SKILL能解决MCP的token冗余,但为什么又说二者不是对立关系而是互补关系呢?

SKILL能解决MCP的token冗余,但为什么又说二者不是对立关系而是互补关系呢?

用户1493530
发布于 2026-05-06 21:31:13
发布于 2026-05-06 21:31:13
本文来自我在知乎上的一个回答,原问题是:
SKILL能解决MCP的token冗余,但为什么又说二者不是对立关系而是互补关系呢? 引入skill能够解决mcp带来的一次加载所有tool信息的上下文的臃肿的问题,可看到很多篇博客都说mcp和skill可以互补,那不相当于还是引入mcp导致上下文臃肿了吗,那这里不也是没节省token吗?这里有点不太理解,二者真的是互补的吗?还是说有其他方式,比如通过某些设计能够同时引入二者且满足解决token冗余呢?
题主的困惑非常精准,我第一次看到各种博客说"互补"的时候也觉得逻辑不自洽。但深入研究之后发现,问题出在大多数文章没有把"互补"的具体机制讲清楚,让人误以为是两套东西简单叠加使用。实际上 Skill 对 MCP 的 token 优化,靠的是一个很具体的架构设计:渐进式披露(Progressive Disclosure)。
我尽量把这个事情掰开了讲。
先搞清楚 MCP 的 token 膨胀到底有多严重
MCP 的工作机制是这样的:客户端连接到 MCP Server 之后,会调用 tools/list 把这个 Server 上所有工具的完整定义拉下来,包括工具名、描述、完整的 JSON Schema 参数定义,然后把这一大坨东西序列化塞进 LLM 的 system prompt 里。模型得先"看到"所有可用工具,才能决定用哪个。这就是所谓的 eager loading(饥饿加载)。
这个设计在工具少的时候没什么问题,但一旦接入多个 Server,token 消耗就爆炸了。有开发者实测过,光一个 GitHub MCP Server 暴露 91 个工具就吃掉大约 48000 个 token,占 Claude 200K 上下文窗口的 24%。更夸张的案例是某人的完整 MCP 配置消耗了 82000 个 token,占上下文的 41%,还没开始对话呢,可用空间就只剩 5.8% 了。有人在 GitHub issue 里吐槽:接了四个 MCP Server 之后问一句"2+2等于几",光 token 成本就花了大约 $0.21。
说白了,MCP 的 token 膨胀不是设计缺陷,而是"先看菜单再点菜"这个模式在工具数量上来之后的必然代价。你接的 Server 越多、每个 Server 暴露的工具越多,这份"菜单"就越厚。
Skill 省 token 的核心机制:三层渐进式披露
Agent Skills(就是题主说的 SKILL)是 Anthropic 2025 年 12 月在 agentskills.io 发布的开放标准,后来被 OpenAI Codex CLI、GitHub Copilot、Google Gemini CLI、Cursor 等一众工具采纳。搞清楚一个关键前提:Skill 不是工具,而是教 Agent 怎么用工具的知识包。它的载体是一个 SKILL.md 文件,里面包含 YAML 元数据头和具体的操作指南。
Skill 省 token 的秘密在于它把信息分成了三层,按需加载:
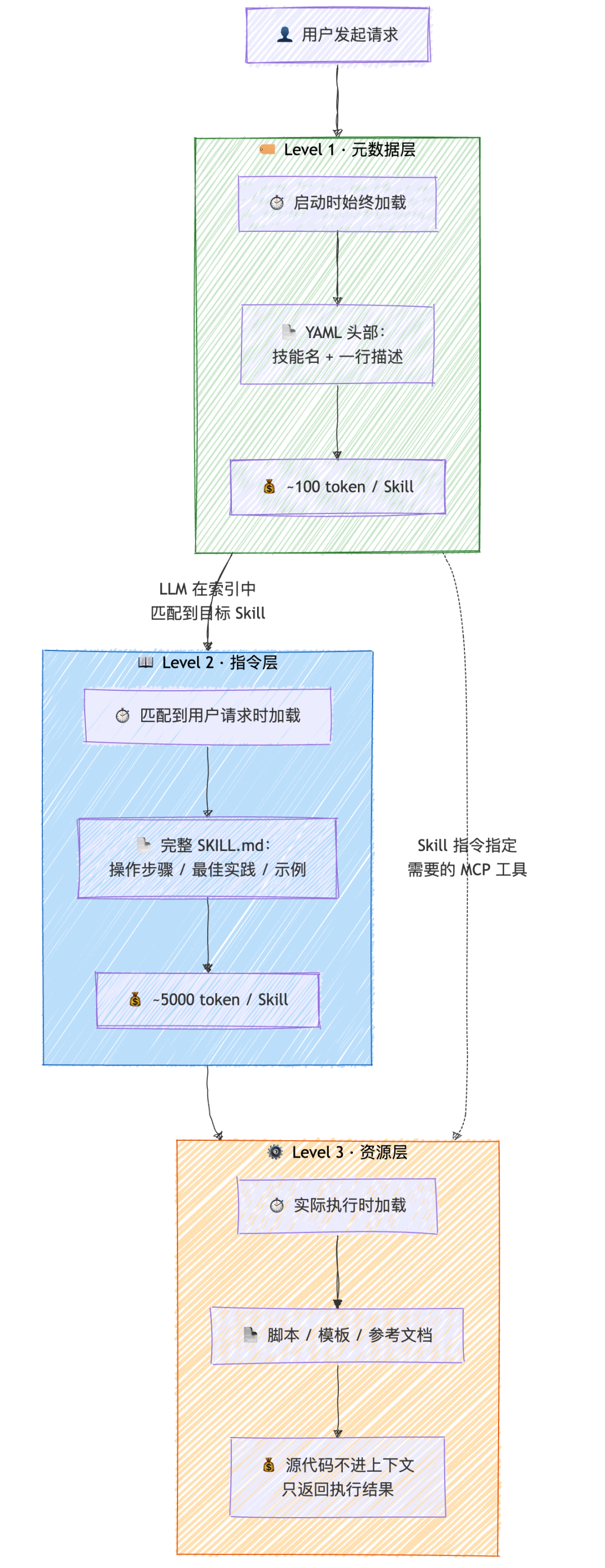
三层渐进式披露架构
这个机制在 DeepWiki 的文档里被描述为 Browse → Load → Use 生命周期。实测数据是:每个 Skill 的初始加载从 16000 token 降到 500 token,降幅 96.9%。Flask 框架的作者 Armin Ronacher 说得很到位:Skill 并不会往上下文里加载工具定义,工具定义还是那些工具定义,Skill 教的是怎么更好地使用这些工具。
回到核心问题:既然互补,token 到底省在哪了?
这是题主真正的困惑所在,也是大多数博客没讲清楚的地方。我换一个方式来解释。
假设你有一个企业级 Agent,接了 10 个 MCP Server,总共暴露 400 个工具。下面这张图直接对比两种方案的 token 开销:
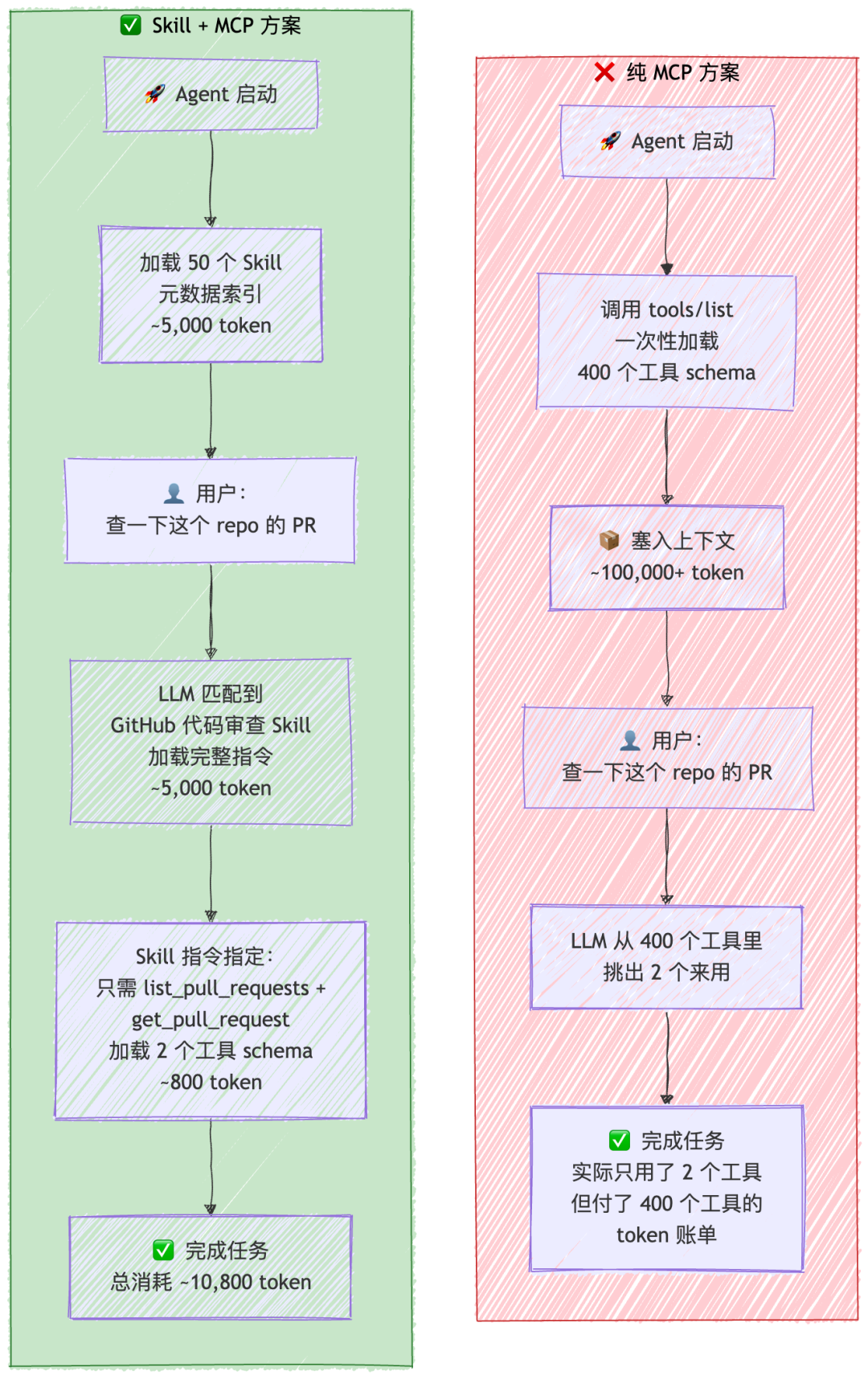
纯 MCP vs Skill + MCP 方案对比
看到关键区别了吗?纯 MCP 方案是 "先把 400 道菜的菜单全读一遍,再点 2 道菜"。Skill + MCP 方案是 "先翻目录找到川菜那一页,再从 8 道川菜里点 2 道"。菜单(MCP schema)还是同一份菜单,但你读的量从 400 道降到了 2 道。
所以回答题主的核心问题:引入 Skill 之后 MCP 的工具 schema 并没有消失,但它们不再被一次性全量加载了。Skill 的元数据索引(5000 token)替代了 MCP 的全量 schema(100000+ token)作为初始上下文的内容,然后只有被 Skill 指令明确指定的那几个 MCP 工具才会被按需加载。净 token 消耗从 100000+ 降到了约 11000,省了 90% 左右。
Google Cloud 的高级工程师、MCP 核心维护者 Kurtis Van Gent 有个比喻特别到位:拿 MCP 和 Skill 比较,就像问 TCP 和 JSON 哪个更好,问题本身就不成立,因为它们在不同的架构层。MCP 解决的是 N×M 集成问题(N 个 Agent × M 个数据源,从 N×M 个定制连接器降到 N+M 个标准化连接器),Skill 解决的是 上下文饱和问题(通过渐进式披露控制信息密度)。
除了 Skill,还有哪些方案在解决同一个问题
题主问到"是否有其他方式能同时引入二者且解决 token 冗余",答案是确实有好几种,而且有些已经在生产环境跑起来了。
分层工具模式(Layered Tool Pattern)。 Block 的 Goose 团队把整个 Square API 平台 200 多个 endpoint 压缩成了 3 个 MCP 工具:get_service_info(发现)、get_type_info(规划)、api_call(执行)。Agent 通过这三层逐步发现需要的具体 endpoint,而不是一开始就把 200 多个 endpoint 的 schema 全加载。DatoCMS 也用了类似方案,把 150+ endpoint 缩减到 10 个工具。
RAG-MCP 语义检索。 把所有工具描述 embedding 之后存到向量索引里,每次请求只检索语义上最相关的几个工具。学术论文 RAG-MCP 的测试结果是 token 减少超过 50%,工具选择准确率从 13.62% 提升到 43.13%,提高了 3 倍。Rocket Connect 的实现做到了 89% 的 token 缩减和 62% 的响应速度提升。
代码执行模式(Code Execution Mode)。 这个思路更激进:不把工具 schema 加载到上下文里,而是让 Agent 直接写代码调用 MCP 工具,在沙盒环境里执行。数据在工具之间直接流转,不经过 LLM 上下文窗口。Anthropic 自己的基准测试显示:150000 token 降到 2000,缩减 98.7%。
MCP Tool Search。 这是 Claude Code 在 2026 年 1 月内置的功能。当 MCP 工具描述超过上下文的 10% 时自动激活,把所有工具定义替换成一个 tool_search 元工具(大约 500 token),按需用正则或 BM25 检索加载 3-5 个相关工具。实测效果是从 57000 token 降到 8700 左右,缩减 85%。
MCP 协议自身也在演进。 MCP 规范的 PR #1928 提出了标准化的 searchTools 端点,只返回工具名和摘要,需要完整 schema 时再调 tools/get_schema 按需获取,预计可以省 91% 的 token。这说明 MCP 社区自己也意识到了 eager loading 的问题,正在从协议层面修复。
一句话总结
Skill 和 MCP 的互补关系,本质上是"索引层"和"执行层"的配合。 下面这张架构图能帮你建立一个更清晰的心智模型:
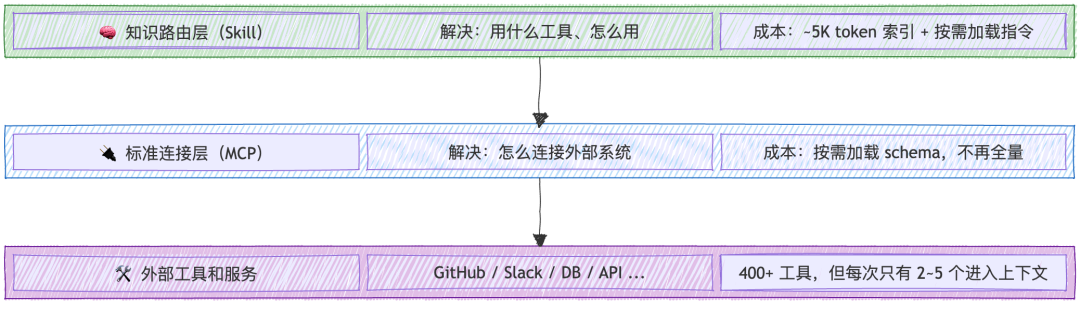
Skill 和 MCP 架构分层
Skill 充当轻量级的知识路由,确保只有当前任务需要的那几个 MCP 工具 schema 进入上下文,而不是把整个工具目录一股脑塞进去。所以"互补"这个词确实容易让人误解,更准确的说法应该是:Skill 是 MCP 的上下文管理层,它让 MCP 从"广播模式"变成了"路由模式"。就像计算机网络从早期的广播域演进到路由网络一样,工具架构也需要一个路由层来突破上下文窗口的物理限制。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号