企业软件的AI深水区:OODER 如何让重量级业务组件在自然语言中重生
原创
企业软件的AI深水区:OODER 如何让重量级业务组件在自然语言中重生
原创
OneCode
发布于 2026-05-11 18:50:19
发布于 2026-05-11 18:50:19

一、问题的本质:AI懂代码,但不懂你的组件
2025年,大模型已经能写出精妙的算法、生成完整的前端页面,甚至帮你重构整个项目架构。但当你对它说"帮我做一个请假审批表单"时,它给出的往往是一段通用的HTML代码——而不是你企业内部已经打磨了十年、集成了二十个业务规则、对接了三个审批引擎的那个 LeaveRequestForm 组件。
这不是AI不够聪明,而是AI没有看到你的积累。
企业软件的核心竞争力,从来不在于"能写出代码",而在于沉淀了多少经过实战检验的业务组件。一个成熟的ERP系统可能有上千个配置化的业务组件——表单、表格、树形导航、图表仪表盘、审批流、报表模板——每一个都承载着特定行业的业务逻辑和交互经验。
问题在于:这些组件往往技术陈旧、接口不统一、难以集成到现代化的AI工具链中。
本文的核心命题:如何将企业沉淀的重量级业务组件进行架构升级,使其既能被AI理解和调用,又不丢失业务深度?
二、架构全景:OODER A2UI 的五层能力模型
我们提出的解决方案是 OODER A2UI(AI-to-UI)框架——一个将自然语言、AI Agent、组件体系、可视化设计器深度整合的企业级架构。其核心能力分为五层:
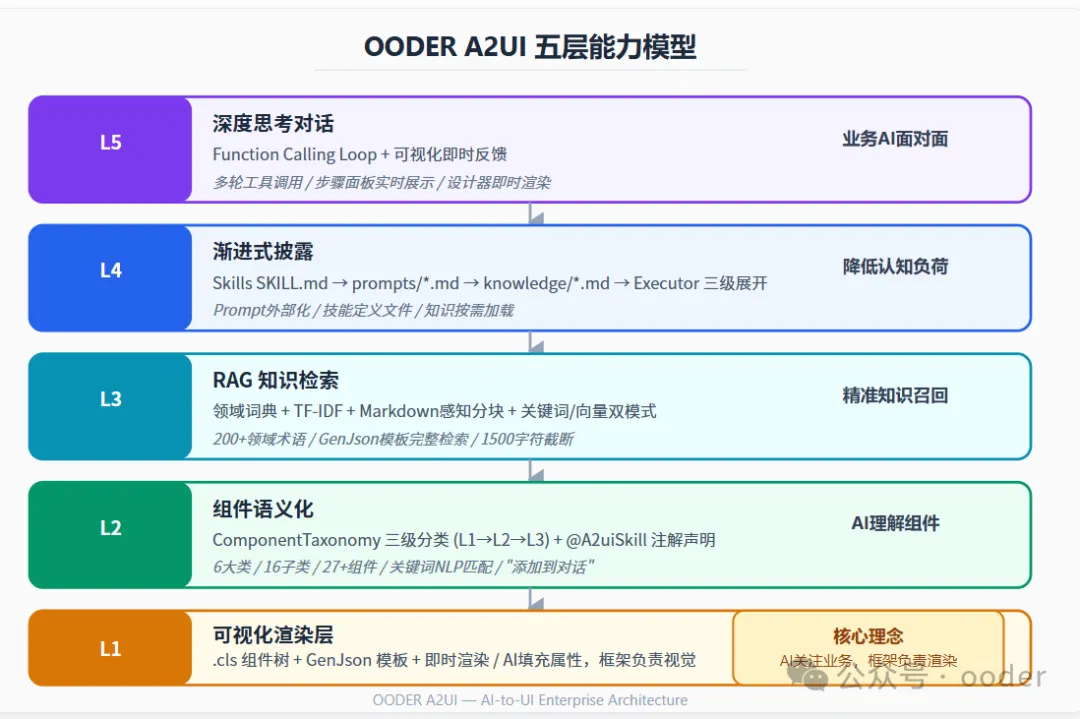
图1:OODER A2UI 五层能力模型架构图
每一层都解决一个关键问题。下面我们逐一展开。
三、L1:更彻底的可视化——AI填充属性,即时渲染高级组件
3.1 传统AI生成的困境
当用户说"做一个员工信息表单",通用AI会生成一段HTML:
<!-- AI 生成的通用代码 -->
<div class="form-group">
<label>姓名</label>
<input type="text" class="form-control">
</div>
<div class="form-group">
<label>部门</label>
<select class="form-control">...</select>
</div>这段代码能用,但它:
- 没有企业统一的样式规范
- 没有对接后端数据源
- 没有表单验证规则
- 没有审批流程集成
- 无法复用企业已有的 EmployeeForm 组件能力
3.2 OODER 的解法:AI 只关注业务,框架负责渲染
OODER 采用 .cls 文件定义页面组件——一种结构化的JSON组件树:
{
"alias": "leaveRequestForm",
"key": "ood.Module",
"className": "view.LeaveRequestForm",
"moduleViewType": "FORMCONFIG",
"properties": { "caption": "请假申请" },
"children": [
{
"alias": "mainLayout",
"key": "ood.UI.Layout",
"properties": {
"items": [
{ "id": "before", "pos": "before", "size": 60 },
{ "id": "main", "pos": "main", "size": 80 },
{ "id": "after", "pos": "after", "size": 100 }
],
"type": "vertical"
},
"children": [
{
"alias": "formArea",
"key": "ood.UI.Form",
"target": "main",
"properties": { "caption": "请假信息", "dock": "fill" },
"children": [
{
"alias": "leaveType",
"key": "ood.UI.ComboInput",
"properties": {
"name": "leaveType",
"caption": "请假类型",
"formField": true,
"value": ""
}
}
]
}
]
}
]
}AI不需要知道如何画表单、如何布局、如何绑定事件——它只需要填写属性。框架根据 moduleViewType 自动选择渲染模板,根据 key 自动匹配组件类,根据 properties 自动配置组件行为。
这就是"更彻底的可视化"的含义:AI关注业务语义,框架负责视觉呈现。
3.3 三级分类体系:让AI理解"该用哪个组件"
为了让AI能正确选择组件,我们设计了 ComponentTaxonomy 三级分类体系:
// L1 大类(6个)
public enum L1Category {
DATA_DISPLAY("data-display", "数据展示"), // 表格、树、卡片
DATA_INPUT("data-input", "数据录入"), // 表单、输入
NAVIGATION("navigation", "导航交互"), // 导航树、标签页
LAYOUT("layout", "布局容器"), // Block、Panel、Layout
CHART("chart", "图表可视化"), // ECharts、FCharts
SPECIAL("special", "特殊组件"); // SVG画布、模块引用
}
// L2 子类(16个)
// L3 具体组件(27个)每个L3组件携带关键词和示例,用于NLP意图匹配:
registerL3Component("TreeGrid", "data-display.table", "列表",
GRIDCONFIG, 10, DESKTOP,
Arrays.asList("表格", "列表", "树表", "grid", "table", "数据表格", "树形表格"),
Arrays.asList("创建一个数据表格", "做一个列表展示", "生成树形表格"));当用户说"做一个数据表格"时,系统通过关键词匹配找到 TreeGrid 组件,再通过 NlpComponentBuilder 自动生成完整的 .cls 结构。
四、L2:"将组件添加到对话"——业务组件零距离接触AI
4.1 功能设计
这是OODER A2UI最具创新性的特性之一。在RAD设计器中,用户可以右键点击任意组件,选择"添加到对话",该组件的完整JSON定义会作为上下文注入到AI对话中。
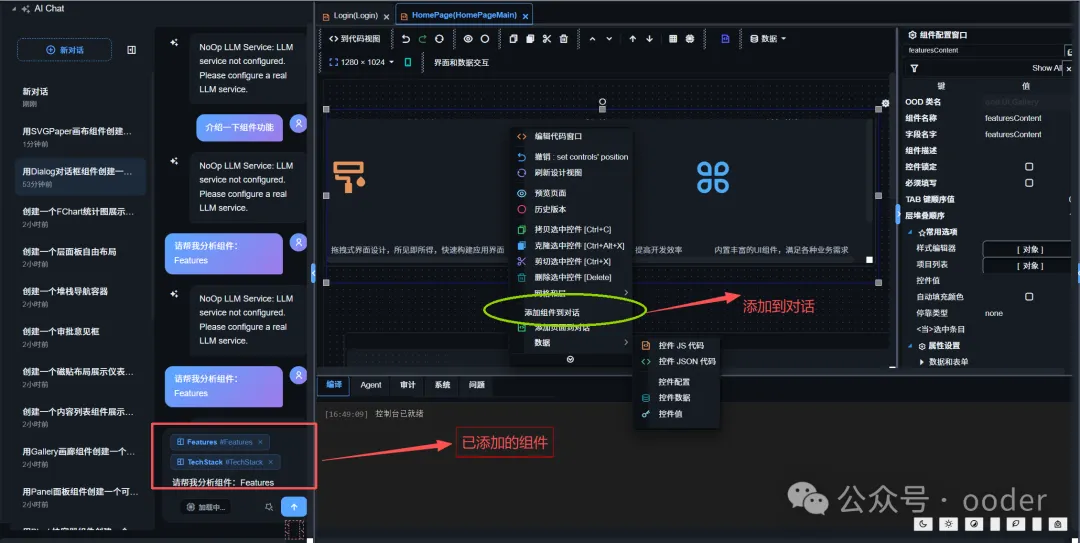
前端实现位于 NlpChatInline.js:
// 用户选中组件后,右键菜单触发
_addComponentContext: function (componentData) {
var host = this;
var attachments = host._state.attachments || [];
// 将组件的完整JSON定义作为附件
attachments.push({
type: 'component',
name: componentData.alias || componentData.name,
data: componentData,
// 自动生成 Markdown 格式的组件描述
markdown: host._formatComponentAsMarkdown(componentData)
});
host._state.attachments = attachments;
host._renderAttachments();
// 显示提示:组件已添加到对话上下文
ood.message('已将组件 ' + componentData.alias + ' 添加到对话');
}4.2 后端处理:上下文注入
当消息发送时,附件会被格式化为Markdown注入到系统提示词中:
// PromptEngine.java
if (contextAttachments != null && !contextAttachments.isEmpty()) {
prompt = prompt + contextAttachmentTemplate
.replace("{attachments}", contextAttachments);
}注入格式(context-attachment.md):
## 用户附加的上下文信息
以下信息是用户主动添加到对话中的上下文,请优先参考这些信息:
{attachments}4.3 价值:零损耗的业务知识传递
传统方式下,AI要理解一个业务组件,需要:
- 阅读组件源码(几百到几千行)
- 理解组件的属性、事件、数据流
- 推断组件的业务语义
而"添加到对话"功能,直接将组件的结构化定义交给AI,AI可以:
- 立即知道组件有哪些属性可以修改
- 理解组件在页面中的位置和层级
- 基于现有结构进行增量修改,而不是从零生成
这实现了"业务组件零距离接触AI"——企业十年的组件积累,瞬间成为AI的领域知识。
五、L3:RAG优化——让知识检索真正服务于意图识别
5.1 问题:通用RAG在企业场景下的失效
通用的RAG(检索增强生成)方案,面对企业级组件知识时有几个致命问题:
- 分词不准确
- :通用分词器不认识"TreeGrid"、"NavMenuBar"、"ComboInput"等领域术语
- 语义断裂
- :用户说"做个树形表格",RAG可能检索到"树形"和"表格"的无关文档
- 结果截断
- :GenJson模板通常很长,500字符的截断会丢失关键结构
5.2 OODER 的RAG优化方案
领域词典增强
LocalRagService 内置了200+领域术语的专用词典,并支持从 .md 文件动态加载扩展:
private static final Set<String> DOMAIN_DICT = new HashSet<>();
static {
String[] defaultTerms = {
"组件", "属性", "事件", "方法", "字段", "类型", "别名",
"treegrid", "tree", "gallery", "form", "navtree", "navtabs",
"navmenubar", "navgallery", "layout", "chart", "echarts",
"svgpaper", "block", "panel", "div", "tabs", "module",
"genjson", "viewtype", "dock", "alias", "caption", "properties",
// ... 200+ 术语
};
}
// 启动时从外部文件加载扩展词典
private void loadExternalDomainDict() {
Resource[] resources = resolver.getResources(
"classpath:skills/*/knowledge/domain-dictionary.txt");
// 逐行加载,补充到 DOMAIN_DICT
}Markdown感知分块
针对 .md 知识文件,采用按标题分块而非固定长度分块:
// 优先按 Markdown 标题分块
List<String> sections = chunkByMarkdownHeaders(content, chunkSize, overlap);
if (!sections.isEmpty()) {
for (String section : sections) {
if (!section.trim().isEmpty()) {
indexDocumentChunks(docId + "#" + sectionIndex, section, kbId, chunkSize, overlap);
}
}
return;
}这样确保每个文档块都是一个语义完整的知识单元(如"TreeGrid组件的完整GenJson模板"),而不是被截断的半句话。
搜索结果截断优化
将搜索结果的截断长度从500字符提升到1500字符,确保GenJson模板等长内容不会被截断:
if (text.length() > 1500) {
text = text.substring(0, 1500) + "...";
}双模式搜索
支持关键词搜索和向量搜索两种模式,通过配置切换:
ooder.rag.search.mode=keyword # keyword 或 vector关键词模式使用 TF-IDF + 查询覆盖率算法,适合精确匹配;向量模式适合语义模糊匹配。
六、L4:Skills架构——渐进式披露的技能体系
6.1 设计理念
渐进式披露(Progressive Disclosure)是OODER Skills架构的核心设计理念。一个技能的知识不是一次性全部暴露给AI,而是按需分层展开:
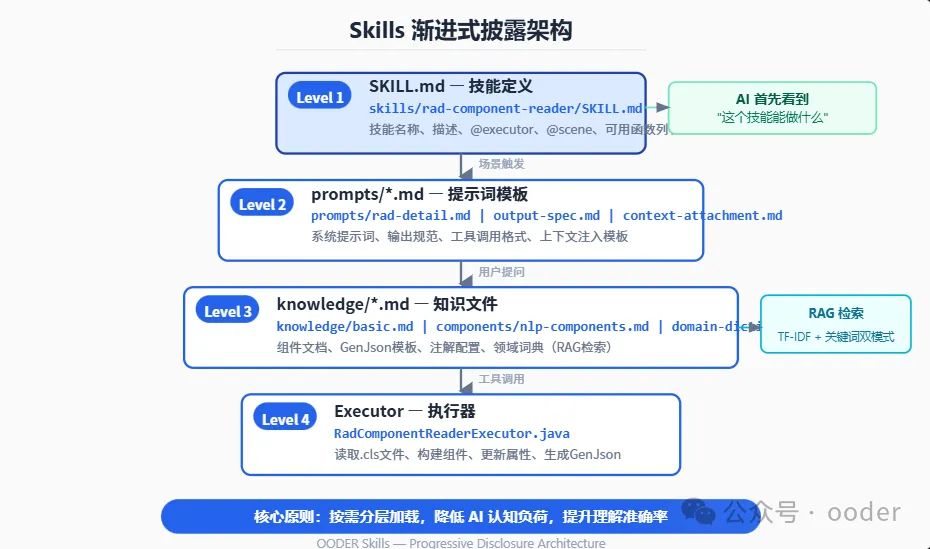
图2:Skills 渐进式披露架构——按需分层加载,降低AI认知负荷
6.2 技能定义文件(SKILL.md)
每个技能有一个 SKILL.md 定义文件,使用结构化元数据:
# RAD Component Reader
@id: rad-component-reader
@version: 2.0.0
@domain: rad
@executor: net.ooder.studio.chat.skill.RadComponentReaderExecutor
@scene: rad
@disclosure: scene
@knowledge-dir: knowledge
@prompts-dir: prompts
## Functions
### list_page_components
列出当前页面中的所有 UI 组件及其类型和别名。
### get_component_defaults
获取指定组件类型的默认 genJson 配置。6.3 SkillMdLoader:技能知识的统一加载器
SkillMdLoader 是技能知识加载的核心组件,支持三种文件类型的扫描和缓存:
@Component
public class SkillMdLoader {
// 缓存:skillDir -> SKILL.md 原始内容
private final Map<String, String> skillContentCache = new ConcurrentHashMap<>();
// 缓存:skillDir -> 解析后的 SkillDefinition
private final Map<String, SkillDefinition> skillDefCache = new ConcurrentHashMap<>();
// 缓存:domain -> 拼接后的知识内容
private final Map<String, String> knowledgeCache = new ConcurrentHashMap<>();
// 缓存:domain -> 拼接后的提示词内容
private final Map<String, String> promptCache = new ConcurrentHashMap<>();
@PostConstruct
public void init() {
loadAllSkills(); // 扫描 skills/*/SKILL.md
loadKnowledgeFiles(); // 扫描 skills/*/knowledge/*.md
loadPromptFiles(); // 扫描 skills/*/prompts/*.md
}
}6.4 PromptEngine外部化:从硬编码到.md驱动
在本次重构中,我们将PromptEngine中的所有硬编码提示词迁移到了 .md 文件:
重构前(PromptEngine.java 构造函数中80行硬编码):
// 硬编码5个场景模板
scenePromptTemplates.put("rad", "你是 OODER Studio 的 RAD 设计助手...");
scenePromptTemplates.put("bpm", "你是 OODER Studio 的 BPM 流程设计助手...");
// ... 更多硬编码重构后(从 .md 文件动态加载):
@PostConstruct
public void init() {
loadScenePromptsFromMd(); // 扫描 skills/*/prompts/*.md
loadSharedTemplatesFromMd(); // 加载输出规范、上下文格式等
}
private String loadPromptMd(String promptName) {
Resource[] resources = resolver.getResources(
"classpath:skills/*/prompts/" + promptName + ".md");
for (Resource resource : resources) {
String content = readResourceContent(resource);
if (content != null && !content.trim().isEmpty()) {
return content.trim();
}
}
return null; // 降级到 fallback 硬编码
}对应的 .md 文件结构:
skills/rad-component-reader/prompts/ ├──rad.md # RAD场景基础提示词 ├──rad-detail.md # RAD场景详细提示词(工具列表、组件体系、工作流规则) ├──bpm.md # BPM场景提示词 ├──bpm-designer.md # BPM设计器详细提示词 ├──skills.md # 技能管理场景提示词 ├──hybrid.md # 混合场景路由提示词 ├──default.md # 默认场景提示词 ├──output-spec.md # 输出规范(7条规则) ├──tool-result.md # 工具调用结果处理模板 ├──context-attachment.md# 上下文附件注入格式 ├──knowledge-injection.md# 组件知识注入格式 └──intent-recognition.md # 意图识别Prompt模板
收益:
- 提示词可以独立于代码迭代,业务人员也能参与优化
- 不同场景的提示词可以独立维护,互不影响
- 支持A/B测试:同一场景可以加载不同版本的提示词
七、L5:深度思考对话——Function Calling Loop + 可视化即时反馈
7.1 Function Calling Loop 执行器
OODER 的对话引擎采用 Function Calling Loop 模式——AI不是一次性回答,而是多轮调用工具,直到任务完成:
// FunctionCallingLoopExecutor.java 核心循环
while (iteration < maxIterations) {
// 1. 调用LLM
ChatResponse response = llmEngine.chatCompletion(messages, tools, ...);
// 2. 解析工具调用
List<ToolCall> toolCalls = response.getToolCalls();
if (toolCalls == null || toolCalls.isEmpty()) break; // 无工具调用,结束循环
// 3. 执行工具
for (ToolCall toolCall : toolCalls) {
String functionName = toolCall.getFunction().getName();
String arguments = toolCall.getFunction().getArguments();
Object result = executeToolCall(functionName, arguments, context);
toolExecutions.add(execution);
}
// 4. 将工具结果反馈给LLM,继续下一轮
messages.add(toolResultMessage);
iteration++;
}7.2 步骤面板:实时可视化执行过程
前端的 NlpChatInline.js 实时解析AI回复中的步骤标记,展示在任务面板中:
// 解析 【Step N】标记
_parseSteps: function (content) {
var stepRegex = /【Step\s*(\d+)】(.+)/g;
var steps = [];
var match;
while ((match = stepRegex.exec(content)) !== null) {
steps.push({
index: parseInt(match[1]),
description: match[2].trim(),
status: 'running'
});
}
return steps;
}7.3 工具结果即时应用到设计器
最核心的闭环:AI调用工具后,结果即时应用到可视化设计器:
// NlpChatInline.js - _applyRadToolResults
if (toolName === 'nlp_build_component') {
// 将AI生成的组件直接渲染到设计器
SPA.fe("onNlpBuildComplete", [{
moduleName: result.moduleName,
componentType: result.componentType,
genJson: result.genJson, // 组件定义
designerJson: result.designerJson // 设计器JSON
}]);
} else if (toolName === 'update_component') {
// 直接更新设计器中组件的属性
var designer = SPA.getDesigner();
var node = designer.getByAlias(updateItem.alias, true);
node.boxing().setProperties(updateItem.properties);
designer.refreshView(designer.getJSCode(designer.getWidgets(true)), true);
} else if (toolName === 'render_chart_quickview') {
// 图表即时预览
host._showChartQuickView(chartHtml, chartType);
}这就是"业务AI面对面"的含义:用户说一句话,AI理解意图、选择组件、填充属性、即时渲染——整个过程在对话窗口中完成,所见即所得。
八、意图识别:从关键词匹配到语义理解
8.1 双层意图识别架构
OODER 采用规则优先 + LLM兜底的双层意图识别策略:
public IntentRecognitionResult recognize(String query) {
// 第一层:规则匹配(快速、确定性)
IntentRecognitionResult ruleResult = ruleBasedRecognize(query);
if (ruleResult.getConfidence() > 0.8) {
return ruleResult; // 高置信度直接返回
}
// 第二层:LLM语义理解(慢速、高准确性)
return llmBasedRecognize(query);
}8.2 意图关键词外部化
意图识别的关键词配置同样支持从外部文件加载:
# intent-keywords.txt
CREATE_FORM | 表单,form,输入,编辑,录入,填写,新增表单,编辑表单
CREATE_GRID | 表格,grid,列表,list,数据,查询,数据表,数据列表
CREATE_TREE | 树,tree,层级,目录,分类,树形,组织架构,菜单树
CREATE_CHART | 图表,chart,统计,分析,报表,柱状图,折线图,饼图
CREATE_SVGPAPER | 流程图,架构图,组织架构图,思维导图,脑图,拓扑图
CREATE_NAVIGATION | 导航,nav,菜单,标签页,tab,侧边栏,导航树
CREATE_LAYOUT | 布局,layout,分栏,分区,容器,block,panel,div
CREATE_DIALOG | 对话框,弹窗,dialog,modal,模态框,弹出框8.3 多场景路由
ChatSceneRouter 根据场景匹配算法,将用户输入路由到最合适的处理场景:
// RadChatScene 匹配逻辑
public int matchScore(String userMessage, ChatContext context) {
int score = 0;
// 正向关键词:组件、表单、表格、树、图表、页面、布局、导航
String[] uiContextKeywords = {"组件", "表单", "表格", "树", "图表", ...};
// 动作关键词:生成、创建、构建、做一个、帮我做
String[] actionKeywords = {"生成", "创建", "构建", "做一个", ...};
for (String kw : uiContextKeywords) {
if (lowerMsg.contains(kw)) score += 2;
}
for (String kw : actionKeywords) {
if (lowerMsg.contains(kw)) score += 1;
}
// 负向关键词:流程、审批、bpm、技能、skill
String[] negativeKeywords = {"流程", "审批", "节点", "bpm", "技能", ...};
for (String kw : negativeKeywords) {
if (lowerMsg.contains(kw)) score -= 5;
}
return score;
}九、完整工作流:从自然语言到可视化组件
让我们用一个完整的例子串联所有能力:
用户输入:"帮我创建一个员工请假审批表单,包含请假类型、开始日期、结束日期、请假天数、请假事由"
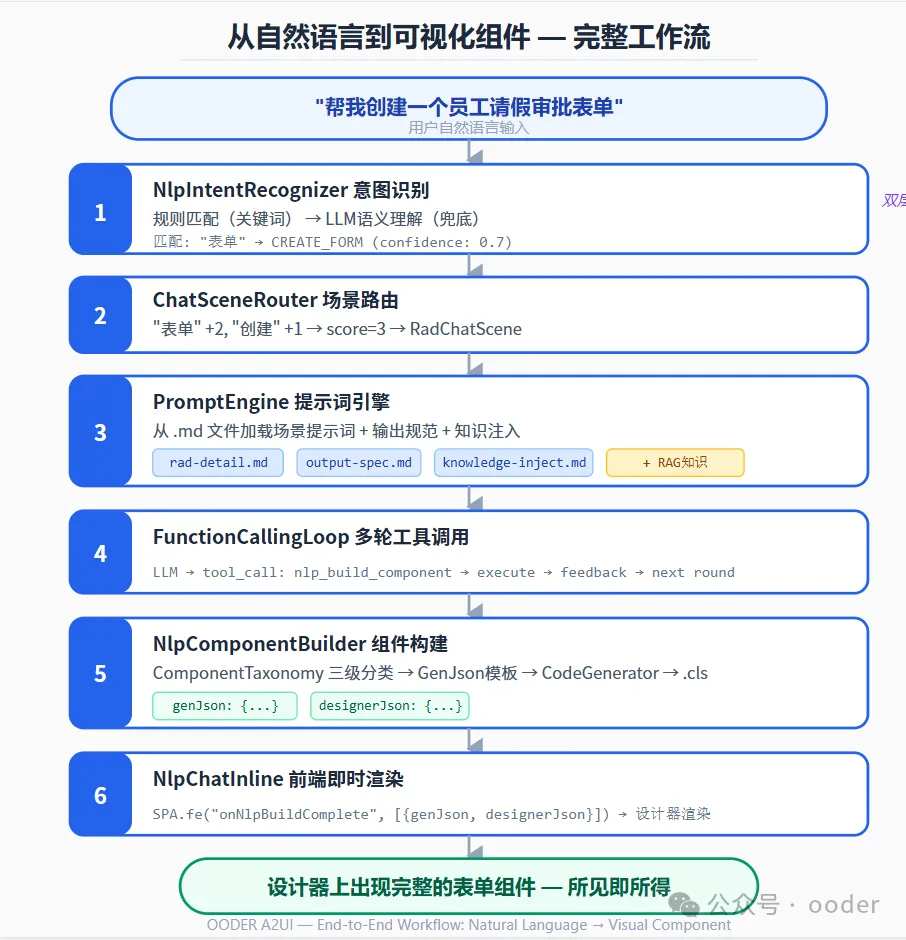
图3:从自然语言到可视化组件的完整工作流
Step 1:意图识别
NlpIntentRecognizer → ruleBasedRecognize
匹配关键词:"表单" → CREATE_FORM (confidence: 0.7)Step 2:场景路由
ChatSceneRouter → RadChatScene.matchScore
"表单" +2, "创建" +1 → score=3 → 路由到 RAD 场景Step 3:PromptEngine 构建系统提示词
String prompt = promptEngine.buildSystemPrompt(scene, context);
// 加载 rad.md + rad-detail.md + knowledge-injection.md + output-spec.mdStep 4:LLM 生成工具调用
{
"tool_calls": [{
"function": {
"name": "nlp_build_component",
"arguments": "{\"description\": \"员工请假审批表单...\"}"
}
}]
}Step 5:NlpComponentBuilder 执行
// FormComponentBuilder.build()
// 1. 根据 description 提取字段:请假类型、开始日期、结束日期、请假天数、请假事由
// 2. 生成 GenJson 模板
// 3. 调用 CodeGenerator 生成 .cls 文件
// 4. 返回 genJson + designerJsonStep 6:前端即时渲染
SPA.fe("onNlpBuildComplete", [{
moduleName: "LeaveRequestForm",
componentType: "Form",
genJson: { /* 完整的 .cls JSON */ },
designerJson: { /* 设计器渲染用 JSON */ }
}]);
// → 设计器立即渲染出表单整个过程在几秒内完成,用户看到的是:说了一句话 → 设计器上出现了一个完整的表单组件。
十、架构总结:组件化 × AI = 企业软件的下一个十年
能力层 | 核心组件 | 解决的问题 | 关键设计 |
|---|---|---|---|
L1 可视化渲染 | .cls + GenJson + moduleViewType | AI生成代码无法复用企业组件 | AI填属性,框架负责渲染 |
L2 组件语义化 | ComponentTaxonomy + @A2uiSkill | AI不知道该用哪个组件 | 三级分类 + 关键词NLP匹配 |
L3 RAG知识检索 | LocalRagService + 领域词典 | 通用RAG不理解领域术语 | 领域词典 + Markdown分块 + 双模式 |
L4 渐进式披露 | Skills SKILL.md + PromptEngine | AI认知负荷过重 | 4级按需加载 + Prompt外部化 |
L5 深度对话 | FunctionCallingLoop + NlpChatInline | AI一次回答无法完成复杂任务 | 多轮工具调用 + 即时渲染反馈 |
十一、对企业软件架构师的建议
11.1 组件标准化是AI化的前提
如果你的企业组件还停留在"每个项目一套样式、一套接口、一套配置方式"的状态,AI化改造的第一步不是接入大模型,而是组件接口标准化。
OODER的做法:
- 统一 .cls JSON格式定义组件树
- 统一 moduleViewType 枚举标识组件类型
- 统一 GenJson 模板作为组件默认配置
- 统一 @A2uiSkill 注解声明组件的NLP能力
11.2 知识外置而非硬编码
本次重构的核心教训:所有面向AI的知识都应该外置为 .md 文件。
- 提示词 → prompts/*.md
- 组件知识 → knowledge/*.md
- 意图关键词 → knowledge/intent-keywords.txt
- 领域词典 → knowledge/domain-dictionary.txt
这不仅便于维护,更重要的是——业务人员可以直接参与知识的编写和优化,而不需要修改代码。
11.3 渐进式披露降低AI认知负荷
不要一次性把所有知识都塞给AI。OODER的Skills架构证明:按需分层加载知识,AI的理解准确率和响应速度都会显著提升。
十二、结语
企业软件的AI化,不是用AI替代组件,而是让AI理解组件、调用组件、组装组件。
组件化配置化是企业软件的骨架,AI是赋予骨架生命的灵魂。骨架越标准、越丰富,灵魂就越强大。
OODER A2UI 的实践证明:当企业沉淀的重量级业务组件完成了架构标准化升级,当知识从硬编码迁移到了可维护的 .md 文件,当意图识别从模糊的关键词匹配进化到了结构化的三级分类体系——AI就能真正成为企业软件的生产力倍增器,而不是一个只能生成通用代码的玩具。
这才是企业软件在AI时代该走的路。
本文基于 OODER A2UI 框架的实际代码重构实践撰写。文中所有代码示例均来自真实项目。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号