智能表格识别技术:实现复杂表格内容的精准解析
原创
智能表格识别技术:实现复杂表格内容的精准解析
原创
中科逸视OCR专家
发布于 2026-05-06 18:04:52
发布于 2026-05-06 18:04:52
在数字化转型的浪潮中,企业每天处理着海量的纸质合同、财务报表、扫描单据以及网页数据。其中,表格作为一种承载高密度信息的载体,因其结构复杂(如合并单元格、跨页表格、嵌套表等),长期以来一直是自动化处理的难点。传统的OCR(光学字符识别)技术往往只能提取纯文本,丢失了关键的行列关系和布局信息,导致后续的数据清洗成本极高。
随着人工智能技术的飞速发展,新一代表格识别技术应运而生。它不仅仅是对文字的“看见”,更是对表格“逻辑”与“结构”的深度理解。本文将深入探讨这一技术的原理、核心能力及其在多场景下的广泛应用。
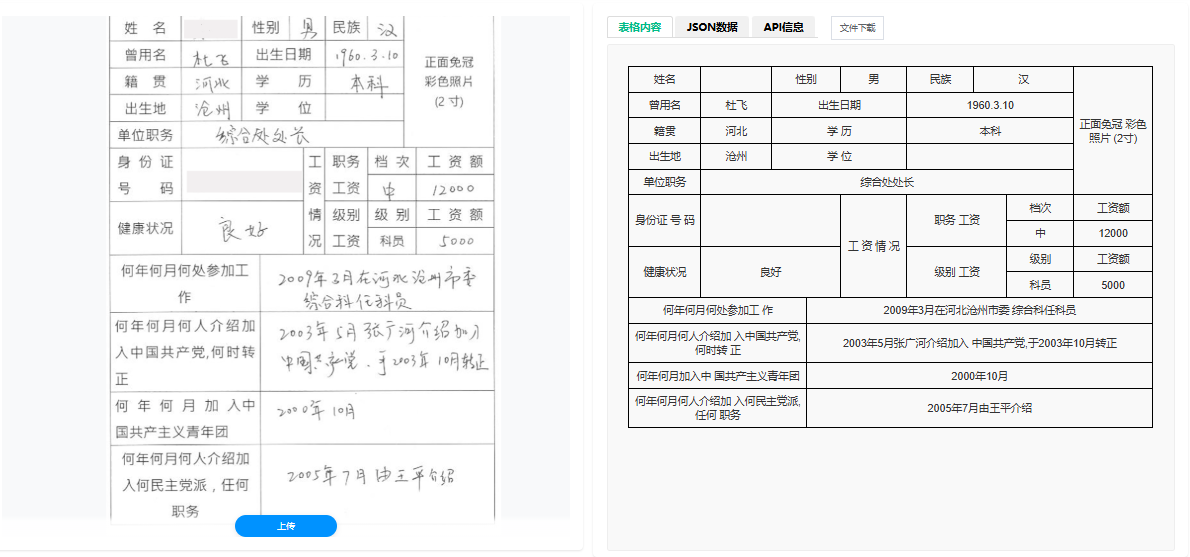
核心技术原理:从像素到语义的跨越
现代表格识别系统并非单一算法的产物,而是版面分析、多语种文字识别与深度学习结构预测技术的深度融合。其工作流程通常包含以下三个关键阶段:
1. 智能版面分析与检测
这是表格识别的第一步,也是决定后续精度的基础。系统利用基于深度学习的目标检测模型,对输入图像进行全局扫描。
- 区域定位:自动区分文本区、图片区、线条区和表格区。
- 网格重建:针对复杂的表格,算法会尝试还原其潜在的网格结构,识别出行、列、合并单元格(Rowspan/Colspan)的边界。即使面对手绘线模糊、背景杂乱的情况,也能通过特征提取准确锁定表格范围。
2. 高精度多语种文字识别
在确定表格区域后,内置的高性能OCR引擎开始工作。与传统OCR不同,现代表格识别引擎具备极强的抗干扰能力:
- 多语种支持:能够同时识别中文、英文、日文、韩文、法文等多种语言,甚至混合排版的文字,无需人工切换模型。
- 复杂字形处理:针对手写体、艺术字体、低分辨率扫描件中的模糊字迹,采用端到端的识别网络,显著提升识别率。
- 方向校正:自动纠正倾斜、旋转的文字,确保内容被正确读取。
3. 结构解析与还原
这是表格识别的“灵魂”所在。系统将识别出的文本框坐标与其所在的行列逻辑进行映射。
- 语义关联:利用图神经网络(GNN)或序列标注模型,判断哪些文字属于同一行、同一列,从而构建出完整的二维数据结构。
- 布局还原:不仅输出Excel或JSON格式的结构化数据,还能生成HTML或LaTeX代码,完美复刻原表的视觉样式(包括边框、对齐方式、合并单元格)。
- 异常处理:对于跨页表格,系统能根据上下文逻辑自动拼接;对于无边框表格,则通过文字间距和语义对齐推断结构。
应用场景:全场景覆盖,助力行业数字化
表格识别技术具有极强的泛化能力,已广泛应用于多个关键领域,有效解决了各行业长期存在的“文档数字化难”痛点:
金融与保险行业:
- 在处理银行流水单、财务报表、保险理赔单据时,系统能快速提取复杂的金额、日期及科目信息,自动匹配财务规则,大幅缩短人工录入时间,降低合规风险。
政务与公共服务:
- 针对各类行政审批表、社保登记表、户籍档案等半结构化文档,技术可实现批量自动化归档与检索,提升政府办事效率,推动“一网通办”进程。
物流与供应链:
- 面对种类繁多、格式各异的运单、装箱单和发票,系统可快速提取货物名称、数量、重量及目的地信息,实现物流信息的实时追踪与库存管理自动化。
教育与科研:
- 在学术论文、实验数据记录本的处理中,该技术能帮助研究人员快速整理历史数据,构建科研数据库,加速知识沉淀与分析。
表格识别技术正在重塑我们处理文档的方式。它将原本沉睡在纸张和PDF中的“死数据”,转化为了流动在数字系统中的“活资产”。通过内置先进的版面分析和多语种识别技术,该方案不仅实现了复杂表格内容的精准解析,更完成了从“看图说话”到“读懂逻辑”的质的飞跃。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号