exo: 使用日常设备在家运行自己的 AI 集群

exo: 使用日常设备在家运行自己的 AI 集群

山行AI
发布于 2026-03-13 18:08:17
发布于 2026-03-13 18:08:17

exo logo
大家好,今天给大家介绍一款软件exo(由 exo Labs[1] 维护),它可以 将您所有的设备连接成一个 AI 集群。exo 不仅能够运行比单一设备更大的模型,还支持通过 Thunderbolt 进行 RDMA 日零支持[2],使得随着设备数量的增加,模型运行速度更快。
特性
•自动设备发现:运行 exo 的设备会自动发现彼此,无需手动配置。•Thunderbolt 上的 RDMA 支持:exo 提供对 Thunderbolt 5 上的 RDMA 的日零支持[3],能够将设备间的延迟减少 99%。•拓扑感知自动并行:exo 会根据设备拓扑的实时视图,计算出最优的方式将模型拆分到所有可用设备上。它会考虑设备资源和各链接间的网络延迟/带宽。•张量并行:exo 支持模型分片,在 2 台设备上可获得最高 1.8 倍的加速,在 4 台设备上可获得最高 3.2 倍的加速。•MLX 支持:exo 使用 MLX[4] 作为推理后端,并使用 MLX[5] 分布式进行分布式通信。
基准测试
•Qwen3-235B(8 位) 在 4 台 M3 Ultra Mac Studio 上运行,支持张量并行 RDMA。•DeepSeek v3.1 671B(8 位) 在 4 台 M3 Ultra Mac Studio 上运行,支持张量并行 RDMA。•Kimi K2 Thinking(原生 4 位) 在 4 台 M3 Ultra Mac Studio 上运行,支持张量并行 RDMA。
快速开始
运行 exo 的设备会自动发现彼此,无需任何手动配置。每个设备都提供一个 API 和一个仪表板,用于与您的集群进行交互(默认在 http://localhost:52415 运行)。
有两种方式可以运行 exo:
从源代码运行(Mac & Linux)
前提条件:
•brew[6](用于在 MacOS 上进行简单的软件包管理)
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"•uv[7](用于 Python 依赖管理)•macmon[8](用于 Apple Silicon 的硬件监控)•node[9](用于构建仪表板)
brew install uv macmon node•rust[10](用于构建 Rust 绑定,当前使用 nightly 版本)
curl --proto '=https'--tlsv1.2-sSf https://sh.rustup.rs | sh
rustup toolchain install nightly克隆代码库,构建仪表板并运行 exo:
# 克隆 exo 仓库
git clone https://github.com/exo-explore/exo
# 构建仪表板
cd exo/dashboard && npm install && npm run build && cd ..
# 运行 exo
uv run exo这将启动 exo 仪表板和 API,您可以在 http://localhost:52415/ 访问。
macOS 应用
exo 提供了一个 macOS 应用,可以在您的 Mac 背景中运行。
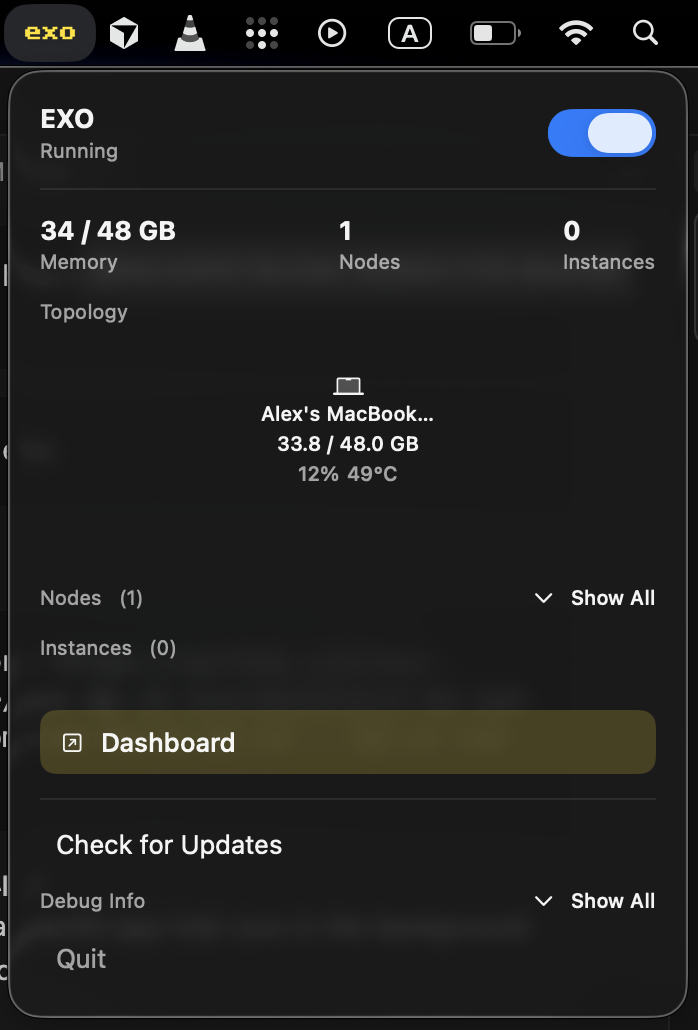
exo macOS App - running on a MacBook
该 macOS 应用要求 macOS Tahoe 26.2 或更高版本。
可以在这里下载最新版本:EXO-latest.dmg。
应用会请求修改系统设置并安装新的网络配置文件。目前正在改进此功能。
使用 API
如果您更喜欢通过 API 与 exo 交互,以下是一个示例,展示如何创建一个小模型的实例(mlx-community/Llama-3.2-1B-Instruct-4bit),发送聊天完成请求并删除该实例。
1. 预览实例位置
/instance/previews 端点将预览该模型的所有有效部署位置。
curl "http://localhost:52415/instance/previews?model_id=llama-3.2-1b"示例响应:
{
"previews":[
{
"model_id":"mlx-community/Llama-3.2-1B-Instruct-4bit",
"sharding":"Pipeline",
"instance_meta":"MlxRing",
"instance":{...},
"memory_delta_by_node":{"local":729808896},
"error":null
}
// ...可能还有更多位置...
]
}此命令将返回该模型的所有有效位置。选择您喜欢的位置。如果选择第一个位置,可以使用 jq 进行过滤:
curl "http://localhost:52415/instance/previews?model_id=llama-3.2-1b"| jq -c '.previews[] | select(.error == null) | .instance'| head -n12. 创建模型实例
发送 POST 请求到 /instance 端点,并在实例字段中提供您选择的位置(完整的请求体必须与 CreateInstanceParams 中的类型匹配),您可以从第 1 步复制这个位置。
curl -X POST http://localhost:52415/instance \
-H 'Content-Type: application/json' \
-d '{
"instance":{...}
}'示例响应:
{
"message":"Command received.",
"command_id":"e9d1a8ab-...."
}3. 发送聊天完成请求
现在,向/v1/chat/completions 端点发送 POST 请求(格式与 OpenAI 的 API 相同):
curl -N -X POST http://localhost:52415/v1/chat/completions \
-H 'Content-Type: application/json' \
-d '{
"model":"mlx-community/Llama-3.2-1B-Instruct-4bit",
"messages":[
{"role":"user","content":"What is Llama 3.2 1B?"}
],
"stream":true
}'4. 删除实例
完成后,通过实例 ID 删除该实例(可以通过 /state 或 /instance 端点找到实例 ID):
curl -X DELETE http://localhost:52415/instance/YOUR_INSTANCE_ID其他有用的 API 端点:
•列出所有模型:curl http://localhost:52415/models•检查实例 ID 和部署状态:curl http://localhost:52415/state
有关详细信息,请参阅 src/exo/master/api.py[11] 中的 API 类型和端点。
好了,今天的分享就到这里了,下期见!
https://github.com/exo-explore/exo?tab=readme-ov-fileReferences
[1] exo Labs:https://x.com/exolabs
[2]Thunderbolt 进行 RDMA 日零支持:https://x.com/exolabs/status/2001817749744476256?s=20
[3]Thunderbolt 5 上的 RDMA 的日零支持:https://x.com/exolabs/status/2001817749744476256?s=20
[4]MLX:https://github.com/ml-explore/mlx
[5]MLX:https://ml-explore.github.io/mlx/build/html/usage/distributed.html
[6]brew:https://github.com/Homebrew/brew
[7]uv:https://github.com/astral-sh/uv
[8]macmon:https://github.com/vladkens/macmon
[9]node:https://github.com/nodejs/node
[10]rust:https://github.com/rust-lang/rustup
[11]src/exo/master/api.py: https://github.com/exo-explore/exo/blob/main/src/exo/master/api.py
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-28,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号