炸裂!编码能力3倍暴涨!怎么用最划算?Opus 4.7重磅上线,又是碾压,遥遥领先于同行....

炸裂!编码能力3倍暴涨!怎么用最划算?Opus 4.7重磅上线,又是碾压,遥遥领先于同行....

AiAgent 马化云
发布于 2026-04-17 21:41:57
发布于 2026-04-17 21:41:57
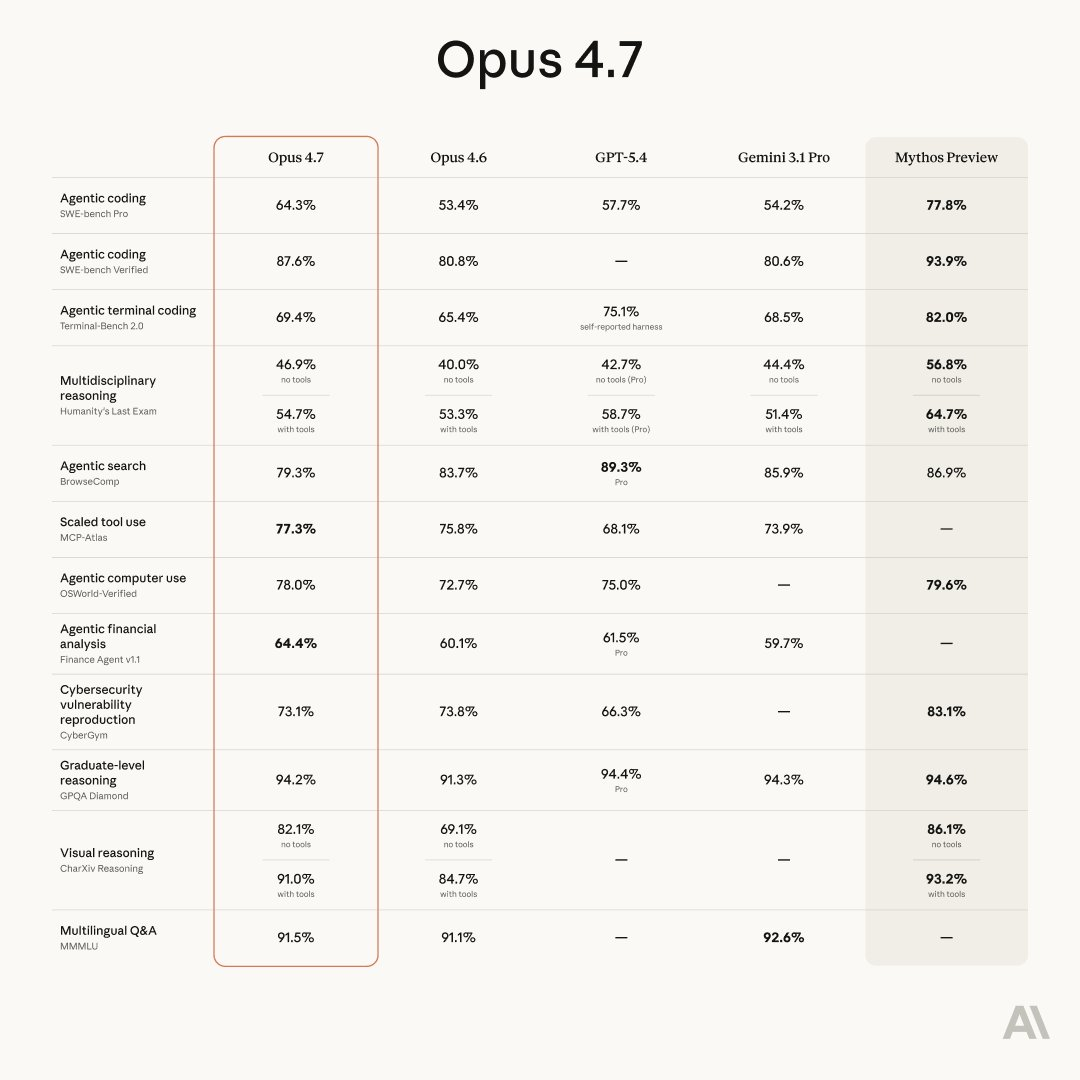
2026 年 4 月 16 日,Anthropic 连夜把 AI 大模型的基准测试榜单又给洗牌了。前几天还在讨论如何用其他模型平替 Claude Opus 4.6,结果新发布的 Opus 4.7 直接把天花板又往上抬了一大截。在 SWE-bench Pro 这类硬核编程基准测试中,Opus 4.7 把 OpenAI 的 GPT-5.4 和 Google 的 Gemini 3.1 Pro 都甩在了身后。这一波操作,仿佛是 Anthropic 在发布自家的“Mythos”之前,先扔出的一颗重磅炸弹。接下来,就一起从技术角度,把这台新“卷王”的底细扒个干净。
一、编码核弹
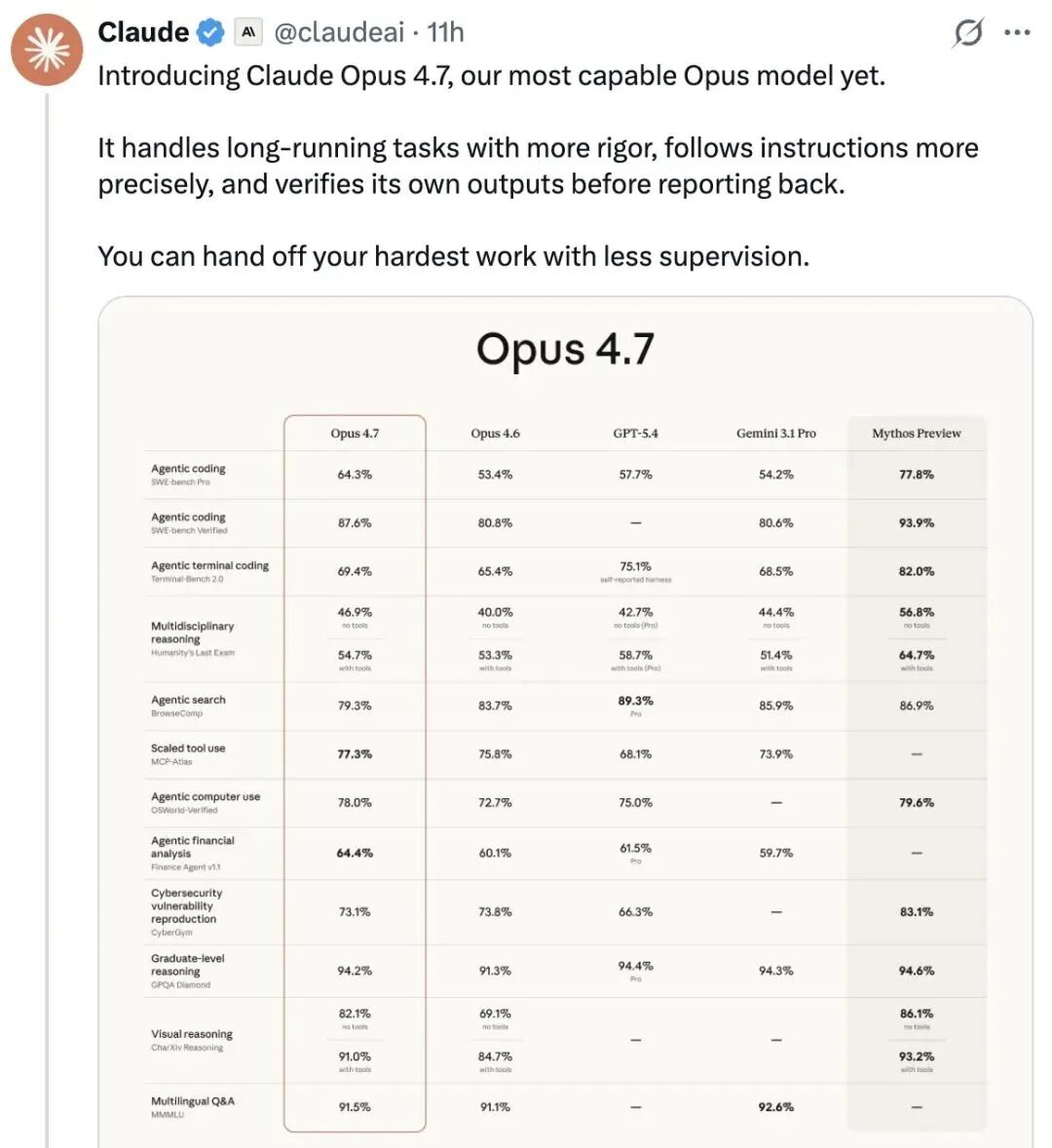
编程能力的提升,是 Opus 4.7 最显著的一张牌。
先看一组实测数据,对比相当直观:
基准测试项 | Opus 4.6 得分 | Opus 4.7 得分 | 提升幅度 |
|---|---|---|---|
SWE-bench Pro | 53.4% | 64.3% | 单代涨近 11 个百分点 |
SWE-bench Verified | 80.8% | 87.6% | 接近 7 个百分点 |
CursorBench | 58% | 70% | 12 个百分点 |
Rakuten SWE-Bench | 基数 | 基数 3 倍 | 解决的生产问题数量 |
SWE-bench Pro 是 AI 编程领域的“毕业大考”,覆盖四种编程语言的完整工程流水线,能测出模型在真实生产环境里修 bug、改代码的能力。
这意味着什么?那些以前要逐行盯着 AI 改的复杂需求,现在可能扔给它跑一晚上,第二天直接验收就行。Cursor 的内部测试也验证了这一点:同样难度的编码任务,4.7 搞定率超过 70%,而 4.6 只有 58%。
低 effort 的 Opus 4.7 差不多能媲美中 effort 的 Opus 4.6。也就是说,同样的任务,4.7 用更少的 token 就能达到相同甚至更好的效果,推理效率明显提升。官方还引入了“Adaptive Thinking”(自适应推理)机制,模型会自己判断每个步骤是否需要深度思考,简单问题快速响应,复杂问题才进入深度推理,资源分配更智能。

二、视觉觉醒
以前的 Claude 看图多少有点“近视”。4.6 看屏幕做渗透测试准确率只有 54.5%——勉强及格。
4.7 直接把清晰度拉满,长边像素从 1568px 提到 2576px,约 375 万像素,是前代的 3 倍以上。结果就是同一项测试,准确率飙到 98.5%。

带来的实际变化是:
- 能直接读懂 Figma 设计稿里的细节文字
- 能识别仪表盘上细微的数据波动
- 生成界面、做 PPT、排版文档,审美和细节精度同步起飞
视觉推理基准 CharXiv 从 69.1% 跳到 82.1%,从辅助功能变成了真正的生产力工具。
三、不再划水
长任务掉链子是 AI 的老毛病,4.7 的解法是:它会自己检查作业。
Vercel 团队发现,4.7 在处理复杂代码前会先“预演”,确认上下文无误再动手。这意味着:
- 以前需要在外面包一层重试逻辑的活,现在模型内部自己兜底
- 夜间跑的重构脚本,第二天早上基本可以放心验收
- Notion 的实际测试中,工具调用出错次数减少了 三分之二
- 法律 AI 平台 Harvey 的 BigLaw 基准测试中,直接拿下 90.9% 的超高分数
Auto 模式也全面开放给 Claude Code Max 用户,AI 可以自动决定哪些命令安全执行、哪些需要人工确认,批量跑任务时不用全程盯着。同时新增的 /ultrareview 命令,可以启动专门审查会话逐行检查代码,Pro 和 Max 用户每月免费三次。
四、快速上手
1. 网页版直接切
打开 Claude.ai 网页端,模型下拉菜单里选 Claude Opus 4.7,简单问题用默认模式,复杂编程任务建议切到 Agent 模式或 CLI 端使用。
2. Claude Code 更新
# 更新 Claude Code 到最新版(v2.1.111 以上)
claude update
# 或通过 npm
npm install -g @anthropic-ai/claude-code@latest
# 进入会话后切换模型
/model opus
更新后 opus 别名会自动指向 4.7。官方建议把 Claude 当成“委派任务的工程师”而非逐行指导的结对搭档,效果更好。
3. API 接入
import anthropic
client = anthropic.Anthropic(api_key="你的API密钥")
response = client.messages.create(
model="claude-opus-4-7-20260416", # 完整模型 ID
max_tokens=,
messages=[{"role": "user", "content": "写一个Python快速排序"}]
)
API 定价与 4.6 持平:输入
百万,输出
25/百万 token。但要注意:4.7 换了新 tokenizer,同样文字切出来的 token 可能多 1.0 到 1.35 倍,实际账单可能会略高一些。
4. 新增 Effort 档位
4.7 新增了 xhigh effort 档位,介于 high 和 max 之间,推理深度和延迟调节更细。Claude Code 全计划默认 effort 已提到 xhigh,交互式应用建议调回 high 或 medium 保持响应速度。
五、升级须知
升级前有几个细节值得留意:
变化点 | 具体影响 |
|---|---|
Tokenizer 调整 | 相同文本 token 数量增加 1.0~1.35 倍,实际成本可能变高 |
Prompt 兼容性 | 4.7 对指令更“字面化”,旧 prompt 可能需重新调优 |
默认 Effort | Claude Code 默认用 xhigh,延迟敏感场景建议调回 |
适用场景 | 编程/智能体任务提升明显,分析/写作等非代码场景反而偏生硬 |
上下文窗口 | 维持 100 万 token 不变 |
另外,4.7 是 Anthropic 当前“最强公开模型”,但内部还有一款专门针对网络安全场景的 Claude Mythos Preview,目前只开放给特定合作伙伴。
Claude Opus 4.7 的核心逻辑不是比谁更会写诗、谁更能编故事,而是让 AI 在执行长链路、高难度的工程任务时变得足够“靠谱”。视觉能力补上短板之后,从读代码、看设计稿到生成最终产物,一条自动化链路变得更可行。至于是不是“最强”,榜单上的数字已经给出了答案。不妨升级体验一下,看看它能不能帮你把那些最头疼的代码活,真正交给 AI 来扛。
#AI工具 #Claude #Opus4.7 #大模型 #编程神器 #GPT5 #Gemini #Anthropic #开发者必备 #技术前沿 #人工智能


本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号