企业级项目:动态 Supervisor Multi Agent 架构 & 功能实现(v1.0)

企业级项目:动态 Supervisor Multi Agent 架构 & 功能实现(v1.0)

臻成AI大模型
发布于 2026-02-02 13:49:30
发布于 2026-02-02 13:49:30
来自学员的企业级实战项目分享:动态 Supervisor Multi Agent 架构 & 功能实现(v1.0)

项目背景
统一智能体平台入口:
该系统作为所有任务识别、路由、分发、监控与交互中心,屏蔽业务对 sub_agent 的直接感知 。
在该架构下,可以充分利用体系中的 agent 的作用,对复杂任务进行统一管理与解决,协同多个 sub_agent 共同解决问题 。*
目标:
使用一套适配且足够通用的架构体系去兼容不同的 sub_agent,只需跟 sub_agent 确定交互协议、Schema 结构等核心可配置信息,即可在用户无感知(即 Supervisor 体系不重新发布)的前提下,通过配置文件动态地挂载、修改、禁用、删除这些 sub_agent 。
项目整体架构
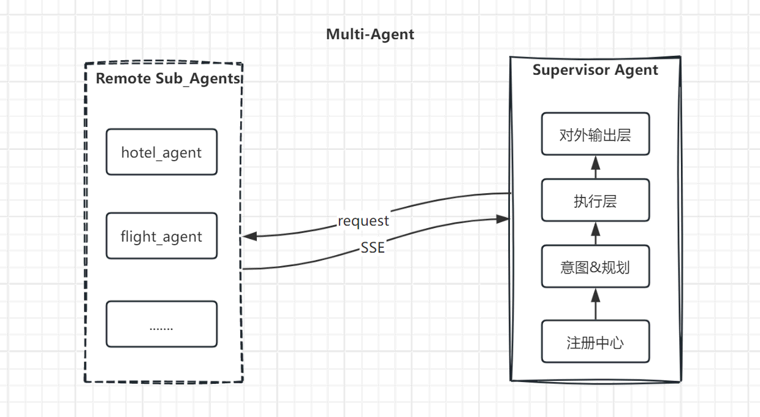
该项目整体架构主要围绕解耦的思路进行设计与实现。
体现在以下几点:
1. supervisor init与sub_agent解耦。
无需将sub_agent的代码纳入supervisor下,sub_agent可以是单独工作,也可以纳入Multi Agent体系协同工作,并且不会影响原有的sub_agent间的Swarm。
sub_agent开发人员只需按照规范对配置文件进行配置,无感知的将”自己“纳入supervisor体系中,且supervisor可以动态无感知的完成能力更新;
2. 避免多轮无效handoff。
sub_agent开发人员可以通过在配置文件中配置有效执行需要的语义参数,supervisor动态获取后在”任务规划“阶段提取用户query中的这些”槽位“进行语义非空判断,如果没有满足必需信息,则不路由到sub_agent,直接返回让用户进行补全,用户补全后通过多轮对话机制结合历史信息对query进行改写后将单元task下发到对应的sub_agent。
考虑到interrupt+Command的方式会暂停graph后从checkpointer中恢复,可能会导致进程阻塞或超时,降低系统整体并发能力和稳定性,所以采用了多轮对话机制进行自动补全;
3. 意图识别非固定语义或规则判断。
在这个解耦架构中通过supervisor的”注册中心“模块,动态的感知sub_agent挂载情况和其能力获取,封装”能力卡片“注入意图识别,做意图分类,故sub_agent变更时意图识别也会动态感知并准确识别;
4. 架构与业务(前后端)解耦。
通过配置文件中配置的sub_agent缺失key对应的前端wigdets,在用户问题缺失这些信息时按缺失顺序返回对应的key、key描述以及wigdet_id,此wigdets_id要与前后端统一维护映射规则进行口径统一,即可在SSE流式返回接口时携带信息方便前端做弹窗或其他适配,无需在supervisor代码中额外增加处理规则。
项目流程
3.1 整体流程
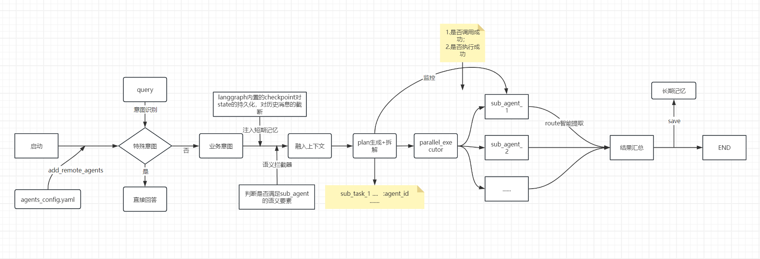
在项目启动时会进行agent_config.yaml热加载在注册中心封装多个”能力卡片“并全局缓存,构建graph。
用户问题进来时会对问题做多级分流:简单意图和业务意图;业务意图中对于需要sub_agent协同的方式中做任务规划,分为串行/并行的简单业务任务以及混合执行的复杂业务任务。
在意图识别中粗粒度识别敏感/风险词进行正确引导,任务规划时会做如下操作:
1. 现有体系中没有的能力不进行sub_task生成,继续其他能力内的sub_task生成以及后续流程;
2. 语义拦截,判断问题中是否包含sub_agent需要的语义要素,如果不满足则不无效路由sub_agent,直接push用户进行补全(包含前端应弹出的组件id),通过短期记忆上下文对补全的信息与当前问题进行问题改写后继续生成sub_tasks,然后handoff sub_agent进行执行,并对过程任务进度进行监控,全部收集后进行统一汇总后输出。
3.2 核心特性
动态 Agent 注册: 基于 YAML 配置的热加载机制,支持运行时增删改子 Agent。
双通道状态架构:AgentState (内部流转) + ResponseState (用户输出) 完全解耦。
分层记忆体系: LangGraph Checkpointer (短期) + 文件持久化 (长期) + 语义缓存。
智能意图识别: 基于 LLM 的多意图并发识别与 Rewrite 机制。
语义要素检测: 自动检测参数缺失并提供前端组件建议。
思维链可视化: 细粒度流式输出,展示 AI 推理全过程。
3.3 功能实现
3.3.1 意图识别
支持单一 query 触发多个意图。
具体逻辑:
1. 注入remote sub_agent的能力卡片(capability_cards)、短期记忆(区分用户+会话)和llm动态生成的few shot到Prompt中,输出结构如下:
{
"intent": ["酒店服务", "机场接送机服务"],
"confidence": "high",
"reason": "用户同时需要酒店预订和接送机",
"rewritten_query": "帮我预订北京的酒店并安排首都机场接机",
"user_friendly_message": "明白了!我将为您查找合适的酒店,并安排接送机服务。"
}
2. 简单意图(非业务意图,包括:闲聊、敏感话题、招呼语、自身能力问答、超出能力范围)不走task_plan生成逻辑,直接回答。
业务意图根据capability_cards信息基于sub_agent粒度进行query拆分,用于任务规划阶段生成task_plan。
特殊情况:如果query中包含超出现有能力体系的需求,则超出能力的意图不纳入intent列表,其他意图要素继续后续任务规划流程。
记忆相关:短期记忆处理逻辑:短期记忆通过state中的memory_content进行最近5轮(可以.env中配置MEMORY_MAX_HISTORY来调整)对话提取,注入prompt中让llm进行判别是否需要融合上下文信息,比如指代补全、用户补充信息融合等。
最终进行query改写到rewritten_query中去覆盖state中的当前query。reason用来交由supervisornode来验证是否合理,是否需要重新提取意图操作。
3.3.2 任务规划
在正式任务规划前,会确保sub_agent需要的语义要素在当前query中完全满足,即通过agent_config.yaml中sub_agent开发人员配置的required_semantic_keys 去语义识别。
如果不满足,则对应sub_task不路由也不执行,会直接返回给用户进行信息补充,而其他sub_tasks正常路由和执行最终输出给用户。在返回semantic_info时会根据配置文件中的fe_wigdets_suggestion进行前端弹出组件id的输出,方便前端即时在页面进行组件召回,方便用户快速填充。
这个组件id是通过统一映射字典进行系统间打通的。任务规划将意图转换为可执行的 sub_tasks 列表,这个操作会基于事实(完整用户query)和capability_card且遵循sub_agent粒度来进行tasks切分,理解不同sub_task之间是否存在依赖关系,决定最终的plan json中sub_task的执行链路(支持串行、并行以及混合执行。后续会完善为准确的DAG结构进行更高效的执行路径规划,这些sub_tasks可以通过合理 的多节点并行执行来提高整体链路的吞吐量和并发能力)。
同时任务规划会根据全局缓存的capability_card对remote sub_agent的输出和输出schema进行严格提取,完全遵循agents_config.yaml配置的schema结构。
最终task_plan如下所示:
{
"task_plan": {
"plan_id": "plan_20251113_001",
"task_type": "sequential",
"sub_tasks": [
{
"task_id": "plan_20251113_001_task_1",
"description": "为用户安排明天早上7点在白云机场的接机服务",
"assigned_agent": "limo_agent",
"inputs": {
"message": "在白云机场,明天早上7点接机",
"model": "openai-compatible",
"user_id": "...",
"thread_id": "..."
},
"dependencies": [],
"status": "pending"
}
],
"reasoning": "用户意图明确为机场接机服务(limo_agent),且query中包含机场名称和时间...",
"total_tasks": 1,
"missing_semantic_keys": [],
"user_friendly_message": "已为您制定执行方案。我将为您安排明天早上7点在广州白云机场的接机服务..."
}
}
注意:在此系统中,为了提高每个步骤的独立性和容错性,task_plan的sub_task划分依据不一味信任intent列表,还会结合现有能力范围和用户query去核实哪些意图要素不可执行,不可执行的意图不进行对应sub_task生成,但其他sub_tasks 不受影响。
3.3.3 路由决策
依据task_plan的assigned_agent进行sub_task的路由提取。
3.3.4 过程监控
supervisor会从state中提取current_task_index对进度进行感知,同时在sub_task结果更新时进行结果验收,将异常情况写入state供summarize node进行结果汇总并用户友好型输出。
3.3.5 结果汇总
将supervisor node验收后的每个sub_task的执行信息做汇总,展示结果的同时告知用户哪些任务没执行,需要补充什么信息,并提供样例。
3.3.6 思维链展示
阶段 | Is Thinking | Agent ID | Content 示例 |
|---|---|---|---|
意图识别开始 | true | supervisor | “正在分析您的需求...” |
意图识别完成 | true | supervisor | “明白了!我将为您查找合适的酒店。” |
任务规划开始 | true | supervisor | “正在为您制定执行方案...” |
任务规划完成 | true | supervisor | “已为您制定执行方案。我将先为您...” |
Agent 开始执行 | true | remote sub_agents | “正在为您提供酒店推荐...” |
Agent 流式输出 | true | remote sub_agents | “找到3家符合条件的酒店” |
汇总开始 | true | summarize | “已成功完成2项任务。正在为您整理结果...” |
最终答案 | false | summarize | “为您推荐以下3家北京的酒店...” |
3.4 State 流转机制
3.4.1 State 结构
AgentState设计要点:
顺序一致性:keys、key_descriptions、fe_wigdets_suggestion 三数组严格一一对应,无 widget时用空字符串占位
安全考量:content 不暴露 agent_id、intent 等内部术语
动态生成:所有友好描述由 LLM 基于 agents_config.yaml 动态生成,无硬编码
每轮清空:response_stream 在 build_initial_state 时重置为空数组
#Graph全局state
AgentState = {
# 用户输入
"query": str,
"user_id": str,
"thread_id": str,
# 意图与规划
"intent": List[str],
"task_plan": Dict,
# 执行控制
"current_task_index": int,
"next_agent": str,
"execution_path": List[str],
# 结果存储
"task_results": Dict[str, Any],
"final_answer": str,
# 记忆与元数据
"memory_context": Dict,
"metadata": Dict, # 含缺失语义信息
"messages": List[Dict],
"response_stream": List[ResponseState] # 用户友好输出队列
}
#接口响应state
ResponseState = {
"type": "content" | "done",
"content": "用户友好文本...",
"agent_id": "supervisor/summarize/...",
"is_thinking": true,
"session_id": "...",
"metadata": {
"semantic_info": [
{
"type": "miss" | "invalid",
"sub_agent_id": "...",
"keys": ["key1"],
"key_descriptions": ["desc1"],
"fe_wigdets_suggestion": ["widget_id_1"]
}
],
"state": {}
}
}
3.4.2 State 流转关键节点
1. 初始化(build_initial_state)
- 创建新一轮对话的初始 state
- 显式重置 task_plan=None、next_agent=None(防止 Checkpointer 合并旧值)
- 初始化 response_stream=[](每轮对话清空)
2. Supervisor 规划阶段
- 读取:query、memory_context、intent_history
- 写入:intent、task_plan、next_agent、metadata
- 更新:response_stream(意图识别结果、任务规划描述)
3. Sub-Agent 执行阶段
- 读取:task_plan.sub_tasks[current_task_index]
- 写入:task_results[agent_id]、execution_path
- 更新:current_task_index += 1、response_stream(流式过程)
4. Summarize 汇总阶段
- 读取:query、task_results、metadata.missing_semantic_info
- 写入:final_answer、next_agent="end"
- 更新:response_stream(汇总描述、最终答案)
3.5 记忆模块
Layer 1:Checkpointer 短期记忆
- 实现:LangGraph AsyncSqliteSaver
- 存储内容:完整的 AgentState(含 messages 历史)
- 索引维度:thread_id(会话级)
- 生命周期:持久化至 SQLite,支持多轮对话上下文延续和interrupt后状态恢复
- 优势:自动管理 state 合并,支持时间旅行调试
Layer 2:Long-term Memory 长期记忆
- 实现:文件系统持久化(JSON)
- 存储内容:完整对话交互(query、intent、task_plan、task_results、final_answer、metadata)
- 索引维度:session_id + 时间戳
- 生命周期:永久保存,用于用户行为分析、画像构建。目前只清洗+结构化+存储,不处理
- 路径结构:{MEMORY_SESSION_DIR}/{session_id}/exchanges/
Layer 3:Semantic Cache 语义缓存
- 实现:能力卡片缓存(get_cached_capabilities_for_agent)
- 存储内容:格式化的 Agent 能力描述(用于 Prompt)
- 更新机制:配置文件变更时自动更新
- 优势:减少重复格式化开销,加速 Prompt 构建
四、后期规划
4.1 长期记忆体系
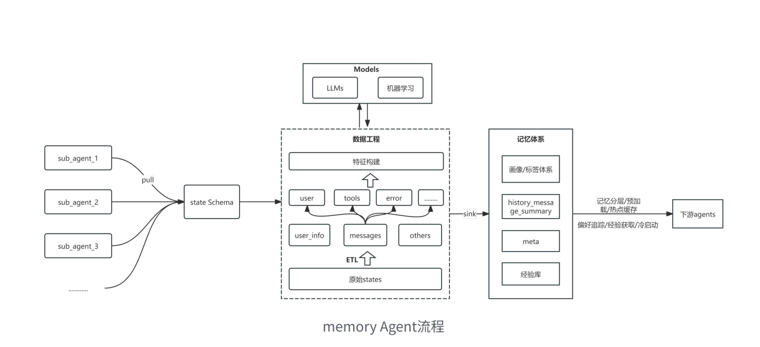
思路:
1. 构建⻓期记忆库原始数据集:state json 离线抽取 ->ETL,如使⽤ dataX/Seatunnal PG-ES,使⽤ SQL/python 进⾏数据清洗、分层汇总;
2. 基于数据⼯程 /LLMs 异步汇总 / 机器学习模型构建特征⼯程;
3. 产出⽤⼾画像体系,⽤于⽤⼾冷启动(Tag 匹配 / 相似度计算)、⽤⼾偏好提取、定制化回答、历史问答回溯、badcasde 分析、agent 实时监控与经验获取(复杂任务构建 cot)等;
4. 记忆分层,热点问题加载 cache;
5. llm_tasks/ data_tasks 离线跑批。流程:⽤⼾冷启动 -> 匹配标签 ->meta、经验库预加载 -> 意图识别 -> 经验获取 -> ⻓期记忆摄⼊ -> 后续流程 ...
优点:
1. 通过数据⼯程、机器学习、⼤模型融合,通过对 state 数据的治理和挖掘,构建⽤⼾画像体系,为智能体适应不同⽤⼾偏好提供事实参照,量化对⽤⼾⻛格的认知,根据⽤⼾所在的tag 更好的做⾏程规划、酒店推荐、饭店推荐、景点推荐等;
2. 避免 agent 在通过 llm 进⾏⻓上下⽂汇总时造成延迟、线程阻塞、效果不稳定等影响⽤⼾体验感的后果;
3. ⽀持历史对话记录、⼯具调⽤情况等数据回溯,可以进⾏舆情分析,⽤⼾历史经验提取与沉淀、badcass 定位与分析、prompt 模块化与⾃适应优化等(避免提⽰词爆炸);
4. ⽤⼾冷启动时避免乱推荐,整体输出相对稳定;
5. 热点问题缓存,将记忆 / 经验提⽰分层存放,平衡性能和准确度;
6. 沉淀⽤⼾画像体系,避免 agent 每次交互时重新探索某个 / 类⽤⼾最佳沟通路径,提⾼agent 适应和学习能⼒。
4.2 业务感知能力
防止后期所有sub_agent扁平化地处在同一层级上,可引入业务地图(图谱)结合RAG+部分预加载使动态挂载的sub_agent遵循业务层级分布,避免每次query都全量扫sub_agent 池,且通过注入业务体系进行结果辅助验证。
4.3 高度复杂任务与多轮 Handoff
对于异常复杂任务,通过用户偏好进行最优路径规划,支持sub_tasks呈DAG或网状结构,更细粒度的划分stage、task并合理使用并行、串行以及混合任务执行机制保证任务执行路径最优。
当前v1.0版本已跑通,欢迎交流!v2.0 迭代ing...
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-01-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号