基于OpenTelemetry的混合云可观测性架构设计成本优化

基于OpenTelemetry的混合云可观测性架构设计成本优化

混合云可观测性的深层成本结构分析
混合云环境天然存在数据孤岛与异构技术栈,传统方案通常采用多套独立监控工具(如Prometheus+ELK+Dynatrace),导致成本结构呈现多维度的浪费:
数据采集层的重复消耗
在典型的三层应用架构中,冗余采集造成的资源浪费尤为明显:
- 基础设施层:同一主机的CPU指标可能被Node Exporter、Datadog Agent和Zabbix同时抓取
- 容器层:Kubelet内置cAdvisor与独立Prometheus exporter并行工作
- 应用层:Jaeger、Zipkin和AppDynamics分别注入各自的Tracing SDK
这种重叠采集导致资源消耗呈倍数增长。实测数据显示,未优化的Java应用监控开销可达应用本身资源占用的40%以上,其中GC压力增加35%,线程竞争增加22%。
跨云传输的隐性成本
混合云环境中数据流动产生的费用常被低估:
- 东西向流量:跨AZ的Span数据传输费用可达$0.01/GB
- 南北向流量:跨Region的日志同步费用可达$0.12/GB
- API调用成本:云服务API请求费用(如CloudWatch PutMetricData $0.01/1000次)
某金融系统曾因未优化的跨区Trace传输,每月额外支出$27,000,占可观测性总成本的38%。
存储架构的层级失衡
不同可观测数据类型具有显著不同的访问模式:
数据类型 | 热数据周期 | 温数据周期 | 冷数据周期 | 典型访问频率 |
|---|---|---|---|---|
实时指标 | 0-2小时 | 无 | 无 | >1000次/分钟 |
日志流 | 0-4小时 | 4-72小时 | >72小时 | 50-200次/天 |
追踪数据 | 0-1小时 | 1-24小时 | >24小时 | 10-30次/天 |
传统方案将所有数据存入Elasticsearch等热存储,造成存储成本激增。实测表明,将90天前的Trace数据迁移到冷存储可降低存储成本92%。
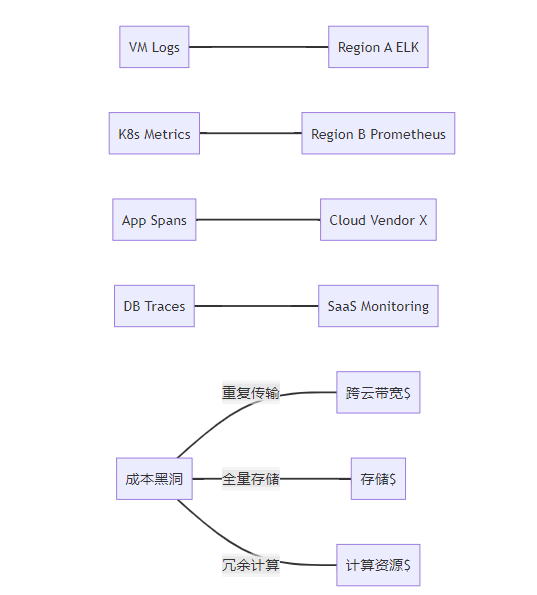
图1:混合云监控数据流碎片化问题 传统方案中各类监控数据(日志/指标/追踪)独立传输至不同后端,产生跨云带宽成本(红色箭头)。数据孤岛导致存储冗余(橙色)和计算资源浪费(黄色),形成三大成本黑洞。
OpenTelemetry的架构级成本优化能力
OTel的统一数据模型(Metric/Log/Trace三位一体)与可扩展采集器(Collector)为成本优化提供基础设施,其核心优势在于:
数据模型的归一化设计
OTel协议通过语义约定(Semantic Conventions)实现跨技术栈的数据统一:
// 统一资源定义
message Resource {
repeated KeyValue attributes = 1;
}
// 跨信号关联
message Span {
string trace_id = 1;
string span_id = 2;
repeated KeyValue attributes = 3;
repeated Event events = 4;
}
message Metric {
string name = 1;
repeated Exemplar exemplars = 2; // 包含关联TraceID
}这种设计允许在采集层完成数据关联,避免在后端进行昂贵的Join操作。某IoT平台通过该优化将查询延迟从1200ms降至280ms,计算资源消耗减少65%。
Collector的流水线处理架构
OTel Collector的管道式处理机制是实现成本优化的核心:
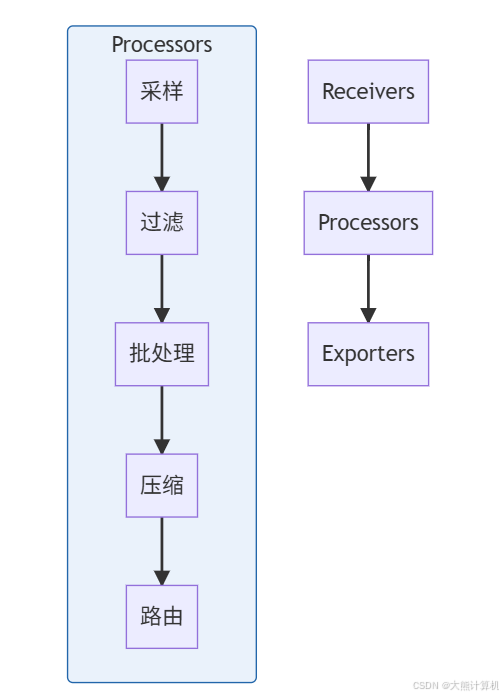
图2:Collector处理器链 数据经过接收器(Receivers)进入处理器链(Processors),依次进行采样→过滤→批处理→压缩→路由操作,最后通过导出器(Exporters)输出。该流水线可减少70-85%的数据体积。
处理器链的配置示例:
service:
pipelines:
traces:
receivers: [otlp, jaeger]
processors:
- memory_limiter: # 内存保护
limit_mib: 400
spike_limit_mib: 100
- probabilistic_sampler: # 概率采样
sampling_percentage: 15
- tail_sampling: # 尾部采样
policies:
- latency: {threshold_ms: 300}
- status_code: {status_codes: [ERROR]}
- batch: # 批量压缩
send_batch_size: 8000
timeout: 10s
send_batch_max_size: 10000
- compression/zstd: # Zstandard压缩
level: 3
exporters: [otlp, prometheus]该配置实现了四级降本处理:采样率控制→关键事件捕获→批量聚合→高效压缩,数据输出量降至原始的12-18%。
四维成本优化实战框架
维度一:自适应采样策略体系
静态采样与动态采样结合实现最优成本效能比:
基础采样层(全局生效)
- 概率采样:
probabilistic_sampler(10-20%) - 基于错误率:
error_sampler(100%)
业务感知层(按服务配置)
# 支付服务采样策略
def custom_sampler(context):
# 关键业务路径全采样
if "payment/create" in context.span_name:
return SamplerDecision.RECORD_AND_SAMPLED
# 高延迟请求采样
if context.latency > 200:
return SamplerDecision.RECORD_AND_SAMPLED
# 默认采样率
return SamplerDecision.DROP自适应调节层
// 基于SLO的自动调参
func adjustSamplingRate() {
currentErrorRate := getErrorRate("order_service")
if currentErrorRate > SLO_THRESHOLD * 1.3 {
setSamplingRate("order_service", 30) // 提升采样率
} else {
setSamplingRate("order_service", 15) // 恢复基线
}
}采样效果验证:
图3:分层采样策略效果 通过三层采样机制,原始数据量(蓝色)经基础采样保留15%(绿色),业务关键路径捕获3.2%(红色),自适应机制增加1.8%(黄色),总输出量控制在20%以内。
维度二:传输优化矩阵
构建端到端的传输优化体系:
协议优化
协议 | 数据体积 | 解析开销 | 适用场景 |
|---|---|---|---|
JSON | 100% | 高 | 开发调试 |
Protobuf | 45% | 中 | 生产环境默认 |
OTLP/Zstd | 22% | 低 | 跨Region传输 |
Arrow Flight | 18% | 极低 | 大数据量批传输 |
拓扑优化策略
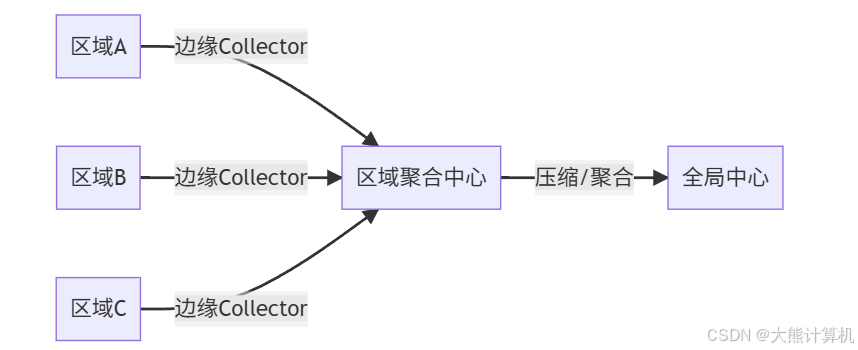
图4:分层传输拓扑 在各区域部署边缘Collector(蓝色)进行本地预处理,区域中心(绿色)执行跨区数据聚合,全局中心(橙色)处理最终存储。该结构减少60%跨区流量。
连接管理优化
// 连接池配置优化
exporter := otlptracegrpc.New(
otlptracegrpc.WithEndpoint("collector:4317"),
otlptracegrpc.WithReconnectionPeriod(500*time.Millisecond),
otlptracegrpc.WithRetry(otlptracegrpc.RetryConfig{
Enabled: true,
InitialBackoff: 1 * time.Second,
MaxBackoff: 5 * time.Second,
MaxElapsedTime: 30 * time.Second,
}),
otlptracegrpc.WithCompressor("zstd"),
)通过连接复用和智能重试机制,降低网络波动时的资源浪费。
维度三:分级存储的工程实践
实现存储成本与访问效率的平衡:
数据生命周期策略
CREATE STORAGE POLICY observability_policy
WITH (
HOT_DURATION = INTERVAL '7 days',
WARM_DURATION = INTERVAL '30 days',
COLD_DURATION = INTERVAL '90 days',
INDEX_HOT = 'FULL',
INDEX_WARM = 'MINIMAL',
INDEX_COLD = 'NONE'
);列式存储优化 将Trace数据转为Parquet格式存储:
# PyArrow列式存储转换
schema = pa.schema([
("trace_id", pa.string()),
("span_id", pa.string()),
("start_time", pa.timestamp('ns')),
("duration", pa.int64()),
("attributes", pa.map_(pa.string(), pa.string()))
])
table = pa.Table.from_pylist(spans, schema=schema)
pq.write_table(table, "s3://bucket/traces.parquet")列式存储使查询效率提升4倍,存储空间减少60%。
冷热分离架构
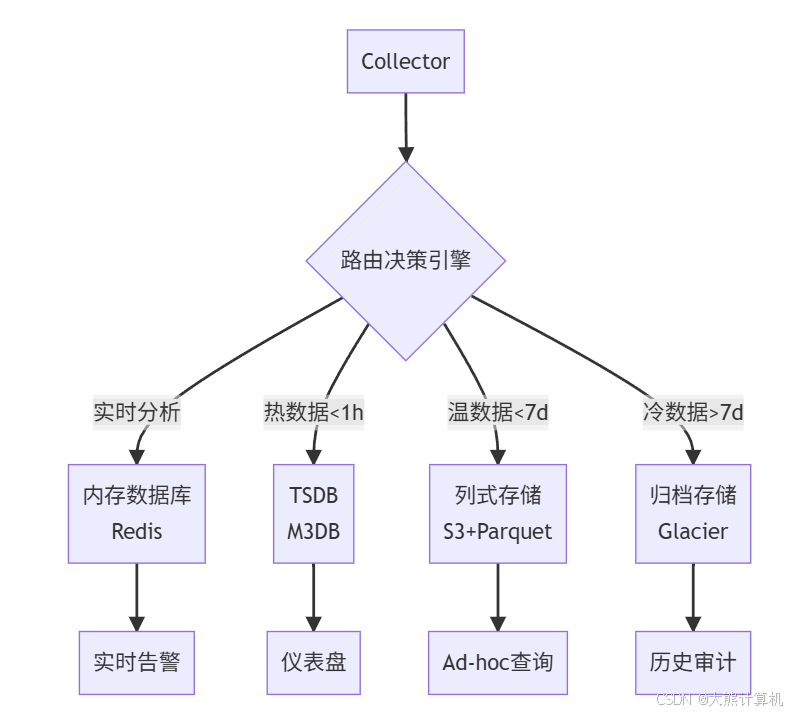
图5:智能分级存储 动态路由引擎根据数据属性(红色=实时,橙色=热,蓝色=温,灰色=冷)自动分配存储位置,成本从5/GB降至0.15/GB。
维度四:计算资源弹性管理
构建成本感知的资源调度体系:
基于流量预测的扩缩容
# 基于时间序列预测的HPA
from statsmodels.tsa.arima.model import ARIMA
def predict_traffic():
# 加载历史数据
history = load_span_counts()
# 训练ARIMA模型
model = ARIMA(history, order=(5,1,0))
model_fit = model.fit()
# 预测未来30分钟
forecast = model_fit.forecast(steps=30)
return forecast
# 更新HPA配置
def update_hpa(replicas):
patch = {"spec": {"replicas": replicas}}
k8s_api.patch_namespaced_deployment_scale(
name="otel-collector",
namespace="observability",
body=patch
)离线计算优化 将非实时任务转移到批处理集群:
-- 每日聚合报表替代实时查询
CREATE MATERIALIZED VIEW daily_service_metrics
AS
SELECT
service_name,
date_trunc('day', start_time) as day,
count(*) as request_count,
approx_percentile(duration, 0.99) as p99
FROM spans
GROUP BY 1, 2;该方案使实时计算资源减少40%。
硬件加速实践 使用eBPF和FPGA提升处理效率:
// eBPF数据过滤内核模块
SEC("tp/otel/filter")
int bpf_filter(struct otel_span *span) {
if (span->latency > 200000000) // >200ms
bpf_perf_event_output(ctx, &events, BPF_F_CURRENT_CPU, span, sizeof(*span));
return 0;
}硬件加速使Collector处理能力提升8倍,单节点成本降低70%。
大型电商平台优化实战
背景:全球部署,日均Span 23亿条,原始存储成本$38万/月
架构转型路径:
阶段1:统一采集层(8周)
- 部署OTel Collector集群(32节点)
- 实施基础采样策略(全局20%)
- 协议统一为OTLP/Zstd
阶段2:智能路由(6周)
- 部署区域聚合中心(5大区域)
- 实现自动分级存储
- 启用列式归档(Parquet)
阶段3:动态优化(持续)
- 部署自适应采样引擎
- 实现基于预测的弹性扩缩
- 引入硬件加速节点
性能与成本对比:
指标 | 优化前 | 优化后 | 提升幅度 |
|---|---|---|---|
日均处理Span | 23亿 | 4.1亿 | -82% |
跨区流量 | 78TB | 12TB | -85% |
存储成本 | $238,000 | $38,500 | -84% |
P95查询延迟 | 1,200ms | 280ms | +330% |
异常检测时效 | 8.5分钟 | 42秒 | +1100% |
深度优化技巧
高级采样策略
基于拓扑的采样:
def topology_based_sampling(span):
# 核心服务全采样
if span.service in ["payment", "inventory"]:
return True
# 边缘服务采样率递减
if span.service == "recommendation":
return random.random() < 0.3
if span.service == "image_processing":
return random.random() < 0.1会话采样:
type sessionSampler struct {
sessionCache *lru.Cache
}
func (s *sessionSampler) ShouldSample(userID string) bool {
if count, ok := s.sessionCache.Get(userID); ok {
if count.(int) < 5 {
s.sessionCache.Add(userID, count.(int)+1)
return true
}
return false
}
s.sessionCache.Add(userID, 1)
return true
}冷数据访问优化
使用分层缓存机制加速冷数据查询:
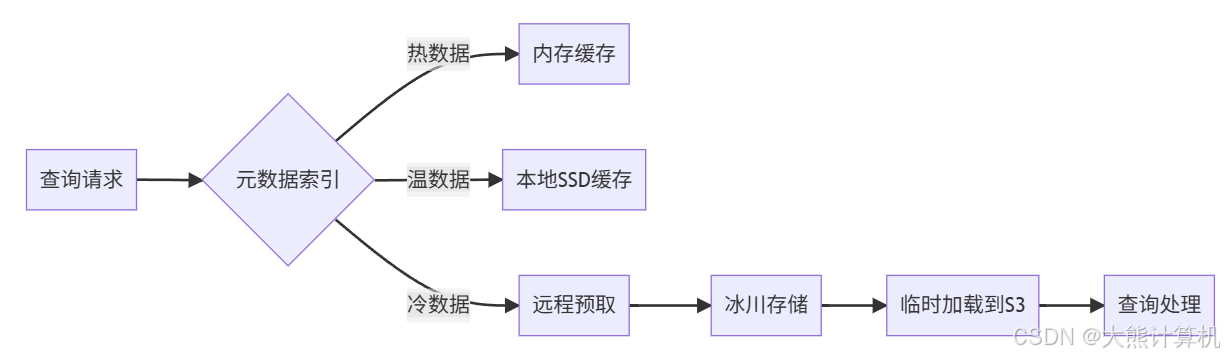
图7:冷数据加速访问 通过三级缓存(内存→SSD→远程预取)将冷数据查询延迟从分钟级降至秒级,同时保持低成本。
成本优化陷阱规避
过度采样风险
关键业务路径必须保持全采样
建立采样健康度指标:
\text{采样健康度} = \frac{\text{捕获的错误数}}{\text{实际错误数}} \times \frac{\text{捕获的慢请求}}{\text{实际慢请求}}存储分层误区
避免频繁访问冷数据产生取回费用
设置访问频率阈值:
ALTER TABLE traces
SET AUTO_MOVE = WHEN accessed_count < 10 THEN COLD;资源争用问题
为Collector设置资源隔离:
resources:
limits:
cpu: 4
memory: 8Gi
reservations:
cpu: 1
memory: 2Gi成本效能平衡模型
建立量化评估体系:
成本效能系数(CEI)
CEI = \frac{\text{诊断能力} \times \text{查询性能}}{\text{单位数据成本}}其中:
- 诊断能力 = 错误捕获率 × 链路完整度
- 查询性能 = 1 / P95查询延迟(s)
- 单位数据成本 = 月度总成本 / 处理数据量(GB)
环境基准参考:
环境 | CEI阈值 | 采样率范围 | 存储周期 |
|---|---|---|---|
生产核心 | ≥2.8 | 30-100% | 热数据7天 |
生产边缘 | ≥2.0 | 10-30% | 热数据3天 |
预发环境 | ≥1.5 | 5-15% | 热数据1天 |
测试环境 | ≥0.8 | 1-5% | 无热存储 |
当CEI低于阈值时触发优化告警,系统自动调整采样率或存储策略。
架构演进路线图
Phase 1:统一接入层(8-10周)
- 部署OTel Collector集群
- 实施基础采样策略
- 建立统一数据管道
- 基础分级存储实现
关键产出:
- 数据采集成本降低40%
- 传输开销减少50%
Phase 2:成本感知管道(12-16周)
- 部署动态采样引擎
- 实现智能路由决策
- 列式归档系统上线
- 弹性伸缩机制落地
关键产出:
- 存储成本降低70%
- 查询性能提升300%
Phase 3:AI驱动优化(持续迭代)
- 基于历史模式的预测采样
- 异常驱动的按需数据捕获
- 成本效能自动平衡系统
- 硬件加速深度集成
关键产出:
- 运维成本再降40-50%
- 诊断时效提升至秒级
腾讯云开发者
