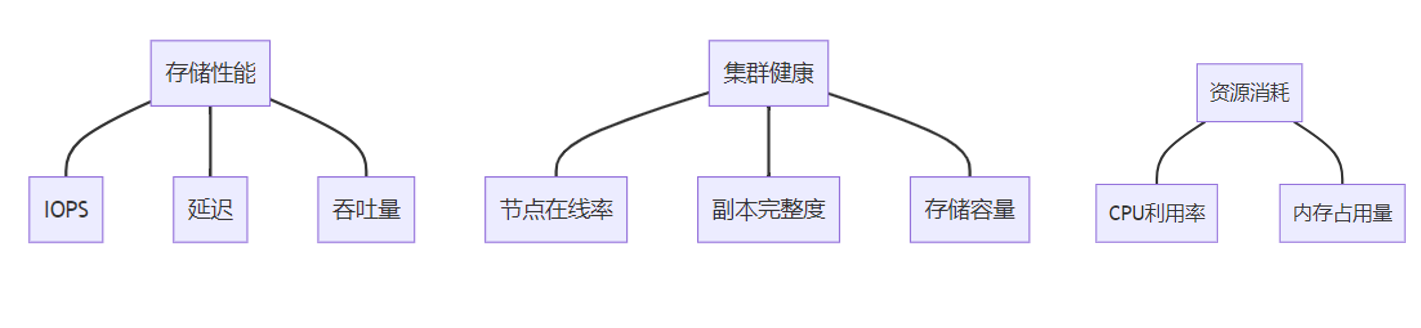
--namespace monitoring关键监控指标:
故障诊断树
graph TD
A[存储卷无法挂载] --> B{查看事件日志}
B -->|PVC Pending| C[检查StorageClass]
B -->|Mount Failed| D[检查节点存储状态]
C --> E[kubectl describe sc]
D --> F[pxctl status]
F -->|设备异常| G[重新初始化设备]
F -->|服务停止| H[重启Portworx服务]
G --> I[pxctl service drive replace --operation start]典型应用场景实践
边缘AI推理服务
架构特点:
- 模型存储:Portworx提供模型版本管理
- 数据流水线:边缘预处理+中心训练
- 增量更新:通过快照实现模型热更新
部署模式:
apiVersion: v1
kind: ConfigMap
metadata:
name: model-config
data:
MODEL_PATH: "/models/v3/"
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: ai-inference
spec:
replicas: 3
template:
spec:
volumes:
- name: model-store
persistentVolumeClaim:
claimName: model-pvc
containers:
- name: infer-engine
image: nvcr.io/ai-inference:latest
volumeMounts:
- name: model-store
mountPath: /models工业物联网数据聚合
数据流架构:
传感器 --> 边缘网关 --> 本地预处理 --> 时序数据库 --> 云端备份Portworx配置要点:
# 专用StorageClass
parameters:
repl: "2"
io_profile: "sequential" # 顺序写优化
fs: "xfs" # 大数据场景使用XFS性能基准测试
测试环境:
- 3节点集群(Intel NUC11, 16GB RAM, 1TB NVMe)
- K3s v1.26.4, Portworx 2.13
- 对比方案:LocalPV, NFS
4K随机读写测试:
fio --name=randwrite --ioengine=libaio --rw=randwrite \
--bs=4k --numjobs=4 --size=10G --runtime=300 \
--direct=1 --group_reporting测试结果对比:
存储类型 | IOPS (读) | IOPS (写) | 延迟(ms) | 带宽(MB/s) |
|---|---|---|---|---|
Portworx (副本1) | 18,532 | 15,678 | 1.02 | 248 |
Portworx (副本2) | 15,890 | 12,456 | 1.87 | 195 |
LocalPV | 22,145 | 19,876 | 0.87 | 312 |
NFS (千兆网络) | 1,245 | 980 | 12.3 | 98 |
测试结论:Portworx在保证数据冗余的同时,性能损失控制在30%以内,显著优于网络存储方案
总结与演进方向
核心价值验证:
- 资源节省:较完整K8s节省60%以上内存
- 部署效率:从裸机到可用集群<10分钟
- 运维简化:存储操作完全Kubernetes API化
典型适用场景:
- 分布式边缘数据库
- 工业物联网数据汇聚
- 5G MEC应用平台
- 连锁零售业务系统
- 自动驾驶数据缓存
边缘基础设施的进化永无止境。当轻量化的K3s遇见云原生存储Portworx,不仅解决了当下边缘计算的存储困境,更为构建下一代智能边缘平台奠定了坚实基础。在资源受限的环境中实现企业级可靠性,这正是云原生技术赋予边缘计算的魔力。
实战经验分享:在最近的智慧工厂项目中,我们遭遇了边缘节点频繁断电导致数据库损坏的问题。通过配置Portworx的异步复制和每15分钟快照策略,成功将数据恢复时间从小时级缩短到分钟级。关键配置如下:
# Portworx卷配置
annotations:
px.portworx.com/snapshot-schedule: "*/15 * * * *"
px.portworx.com/repl: "2"
px.portworx.com/io_priority: "high"排坑指南:当遇到节点间数据同步延迟过高时,检查以下配置:
- 网络MTU设置(建议1500)
- 禁用
network_compression(低带宽场景启用) - 调整
max_concurrent_repl参数(默认16)
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-07-14,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号