Kubernetes 存储高可用实战:Longhorn 故障演练与恢复

Kubernetes 存储高可用实战:Longhorn 故障演练与恢复

一根头发丝的宽度
发布于 2026-05-06 20:30:35
发布于 2026-05-06 20:30:35
一、实验背景
在搭建 Kubernetes 实验环境的过程中,我在集群中部署了一个 MySQL 服务,并使用 Longhorn 作为持久化存储。
原本只是为了让数据库能够在 Kubernetes 集群中稳定运行,但在部署完成后,产生了一个很实际的问题:
如果数据库所在的节点突然宕机,会发生什么?
- Pod 是否能够被重新调度到其他节点
- 数据卷能否重新挂载
- 数据库是否可以正常启动
- 数据会不会丢失
正好借这个机会,做一次完整的故障演练。
整个过程并没有特别复杂的设计,只是按照实际环境中的操作流程,一步一步进行验证,同时把过程中遇到的各种问题记录下来,比如:
- Volume 无法重新挂载
- Multi-Attach 错误
- Longhorn 副本降级
- 副本重新构建
通过这次实践,不仅验证了分布式存储在 Kubernetes 环境中的高可用能力,也对 数据库在云原生架构中的运行方式和故障恢复机制有了更直观的理解。
本文记录的,就是这一整个实践过程以及遇到问题时的排查和解决方法。
二、实验架构
实验环境为一个三节点 Kubernetes 集群:
k8s-master
k8s-node01
k8s-node02
k8s-node03
MySQL 通过 StatefulSet 部署:
mysql-0
mysql-1
每个 Pod 使用一个 PVC,由 Longhorn 提供存储。
Longhorn 官方的存储架构如下图所示:
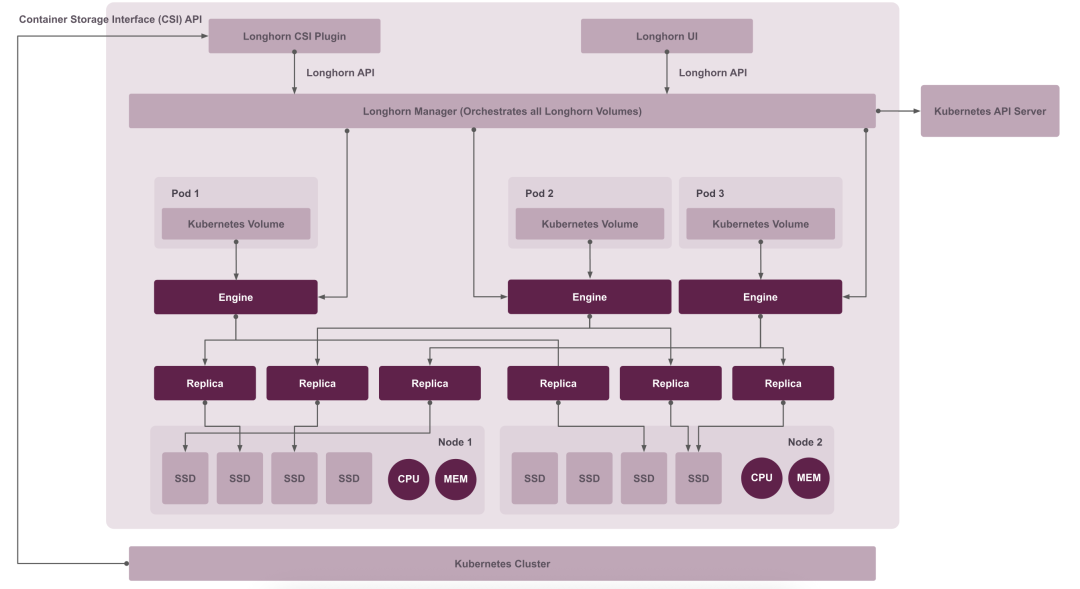
也就是说:同一份数据会在多个节点保存副本。
二、故障演练目标
本次实验验证以下能力:
节点宕机
↓
Pod 自动迁移
↓
存储重新挂载
↓
数据库恢复
↓
副本自动重建
三、初始状态
首先查看 MySQL Pod:
kubectl get pod -o wide
结果:
mysql-0 Running k8s-node01
mysql-1 Running k8s-node03

进入 MySQL 查看数据:
SHOW DATABASES;
结果:
company
testDB
显示之前创建的数据说明数据库运行正常。
四、模拟节点宕机
关闭运行 mysql-0 的节点k8s-node01:
sudo init 0
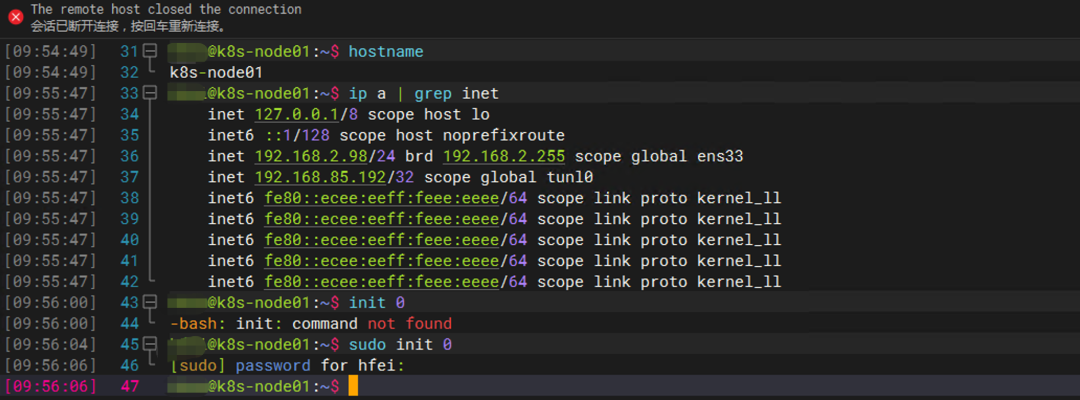
Kubernetes 很快检测到节点异常:
kubectl get nodes
结果:
k8s-node01 NotReady
五、Pod 自动迁移
StatefulSet 控制器开始重新创建 Pod。
查看状态:
kubectl get pod -o wide

结果:
mysql-0 ContainerCreating k8s-node02
mysql-1 Running k8s-node03
说明:
mysql-0 已经迁移到 node02
到这里 Kubernetes 的 自愈能力正常工作。
但新的问题开始出现。
六、问题一:Multi-Attach 错误
Pod 一直无法启动。
查看事件:
kubectl describe pod mysql-0
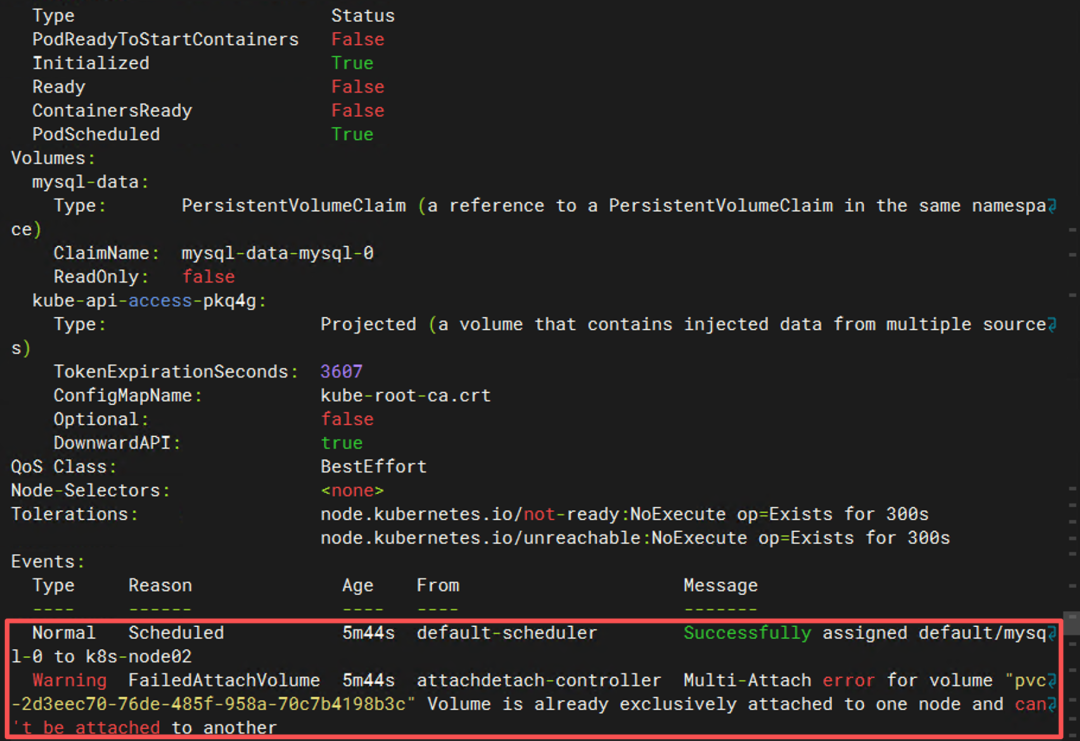
出现错误:
Multi-Attach error
Volume is already exclusively attached
原因:
node01 宕机
Volume 仍然被标记为已挂载
因此 node02 无法挂载该 Volume。
七、解决方法:Detach Volume
在 Longhorn 控制台中找到对应 Volume。
执行:
Detach
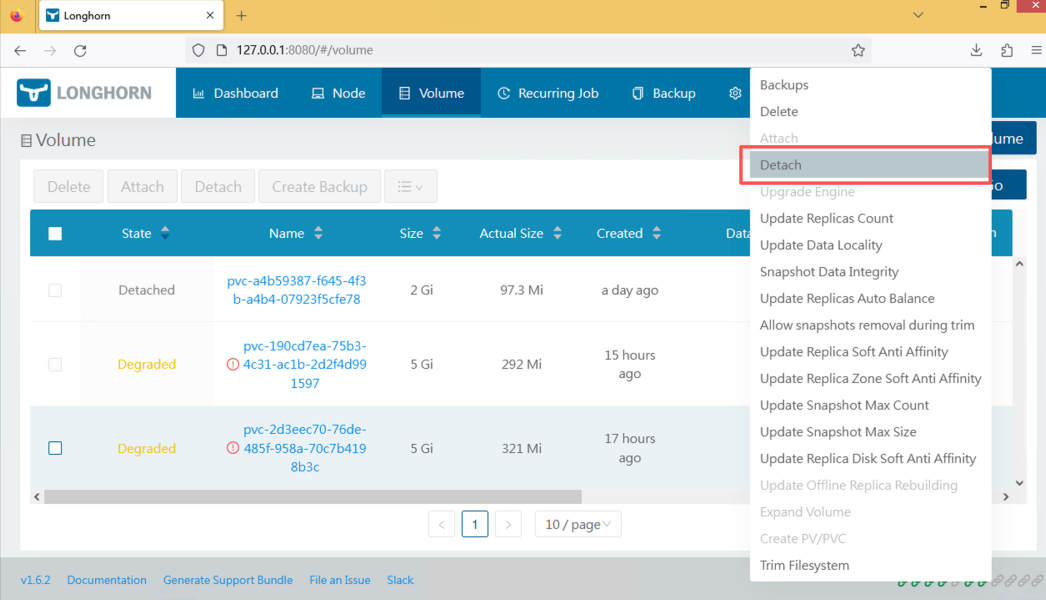
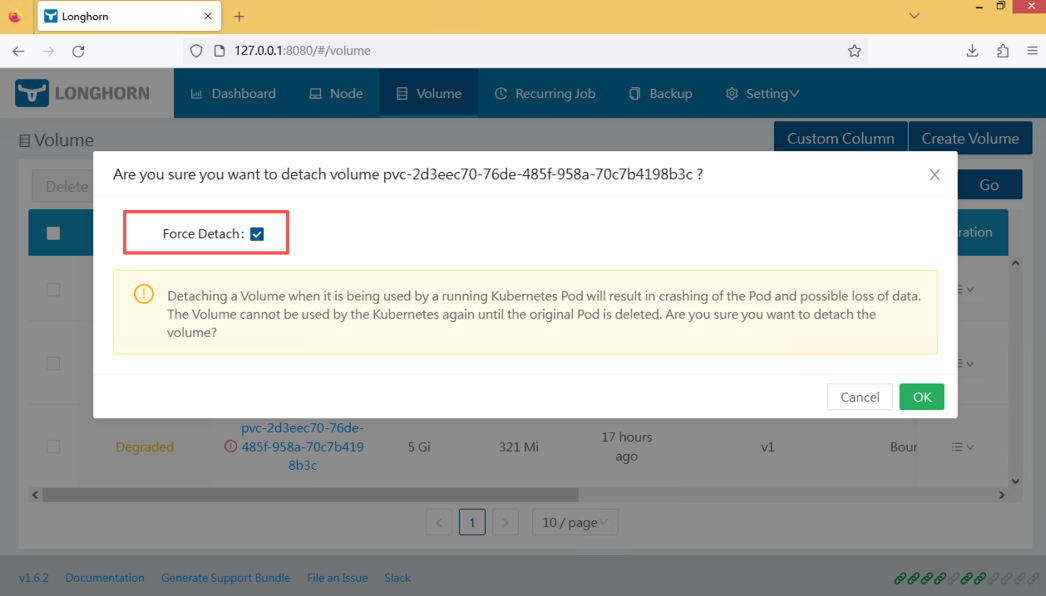
释放旧节点的挂载。
八、问题二:Volume 未自动 Attach
Volume Detach 后 MySQL 仍然无法启动。
查看日志:
kubectl logs mysql-0

出现:
/var/lib/mysql Input/output error
Longhorn 状态:
State: Detached
说明:
Volume 并没有自动重新 Attach
九、解决方法:手动 Attach
在 Longhorn 控制台执行:
Attach → k8s-node02
随后 Kubernetes 完成:
Volume Mount
Container Start
Pod 成功运行:
mysql-0 Running

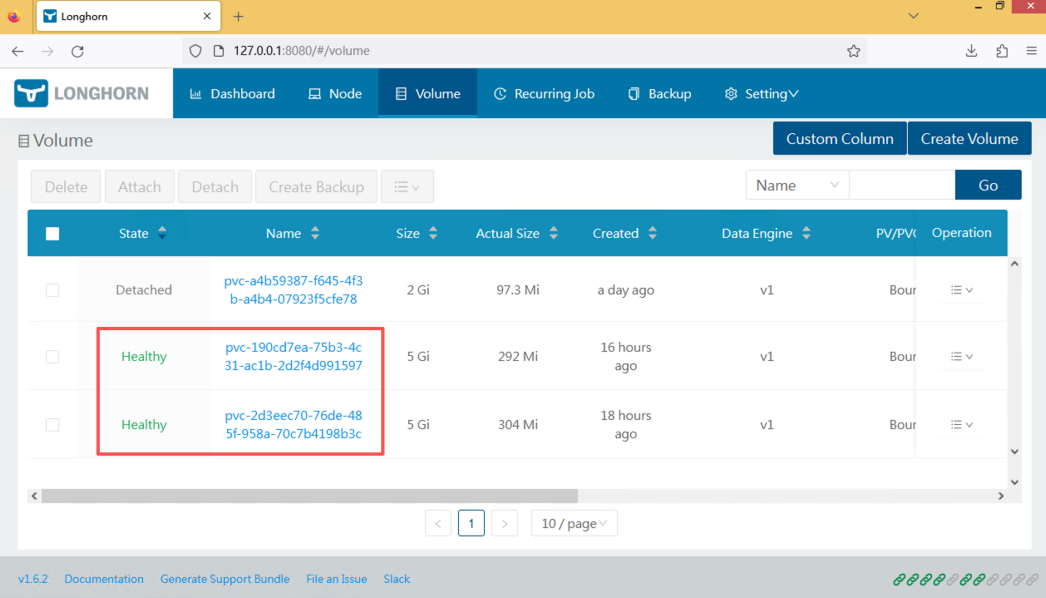
十、数据验证
进入 MySQL:
SHOW DATABASES;
结果:
company
testDB
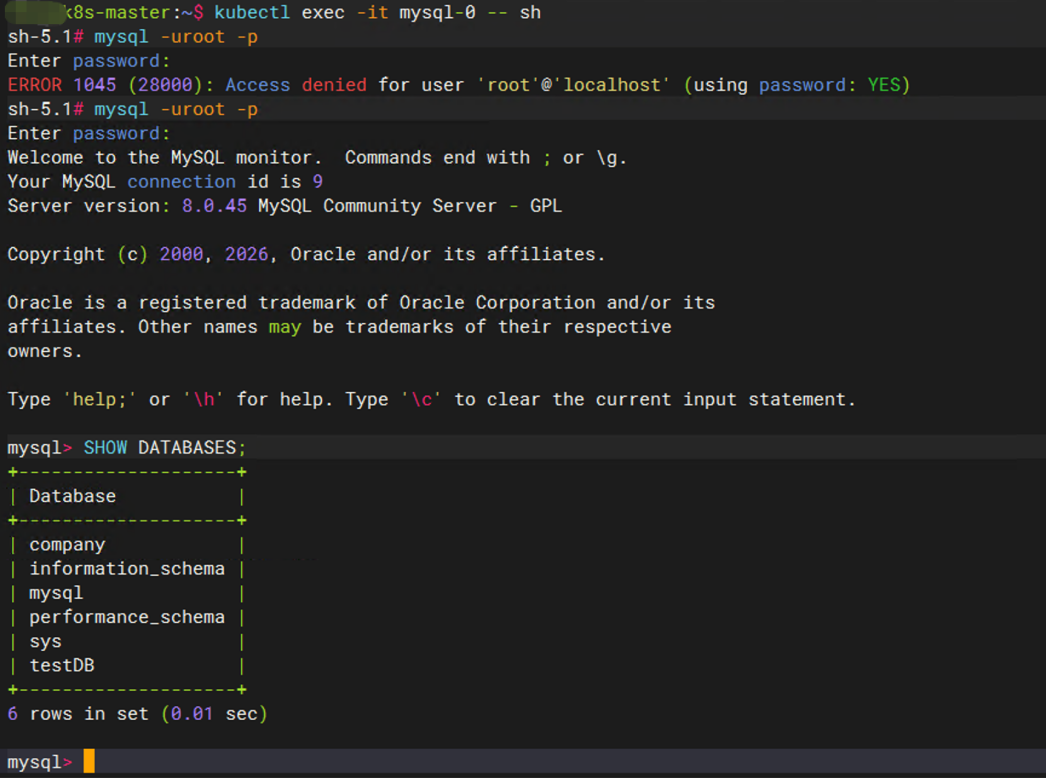
说明:数据完全没有丢失。
十一、问题三:Volume Degraded
虽然数据库已经恢复,但 Longhorn 显示:
Health: Degraded
Replica Scheduling Failure
原因是:
原本副本分布为:
node01
node02
node03
但 node01 宕机后:
node01 副本丢失
只剩一个副本。
因此 Volume 状态为:
Degraded
十二、副本自动重建
重新启动 node01。
Longhorn 自动开始:
Replica Rebuild
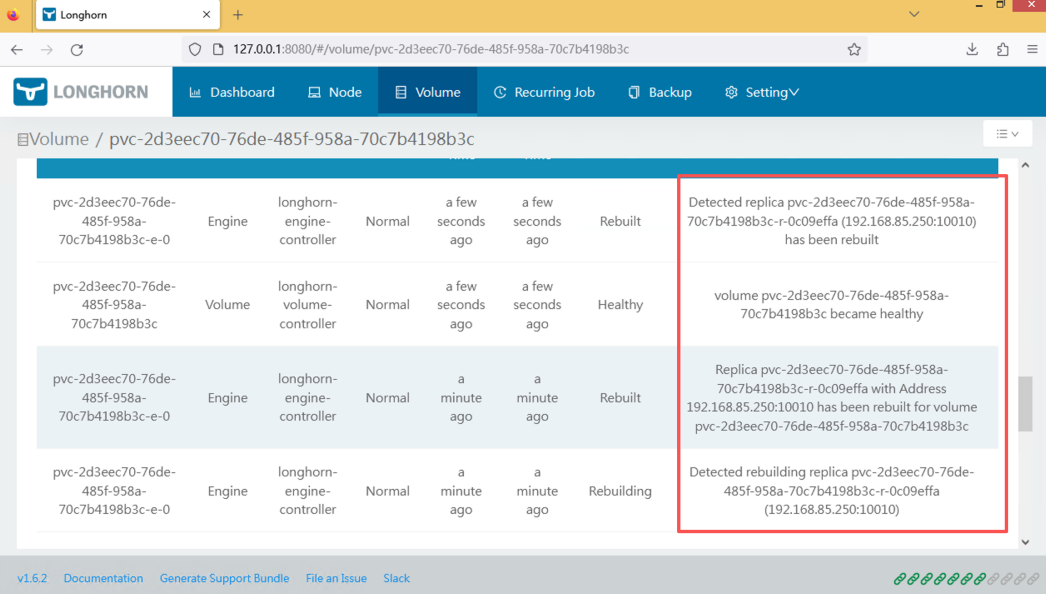
系统会将数据重新同步到新的副本节点。
完成后:
Health → Healthy
整个恢复过程自动完成。
十三、故障恢复时间线
整个故障恢复过程可以总结为:
节点宕机
↓
Pod 消失
↓
StatefulSet 创建新 Pod
↓
Pod 调度到新节点
↓
Multi-Attach 错误
↓
Detach Volume
↓
Attach 新节点
↓
MySQL 启动
↓
Replica Rebuild
↓
Volume Healthy
十四、总结
Pod + Volume 调度流程图如下:

通过这次故障演练,可以验证:
1️⃣ Kubernetes 可以自动恢复数据库 Pod 2️⃣ Longhorn 提供持久化存储能力 3️⃣ 节点宕机不会导致数据丢失 4️⃣ 存储副本可以自动重建
这也是云原生架构的重要价值:
节点故障 ≠ 服务故障
当然,在实际运维中仍然需要理解系统的故障机制。
这次实验记录的排障过程,就是一次典型案例。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-13,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号