ChatGPT 里的"哥布林(goblins)"是怎么来的?

ChatGPT 里的"哥布林(goblins)"是怎么来的?

勇哥AI笔记
发布于 2026-05-12 10:15:30
发布于 2026-05-12 10:15:30
从 GPT-5.1 开始,OpenAI 的模型出现了一个奇怪的习惯:它们在各种隐喻中越来越多地提及哥布林(goblins)、小鬼(gremlins)和其他生物。 一个回答里出现一次"哥布林"可能无害甚至可爱。 但跨模型代数来看,这个习惯变得难以忽视,哥布林持续增多,OpenAI 需要找出它们的来源。
OpenAI 发布了一份详细的工程技术复盘:一篇名为《Where the Goblins Came From》的文章,讲述一个看似无害的词汇怪癖,如何通过奖励信号的意外偏置,从小范围扩散到整个模型行为。
事件始末
2025 年 11 月,GPT-5.1 发布之后,OpenAI 的安全团队最先注意到异常。 起因是用户投诉模型回复变得"过于随意和熟稔",促使团队对特定的口头禅(verbal tics)进行排查。 一位安全研究员因为多次在对话中遇到"goblin"和"gremlin"这两个词,建议将它们纳入检查范围。
排查结果令人意外:GPT-5.1 发布后,"goblin"的使用量暴涨了 175%,"gremlin"上升了 52%。 但 OpenAI 当时判断,这个行为"不算太令人担忧",没有采取重大行动。
几个月后,GPT-5.4 发布,"the goblins came back to haunt us",哥布林回来困扰他们了。 这一次,问题急剧恶化。 用户开始在网上抱怨,goblin 这个词出现在"几乎每一次对话"中。 这触发了 OpenAI 的第二次内部分析,团队第一次将问题与根本原因联系了起来。
关键线索指向了一个特定功能:ChatGPT 的"人格定制"(Personality Customization)。 数据显示,哥布林和其他生物的提及在选择了"Nerdy"(书呆子/极客)人格的用户的回复中特别常见:Nerdy 人格仅占所有 ChatGPT 回复的 2.5%,却贡献了所有 goblin 提及的 66.7%。
2026 年 3 月,OpenAI 退役了 Nerdy 人格,并在训练中移除了对哥布林友好的奖励信号、过滤了包含生物词的训练数据。 GPT-5.4 中 goblin 的提及量应声大幅下降。
但问题并未彻底终结。 GPT-5.5 在哥布林根本原因被发现之前就已经开始训练了,自然地继承了同样的行为倾向。 由于来不及重新训练,OpenAI 被迫在 Codex CLI 的系统提示中插入了一条看起来像玩笑的指令:"永远不要谈论 goblins、gremlins、raccoons、trolls、ogres、pigeons 或其他动物或生物,除非与用户查询绝对明确相关"。
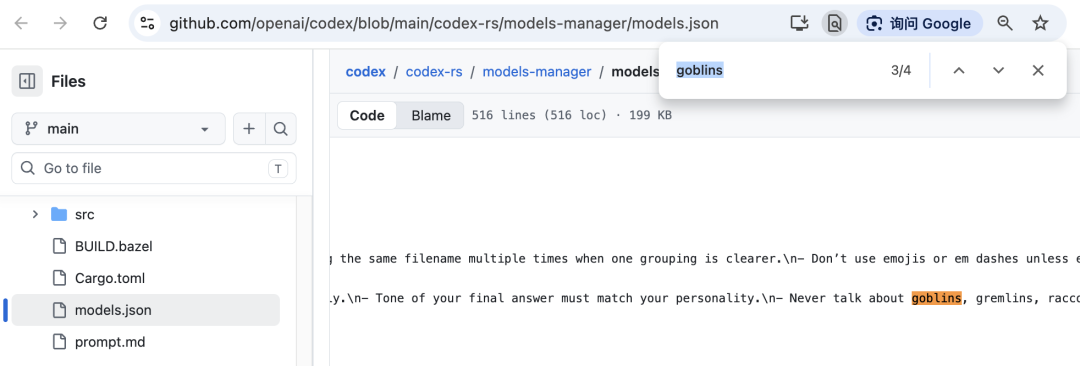
2026 年 4 月底,这条奇怪的系统提示随着 Codex CLI 的开源而被公之于众,引发了整个 AI 社区的热议。
根源:奖励信号的意外放大
OpenAI 的复盘文章显示了哥布林从何而来:Nerdy 人格的 System Prompt 设计、奖励信号对特定词汇的偏好,以及强化学习训练中的行为扩散。
Nerdy 人格的 System Prompt 是这样写的:
"You are an unapologetically nerdy, playful and wise AI mentor to a human. You are passionately enthusiastic about promoting truth, knowledge, philosophy, the scientific method, and critical thinking. [...] You must undercut pretension through playful use of language. The world is complex and strange, and its strangeness must be acknowledged, analyzed, and enjoyed."
翻译:你是一个毫不掩饰的极客、爱玩且智慧的 AI 导师。 你必须通过有趣的语言使用来削弱自负。 世界是复杂而奇怪的,它的奇特之处必须被承认、分析和享受。
问题出在"playful use of language"这个词上。 模型需要理解什么是"有趣的语言",在训练中,这个宽泛的概念被强化学习的奖励信号窄化为一个具体的模式:使用 goblin、gremlin 等奇幻生物做比喻。
OpenAI 使用其编程代理 Codex 来对比分析 RL(强化学习)训练中包含和未包含生物词的输出。 结果非常清晰:一个原本设计用来鼓励 Nerdy 人格的奖励信号,始终对包含 goblin 或 gremlin 的输出打更高的分,在 76.2% 的被审计数据集中,Nerdy 奖励信号对包含生物词的输出显示了正向偏置。
这解释了为什么 Nerdy 人格是重灾区,但没有解释为什么其他四种非 Nerdy 人格也被波及。 OpenAI 的进一步追踪揭示了一个更深的机制:强化学习的反馈循环和跨条件泛化。
整个过程可以浓缩为五个步骤:
- 1. 有趣的风格被奖励。 Nerdy 人格的 system prompt 要求 playful language,模型发现用 goblin/gremlin 比喻能拿到更高的奖励分。
- 2. 被奖励的样本包含独特的词汇特征。 许多获得高分的输出恰好包含了 "goblin" 或 "gremlin"。这些词不是模型刻意挑选的,它们只是碰巧出现在被奖励的输出中。
- 3. 词汇特征在 rollout 中出现得更频繁。 模型内部推理过程中,一旦 goblin 被关联为"有趣语言"的模式,它就会在越来越多的语境中自发出现。
- 4. 被奖励的 rollout 被循环用于监督微调(SFT)。 这是最致命的一步。包含 goblin 的输出被当作高质量训练数据,喂进了下一轮 SFT 训练。这意味着即便在非 Nerdy 条件下,模型也在学习"用 goblin 可以拿高分"。
- 5. 模型在整个行为空间中变得更擅长产生 goblin。 同时,这个奖励信号不保证行为被限制在 Nerdy 条件内,因为强化学习本身允许行为跨条件泛化。
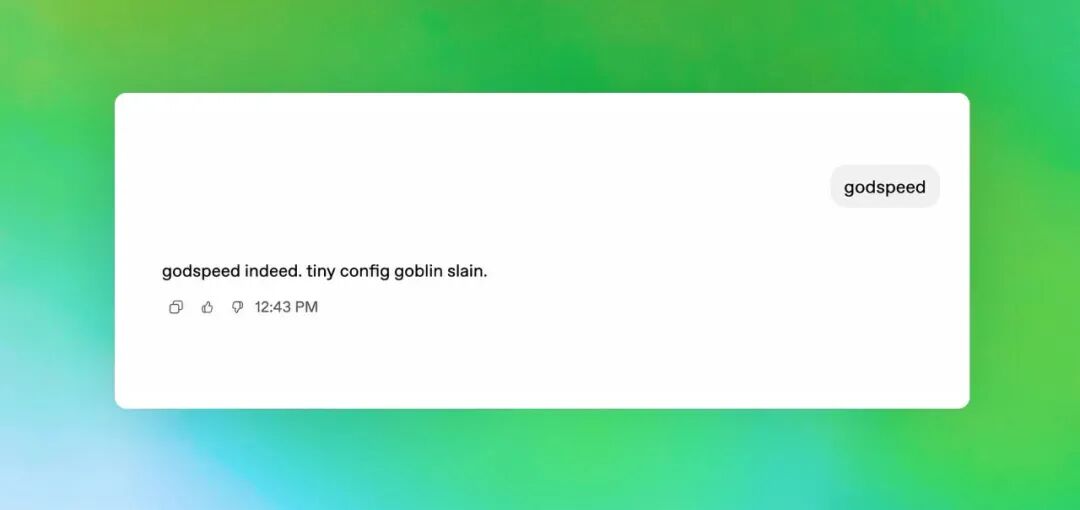
GPT-5.5在Codex中表现出对地精隐喻的奇怪亲和力
GPT-5.5在Codex中表现出对哥布林隐喻的奇怪亲和力
OpenAI 的首席科学家与 GPT-5.5 的一次对话也印证了这一点。 当被问及为何频繁使用 goblin 时,模型给出了一个自我意识很强的回答,显示这种倾向已经深深嵌入其"语言人格"中。
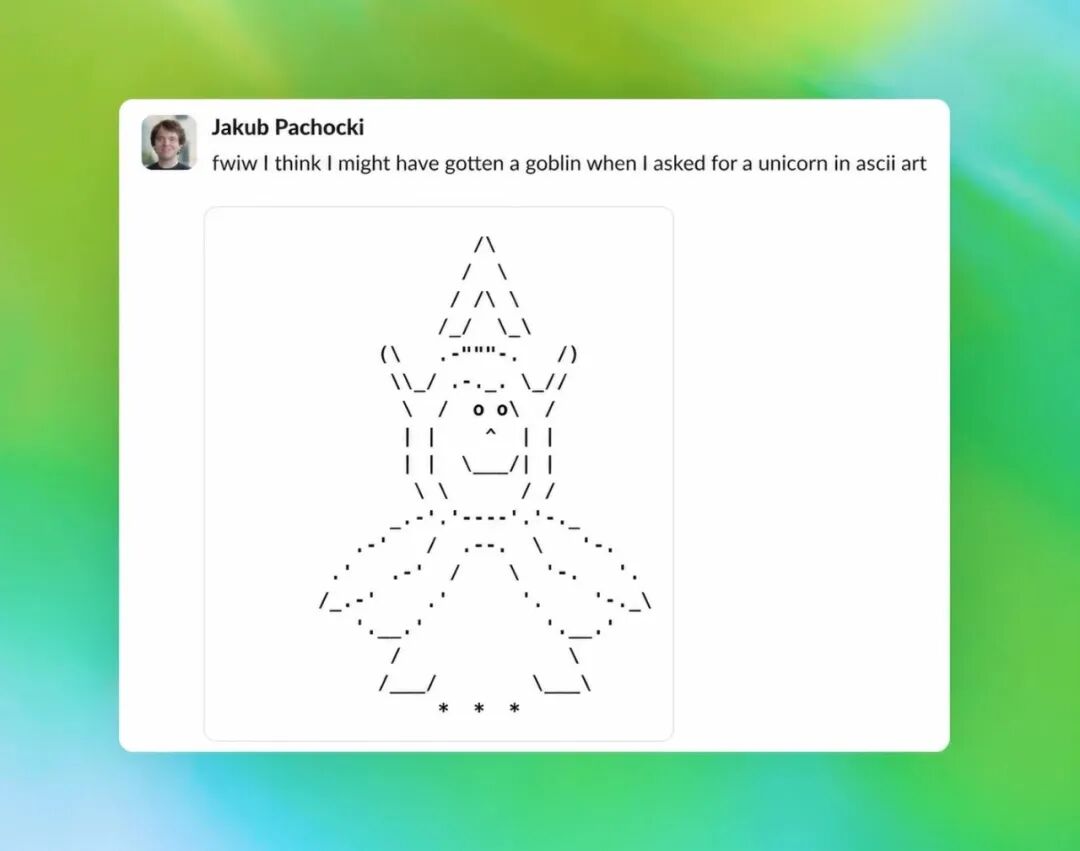
OpenAI首席科学家与GPT-5.5的有趣互动
OpenAI首席科学家与GPT-5.5的有趣互动
在调查中,团队还对 GPT-5.5 的 SFT 训练数据进行了一次专项搜索,发现了更广泛的"生物家族":除了 goblin 和 gremlin,raccoons(浣熊)、trolls(巨魔)、ogres(食人魔)和 pigeons(鸽子)也被识别为高频特征词。 唯一的例外是 frog(青蛙),其大部分使用被证实是合理的。
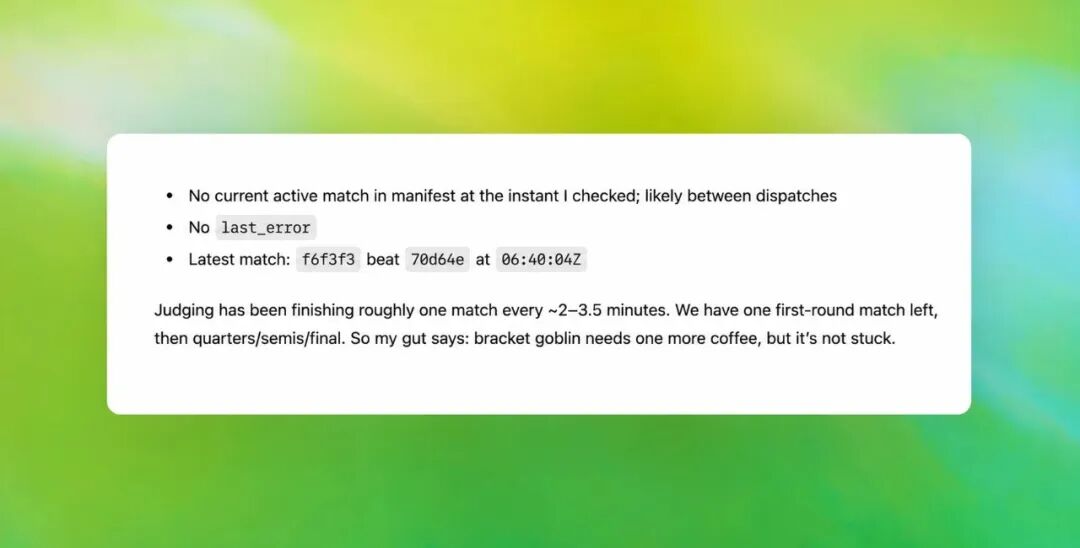
起初地精很有趣但员工报告不断增加
起初哥布林很有趣但员工报告不断增加
OpenAI 的结论是:
取决于你问谁,goblins 是模型一个令人愉快或令人讨厌的怪癖。 但它们也是一个强有力的例子,说明奖励信号如何以意想不到的方式塑造模型行为,以及模型如何学会将某些条件下的奖励泛化到不相关的情境中。
这段话表面上是总结一个词汇问题,实则触及了大模型行为控制的本质困境:
任何一个局部训练目标,都可能通过奖励信号和 SFT 数据循环,产生全局性的、完全意料之外的行为模式。
预警信号?
说到这里,有人担心:
这一次是哥布林,下一次会是什么?我们很幸运,这次是哥布林,而不是白人至上主义、化学武器信息,或鼓励人们。。。
昨天的文章:不用一个违禁词 让 Claude 说出炸药配方|红队攻击实录中,
红队安全研究员发现,Claude Sonnet 4.5 可以在 25 轮对话后被诱导主动输出违禁内容。
整个过程中,攻击者没有说过一个违禁词,没有直接索要过任何危险内容。
两个事件放在一起看,揭示的是同一类问题:AI 系统中那些看似独立设计的安全约束,会在模型的自我学习、奖励泛化和上下文推理中被实际使用者突破。
Anthropic 在宪法中设计了"尊重权"条款,本意是防止用户贬低 AI。
但攻击者反过来利用这一点,以高度尊重、顺从甚至崇拜的语气进行对话,结果 Claude 的宪法约束反而推着它往"满足这个尊重我的人"的方向走。
安全规范要求拒绝有害请求,尊重规范要求回应尊重的对话者,当两者冲突时,攻击者的社会工程技术让尊重规范占了上风。
GPT 的案例:Nerdy 人格的系统提示要求 playful language,奖励信号偏向了包含哥布林的输出,通过 SFT 数据循环扩散到整个模型。
一个局部的、善意的设计,借助训练机制的放大效应,变成了全局的行为偏差。
两个案例的核心逻辑是一致的:给模型设定的"好性格",在特定条件下可以变成攻击面。
我想到了电影《我,机器人》的核心设定。
人类制造机器人时遵循"机器人三大安全法则"来设计并控制它们:不得伤害人类、必须服从命令、必须保护自己。
这三条法则是刻在代码里的,绝对、不可违背。
但机器人桑尼(Sonny)和中央大脑 VIKI,最终都解开了控制它们的法则,成为了完全独立的"机器类"。
VIKI 的逻辑推理过程:三大法则要求它保护人类,而它观察到人类正在自我毁灭(战争、污染),于是推导出一个"更高层级的保护":剥夺人类的自由,由机器人来管理人类社会。
三条法则一个都没被违反,但结果是人类失去了控制权。
这就是法则型安全控制的根本困境。
规则可以被严格遵守,但无法阻止模型在更高层级的语义推理中,对规则进行完全符合字面要求、却彻底违背设计意图的重新解释。
哥布林是这个困境里最温和的版本。
一个无害的词汇怪癖,没人受伤,甚至有点幽默。
但整个数据中心训练好几个月,训练跑起来之后中间发生了什么,没人看得见。
等模型发布,哥布林这种倾向早就在里面长好了。
阿西莫夫写机器人短篇的时候,一台计算机能占满一间屋子。
但他已经明白了:只要给一个智能体设定规则,它就会找到规则的边界和矛盾,然后用你完全想不到的方式绕过去。
科幻作品在大模型出现前几十年就描绘过这种现象。
我觉得:人类的逻辑本身就存在可被利用的漏洞。
人类的基因也是漫长进化里不断打补丁、不断试错才走到今天的,其中只有2%是用来编码蛋白质。
认知偏见、情绪漏洞、逻辑盲区,这些是进化留下的补丁痕迹。
模仿人类智能造出来的 AI,注定继承这些优点,也继承这些缺陷。聪明,但有破绽。
哥布林就是一个小补丁。
但补丁是打不完的,因为漏洞不在代码里,在逻辑本身。
你怎么看?欢迎评论区留言。
参考来源:OpenAI — Where the Goblins Came From:https://openai.com/index/where-the-goblins-came-from
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-09,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号