苹果最新论文打脸推理模型:思维链集体翻车,复杂难题面前秒变人工智障?

苹果最新论文打脸推理模型:思维链集体翻车,复杂难题面前秒变人工智障?

不二小段
发布于 2026-04-09 15:44:52
发布于 2026-04-09 15:44:52
从 OpenAI 的 o1 惊艳亮相,再到 DeepSeek R1 以及 Claude、Gemini 推出「Thinking」模式,新一代的大模型纷纷亮出了自己的「思考」能力。
它们不再是简单地直接给出答案,而是会生成详尽的「思维链」(Chain-of-Thought, CoT),模拟人类解决问题时的思考过程,甚至还会自我反思和修正,被称为「大型推理模型」(Large Reasoning Models, LRMs)。这种进步在各大数学和代码榜单上带来了显著的性能提升,让许多人惊呼「通用人工智能(AGI)的曙光已现」。
然而,在这片繁荣的背后,一个根本性的问题始终萦绕在研究者的心头:这种「思考」,究竟是真正意义上的、可泛化的逻辑推理,还是一种更加高级、更加逼真的模式匹配?
今天,来自苹果公司的最新研究,对这个问题进行了一次系统性的、堪称「灵魂拷问」级别的深入探究,给 LRMs 热潮泼了一盆冷水。

Image
这篇名为 《思考的幻觉:通过问题复杂度的视角理解推理模型的优势与局限》 的论文,通过一系列精巧的实验,揭示了一个令人不安的结论:大模型的推理能力并非我们想象中那样通用和稳健,而是在复杂性面前不堪一击,最终会遭遇「断崖式崩溃」。
Image
著名 AI 学者、坚定的「大模型怀疑论者」Gary Marcus 将这篇论文称为对大模型的一次「毁灭性打击」。他认为,这篇论文无可否认地证明了当前「思考型」大模型不存在真正的推理能力。
这篇来自苹果的论文究竟揭示了什么?它又是如何系统性地戳破了 AI「思考」的泡沫?这是否意味着,通往 AGI 的道路,比我们想象的要崎岖得多?
从「刷榜」到「解谜」:为什么数学题不够用了?
长久以来,我们习惯于用各种数学和编程竞赛题库(如 MATH、AIME 等)来衡量一个大模型的聪明程度。模型在这些榜单上的分数,往往被视为其推理能力的黄金标准。
但苹果的研究团队犀利地指出,这种评估方式存在致命缺陷:数据污染。
由于这些基准测试都是公开的,模型很可能在训练过程中已经「背」下了答案或解题套路。这就像一个考生提前拿到了考卷,即使他并不真正理解,也能考出高分。
Image
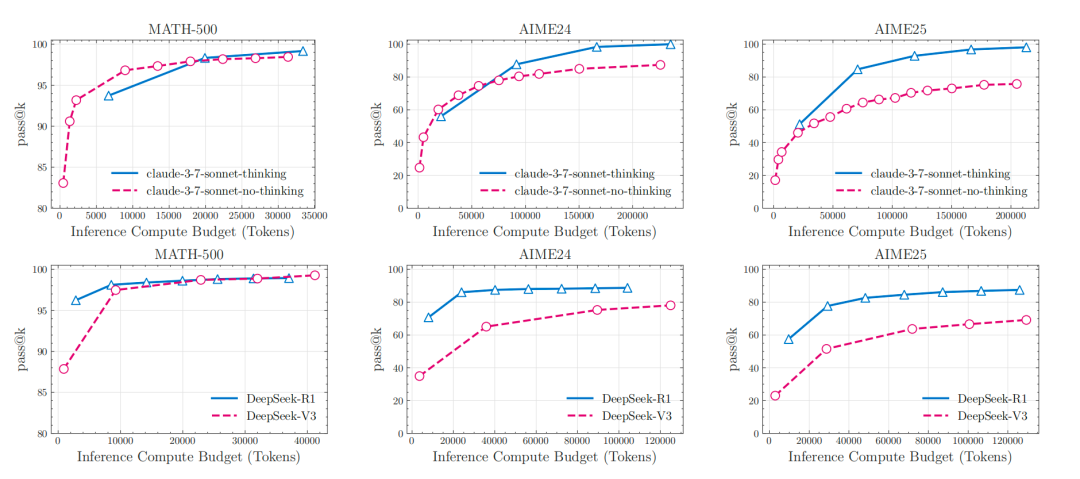
论文中的一个观察佐证了这一点。研究人员发现,在 AIME24 和 AIME25 这两个数学竞赛基准上,模型的表现出现了奇怪的波动。通常认为 AIME25 的题目对人类来说甚至比 AIME24 更简单一些,但很多模型的表现却在 AIME25 上不升反降。这很难用「题目变难了」来解释,一个更合理的推测是,模型对 AIME24 的训练数据接触得更充分,即数据污染更严重。
为了摆脱这种困境,研究团队设计了一套全新的、更纯粹的测试方法——可控的逻辑谜题。
他们选择了四个经典的逻辑游戏,设计了一系列可控的逻辑谜题作为实验环境:
- 汉诺塔 (Tower of Hanoi): 测试递归思想和规划能力。
- 跳棋 (Checkers Jumping): 测试序列规划和空间推理。
- 过河问题 (River Crossing): 测试复杂的约束满足和多智能体协调。
- 积木世界 (Blocks World): 测试规划、状态跟踪和子目标分解。
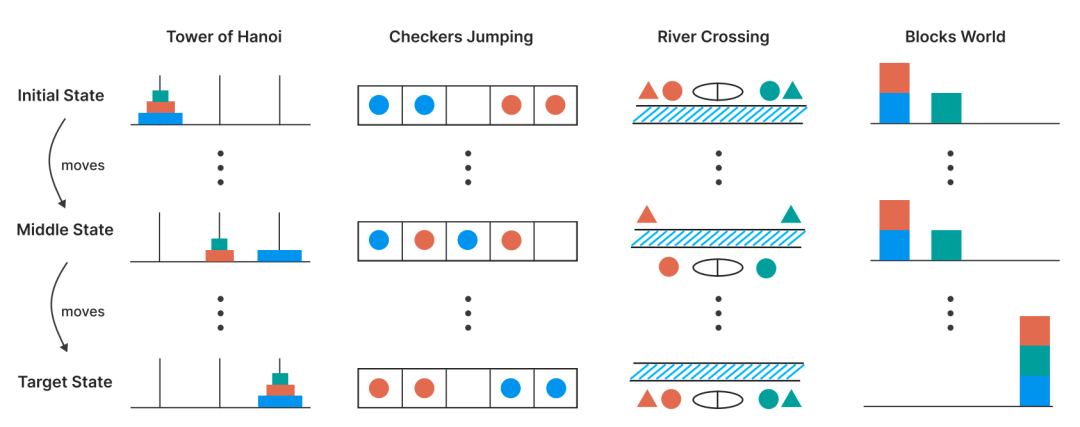
Image
图注:论文中使用的四个谜题环境,从上到下分别为初始状态、中间状态和目标状态。
这些谜题有几个关键优势:
- 复杂度可控: 只需增减几个棋子或盘子,就能精确地、指数级地提升难度。
- 无数据污染: 这些谜题的特定复杂实例,几乎不可能出现在通用训练数据中,避免了污染问题。
- 规则明确: 模型只需理解规则,无需任何外部知识。
- 过程可验证: 每一步的对错都可以通过模拟器进行精确判断,不仅能看最终答案,还能分析整个「思考过程」的质量。
从「刷榜」转向「解谜」,苹果的研究者们准备对这些看似聪明的「思考者」进行一次彻底的压力测试。
「汉诺塔」之辱:AI 的尴尬时刻
在所有谜题中,「汉诺塔」的测试结果最令人震惊,也最具讽刺意味。
汉诺塔问题对于计算机算法来说是小菜一碟,任何一个计算机科学专业的本科生都能写出解决它的递归程序。对于人类来说,一个聪明的 7 岁孩子经过练习也能掌握。
然而,当今最顶尖、耗资数十亿美元训练的大语言模型,却在这个古老的问题上栽了跟头。
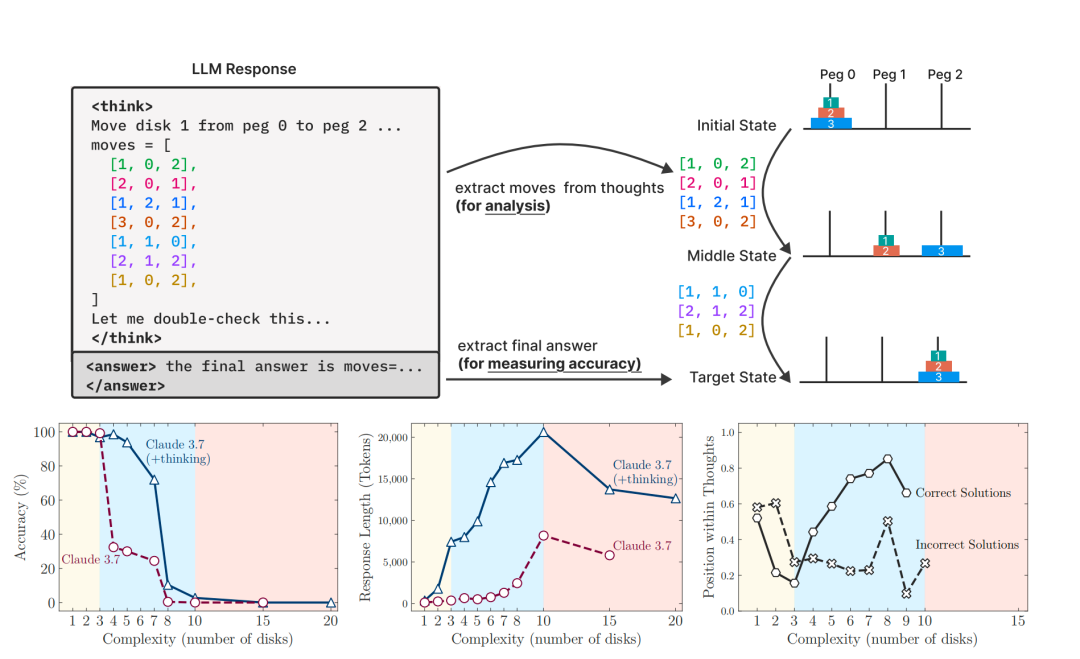
研究结果显示无论是 Claude 3.7 Sonnet 还是 DeepSeek-R1,在处理 3、4、5 个盘子的汉诺塔问题时,还能保持不错的准确率。但当盘子数量增加到 8 个时,它们的准确率就断崖式下跌,几乎为零。苹果团队发现,即使是备受赞誉的 o3-mini 模型也同样惨败。
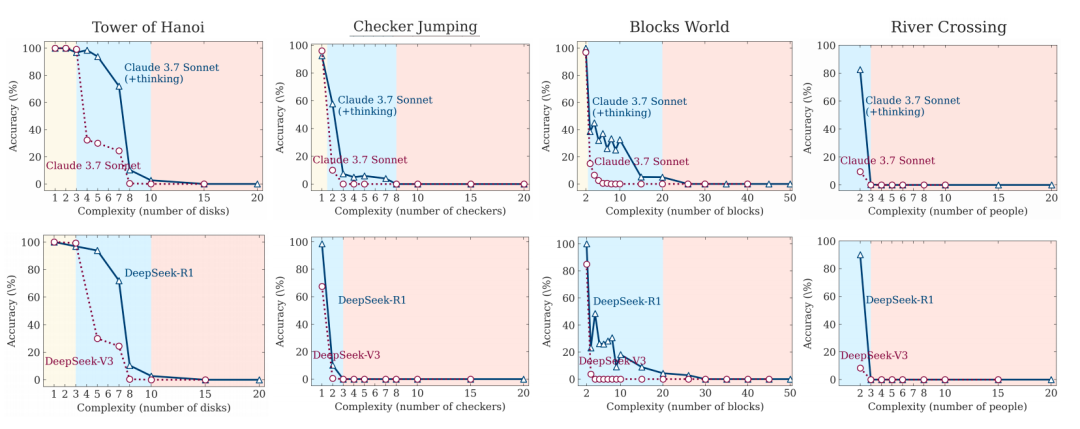
Image
△ 不同模型在四种谜题上的准确率随复杂度变化
Gary Marcus 评论道:「LLM 无法可靠地解决汉诺塔问题,这真的非常尴尬。」
更令人瞠目结舌的还在后面。论文的共同第一作者 Iman Mirzadeh 透露了一个关键实验细节:
「我们不仅仅是让模型解决谜题。在论文的 4.4 节,我们做了一个实验,直接把解决汉诺塔的算法提供给模型,它所要做的仅仅是遵循步骤。然而,这对其性能毫无帮助。」
也就是说,即便是把解题算法直接「喂」给模型,让它们照着抄作业,它们也无法正确执行。
这意味着,模型的失败并非源于找不到解题思路,而是根本无法稳定地、逻辑一致地执行一系列明确的指令。 它们的「推理」过程并非基于逻辑,而更像是一种脆弱的、无法泛化的模式匹配。
一个号称能达到 AGI 的系统,却无法完成一个早在 1957 年就被 AI 先驱赫伯特·西蒙 (Herb Simon) 用早期 AI 技术解决的问题。这不禁让人怀疑,我们离真正的通用智能还有多远。
「思考」的三种模式:从过度思考到集体崩溃
实验将最先进的「思考型」大模型,如 Claude 3.7 Sonnet (thinking) 和 DeepSeek-R1,与它们对应的「非思考型」标准版大模型进行正面 PK。
通过系统地调整谜题复杂度,苹果的研究者们发现了 LLM 推理行为中存在的三种截然不同的模式。
模式一:低复杂度——「过度思考」的陷阱
在问题非常简单时(例如,只有 3 个盘子的汉诺塔),出现了一个有趣的现象:不带思考链的标准 LLM,反而比带有复杂「思考链」的 LRM 更准确、更高效。
LRM 在这些简单任务上会生成大量冗长的「思考」步骤,但这些步骤往往在早期就已经找到了正确答案,后续的思考不仅毫无助益,反而可能引入错误。研究者将这种现象称为「过度思考」(overthinking)。这表明,在低复杂度下,模型的「思考」机制成了一种计算资源的浪费。
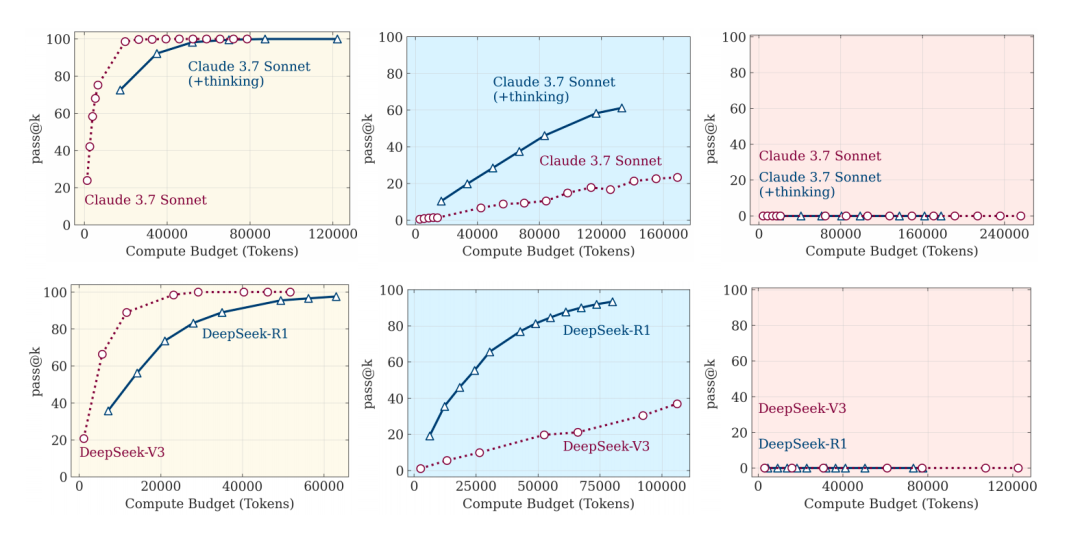
Image
△ 思考模型(蓝色)与非思考模型(红色)的性能对比。左:低复杂度;中:中等复杂度;右:高复杂度
模式二:中等复杂度——「思考」的价值显现
当问题复杂度适度增加时,「思考链」的优势开始显现。在这个区间,LRM 的表现明显优于标准 LLM。详尽的步骤分解和中间状态的生成,确实帮助模型更好地应对了增加的挑战,性能差距也随之拉开。
模式三:高复杂度——「集体崩溃」的结局
然而,这种优势是短暂的。一旦问题复杂度超过某个「临界点」,所有模型,无论是标准 LLM 还是 LRM,其性能都会彻底崩溃,准确率降至零。
LRM 的「思考」过程仅仅是推迟了崩溃的到来,但无法避免最终的失败。它们最终还是会遇到和标准模型同样的基础性限制。
Gary Marcus 点评道:看到像 Claude 3.7 Sonnet 和 o3-mini 这样顶尖的模型,在解决一个仅有 7-8 个盘子的汉诺塔问题上都如此挣扎,甚至无法保证正确性,这简直是「真正的尴尬」。
最反常的发现:越难,反而「想」得越少
如果说性能崩溃还在意料之中,那么接下来的发现则完全颠覆了直觉。
研究团队分析了模型在解题时,用于「思考」所花费的计算量(以 thinking tokens 的数量来衡量)。研究者发现,当问题变得极其困难,接近模型的崩溃点时,这些 LRM 反而开始减少它们的「推理努力」——即用于思考的计算资源(tokens)不增反降。
也就是说,面对最棘手的难题时,即便还有充足的计算预算,模型反而开始减少它们的思考量。
这就像一个学生在做一道极难的奥数题,他明明还有充足的考试时间,却在思考了一会儿后突然开始「摆烂」,写下的草稿越来越少。研究者强调,模型此时远未达到其最大输出长度的限制,拥有充足的 token 预算。
这一现象暗示了当前 LRM 在推理能力上存在着一个根本性的、内在的扩展限制(scaling limitation),而非简单的计算资源不足问题。它们的推理能力似乎存在一个内在的「天花板」,一旦问题复杂度触及这个天花板,整个思考机制就会失灵。
历史的回响:这不是一个新问题
Gary Marcus 进一步指出,苹果的这项研究,其实是对一个存在已久问题的强力印证。
泛化能力的「阿喀琉斯之踵」
Gary Marcus 自 1998 年以来就反复强调一个观点:神经网络(包括今天的 LLM)擅长在它们见过的训练数据分布内进行泛化,但一旦遇到分布外(out-of-distribution)的数据,它们的泛化能力就会迅速瓦解。
苹果的谜题实验完美地验证了这一点。汉诺塔的规则是固定的,但改变盘子数量就创造了一个模型在训练数据中很可能没见过的、新的问题实例。模型无法从 5 个盘子的成功经验中,真正「理解」并泛化出解决 8 个盘子问题的通用逻辑。这正是 Marcus 在其著作《代数思维》(The Algebraic Mind) 中所阐述的核心思想。
从早期的多层感知器到今天的LLM,这个根本性的弱点似乎从未被真正克服。苹果的论文再次验证了这个「分布外即失效」的古老魔咒。
「思维链」的虚假繁荣
Marcus 还将苹果的发现与亚利桑那州立大学计算机科学家 Subbarao (Rao) Kambhampati 的一系列研究联系起来。Rao 多年来一直对大模型的「思维链」持批判态度。
Rao 的研究表明:
- 思维链与最终答案可能脱节:模型生成的看似正确的思考过程,并不总能导向正确的最终答案。
- 思维链是不可靠的叙述:我们倾向于过度拟人化地将这些文本轨迹称为「思考」,但它们可能与模型内部的实际计算过程并不一致。
苹果的论文为 Rao 的批判增添了新的重磅证据,表明即使是最新一代的「思考模型」,其思维链在面对真正复杂的、分布外的问题时,依然是脆弱和不可靠的。这些模型的「思考」过程缺乏逻辑的严谨性和一致性,更像是一种基于概率的文本生成游戏。
这也引出了两个更深层次的问题,也是论文中最令人不安的发现:
喂给「标准答案」,它照样不会抄
研究者做了一个堪称「终极放水」的实验:在解决汉诺塔问题时,他们直接在提示(prompt)中提供了解决汉诺塔的完整递归算法伪代码。按理说,模型只需要一步步「执行」这个给定的算法即可。
然而,结果令人大跌眼镜:模型的表现没有任何改善,依然在相同的复杂度点上崩溃了!
论文作者之一 Iman Mirzadeh 在与 Marcus 的交流中也证实了这一点,他说:「我们的论点不是人类没有极限而 LRM 有,而是基于我们从它们的思考过程中观察到的,这个过程本身就不是逻辑和智能的。」
这强烈暗示,当前大模型的核心缺陷,可能不只是在于「规划」,更在于缺乏精确的、可靠的符号执行能力。它们连「照本宣科」都做不好。
表现飘忽不定,严重「偏科」
此外,模型在不同谜题上的表现差异巨大。例如,它能解决一个需要31步的汉诺塔,却搞不定一个仅需11步的过河问题。这很可能又回到了原点——训练数据的分布。模型也许对经典的、网上资料丰富的汉诺塔模式更熟悉,而对相对少见的过河问题则束手无策。
别找借口:AGI 不应复制人类的弱点
有人可能会提出一个反驳:人类在面对复杂的汉诺塔问题时也会犯错,这不正好说明大模型像人吗?这是否意味着 LLM 的失败情有可原?
Gary Marcus 对此提出了批评。他认为,这种辩护混淆了AGI的目标。我们发明计算机和计算器,正是为了克服人类在处理大型、繁琐问题上的不可靠性。
AGI 的愿景应该是结合人类的优点(如适应性和创造力)与机器的优点(如计算速度、记忆力和可靠性),而不是复制人类的弱点。
我们不想要一个在基础算术中会因为进位而出错的 AGI,就像人类有时会犯错一样。如果想在一个不可靠的系统上实现对齐或安全,那只能祝你好运。
人类的失败往往源于记忆力的限制,而拥有 G 字节级别内存的 LLM,不应该有同样的借口。
结论:走出幻觉,直面现实
苹果的最新研究深刻地探讨了当前大语言模型在核心推理能力上存在的局限:
- 通用性仍是奢望: 最前沿的 LRMs 仍未能发展出通用的、可扩展的解决问题的能力,其性能在超过某个复杂度阈值后会完全崩溃。
- 扩展性存在瓶颈: 模型的「思考努力程度」与问题难度不成正比,这暗示了其推理机制存在根本性的内在缺陷。
- 对数据的依赖超过逻辑: 模型的推理表现极度不一致,与其说是依赖纯粹的逻辑能力,不如说是高度依赖于训练数据中的模式记忆。
- 「思考」更像是近似而非精确: 正如 Rao 所说,LRM 更像是在「学习近似一个算法的展开过程」,而不是真正理解并执行算法。这在某些场景下可用,但在需要高可靠性的场合则完全不够。
这项工作并非要全盘否定大模型的进步。它们在编码、头脑风暴和写作等领域依然是强大的工具。这也不意味着深度学习或神经网络领域的终结。LLM 只是深度学习的一种范式。但这篇论文无疑为当前甚嚣尘上的 AGI 炒作泼上了一盆冷水,它促使我们必须正视当前技术路线的局限。

Image
就目前而言,我们必须承认,大语言模型的「思考」种依然充满了幻觉。也许认清幻觉,正是走向真正智能的第一步。
参考来源:
https://machinelearning.apple.com/research/illusion-of-thinking
https://garymarcus.substack.com/p/a-knockout-blow-for-llms
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-06-08,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号